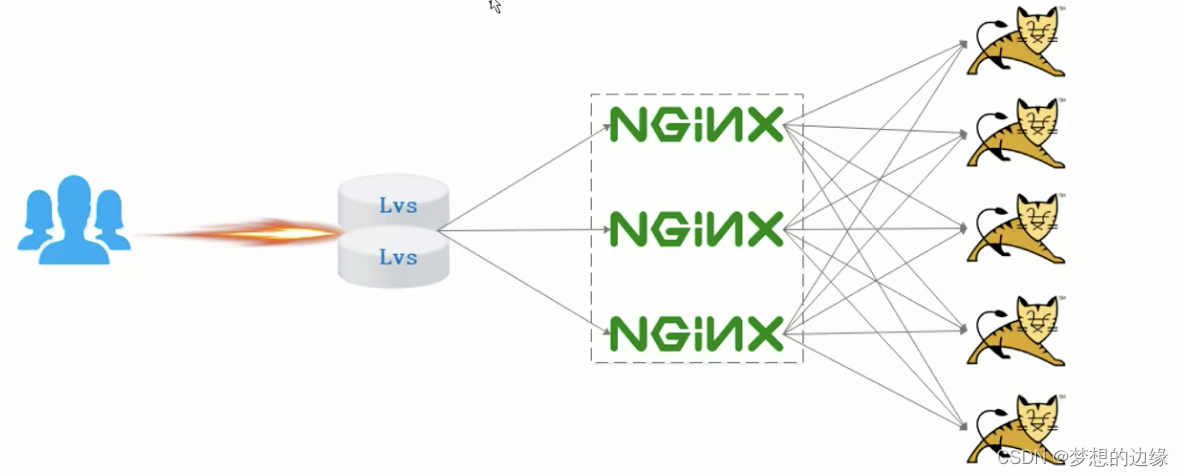
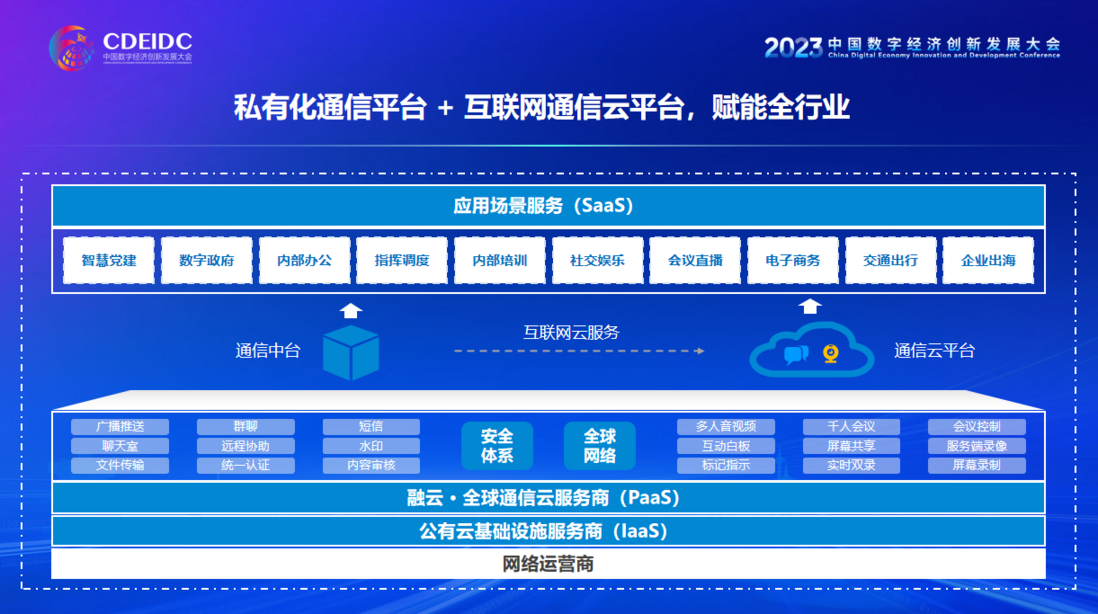
Keras和PyTorch是两个常用的深度学习框架,它们都提供了用于构建和训练神经网络的高级API。
Keras:
Keras是一个高级神经网络API,可以在多个底层深度学习框架上运行,如TensorFlow和CNTK。以下是Keras的特点和优点:
优点:
- 简单易用:Keras具有简洁的API设计,易于上手和使用,适合快速原型设计和实验。
- 灵活性:Keras提供了高级API和模块化的架构,可以灵活地构建各种类型的神经网络模型。
- 复用性:Keras模型可以轻松保存和加载,可以方便地共享、部署和迁移模型。
- 社区支持:Keras拥有庞大的社区支持和活跃的开发者社区,提供了大量的文档、教程和示例代码。
缺点:
- 功能限制:相比于底层框架如TensorFlow和PyTorch,Keras在某些高级功能和自定义性方面可能有所限制。
- 可扩展性:虽然Keras提供了易于使用的API,但在需要大量定制化和扩展性的复杂模型上可能会有限制。
- 灵活程度:Keras主要设计用于简单的流程,当需要处理复杂的非标准任务时,使用Keras的灵活性较差。
适用场景:
- 初学者:对于新手来说,Keras是一个理想的选择,因为它简单易用,有丰富的文档和示例来帮助快速入门。
- 快速原型设计:Keras可以快速搭建和迭代模型,适用于快速原型设计和快速实验验证。
- 常规计算机视觉和自然语言处理任务:Keras提供了大量用于计算机视觉和自然语言处理的预训练模型和工具,适用于常规任务的开发与应用。
PyTorch:
PyTorch是一个动态图深度学习框架,强调易于使用和低延迟的调试功能。以下是PyTorch的特点和优点:
优点:
- 动态图:PyTorch使用动态图,使得模型构建和调试更加灵活和直观,可以实时查看和调试模型。
- 自由控制:相比于静态图框架,PyTorch能够更自由地控制模型的复杂逻辑和探索新的网络架构。
- 算法开发:PyTorch提供了丰富的数学运算库和自动求导功能,适用于算法研究和定制化模型开发。
- 社区支持:PyTorch拥有活跃的社区和大量的开源项目,提供了丰富的资源和支持。
缺点:
- 部署复杂性:相比于Keras等高级API框架,PyTorch需要开发者更多地处理模型的部署和生产环境的问题。
- 静态优化:相对于静态图框架,如TensorFlow,PyTorch无法进行静态图优化,可能在性能方面略逊一筹。
- 入门门槛:相比于Keras,PyTorch对初学者来说可能有一些陡峭的学习曲线。
适用场景:
- 研究和定制化模型:PyTorch适合进行研究和实验,以及需要灵活性和自由度较高的定制化模型开发。
- 高级计算机视觉和自然语言处理任务:PyTorch在计算机视觉和自然语言处理领域有广泛的应用,并且各类预训练模型和资源丰富。
在前面的两篇文章中整体系统总结记录了Keras和PyTroch这两大主流框架各自开发构建模型的三大主流方式,并对应给出来的基础的实例实现,感兴趣的话可以自行移步阅读即可:
《总结记录Keras开发构建神经网络模型的三种主流方式:序列模型、函数模型、子类模型》
《总结记录PyTorch构建神经网络模型的三种主流方式:nn.Sequential按层顺序构建模型、继承nn.Module基类构建自定义模型、继承nn.Module基类构建模型并辅助应用模型容器来封装》
本文的主要目的就是想要基于真实业务数据场景来实地开发实践这三种不同类型的模型构建方式,并对结果进行对比分析。
首先来看下数据集:

这里模型结构的话可以自行构建设计层数都是没有关系的,我这里主要是参考了VGG的网络结构来搭建的网络模型,首先来看序列模型构建实现:
def initModel(h=100, w=100, way=3):
"""
列模型
"""
input_shape = (h, w, way)
model = Sequential()
model.add(
Conv2D(
64,
(3, 3),
strides=(1, 1),
input_shape=input_shape,
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(
Conv2D(
128,
(3, 2),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(
Conv2D(
256,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(
Conv2D(
512,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(
Conv2D(
512,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(820, activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(820, activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(numbers, activation="softmax"))
return model网络结构输出如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 100, 100, 64) 1792
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 50, 50, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 50, 50, 128) 49280
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 25, 25, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 25, 25, 256) 295168
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 12, 12, 256) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 12, 12, 512) 1180160
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 6, 6, 512) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 3, 3, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_1 (Dense) (None, 820) 3779380
