如果将深度定义为网络中信息传递路径长度的话,循环神经网络可以看作既“深”又“浅”的网络。
一方面来说,如果我们把循环网络按时间展开,长时间间隔的状态之间的路径很长,循环网络可以看作一个非常深的网络。
从另一方面来 说,如果同一时刻网络输入到输出之间的路径𝒙𝑡 → 𝒚𝑡,这个网络是非常浅的。
因此,我们可以增加循环神经网络的深度从而增强循环神经网络的能力。增加循环神经网络的深度主要是增加同一时刻网络输入到输出之间的路径 𝒙𝑡 → 𝑦𝑡,比如增加隐状态到输出 𝒉𝑡 → 𝒚𝑡,以及输入到隐状态 𝒙𝑡 → 𝒉𝑡 之间的路径的深度。
本文我来学习两种常见的增加循环神经网络深度的做法。
一、堆叠循环神经网络
堆叠循环神经网络(Stacked RNN)是将多个循环神经网络层级组合在一起的结构,也称为循环多层感知器,相当于在时间序列上“堆叠”多层隐状态,从而提高模型对信息的抽象能力和表达复杂性。
1. 基本概念
在传统的单层 RNN 中,每个时间步的隐藏状态 ht 的计算通常为:
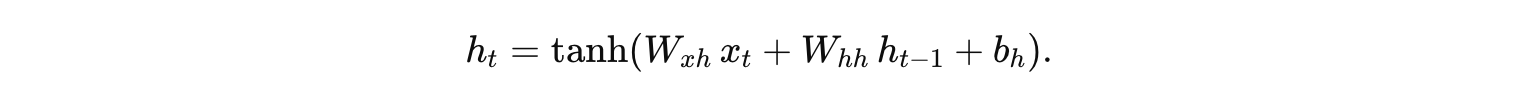
而在堆叠 RNN 中,我们将多个这样的 RNN 单元按层级排列,通常称为“深层 RNN”或“堆叠 RNN”。例如,假设我们有两层 RNN:
-
第一层 RNN(低层)处理原始输入序列 xt 产生隐层表示
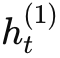 。
。 -
第二层 RNN(高层)以第一层的输出作为输入,进一步生成更高层次的表示
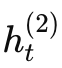 。
。
这种设计使得低层可以捕捉局部、短期的信息,而高层则能抽象出全局或更复杂的模式,特别适合于具有多层语义结构的任务,如自然语言处理、语音识别、时间序列预测等。
下图给出了按时间展开的堆叠循环神经网络:
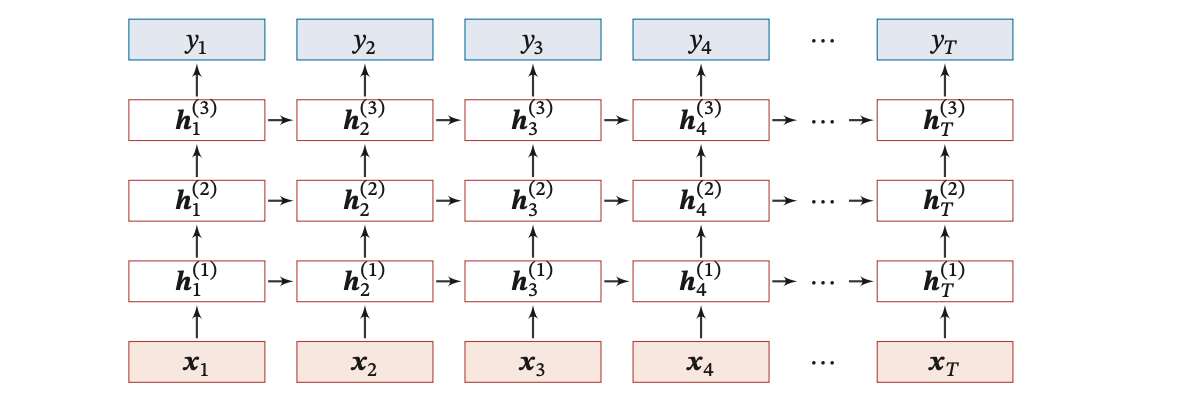
第 𝑙 层网络的输入是第 𝑙 − 1 层网络的输出。我们定义 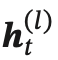 为在时刻 𝑡 时第 𝑙 层的隐状态:
为在时刻 𝑡 时第 𝑙 层的隐状态:

2. 具体例子
