- Spring源码编译教程
Spring IoC容器的加载过程
- 1.实例化化容器:AnnotationConfigApplicationContext :
// 加载spring上下文
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(MainConfig.class);
AnnotationConfigApplicationContext的结构关系:
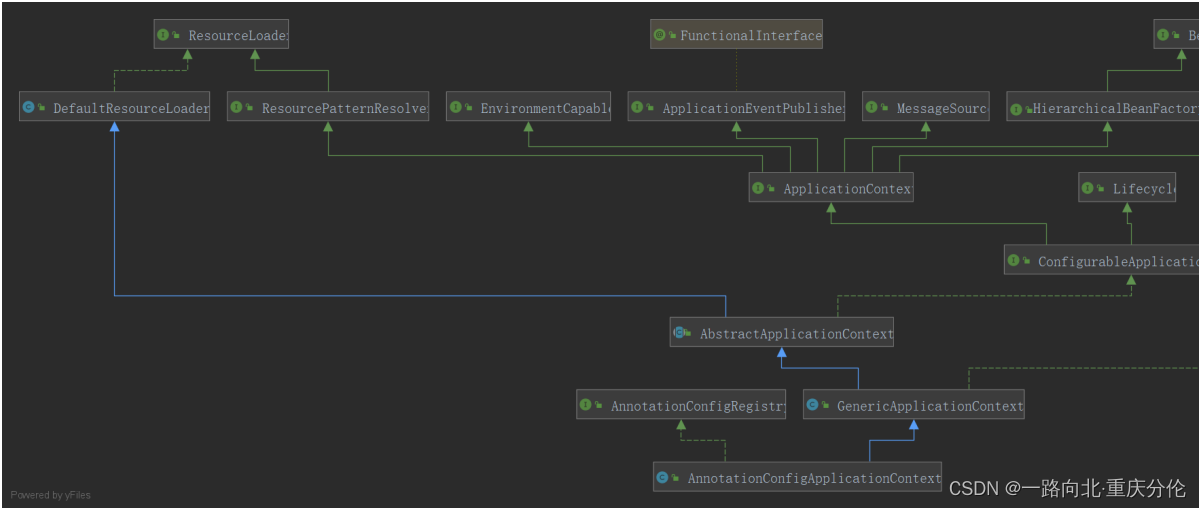
创建AnnotationConfigApplicationContext对象
调用AnnotationConfigApplicationContext的构造方法
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
//调用构造函数
this();
//注册我们的配置类
register(annotatedClasses);
//IOC容器刷新接口
refresh();
}
构造方法做一个简单的说明:
- 是一个有参的构造方法,可以接收多个配置类,不过一般情况下,只会传入一个配置类。
- 这个配置类有两种情况,一种是传统意义上的带上@Configuration注解的配置类,还有一种是没有带上@Configuration,但是带有@Component,@Import,@ImportResouce,@Service,@ComponentScan等注解的配置类,在Spring内部把前者称为Full配置类,把后者称之为Lite配置类。在本源码分析中,有些地方也把Lite配置类称为普通Bean。
使用断点调试,通过this()调用此类无参的构造方法,代码到下面
/**
* 注解的bean定义读取器
* 注解bean定义读取器,主要作用是用来读取被注解的
*/
private final AnnotatedBeanDefinitionReader reader;
/**
* 类路径下的bean定义扫描器
* 扫描器,它仅仅是在我们外部手动调用 .scan 等方法才有用,常规方式是不会用到scanner对象的
*/
private final ClassPathBeanDefinitionScanner scanner;
/**
* Create a new AnnotationConfigApplicationContext that needs to be populated
* through {@link #register} calls and then manually {@linkplain #refresh refreshed}.
