文章目录
- 前言
- 1.IK分词器
- 2.pingying分词器
- 一、ELK添加中文分词器插件
- 1.IK分词器测试
- 1.1 文件准备
- 1.2 测试
- 2.pingying分词器测试
- 2.1 文件准备
- 2.2 测试
- 2.2.1 单个测试
- 2.2.2 多个测试
- 2.2.3 短语查询测试
- 2.2.3.1 medcl2索引
- 2.2.3.2 medcl3索引
前言
分词器的作用是把一段文本中的词按一定规则进行切分。对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的分词器。
在创建索引时会用到分词器,在搜索时也会用到分词器,这两个地方要使用同一个分词器,否则可能会搜索不出结果。
1.IK分词器
IK 分词器地址:https://github.com/medcl/elasticsearch-analysis-ik
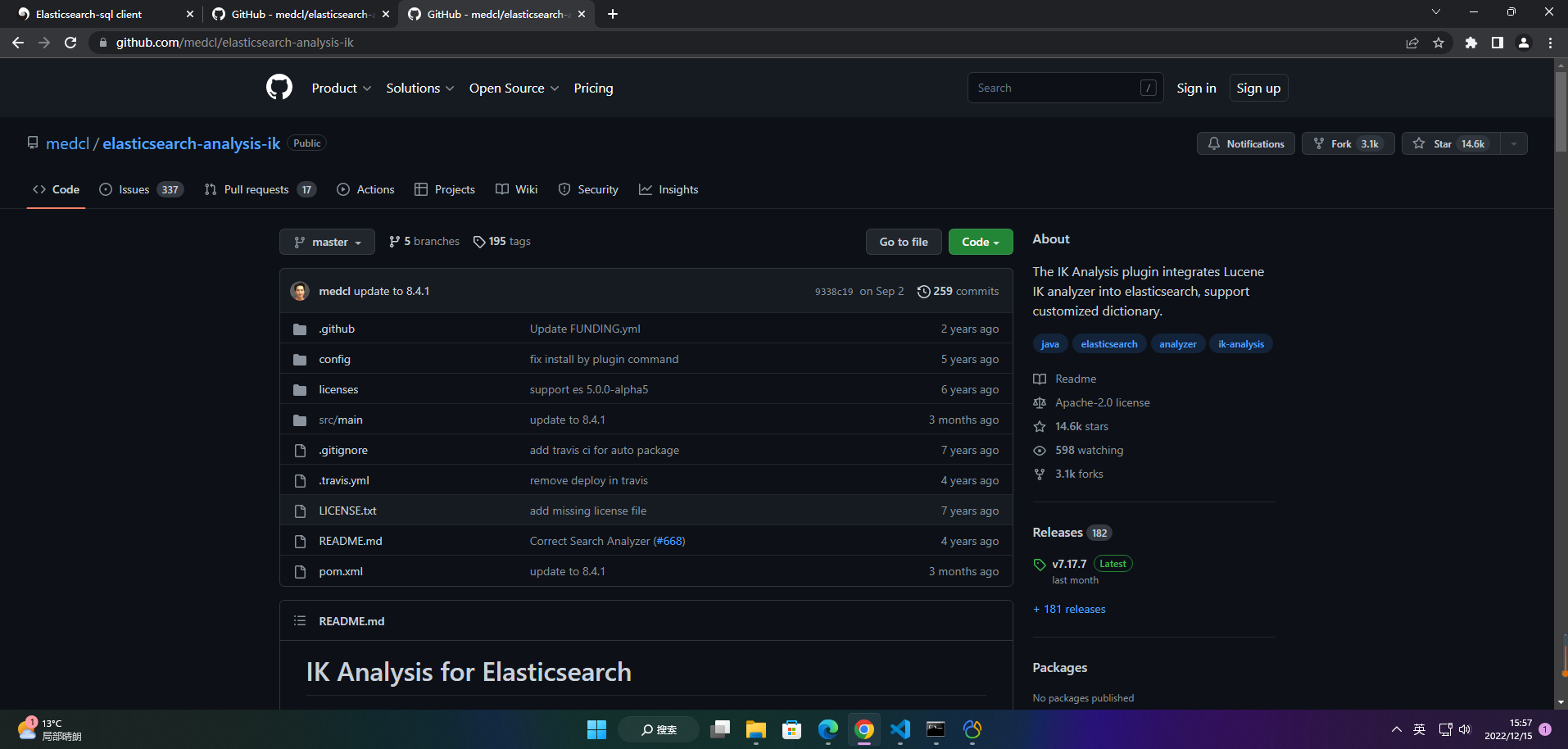
IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.15.2/elasticsearch-analysis-ik-7.15.2.zip
2.pingying分词器
pingying Github地址: https://github.com/medcl/elasticsearch-analysis-pinyin