任务: 对简单数列进行预测——给定输入序列 [1, 2, 3],目标输出为 [2, 3, 4],即每个数字加 1。
模型设定:
-
输入和输出均为标量。
-
我们使用一个两层 RNN,每层都有一个隐藏单元(为了便于示例,我们这里采用单隐藏单元,但后续扩展到多维也类似)。
第一层 RNN(层 1):
公式:
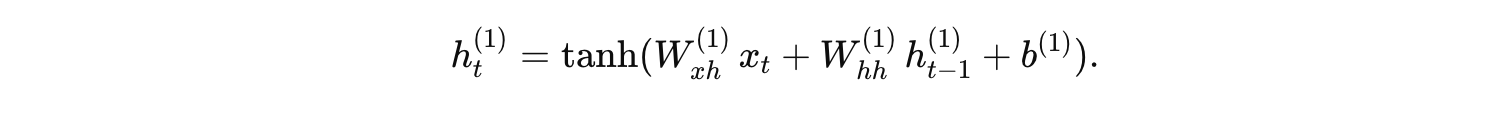
假设参数为:

计算过程:
-
时间步 1 (t=1):
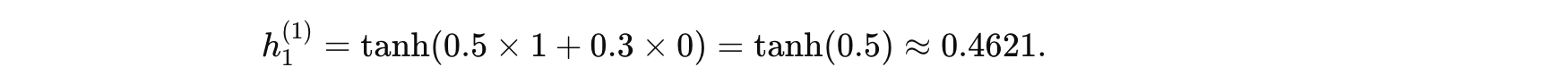
-
时间步 2 (t=2):
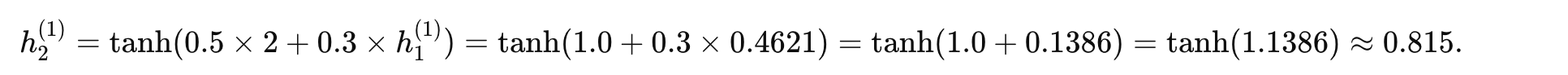
-
时间步 3 (t=3):
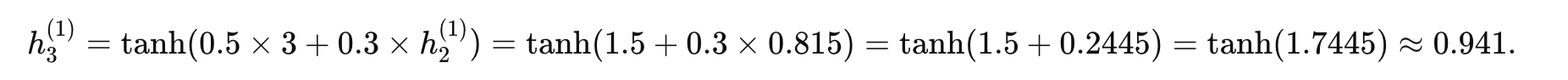
第二层 RNN(层 2):
公式:
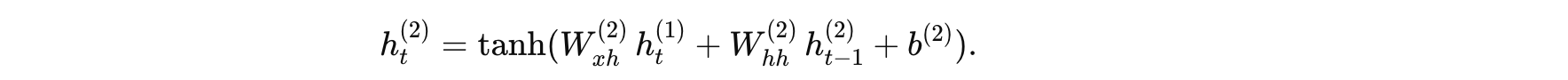
假设参数为:

计算过程:
-
时间步 1 (t=1):
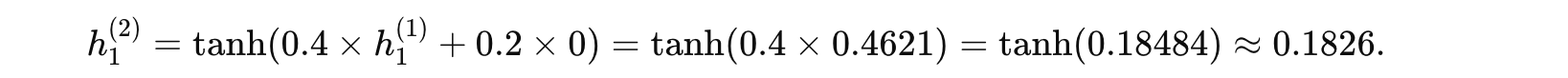
-
时间步 2 (t=2):
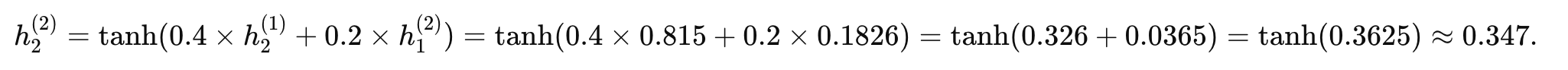
-
时间步 3 (t=3):
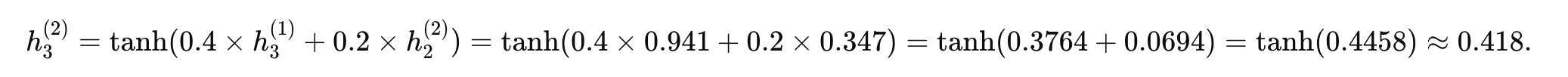
输出层:
假设将第二层的隐藏状态直接映射为输出,公式为:
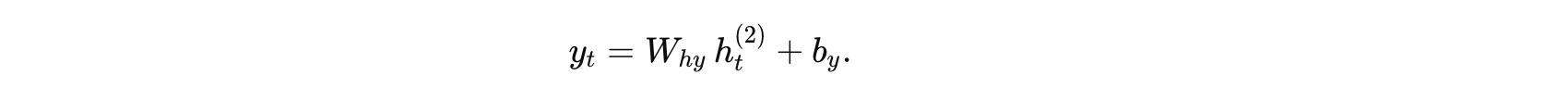
假设参数为:

则最终模型输出:
-
y1≈0.1826
-
y2≈0.347
-
y3≈0.418
为使输出反映“每个数字加 1”,假设目标输出应该为 [2, 3, 4],当前输出与目标有较大差距。通过反向传播(例如均方误差损失)计算梯度,再结合 BPTT,将误差信息逐层反传,从第二层到第一层,对各层参数 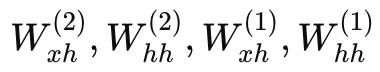 进行更新。
进行更新。
经过多轮迭代后,模型逐渐学会如何利用低层提取到的局部特征和高层传递到整体抽象信息,使得输出能够更准确地逼近目标(例如最终输出 [2, 3, 4])。
3. 为什么使用堆叠 RNN?