*/
public AnnotationConfigApplicationContext() {
//会隐式调用父类的构造方法,初始化DefaultListableBeanFactory
/**
* 创建一个读取注解的Bean定义读取器
* 什么是bean定义?BeanDefinition
*
* 完成了spring内部BeanDefinition的注册(主要是后置处理器)
*/
this.reader = new AnnotatedBeanDefinitionReader(this);
/**
* 创建BeanDefinition扫描器
* 可以用来扫描包或者类,继而转换为bd
*
* spring默认的扫描包不是这个scanner对象
* 而是自己new的一个ClassPathBeanDefinitionScanner
* spring在执行工程后置处理器ConfigurationClassPostProcessor时,去扫描包时会new一个ClassPathBeanDefinitionScanner
*
* 这里的scanner仅仅是为了程序员可以手动调用AnnotationConfigApplicationContext对象的scan方法
*
*/
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
首先无参构造方法中就是对读取器reader和扫描器scanner进行了实例化,reader的类型是AnnotatedBeanDefinitionReader,可以看出它是一个 “打了注解的Bean定义读取器”,scanner的类型是ClassPathBeanDefinitionScanner,它仅仅是在外面手动用.scan方法,或者调用参数为String的构造方法,传入需要扫描的包名才会用到,像这样方式传入的配置类是不会用到这个scanner对象的。
AnnotationConfigApplicationContext类是有继承关系的,会隐式调用父类的构造方法:
- 2.实例化工厂:DefaultListableBeanFactory
public GenericApplicationContext() {
/**
* 调用父类的构造函数,为ApplicationContext spring上下文对象初始beanFactory
* 为啥是DefaultListableBeanFactory?我们去看BeanFactory接口的时候
* 发DefaultListableBeanFactory是最底层的实现,功能是最全的
*/
this.beanFactory = new DefaultListableBeanFactory();
}
DefaultListableBeanFactory的关系图
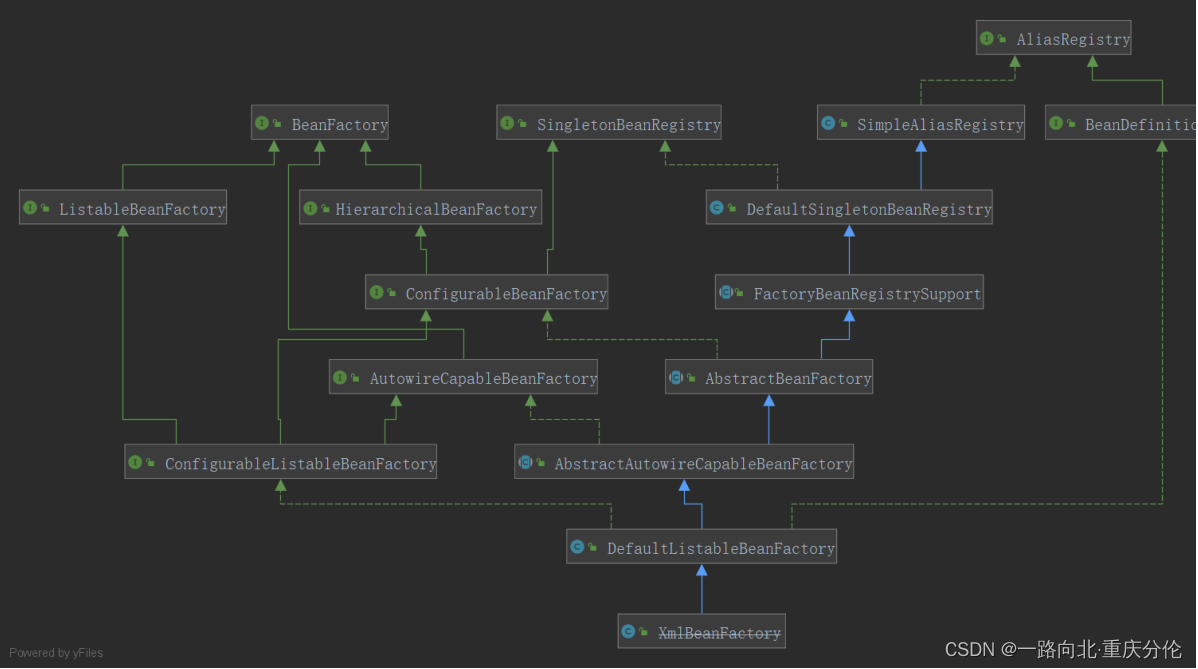
DefaultListableBeanFactory是相当重要的,从字面意思就可以看出它是一个Bean的工厂,什么是Bean的工厂?当然就是用来生产和获得Bean的。
- 3.实例化建BeanDefinition读取器: AnnotatedBeanDefinitionReader:
其主要做了2件事情
1.注册内置BeanPostProcessor
2.注册相关的BeanDefinition

让我们把目光回到AnnotationConfigApplicationContext的无参构造方法,让我们看看Spring在初始化
AnnotatedBeanDefinitionReader的时候做了什么:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry) {
this(registry, getOrCreateEnvironment(registry));
}
这里的BeanDefinitionRegistry当然就是AnnotationConfigApplicationContext的实例了,这里又直接调用了此类其他的构造方法:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
//把ApplicationContext对象赋值给AnnotatedBeanDefinitionReader
this.registry = registry;
//用户处理条件注解 @Conditional os.name
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
//注册一些内置的后置处理器
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
让我们把目光移动到这个方法的最后一行,进入registerAnnotationConfigProcessors方法:
public static void registerAnnotationConfigProcessors(BeanDefinitionRegistry registry) {
registerAnnotationConfigProcessors(registry, null);
}
这又是一个门面方法,再点进去,这个方法的返回值Set,但是上游方法并没有去接收这个返回值,所以这个方法的返回值也不是很重要了,当然方法内部给这个返回值赋值也不重要了。由于这个方法内容比较多,这里就把最核心的贴出来,这个方法的核心就是注册Spring内置的多个Bean:
核心方法块
/**
* 为我们容器中注册了解析我们配置类的后置处理器ConfigurationClassPostProcessor
* 名字叫:org.springframework.context.annotation.internalConfigurationAnnotationProcessor
*/
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
- 判断容器中是否已经存在了ConfigurationClassPostProcessor Bean
- 如果不存在(当然这里肯定是不存在的),就通过RootBeanDefinition的构造方法获得ConfigurationClassPostProcessor的BeanDefinition,RootBeanDefinition是BeanDefinition的子类
- 执行registerPostProcessor方法,registerPostProcessor方法内部就是注册Bean,当然这里注册
其他Bean也是一样的流程
BeanDefinition是什么?