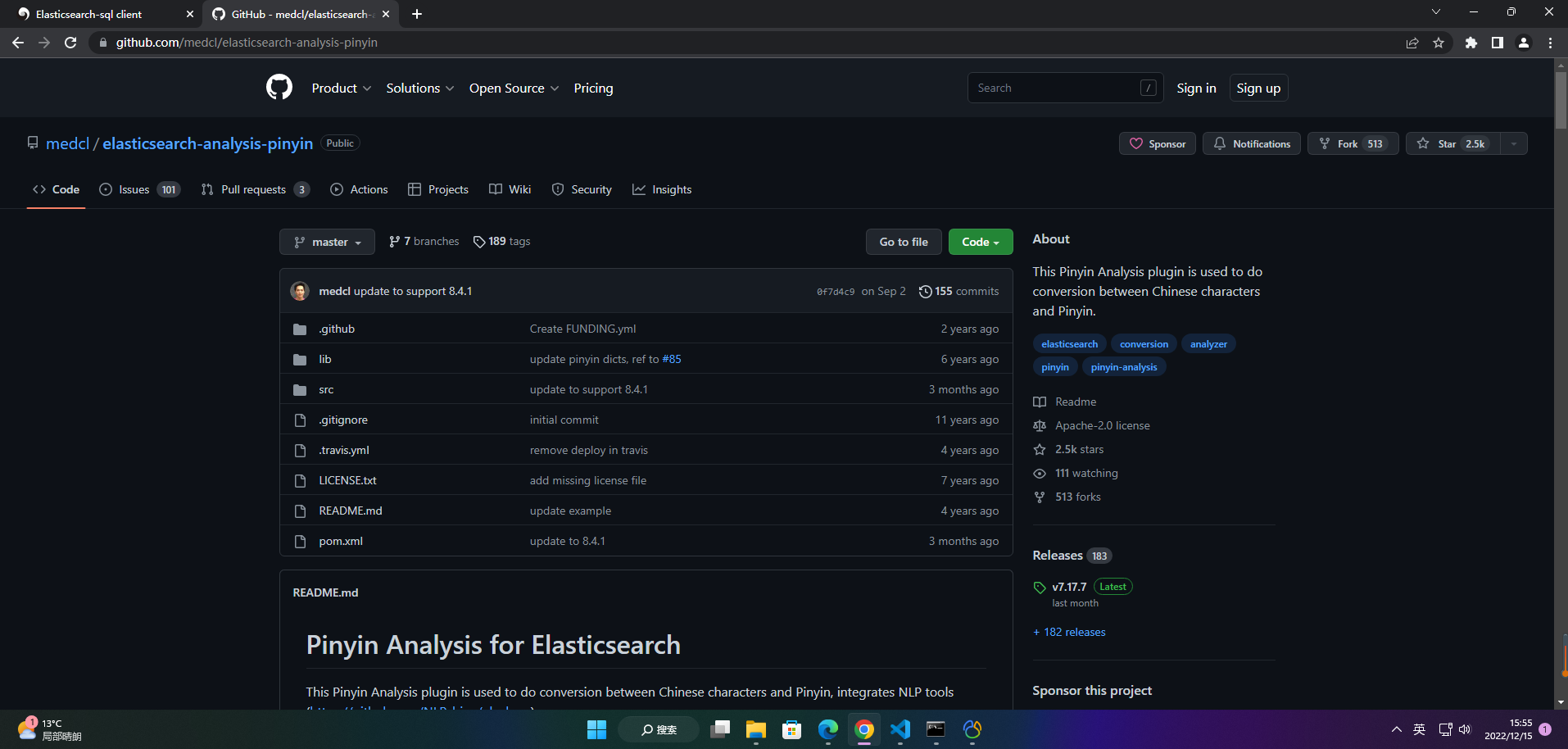
pinyin分词器下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.15.2/elasticsearch-analysis-pinyin-7.15.2.zip
一、ELK添加中文分词器插件
1.IK分词器测试
1.1 文件准备
把下载好的IK分词器解压到plugins文件夹
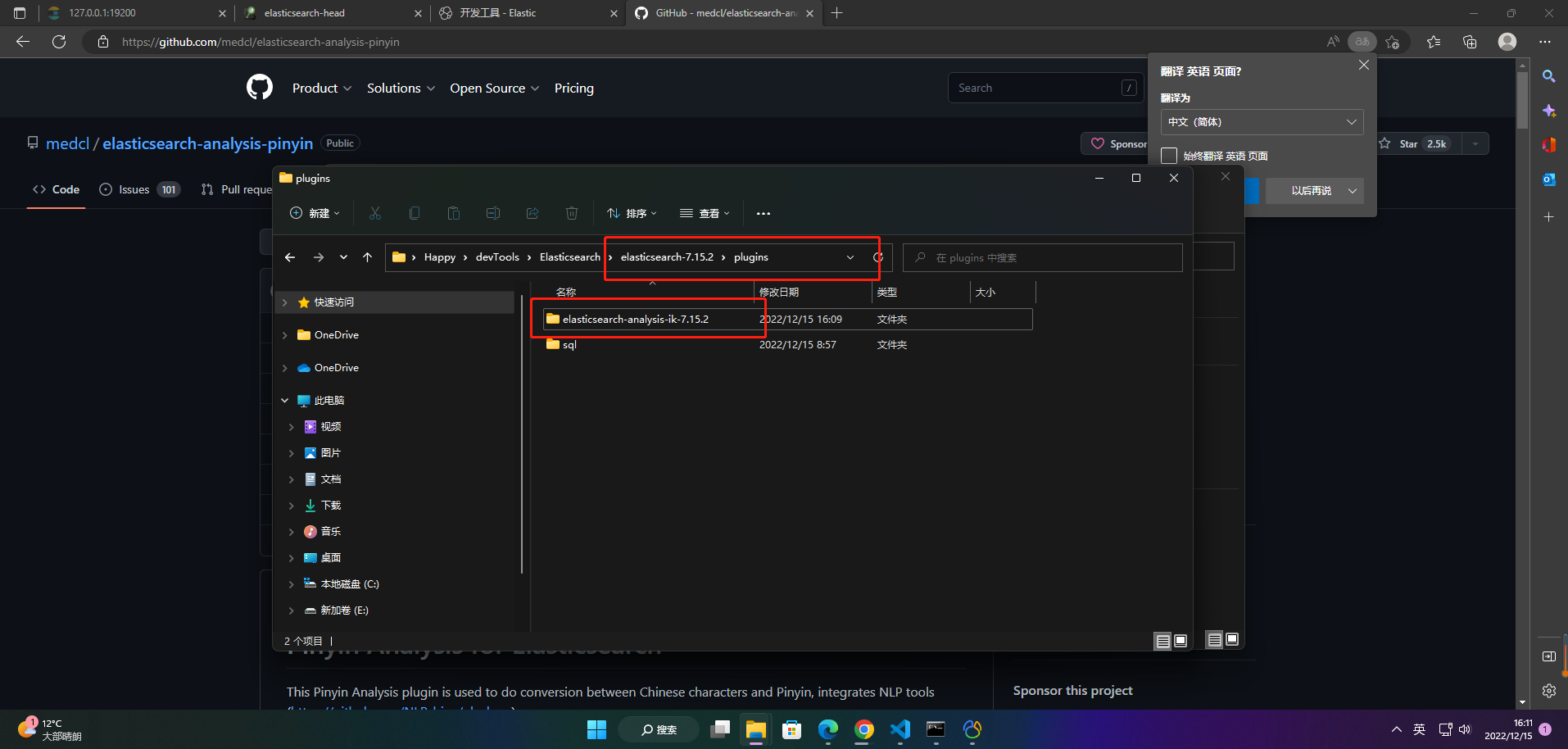
重启Elasticsearch服务
1.2 测试
1、创建索引
#创建映射
post index/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
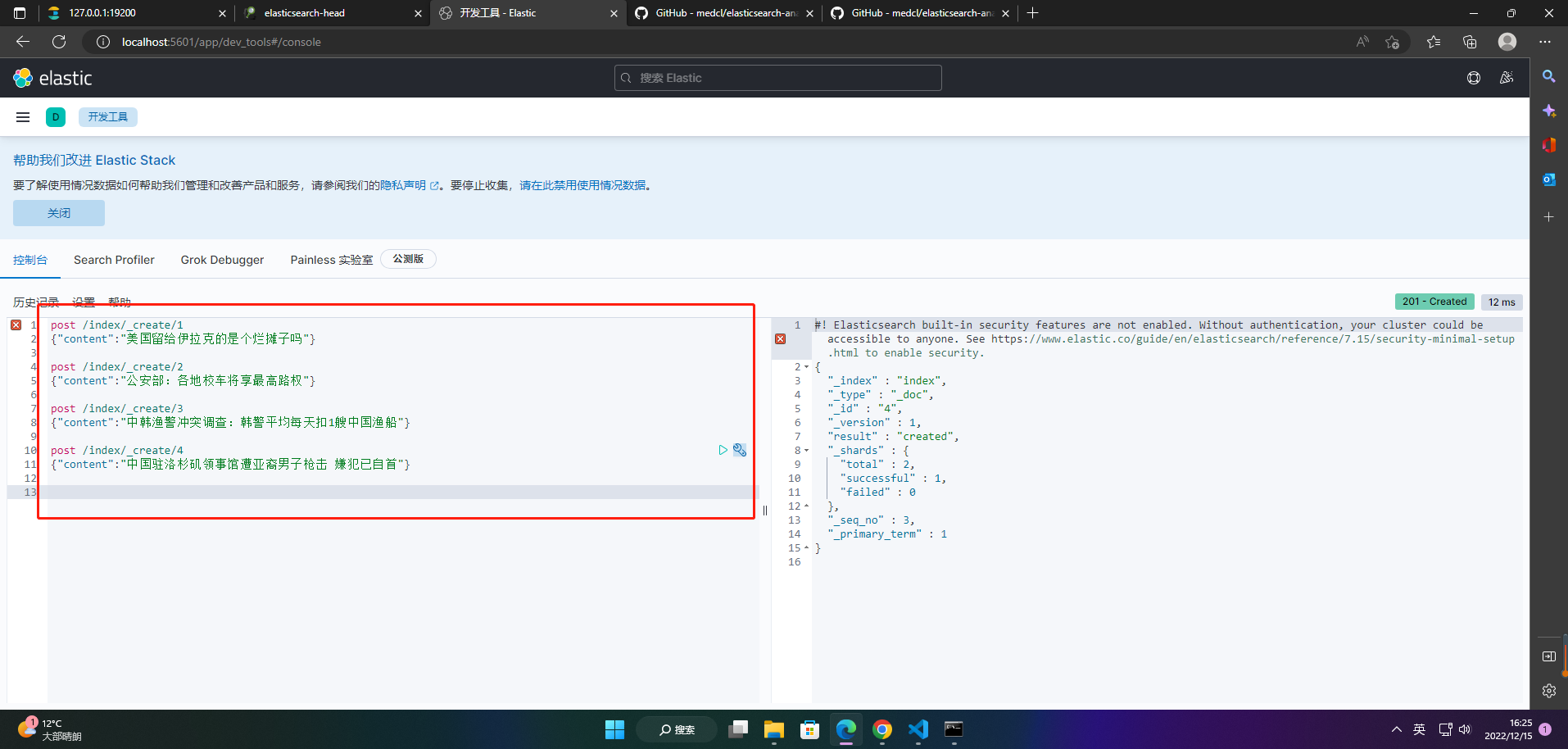
2、添加索引数据
post /index/_create/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
post /index/_create/2
{"content":"公安部:各地校车将享最高路权"}
post /index/_create/3
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
post /index/_create/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