-
抽取多层次特征:
低层可以捕捉输入中局部、短期的模式,比如简单的数值变化;高层则能捕捉更抽象的全局信息,如序列整体趋势、结构关系等。 -
提高模型表现:
对于复杂任务,例如机器翻译或情感分析,堆叠 RNN 能够实现更深入的信息处理,进而提升性能。
4. 应用场景
-
自然语言处理:
在语句建模、语言翻译中,堆叠 RNN 能够从词汇级别到句子级别提取不同层次的语法和语义信息。 -
语音识别:
利用多层结构捕捉语音信号中局部发音和全局语调等特征,提升识别准确率。 -
时间序列预测:
在金融数据、传感器数据等任务中,堆叠 RNN 能够建模短期波动和长期趋势,提高预测精度。
堆叠循环神经网络通过在不同层次上堆叠多个 RNN 层,使模型能够逐步抽象出从局部模式到全局语义的复杂表示。在以上例子中,我们以简单的数字序列预测为例,通过两层 RNN 分别提取原始输入的低级特征和高级抽象信息,再通过输出层映射得到预测结果。尽管示例中采用了非常简单的数值和单隐藏单元,但在实际应用中,这种多层结构可以大幅提升模型对长序列和复杂依赖关系的表达能力,因此在 NLP、语音识别、时间序列预测等领域得到广泛应用。
二、双向循环神经网络
在有些任务中,一个时刻的输出不但和过去时刻的信息有关,也和后续时刻 的信息有关。比如给定一个句子,其中一个词的词性由它的上下文决定,即包含左右两边的信息。因此,在这些任务中,我们可以增加一个按照时间的逆序来传递信息的网络层,来增强网络的能力。即所谓的双向循环神经网络,由两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同:
假设第 1 层按时间顺序,第 2 层按时间逆序,在时刻 𝑡 时的隐状态定义为 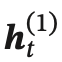 和
和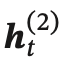 ,
,
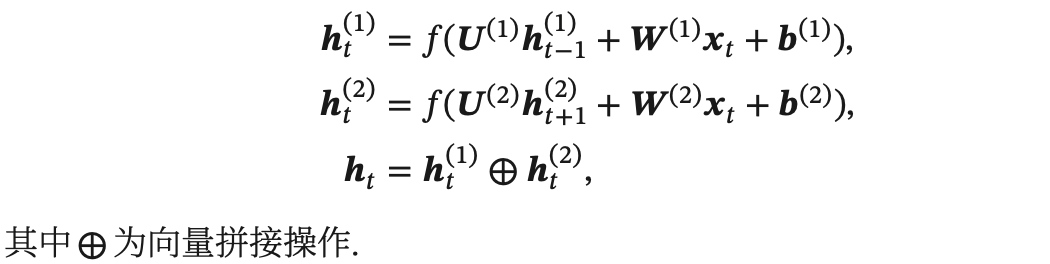
双向循环神经网络(Bidirectional RNN, Bi-RNN)是一种扩展自传统RNN的架构,其基本思想是同时利用序列的正向和反向信息,从而使每个时间步的隐层状态能够综合考虑前后文信息。这对于很多自然语言处理任务非常关键,因为理解一个词语或字符往往不仅依赖于它之前的信息,也与它之后的语境密切相关。
下图给出了按时间展开的双向循环神经网络:
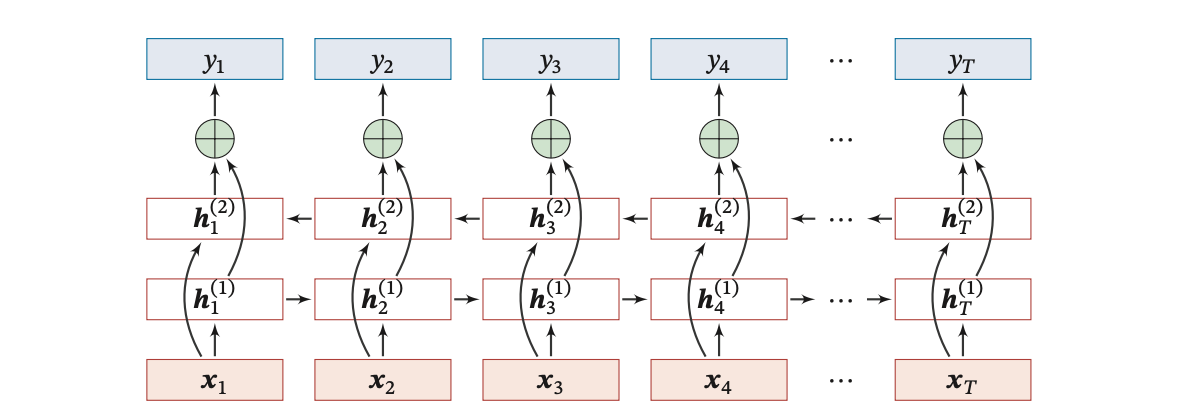
下面通过详细的解释和一个具体例子来说明双向RNN的原理和应用。
1. 核心原理
在传统的单向RNN中,隐藏状态 ht 只依赖于从序列起点到时间步 t 的信息,这意味着对于当前时间步的输出,只能利用其历史信息。这在某些任务中可能不足以捕捉上下文的全部信息。
