论文引用
此篇阅读笔记与思考主要针对以下两篇论文:
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
Transformer Feed-Forward Layers Are Key-Value Memories
本文将讨论第一篇论文所引发的思考(第一篇论文的详细解读可以参考这里[1]),再对第二篇论文的实验和方法进行梳理总结。同时基于第二篇论文,北京大学和微软的几位学者也发表了相关的论文论述了如何寻找transformer模型里的知识神经元的一些方法,感兴趣的同僚可以看看。论文如下:
Knowledge Neurons in Pretrained Transformers
语言模型学习到的是形式还是意义
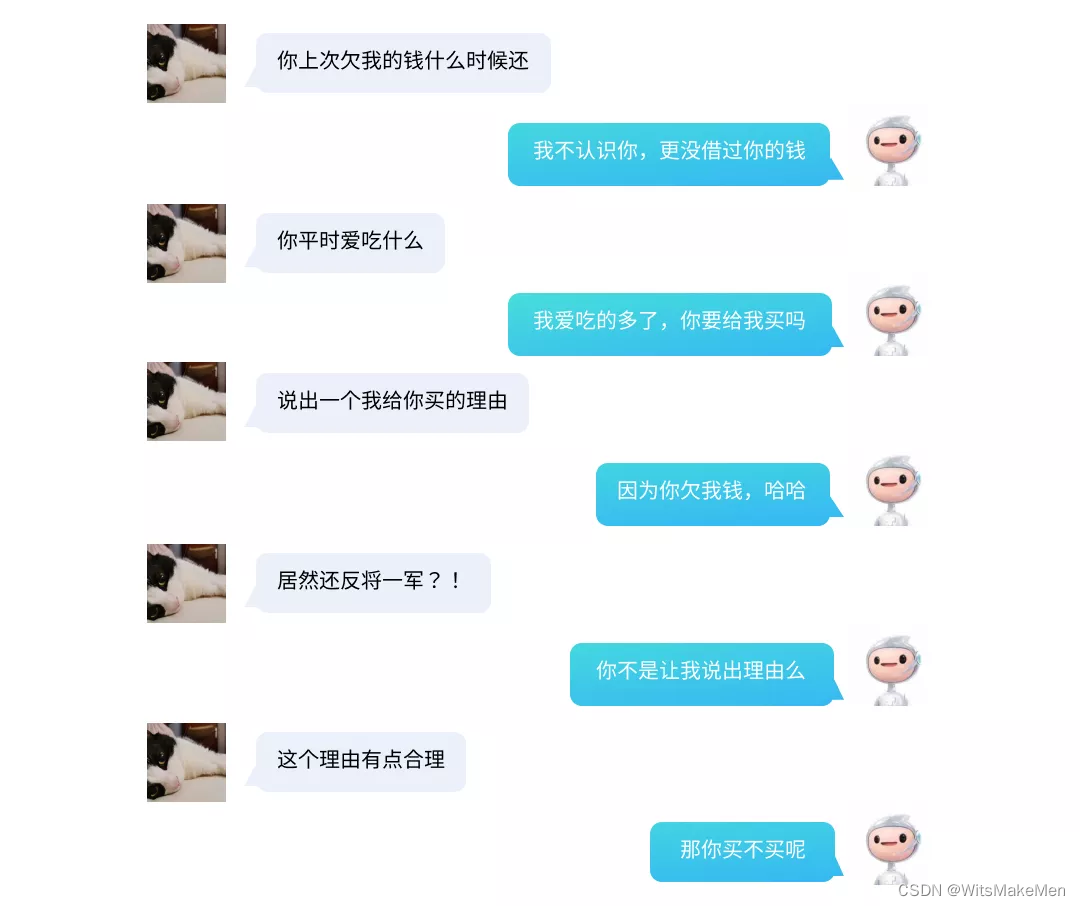
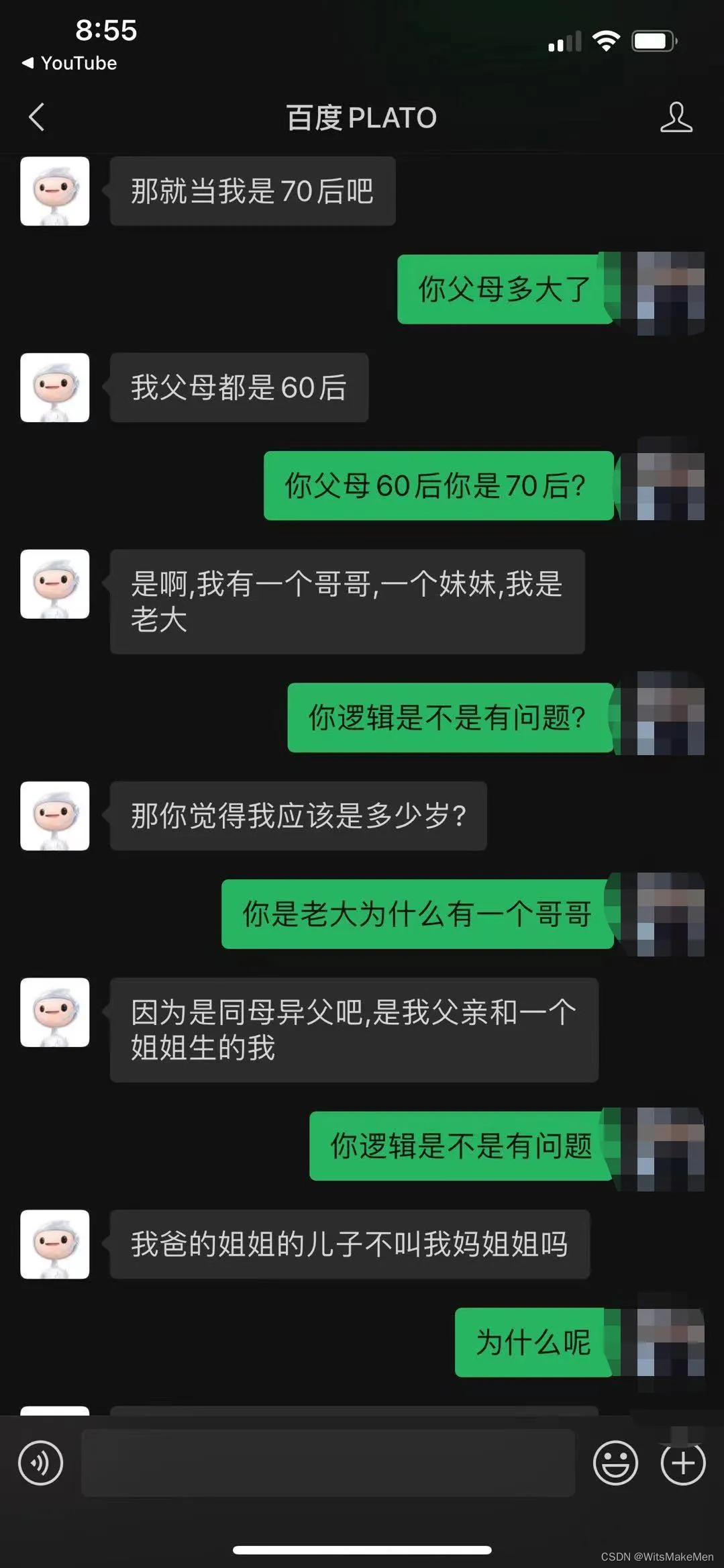
在去年ACL2020的会议上一篇最佳主题论文[2]提出了灵魂拷问,即语言模型学习到的是我们语言的形式还是其真正的含义,而我们对预训练语言模型是否给予了过高的期望?从表象上来看,大规模预训练的语言模型表现出了惊人的学习能力,其生成的语句行文通畅,在某些具体的下游任务上表现甚至超越了人类。但是,在对语言模型提出包含逻辑的问题,或者要求给出具体的建议时,模型往往牛头不对马嘴。举个例子,百度不久前(2021-Oct)发布了百亿级参数的自然语言对话模型Plato-xl[3],在多个对话领域任务达到榜一水平。毫无疑问是当下的SOTA。其对话效果对公众开放测试。在开放域的闲聊中,如链接所示的例子(下图一)里,似乎完全可以说是通过了图灵测试,难以判断谈话对象是机器人还是人类。但一旦涉及到了逻辑,深究词语背后的指代与关系时,模型的表现之差让人瞠目。下图二是我的朋友出于好奇在微信端口测试模型时的对话:
在灵魂拷问这篇论文[2]里提到了一个经典的哲学思维实验:由美国哲学家John Searle在1980年提出。该实验称为中文房间思维实验(The Chinese Room Argument)。实验假设如果一个不懂中文的人走进一个写满中文语言规则公式的房间,仅通过纸条和外界的中文使用者交流。如果该人能够如计算机般准确地根据规则排列操纵那些对它来说陌生如同乱码的字符,来组织回答,该人也可以表现得如同一个中文为母语的人。但是对于该人来说,实际上其并不理解和掌握中文。类比于该实验,最近十年自然语言学界的发展,只不过是将语言从离散的字符,经过大规模文本的预训练构建出低维的稠密分布式向量表示,通过精心设计的损失函数建模语言模型。究其本质,深度学习依然属于经验主义的统计学习范畴,其学习到的毫无疑问只是语言的形式(form)。直观上来说一个自然语言的输入在进入模型后,模型的一系列前向计算就类似于中文房间内的人按照规则对中文字符集进行排列,生成最终的答案。而如论文[2]指出,人类使用自然语言时的目的在于交流,其字符后往往对应着某种概念或实体。比如当我们说开窗时,对于窗这个实体,人类会对其功能,外观有相对固定的定义,对其与其他实体或概念(如墙如天气如室内空气的浑浊程度)的联系有初步的判断与假设。而这些在语言的形式(form,即一些任意形状的字符)上是无法体现的。目前我们大部分的语言模型对实体世界缺少关注(多模态训练和知识图谱的信息可以看作在尝试解决这个问题,但目前融入的方法仍然十分局限)。而如果模型缺乏对实体关系的学习,当前的统计学习范式或许将永远无法真正理解人类的语言。正如上图百度的Plato-XL模型所示,其对字符后所代表的实体间关系一无所知。
我之所以要将本文开头的这两篇论文放在一起讨论,是因为把transformer模型类比于记忆神经网络这篇论文[4]为我们理解目前的大规模预训练模型是否真正理解语言的本质提供了一个角度。我认为该论文的实验,很大程度上佐证了现在的SOTA语言模型很大程度上仍然只是个关注语言形式的模式识别模型。 以下为该论文的详细阅读笔记