3、查询索引数据
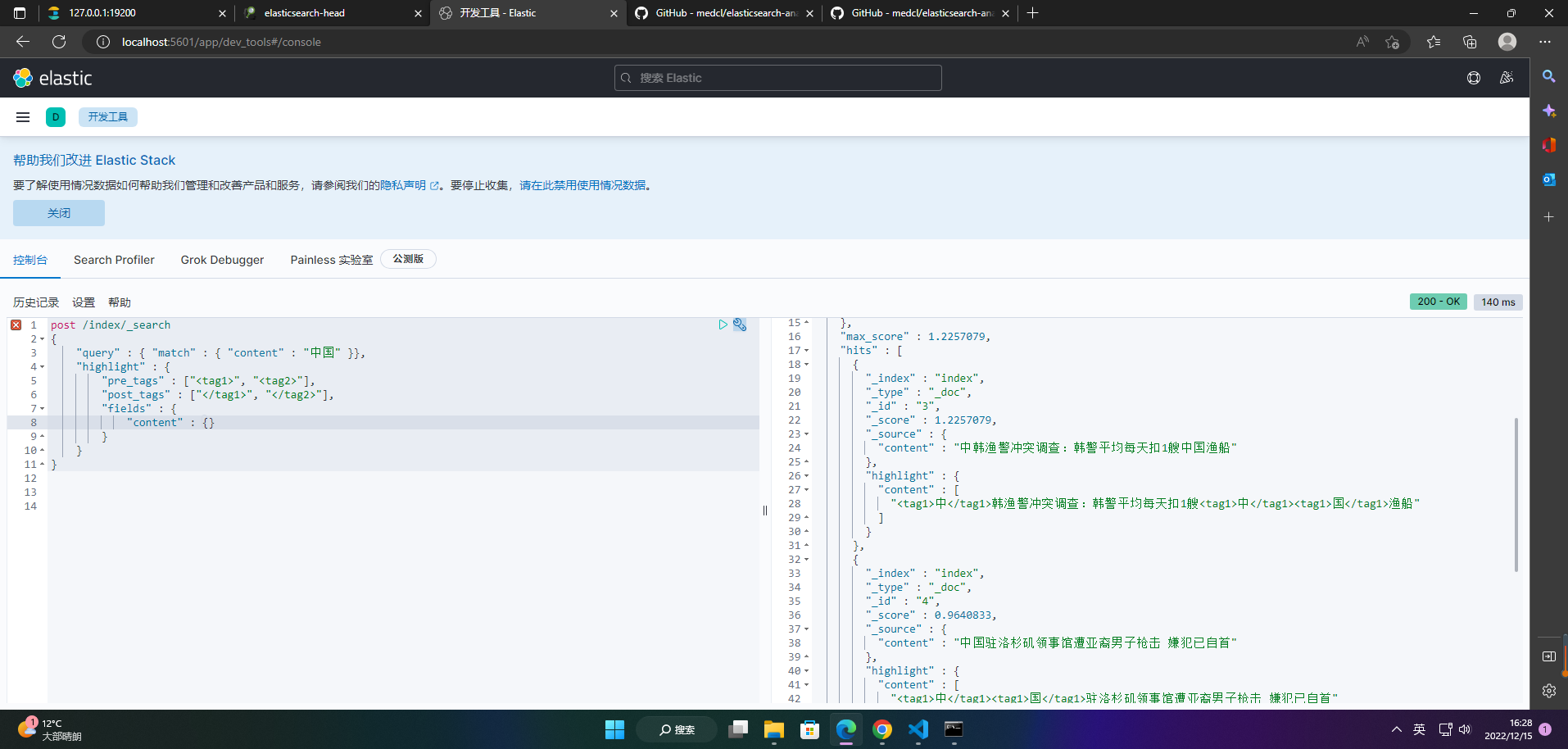
post /index/_search
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
2.pingying分词器测试
2.1 文件准备
把下载好的pingying分词器解压到plugins文件夹
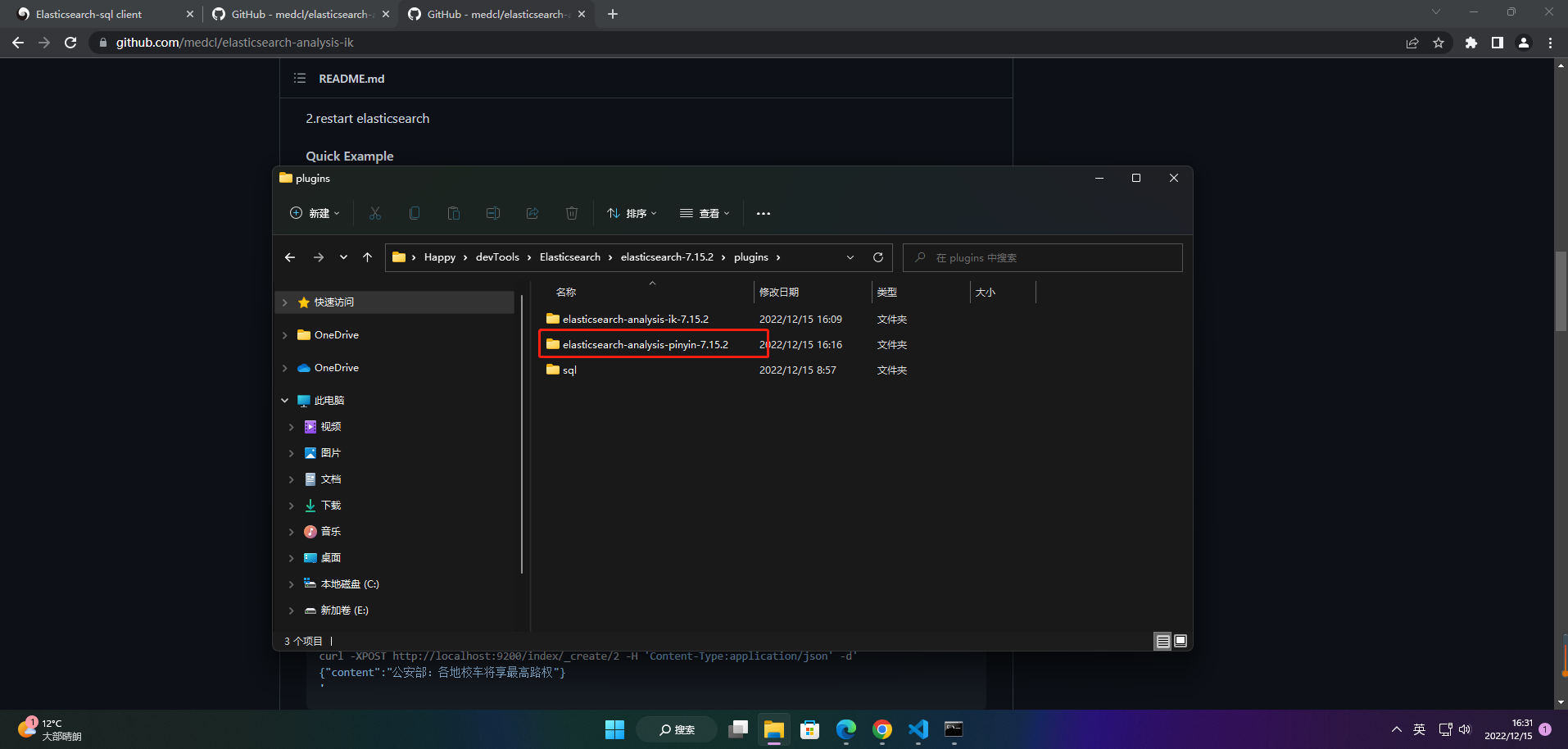
重启Elasticsearch服务
2.2 测试
2.2.1 单个测试
1、创建索引
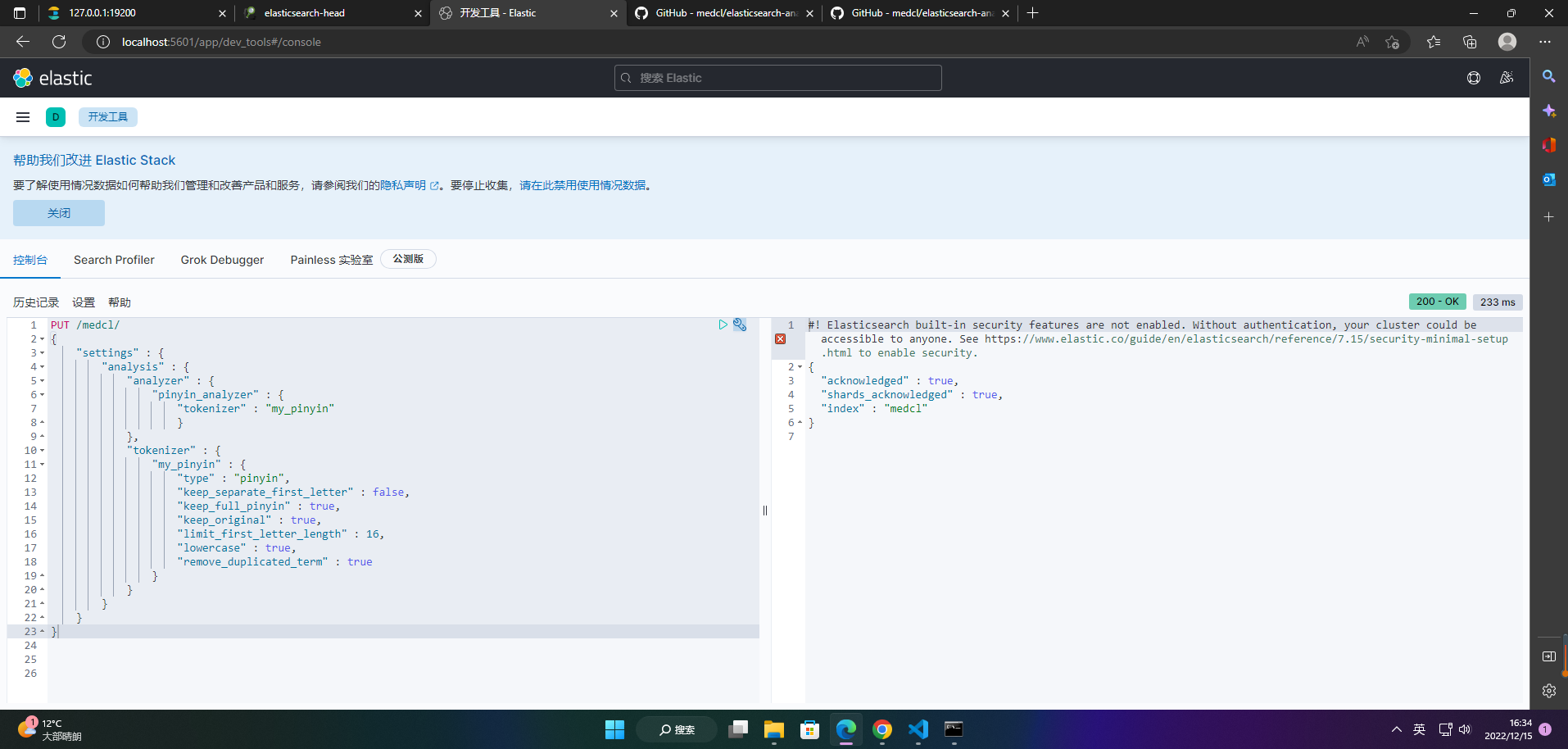
PUT /medcl/
{
"settings" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
}
}
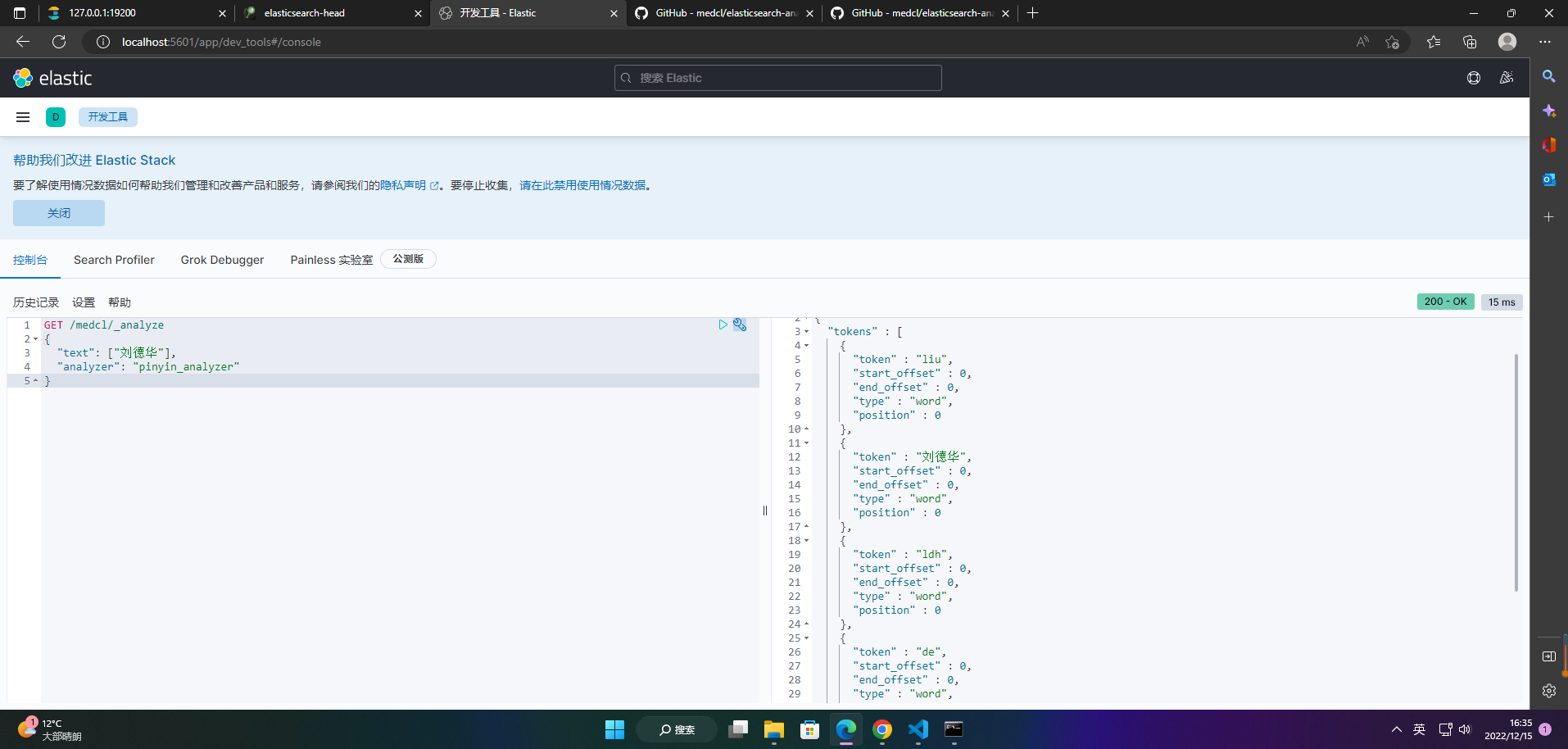
2、测试拼音分词器效果
GET /medcl/_analyze
{
"text": ["刘德华"],
"analyzer": "pinyin_analyzer"
}
3、创建映射
POST /medcl/_mapping
{
"properties": {
"name": {
"type": "keyword",
"fields": {
"pinyin": {
"type": "text",
"store": false,
