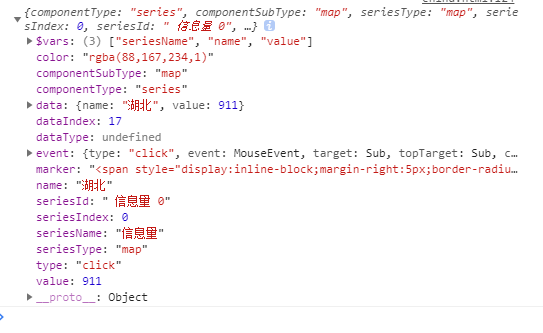
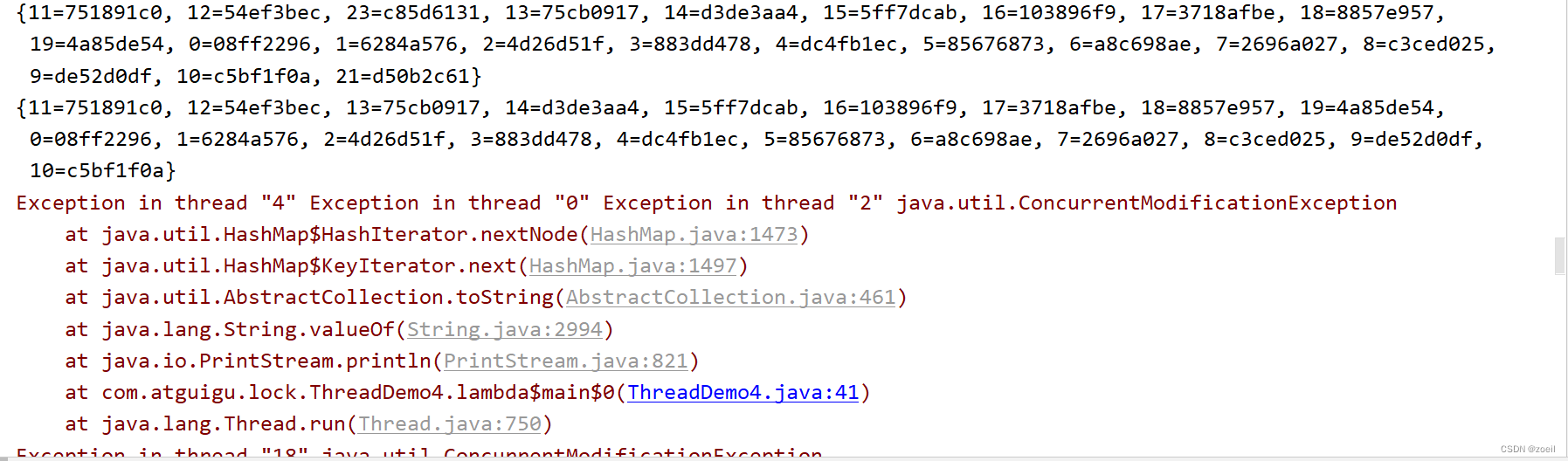
在SQL中,全外连接(full outer join)是一种无论是否匹配,都返回两张表中所有记录的连接:
不幸的是,MySQL不支持这种关联,我们必须以某种方式模拟它。但该如何操作呢?
在SQL中,同样的结果可以通过不同的方式实现,哪种方式最合适取决于个人喜好(或性能)。
但这一次这个问题有点争议,即使在StackOverflow上也不是每个人都同意,标记为正确的解决方案实际上并不是正确的。
假设我们有以下表格:
Customers:
| company_id | name |
|---|---|
| 1 | Abc Company |
| 2 | Noise Inc. |
| 3 | Mr. Smith |
Partners:
| company_id | name |
|---|---|
| 2 | Noise Inc. |
| 4 | The Pages |
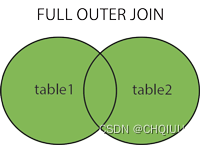
一个完整的外连接可以写成:
select
c.name, p.name
from
customers c full outer join partners p
on c.company_id = p.company_id
预期的结果是:
| name | name |
|---|---|
| Abc Company | |
| Noise Inc. | Noise Inc. |
| Mr. Smith | |
| The Pages |
为了得到相同的结果,我们必须结合左外连接查询:
select c.name, p.name
from
customers c left join partners p
on c.company_id = p.company_id
使用右外连接查询:
select c.name, p.name
from
customers c right join partners p
on c.company_id = p.company_id
(右连接不常见,因为它更难读,它相当于左连接,只是表的顺序发生了改变)。
我们可以使用UNION ALL子句将两个查询组合起来,但这将返回一些重复的行(连接成功的所有行将返回两次)。
然后我们可以使用UNION子句来删除重复项,但是如果其中一张表没有主键或唯一约束,或者所选列不是唯一的,那么它将失败。
我们还可以使用另一种方法:
select c.name, t.name
from
(select company_id from customers UNION
select company_id from partners) n
left join customers c on n.company_id = c.company_id
left join partners p on n.company_id = p.company_id
这通常是一个很好的解决方案,但如果我们允许一个或两个表中的company_id为NULL,则会失败(完整的外连接将返回这些行,而前一个不会)。
最通用的解决方案是这样的:
select c.name, p.name
from
customers c left join partners p
on c.company_id = p.company_id
union all -- 不要删除重复项
select c.name, p.name
from
customers c right join partners p
on c.company_id = p.company_id
where
c.company_id is null
如果源表中已经存在重复项,则不会删除。第二个查询的反连接模式确保我们没有引入新的重复的行。

![[保研/考研机试] KY207 二叉排序树 清华大学复试上机题 C++实现](https://img-blog.csdnimg.cn/9aceff213b5d4973a7e73264b6517849.png)