_________________________________________________________________
dropout_1 (Dropout) (None, 820) 0
_________________________________________________________________
dense_2 (Dense) (None, 820) 673220
_________________________________________________________________
dropout_2 (Dropout) (None, 820) 0
_________________________________________________________________
dense_3 (Dense) (None, 2) 1642
=================================================================
Total params: 8,340,450
Trainable params: 8,340,450
Non-trainable params: 0
_________________________________________________________________接下来是函数模型代码实现,如下所示:
def initModel(h=100, w=100, way=3):
"""
函数模型
"""
input_shape = (h, w, way)
inputs = Input(shape=input_shape)
X = Conv2D(
64,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)(inputs)
X = Conv2D(
64,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)(X)
X = MaxPooling2D(pool_size=(2, 2))(X)
X = Conv2D(
128,
(3, 2),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)(X)
X = MaxPooling2D(pool_size=(2, 2))(X)
X = Conv2D(
256,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)(X)
X = MaxPooling2D(pool_size=(2, 2))(X)
X = Conv2D(
512,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)(X)
X = MaxPooling2D(pool_size=(2, 2))(X)
X = Conv2D(
512,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)(X)
X = MaxPooling2D(pool_size=(2, 2))(X)
X = Flatten()(X)
X = Dense(820, activation="relu")(X)
X = Dropout(0.1)(X)
X = Dense(820, activation="relu")(X)
X = Dropout(0.1)(X)
outputs = Dense(2, activation="sigmoid")(X)
model = Model(input=inputs, output=outputs)
return model
模型结构信息输出如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 100, 100, 3) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 100, 100, 64) 1792
_________________________________________________________________
conv2d_7 (Conv2D) (None, 100, 100, 64) 36928
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 50, 50, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 50, 50, 128) 49280
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 25, 25, 128) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 25, 25, 256) 295168
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 12, 12, 256) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 12, 12, 512) 1180160
_________________________________________________________________
max_pooling2d_9 (MaxPooling2 (None, 6, 6, 512) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
max_pooling2d_10 (MaxPooling (None, 3, 3, 512) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_4 (Dense) (None, 820) 3779380
_________________________________________________________________
dropout_3 (Dropout) (None, 820) 0
_________________________________________________________________
dense_5 (Dense) (None, 820) 673220
_________________________________________________________________
dropout_4 (Dropout) (None, 820) 0