"term_vector": "with_offsets",
"analyzer": "pinyin_analyzer",
"boost": 10
}
}
}
}
}
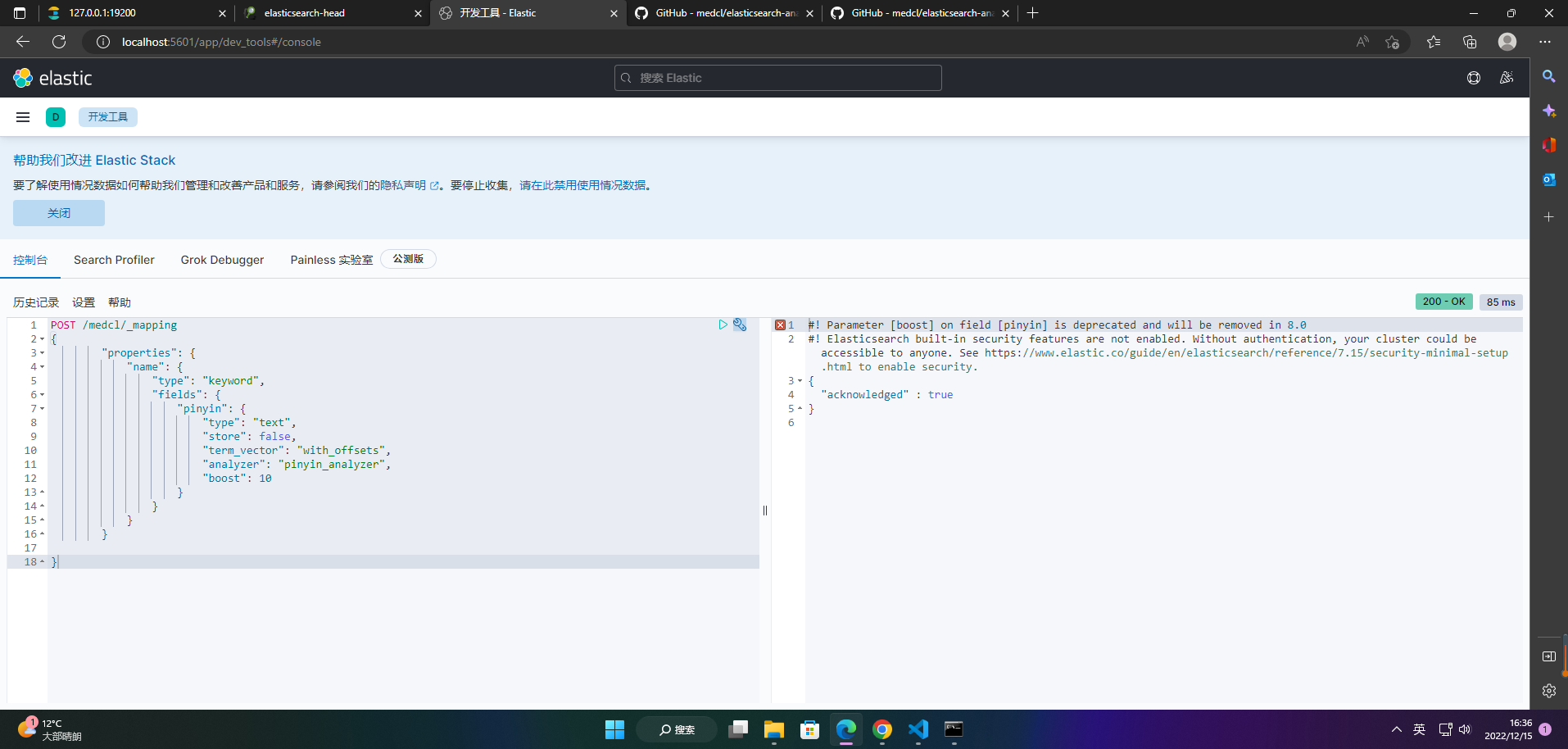
4、添加索引数据
POST /medcl/_create/andy
{"name":"刘德华"}
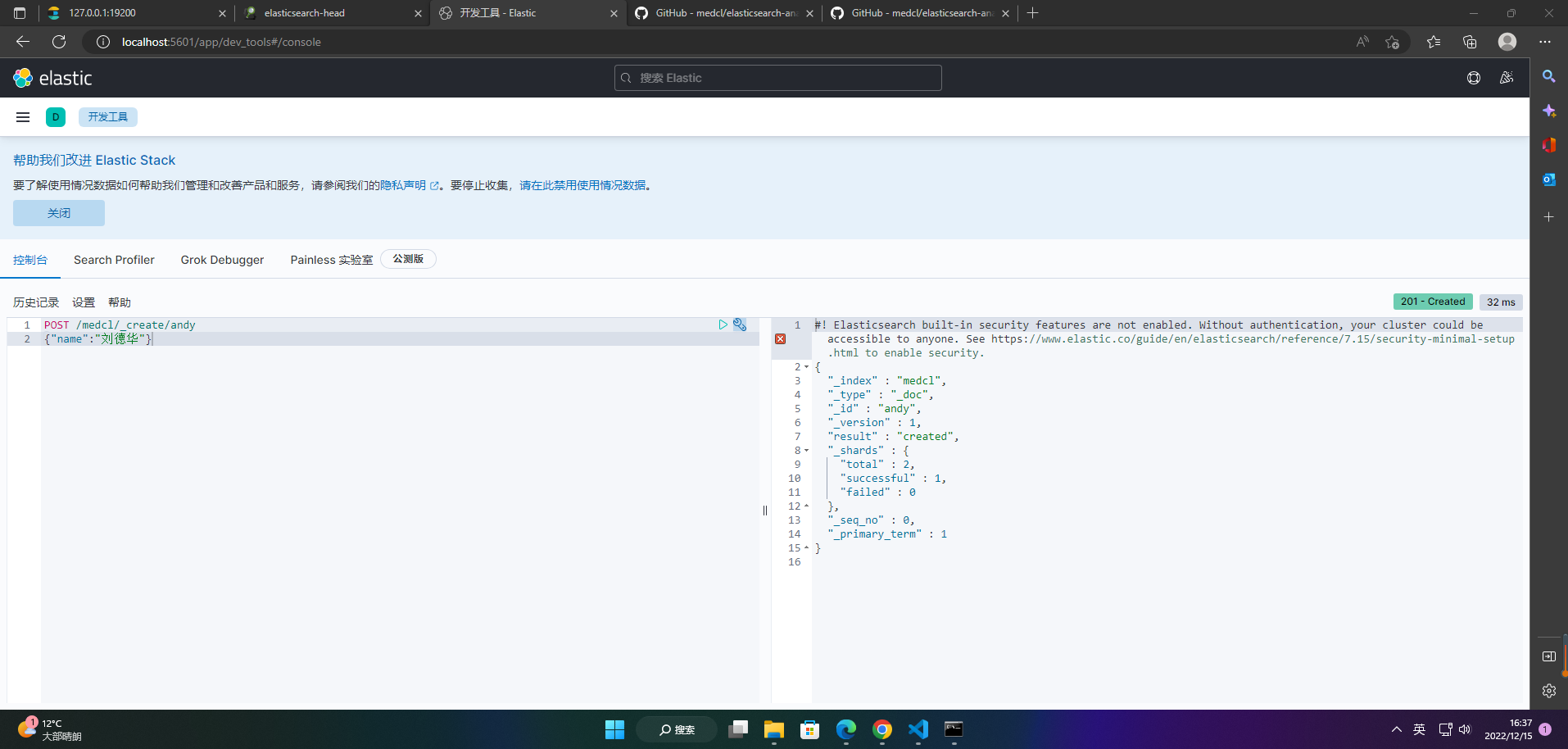
5、查询索引数据
GET /medcl/_search
{
"query": {
"match": {
"name.pinyin": "liu"
}
}
}
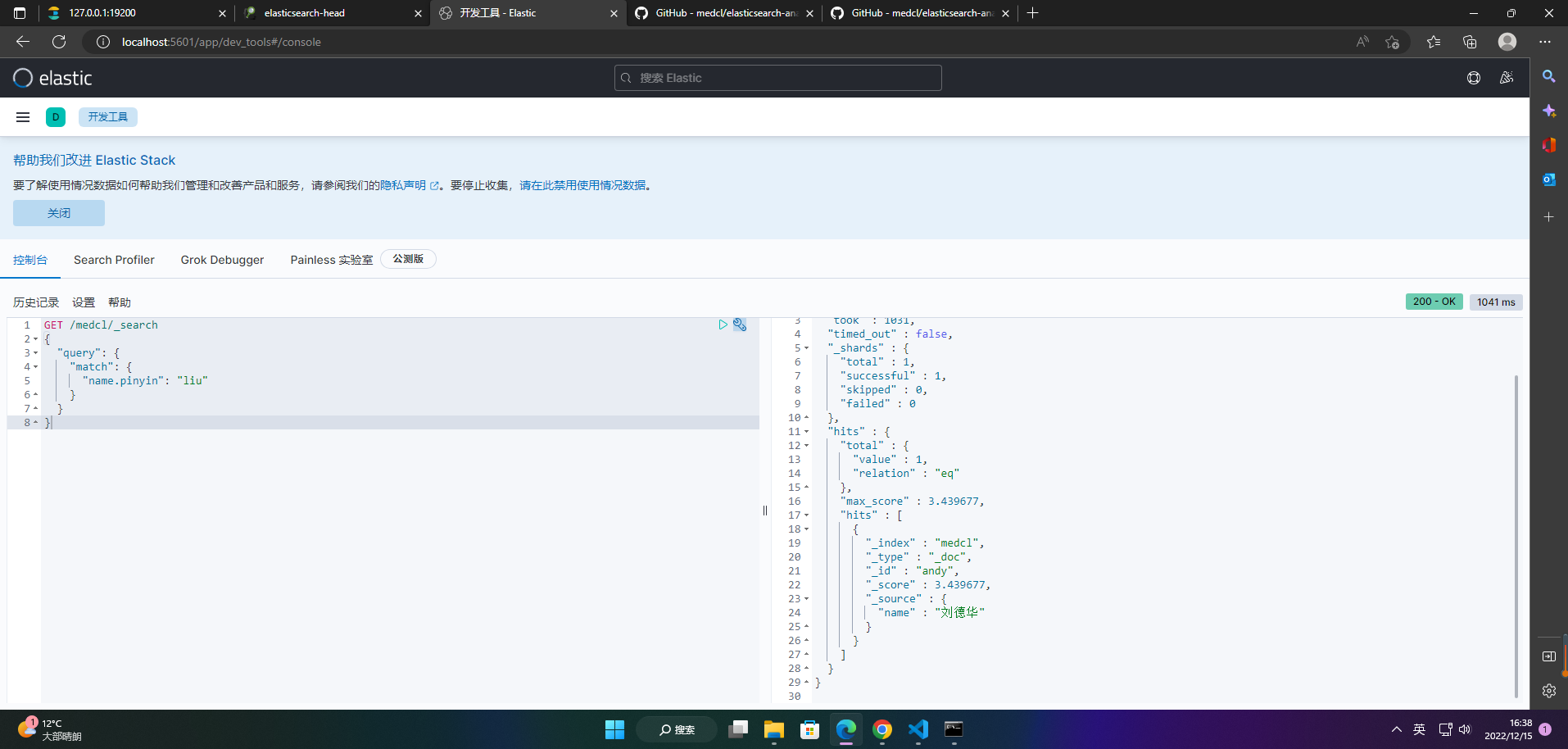
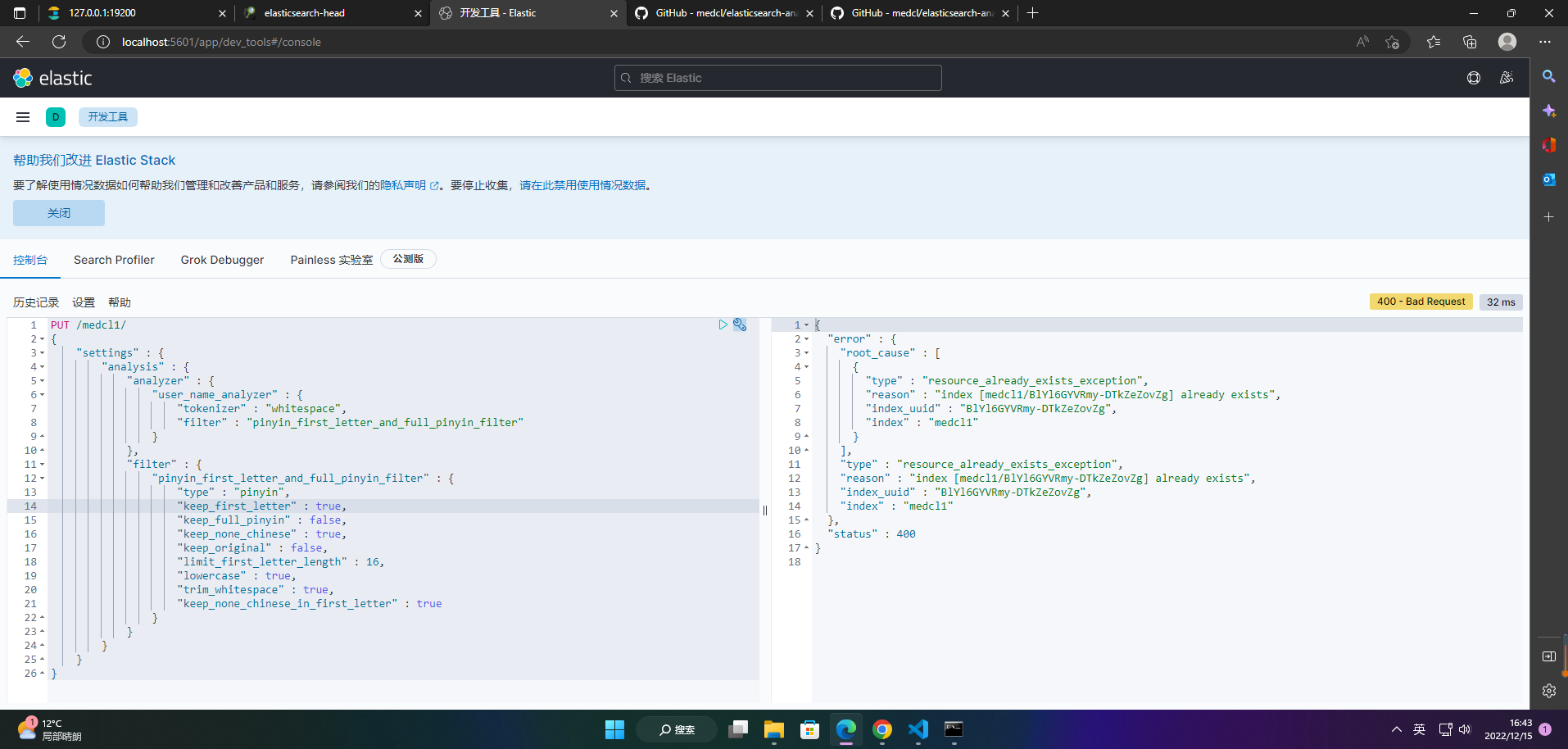
2.2.2 多个测试
1、创建索引
PUT /medcl1/
{
"settings" : {
"analysis" : {
"analyzer" : {
"user_name_analyzer" : {
"tokenizer" : "whitespace",
"filter" : "pinyin_first_letter_and_full_pinyin_filter"
}
},
"filter" : {
"pinyin_first_letter_and_full_pinyin_filter" : {
"type" : "pinyin",
"keep_first_letter" : true,