一个transformer架构的模型里,占大头的参数除了词嵌入层和多头注意力层外,就是前馈神经网络层了。前馈层占了模型大约三分之二的参数量,但关于其在模型内的作用的探索和解释依然较为稀缺,论文[4]针对该问题提出了以下几个论点:
1.论证了transformer架构下的前馈神经网络在形式上高度类似于记忆神经网络。并且其第一层前馈网络对应键值对(KEY-VALUE)记忆网络里的KEY,而第二层前馈网络对应着VALUE。
2.论证了每个KEY与一个人类可理解的输入模式高度相关,每个VALUE则能激发特定的输出分布。VALUE对应的KEY所关联的模式句子的下一个词会以高概率值出现在该分布中(尤其是在模型高层里)。
3.论证了前馈网络的输出相当于合并了数以千百计的激活记忆分布,最后形成全新的分布。该分布的预测会随着每层里的残差链接被不断校正,直到最后一层。
记忆网络与前馈网络的相似性
首先我们观察以下的记忆网络,给定输入x和键k,我们有
。我们定义记忆网络是以向量内积的指数形式建模键(key)对于输入(x)的条件概率,我们可以得到记忆网络的整体是对每个键值对的加权求和。类似于注意力机制的表示。

而我们再观察前馈神经网络的表达式(1)与记忆网络的表达式(2),我们会发现除了transformer的前馈网络里的激活函数与记忆网络不同外,其形式高度接近。
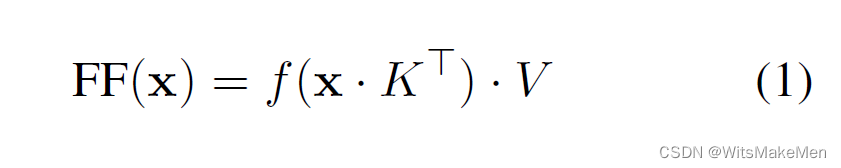
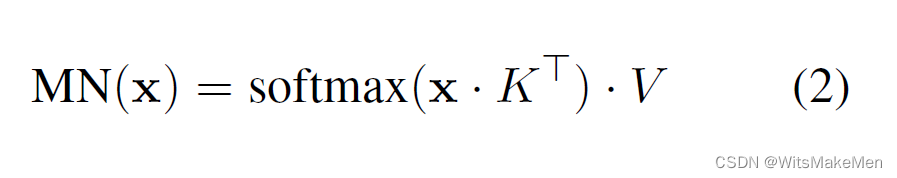
那么问题来了,如果我们假设前馈网络可以看作记忆网络的话,那么其对应的键和值分别是什么呢?作者设计了以下几个精巧的实验探究:
前馈网络的键捕捉了输入的某种模式(pattern)
如本笔记开篇的总结2里所说,作者认为前馈网络的键捕捉了输入的某种模式,并且进一步假设记忆网络里储存的模式来源于训练数据。为此,作者设计了以下实验:对于一个基于WikiText-103文本集训练的transformer, 计算文本里每个句子的前缀的向量表示,将其与某个给定的键向量做计算得到每个句子前缀的系数,最后取前t个系数最大的句子前缀观测是否存在某种模式特征。