双向RNN的关键在于构建两个RNN子网络:

最后,把正向和反向隐藏状态进行合并(例如拼接、加权平均或求和),形成每个时间步的综合表示 ht=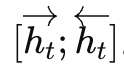 。这种综合表示既包含了过去的信息,也包含了未来的信息,为后续任务(如分类、标注、生成)提供了更完整的上下文。
。这种综合表示既包含了过去的信息,也包含了未来的信息,为后续任务(如分类、标注、生成)提供了更完整的上下文。
2. 详细例子:命名实体识别(NER)
任务说明:
在命名实体识别任务中,我们需要从一段文本中识别出人名、地点、组织等实体。正确判断一个词是否为实体,往往需要综合该词前后的上下文信息。
输入示例:
假设有一句话:"Barack Obama visited Berlin last summer."
我们对这句话进行分词,得到:
["Barack", "Obama", "visited", "Berlin", "last", "summer"]
双向RNN建模:
-
正向处理:
正向RNN从第一个单词 "Barack" 开始,一直向后计算隐藏状态:
其中 f 表示 RNN 单元的前向更新函数,这里可理解为典型的 tanh(Wx+Uh+b) 形式。
-
反向处理:
反向RNN从最后一个单词 "summer" 开始,往回计算隐藏状态:
-
合并隐藏状态:

模型训练和输出:
-
训练过程中,模型会在每个时间步计算一个预测(例如通过 softmax 输出每个词的实体类别标签)。
-
损失函数(如交叉熵)被计算在整个序列上,反向传播时两个方向的梯度分别求出,再根据参数共享机制更新网络参数。
-
经过训练,模型能学习到如何利用正向和反向信息共同对每个词进行分类,从而提高命名实体识别的准确率。
3. 应用场景
-
命名实体识别、序列标注等 NLP 任务
例如,翻译、情感分析、对话系统中,词的含义往往受其前后文影响,双向RNN可以同时捕捉两侧上下文信息,从而提升模型性能。 -
语音识别
在语音识别中,双向模型可以利用未来和过去的信息提高语音转写的准确率,尤其是在需要后处理来消除噪音的场景中更为有效。 -
视频分析任务
在一些需要同时考虑前后帧信息的任务(如视频中的动作识别)中,双向信息也能提供更全面的时间上下文。
双向循环神经网络通过并行计算正向和反向隐藏状态,并将它们合并为每个时间步的最终表示,使得每个时间步的输出不仅利用了过去信息,也利用了未来信息。以命名实体识别任务为例,双向RNN能够为每个单词提供全局上下文的特征,显著提升了序列标注的准确性。这种方法广泛应用于需要全局语境理解的自然语言处理、语音识别和视频分析任务中,成为提升序列模型性能的重要技术之一。