"keep_full_pinyin" : false,
"keep_none_chinese" : true,
"keep_original" : false,
"limit_first_letter_length" : 16,
"lowercase" : true,
"trim_whitespace" : true,
"keep_none_chinese_in_first_letter" : true
}
}
}
}
}
2、测试拼音分词器效果
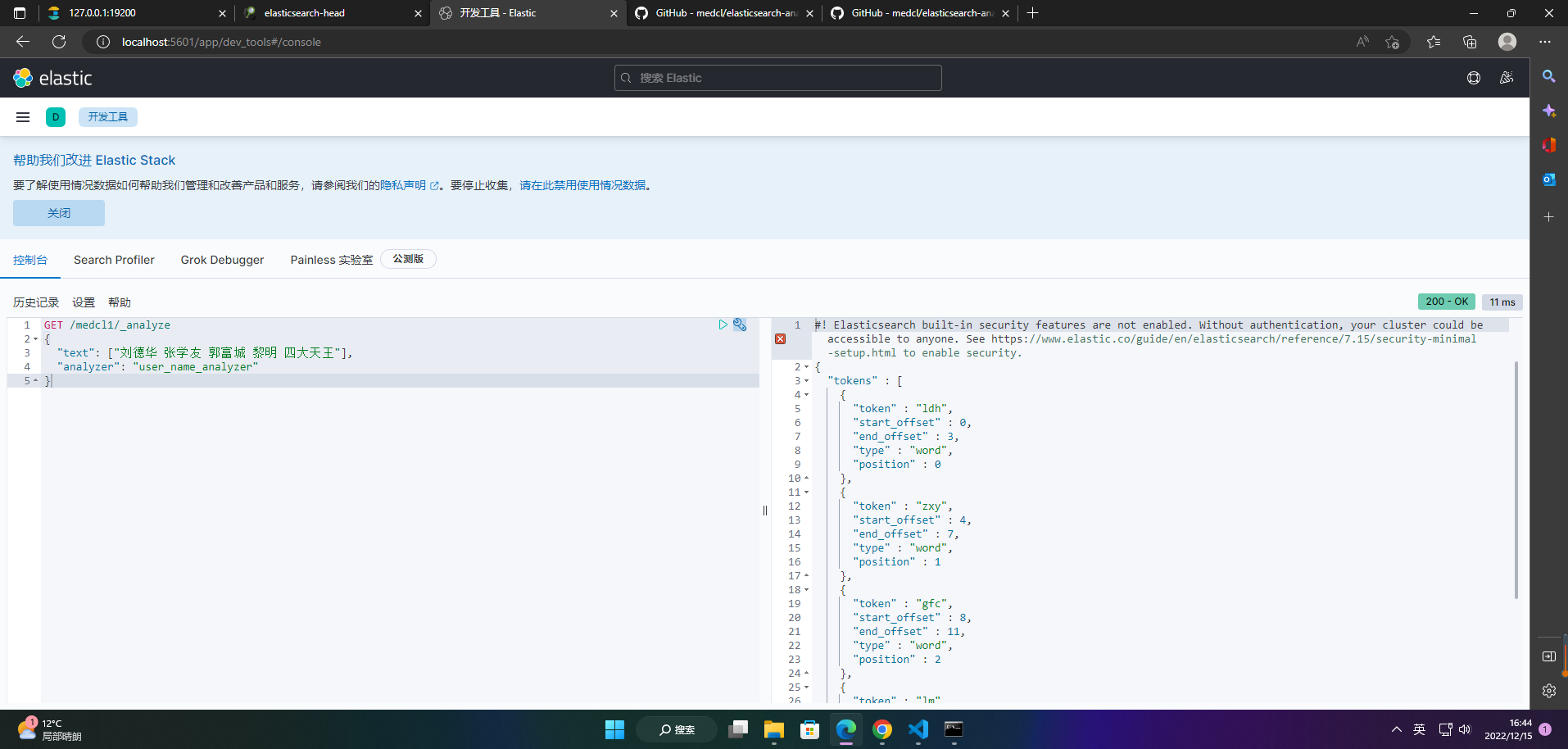
GET /medcl1/_analyze
{
"text": ["刘德华 张学友 郭富城 黎明 四大天王"],
"analyzer": "user_name_analyzer"
}
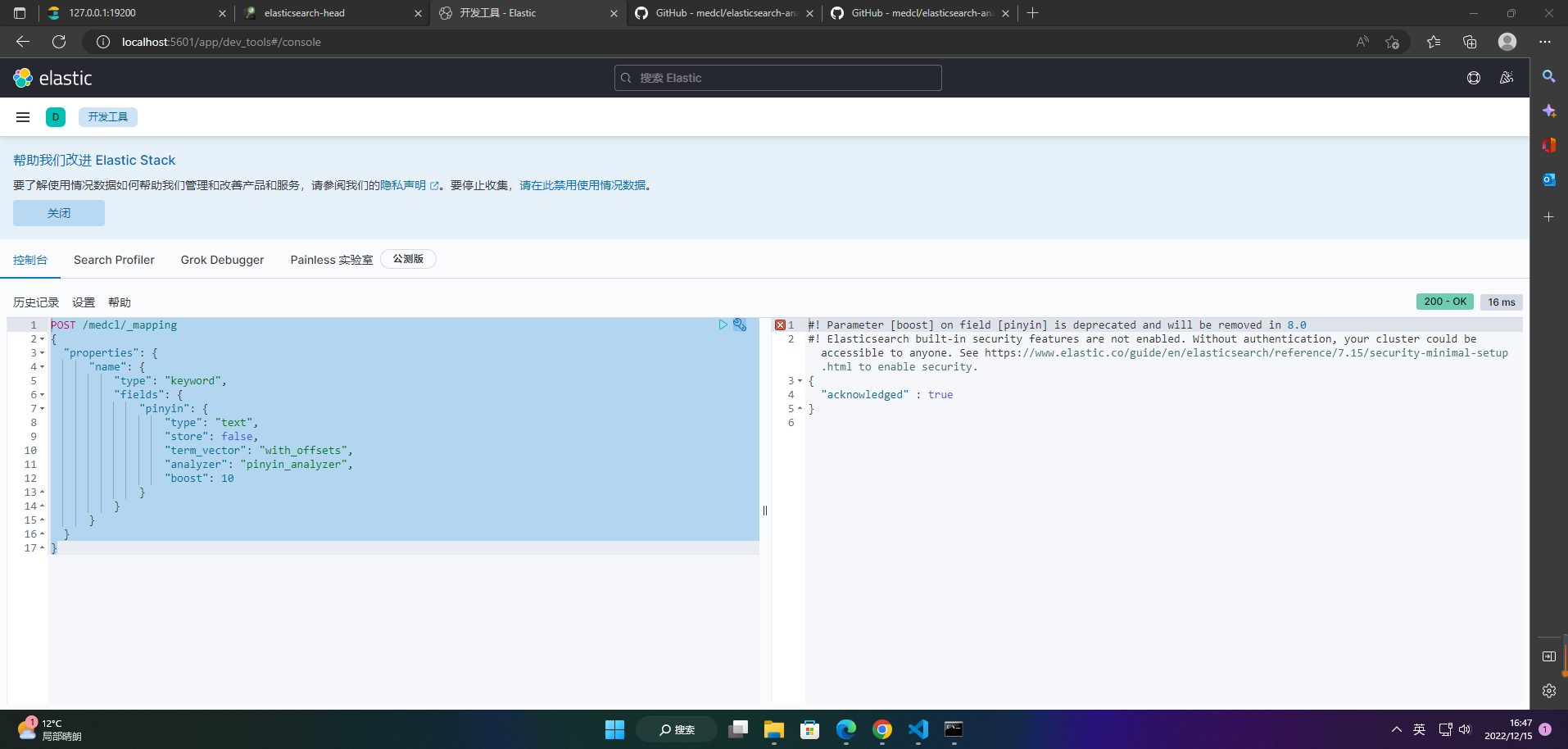
3、创建映射
POST /medcl/_mapping
{
"properties": {
"name": {
"type": "keyword",
"fields": {
"pinyin": {
"type": "text",
"store": false,
"term_vector": "with_offsets",
"analyzer": "pinyin_analyzer",
"boost": 10
}
}
}
}
}
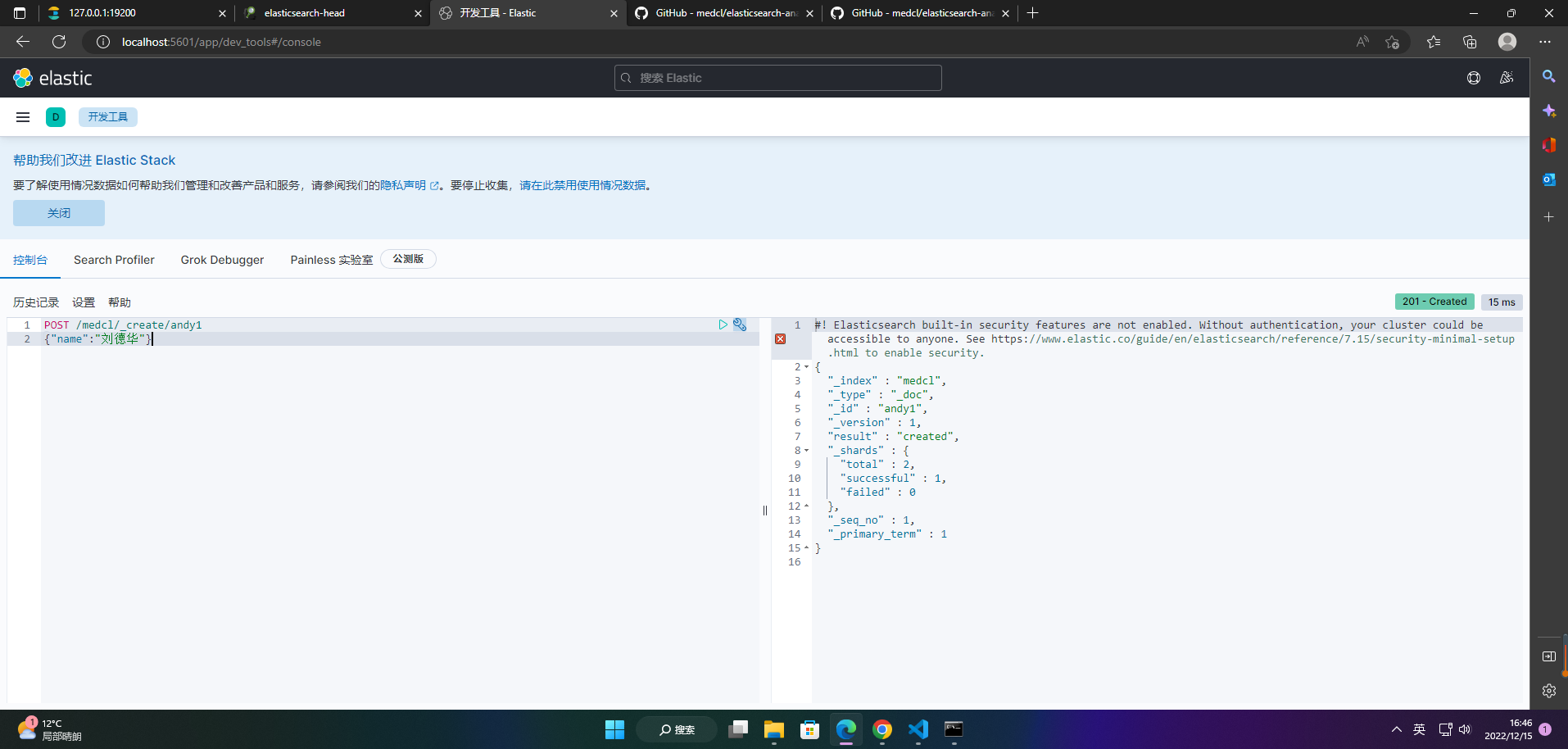