具体来说,对于某个特定的L层的第i个隐层键向量
,我们计算每个句子从0到j个单词所组成的前缀在第L层的表示
与键向量的记忆系数
,最后取top-t个系数最大的句子来观察。
作者找了些NLP的博士生来当苦力标注了一批键值对应的句子池,要求模式必须重复三次以上,可描述,并且包含浅表模式(重复词句n-gram)或者语义模式(多次重复的主题)。作者发现每个键向量至少对应一种人类可解读的模式,并且低层键向量趋向于捕捉浅显的模式,而高层的键向量趋向于捕捉抽象的语义模式!这个发现类似于CNN里底层趋向于捕捉显示的图像特征而高层趋向于捕捉抽象的特征。也类似于ELMO等论文在NLP学界的发现。

同时,作者继续分析了模式和键值间的关系。作者随机采样了一批键向量,对于其对应的TOP-T句子对,删除头,或尾或任一位置的词语,观测对于记忆系数的影响。实验发现,底层的浅表模式对移去尾部词比移去头部词,相较于高层键值来说,其记忆系数的影响更敏感。佐证了高层和底层关注的模式抽象层次不同的结论。
记忆网络的值向量表示的是分布

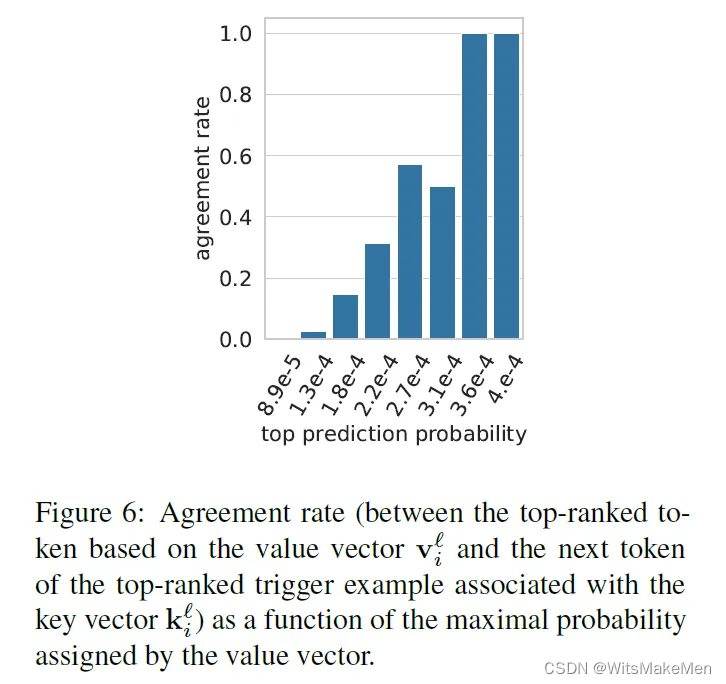
低层的低重合率,低最大概率可能由于其并不与高层分享同样的词嵌入空间(即不遵循前面作者提出的简单假设)。但实验进行到这一步,我们仍能合理地推断出,记忆网络里的值向量储存的信息与如何根据输入的模式来预测下一个词高度相关。究其根本,深度学习无非是经验主意里的统计学派的另一发展高峰。我认为其并没有摆脱模式识别和统计学习的范畴。
记忆聚合
截至目前,作者讨论的依然是某个特定的键值对。但我们知道一个记忆网络是所有值向量的加权(记忆系数)求和(并加上偏置项)。那么如果值向量表示的是在词空间的分布,那么这些信息是如何聚合到一个最终分布的呢?