_________________________________________________________________
dense_6 (Dense) (None, 2) 1642
=================================================================
Total params: 8,377,378
Trainable params: 8,377,378
Non-trainable params: 0
_________________________________________________________________最后是子类模型代码实现,如下所示:
class initModel(Model):
"""
子类模型
"""
def __init__(self):
super(initModel, self).__init__()
self.conv2d1 = Conv2D(
64,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
self.conv2d2 = Conv2D(
64,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
self.pool1 = MaxPooling2D(pool_size=(2, 2))
self.conv2d3 = Conv2D(
128,
(3, 2),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
self.pool2 = MaxPooling2D(pool_size=(2, 2))
self.conv2d4 = Conv2D(
256,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
self.pool3 = MaxPooling2D(pool_size=(2, 2))
self.conv2d5 = Conv2D(
512,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
self.pool4 = MaxPooling2D(pool_size=(2, 2))
self.conv2d6 = Conv2D(
512,
(3, 3),
strides=(1, 1),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
self.pool5 = MaxPooling2D(pool_size=(2, 2))
self.flatten = Flatten()
self.dense1 = Dense(820, activation="relu")
self.dropout1 = Dropout(0.1)
self.dense2 = Dense(820, activation="relu")
self.dropout2 = Dropout(0.1)
self.dense3 = Dense(2, activation="sigmoid")
def call(self, inputs):
"""
回调
"""
x = self.conv2d1(inputs)
x = self.conv2d2(x)
x = self.pool1(x)
x = self.conv2d3(x)
x = self.pool2(x)
x = self.conv2d4(x)
x = self.pool3(x)
x = self.conv2d5(x)
x = self.pool4(x)
x = self.conv2d6(x)
x = self.pool5(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dropout1(x)
x = self.dense2(x)
x = self.dropout2(x)
y = self.dense3(x)
return y
完成模型的搭建之后就可以加载对应的数据集开始训练模型了,数据集加载仿照mnist数据集的形式即可,这里就不再赘述了,在我之前的文章中也都有对应的实现,如下所示:
# 数据加载
X_train, X_test, y_train, y_test = loadData()
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
# 数据归一化
X_train /= 255
X_test /= 255
# 数据打乱
np.random.seed(200)
np.random.shuffle(X_train)
np.random.seed(200)
np.random.shuffle(y_train)
np.random.seed(200)
np.random.shuffle(X_test)
np.random.seed(200)
np.random.shuffle(y_test)
# 模型
model=initModel()
model.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"])模型评估测试可视化实现如下所示:
# 可视化
plt.clf()
plt.plot(history.history["acc"])
plt.plot(history.history["val_acc"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epochs")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(saveDir + "train_validation_acc.png")
plt.clf()
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epochs")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(saveDir + "train_validation_loss.png")
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1] * 100))接下来看下结果:
【序列模型】

【函数模型】

【子类模型】
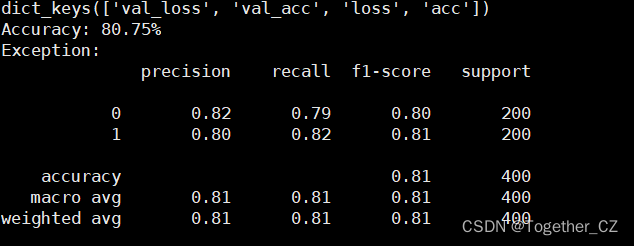
结果上有略微的差异,这个应该跟训练有关系。
可视化结果如下所示:

其实三种方法也是本质一样的,只要熟练熟悉了某一种,其他的构建方式都是可以基于当前的构建方式转化完成的。没有绝对唯一的选择,只有最适合自己的选择。