4、添加索引数据
POST /medcl/_create/andy1
{"name":"刘德华"}
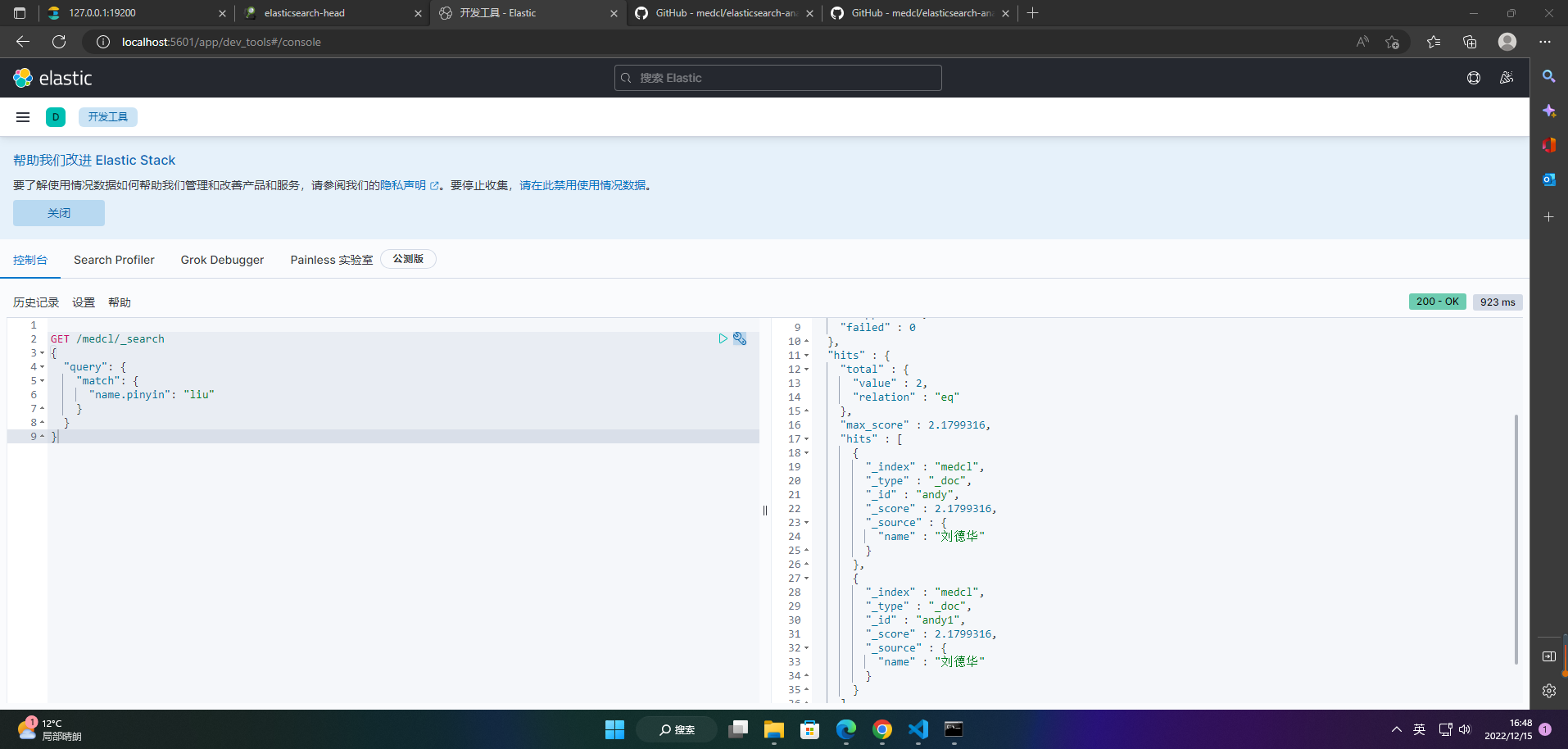
5、查询索引数据
GET /medcl/_search
{
"query": {
"match": {
"name.pinyin": "liu"
}
}
}
2.2.3 短语查询测试
2.2.3.1 medcl2索引
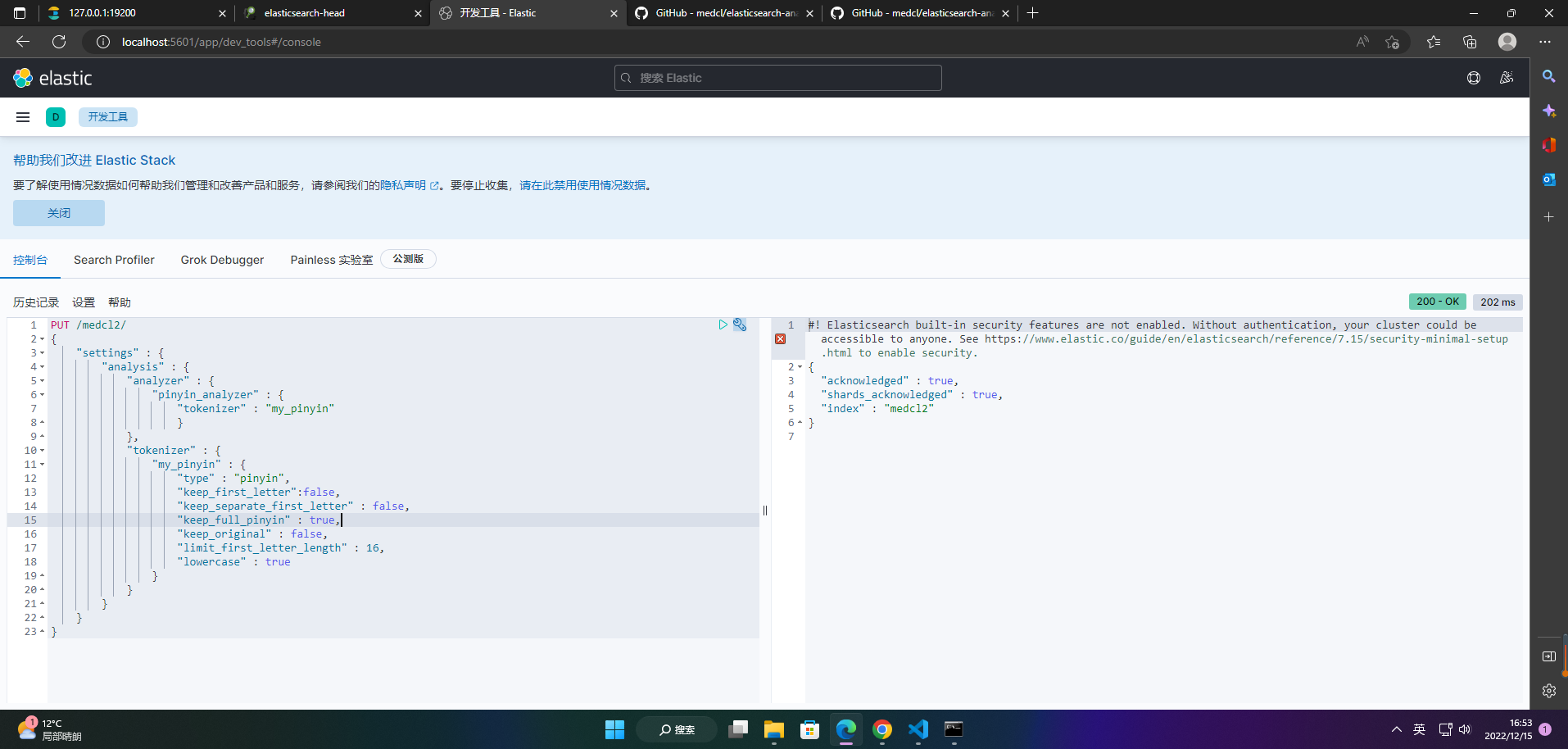
1、创建索引
PUT /medcl2/
{
"settings" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_first_letter":false,
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : false,
"limit_first_letter_length" : 16,
"lowercase" : true
}
}
}
}
}
2、查询medcl2索引数据
GET /medcl2/_search
{
"query": {"match_phrase": {
"name.pinyin": "刘德华"
}}
}
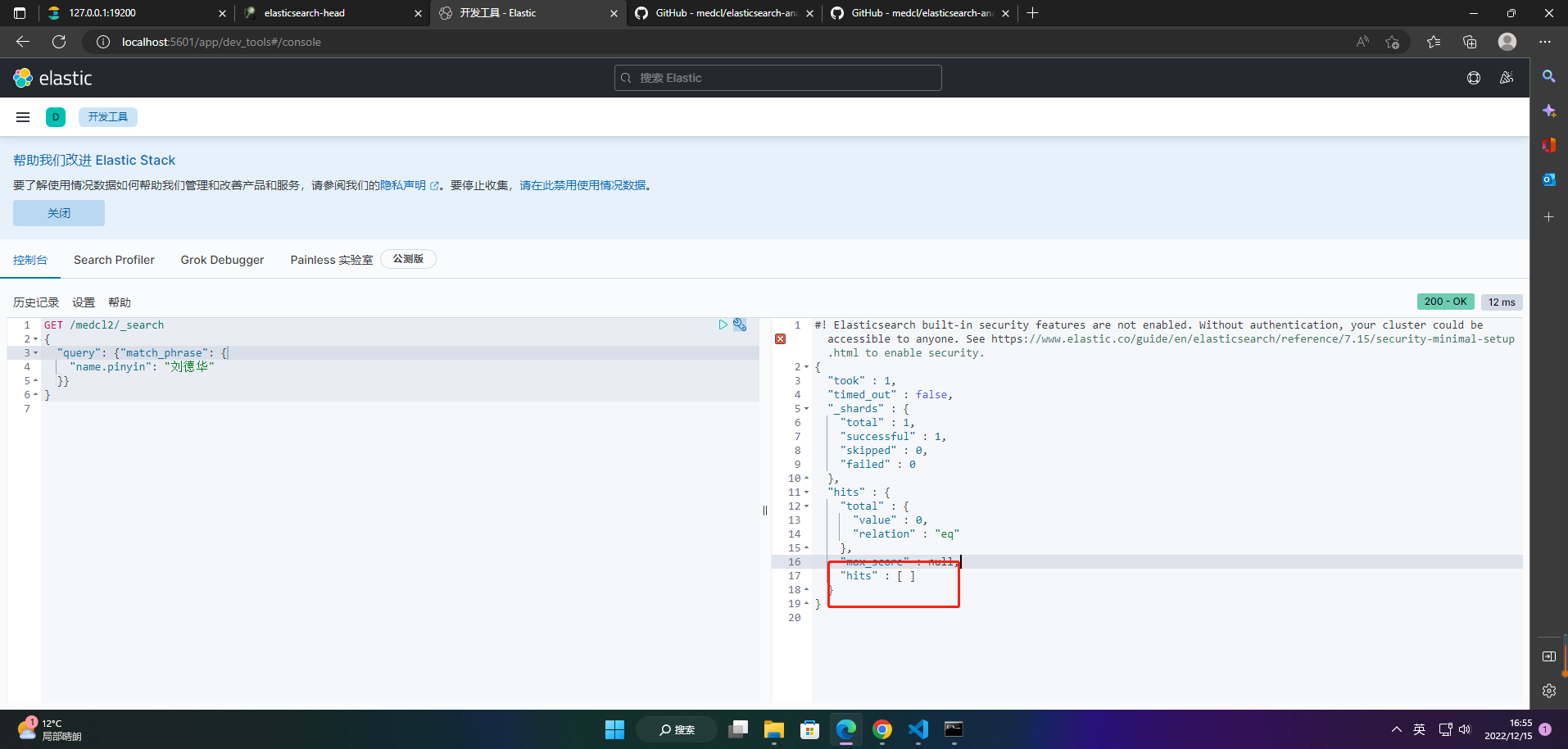
因为没数据哈哈哈。。。。。
2.2.3.2 medcl3索引