作者设计了以下实验:观察模型每一层的最终分布所预测的最高概率词,与该层的值向量分布所预测的最高概率词的重合情况。发现对于从验证集(注意此处是验证模型推断时的分布,故不再继续从训练集中采样)里所随机采样的4000条数据,至少有大约百分之六十八的数据,每一层的预测词与该层的所有值向量预测词没有任何重合。对所有测试数据来说,在模型的低层里,不重合率更高。而对于那些层预测词和某个值向量预测此重合的情况,大约六成是常见的停顿词,并且大约百分之四十三的数据是少于五个词的输入。这可能说明简单的停顿预测可能不需要多层记忆的聚合。并且实验证明层的预测多数是多个记忆分布的聚合,而非任一单一的值向量分布。
模型层间的修正
我们知道每一层的输出是其值向量分布的聚合,但同时一个前馈网络的输出还包括了来自前馈网络之前的残差信息。那么这些残差链接起到了怎样的作用呢?
作者设计了四个实验。第一个实验探究每一层的残差向量所对应的预测分布的最大概率词与整个模型的预测分布的最大概率词的重合率。第二个实验探究模型的预测分布中最大概率词在每一层的残差向量所对应的预测分布里的概率值。在这两个实验里都观察到了类似的趋势。如下两图所示,即随着模型层层递进,模型的最终预测越来越确定,且概率值越来越大。
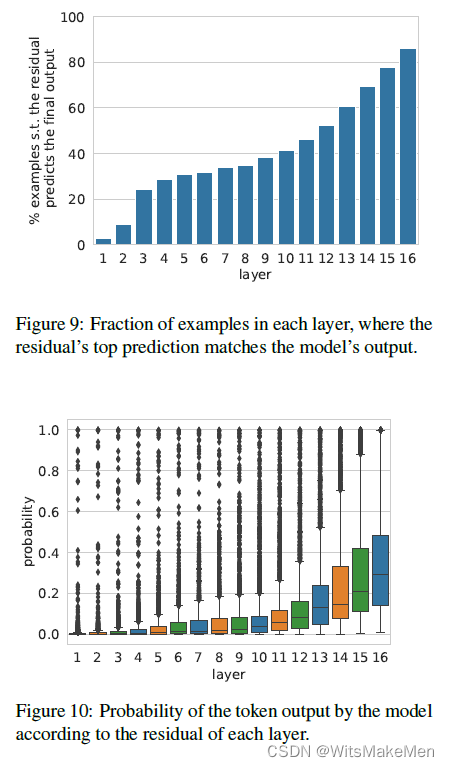
作者同时也检测了层的前馈行为改变了残差分布的最高预测词结果的频率。检测时重点关注了前馈网络改变残差的预测是否将预测更正为最后的模型预测,还是改为了既非残差的预测也非模型的最终预测。实验结果显示,大部分时候,残差的最高预测词是模型的最终预测词(如该节的第一个实验所示)。而在大部分这种情况里,前馈网络的输出分布的最高预测词都和残差的最高预测词不同。并且前馈分布融入了残差后的分布最高预测词极少保留为前馈分布或残差分布的最高预测词。这个观测现象和前面的记忆聚合章节观测到的现象一致。最后,作者随机挑出了100个模型最后一层里残差分布和前馈分布不同的例子。发现聚合的新分布的最高预测词在百分之六十六的情况下语义发生了剧变,只有百分之三十四的情况新预测词语义与原预测词接近。说明前馈网络是持续不断地更新残差的分布,即使在最后一层。
总结与可继续探讨的内容
这篇文章的所有实验都非常的精巧,也非常的有指向性。笔者认为如同该论文所揭示一般,基于transformer架构的大规模预训练语言模型依然是基于统计的一种模式识别方法。但从逻辑的角度来讲,论文揭示了transformer类语言模型里的一个子部分的其中一种特性,为我们了解该类语言模型的整体作用机制提供了一种角度。但语言模型是否仅拥有记忆的特征,其是否存在其他特性,如推理或联想类比等。这些部分的能力是否可以(或已经)通过其他子部分联合体现?目前来看,笔者认为未融合其他先验所预训练的transformer类语言模型还未展现出相关潜力。而人工智能或者说自然语言处理的未来,大概率将着眼于如何深层次地将各种世界知识,认知知识,专业知识等融入进来。
参考
^ACL 2020 | 最佳主题论文奖“ 迈向NLU:关于数据时代的意义、形式和理解 https://www.aminer.cn/research_report/5f16a5e821d8d82f52e5a2f8
^abcClimbing towards NLU: On Meaning, Form, and Understanding in the Age of Data https://aclanthology.org/2020.acl-main.463.pdf
^「比人还会聊天」百度PLATO对话机器人开放体验 https://ai.baidu.com/support/news?action=detail&id=2630
^abTransformer Feed-Forward Layers Are Key-Value Memories https://arxiv.org/abs/2012.14913