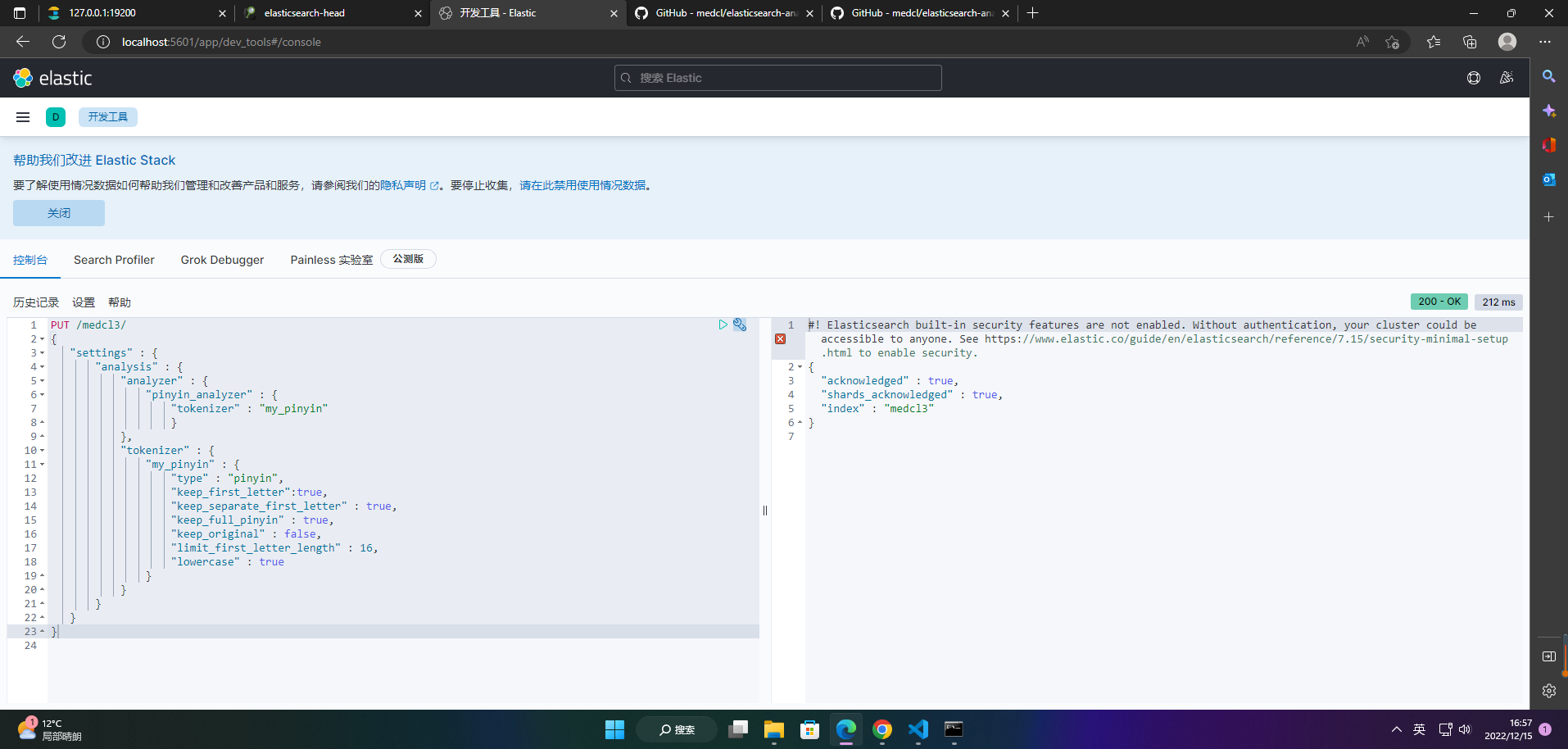
1、创建索引
PUT /medcl3/
{
"settings" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_first_letter":true,
"keep_separate_first_letter" : true,
"keep_full_pinyin" : true,
"keep_original" : false,
"limit_first_letter_length" : 16,
"lowercase" : true
}
}
}
}
}
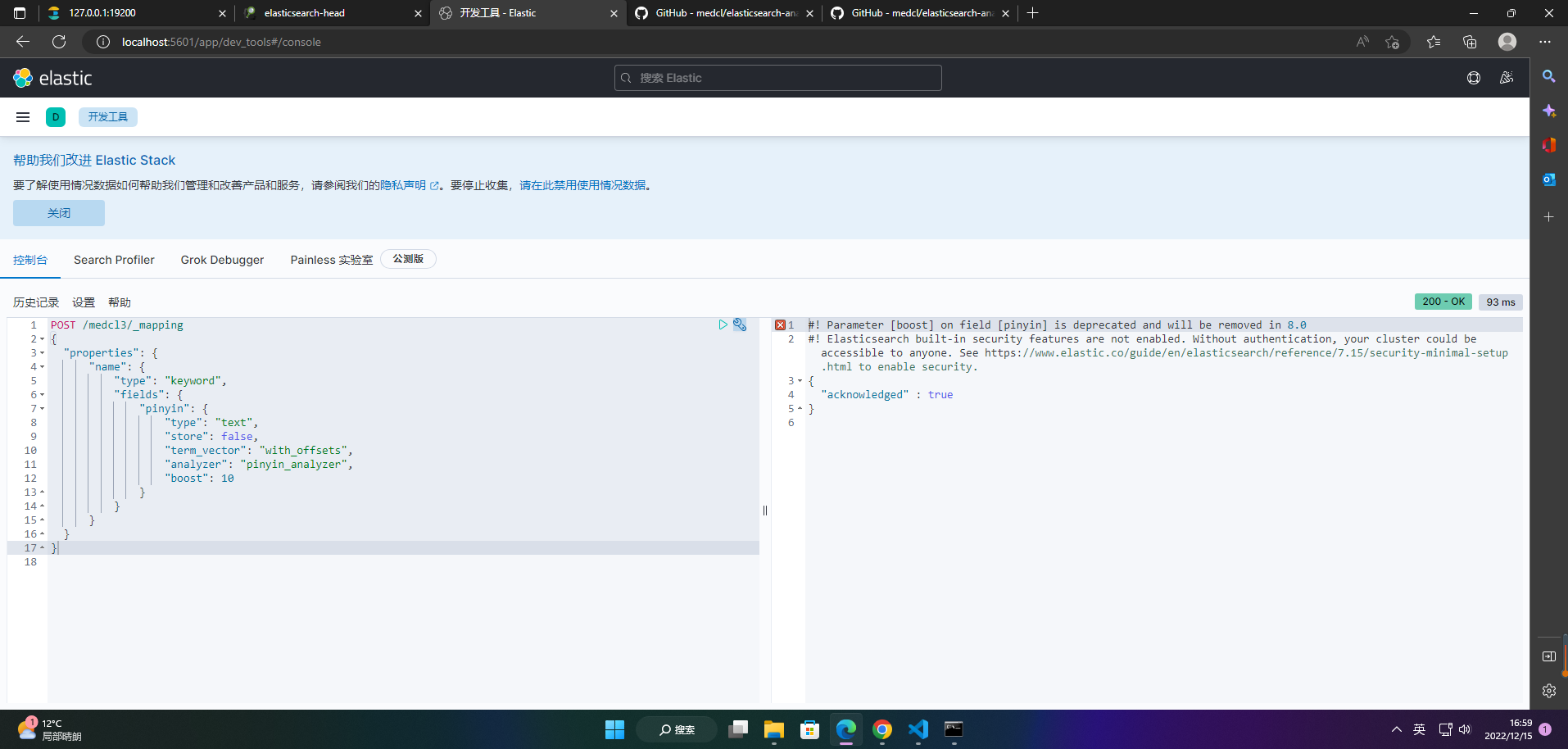
2、添加索引映射
POST /medcl3/_mapping
{
"properties": {
"name": {
"type": "keyword",
"fields": {
"pinyin": {
"type": "text",
"store": false,
"term_vector": "with_offsets",
"analyzer": "pinyin_analyzer",
"boost": 10
}
}
}
}
}
3、分析索引数据
GET /medcl3/_analyze
{
"text": ["刘德华"],
"analyzer": "pinyin_analyzer"
}
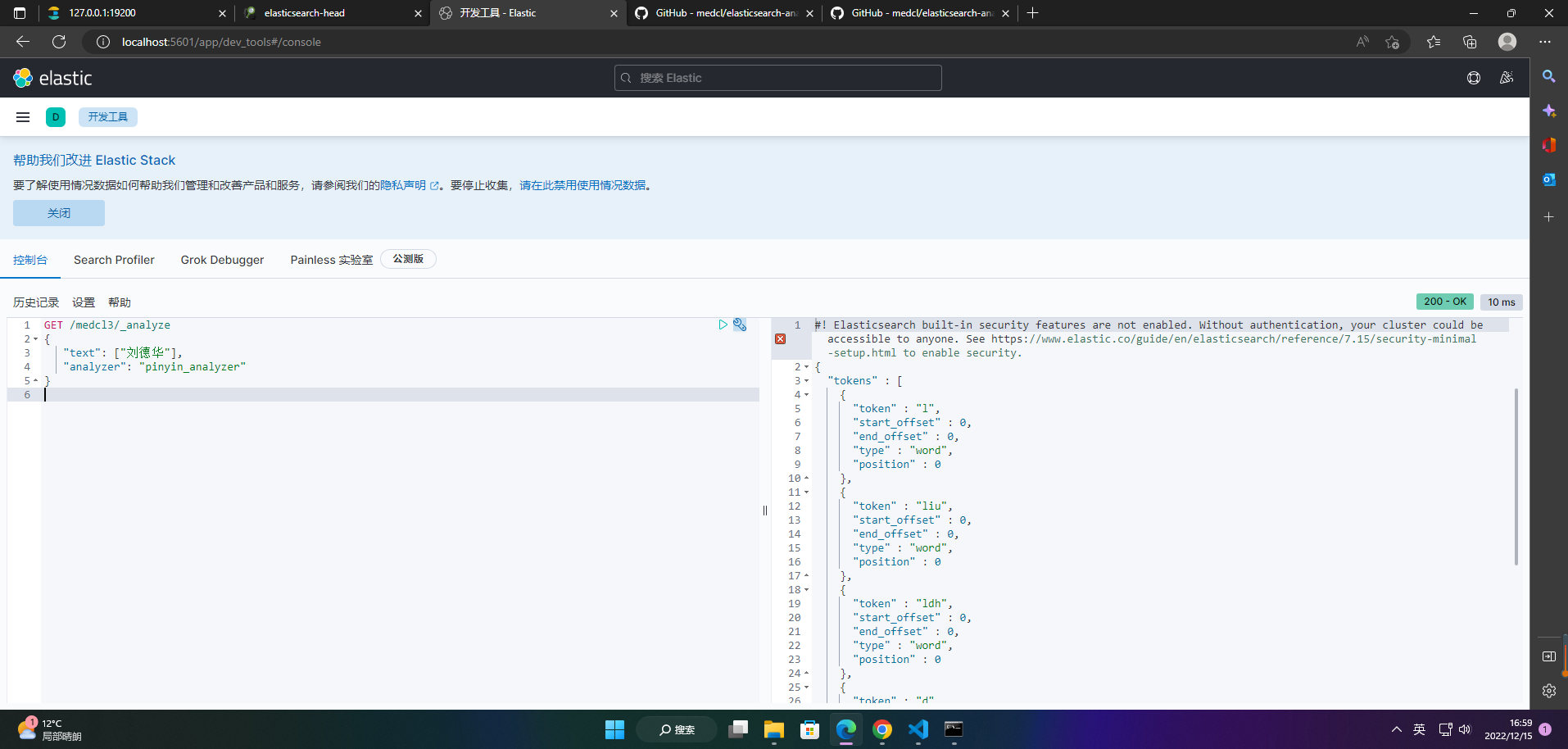
4、添加索引数据
POST /medcl3/_create/andy
{"name":"刘德华"}
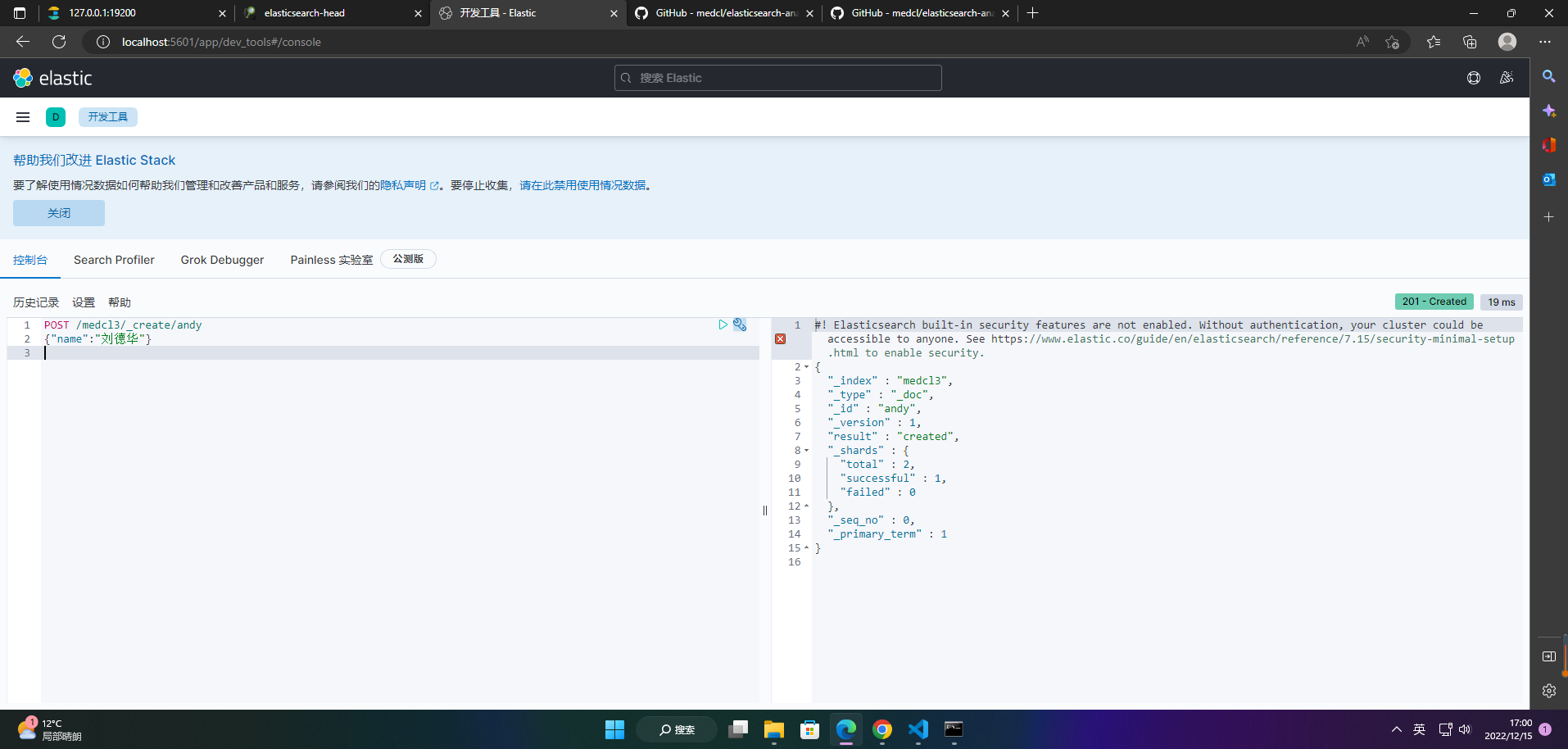
5、查询索引数据
GET /medcl3/_search
{
"query": {"match_phrase": {
"name.pinyin": "刘德h"
}}
}
GET /medcl3/_search
{
"query": {"match_phrase": {
"name.pinyin": "刘dh"
}}
}
GET /medcl3/_search
{
"query": {"match_phrase": {
"name.pinyin": "liudh"
}}
}
GET /medcl3/_search
{
"query": {"match_phrase": {
"name.pinyin": "liudeh"
}}
}
GET /medcl3/_search
{
"query": {"match_phrase": {
"name.pinyin": "liude华"
}}
}
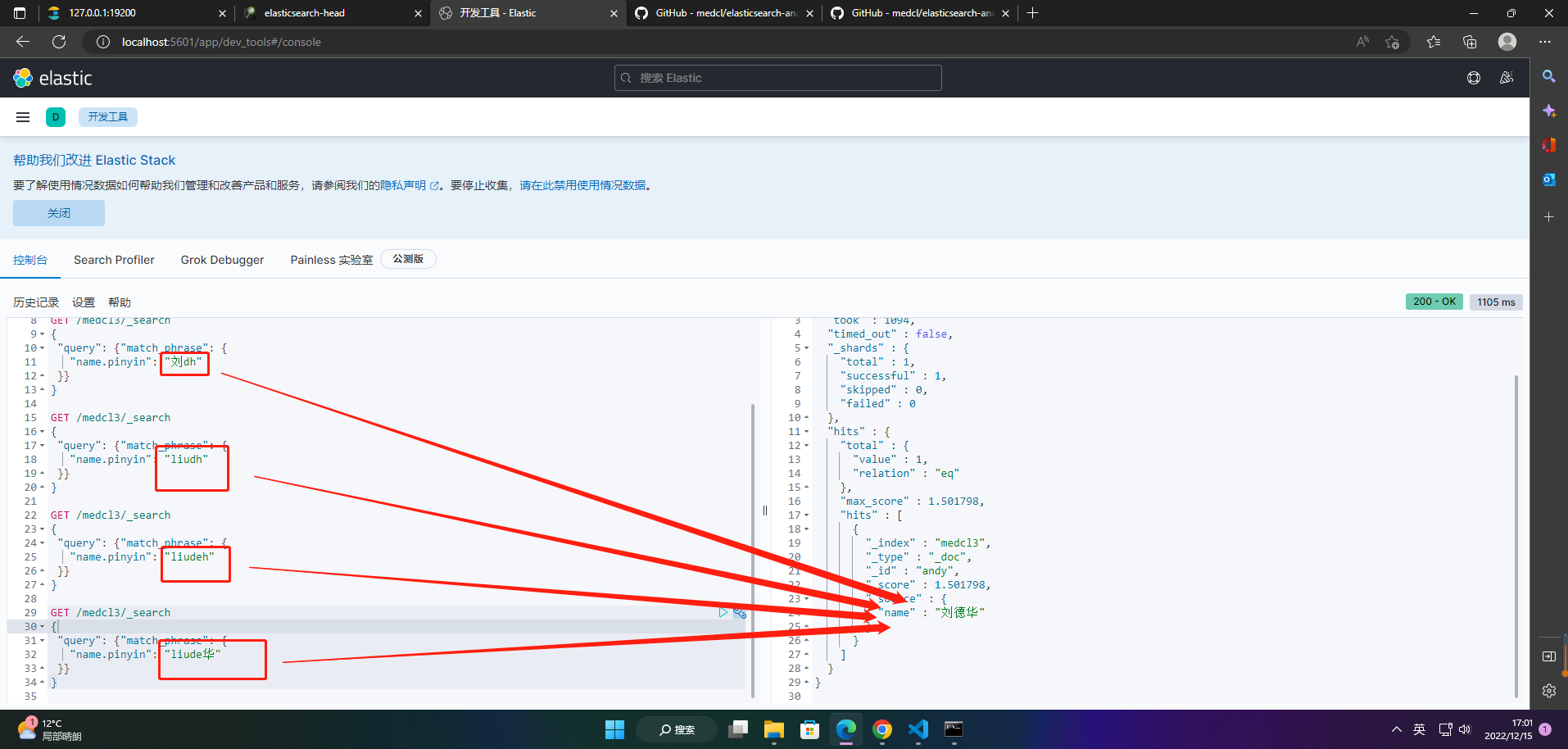








![[附源码]Node.js计算机毕业设计高校教务管理系统Express](https://img-blog.csdnimg.cn/1e17b6b9ec6d40f197c2ba7819d0765b.png)