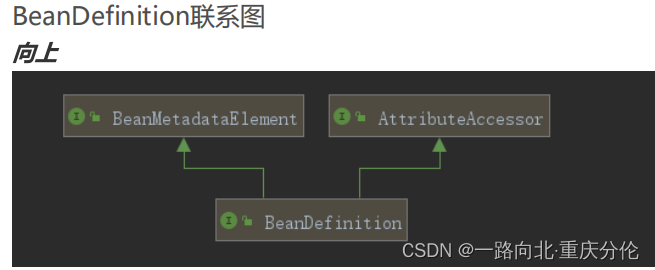
BeanMetadataElement接口:BeanDefinition元数据,返回该Bean的来源
AttributeAccessor接口:提供对BeanDefinition属性操作能力,
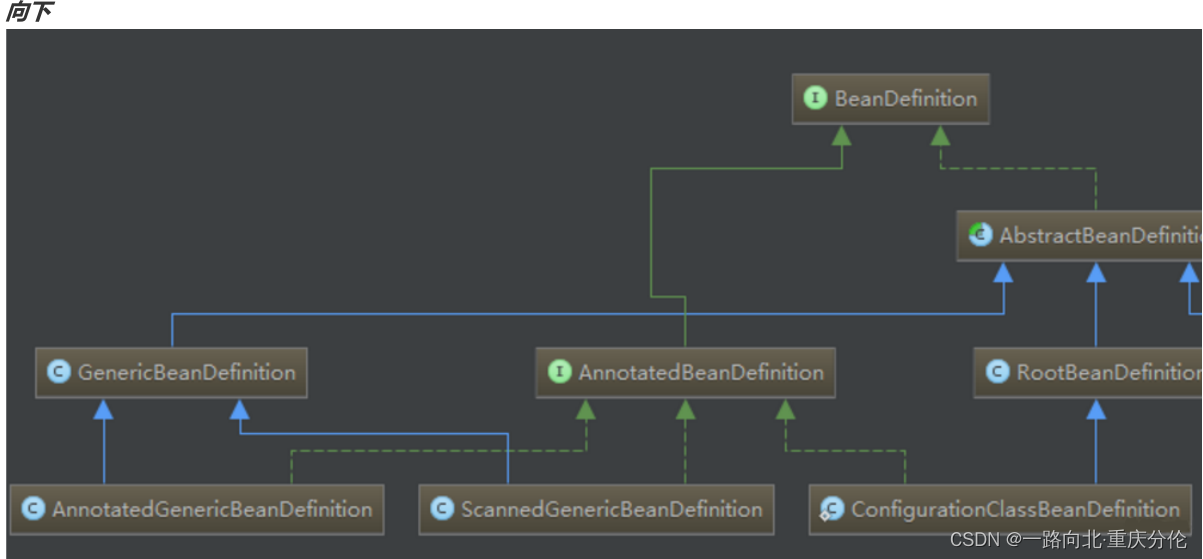
它是用来描述Bean的,里面存放着关于Bean的一系列信息,比如Bean的作用域,Bean所对应的Class,是
否懒加载,是否Primary等等,这个BeanDefinition也相当重要,我们以后会常常和它打交道。
registerPostProcessor方法:
private static BeanDefinitionHolder registerPostProcessor(
BeanDefinitionRegistry registry, RootBeanDefinition definition, String beanName) {
definition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(beanName, definition);
return new BeanDefinitionHolder(definition, beanName);
}
这方法为BeanDefinition设置了一个Role,ROLE_INFRASTRUCTURE代表这是spring内部的,并非用户定义的,然后又调用了registerBeanDefinition方法,再点进去,Oh No,你会发现它是一个接口,没办法直接点进去了,首先要知道registry实现类是什么,那么它的实现是什么呢?答案是DefaultListableBeanFactory。
核心在于下面两行代码:
//beanDefinitionMap是Map<String, BeanDefinition>,
//这里就是把beanName作为key,ScopedProxyMode作为value,推到map里面
this.beanDefinitionMap.put(beanName, beanDefinition);
//beanDefinitionNames就是一个List<String>,这里就是把beanName放到List中去
this.beanDefinitionNames.add(beanName);
从这里可以看出DefaultListableBeanFactory就是我们所说的容器了,里面放着beanDefinitionMap,beanDefinitionNames,beanDefinitionMap是一个hashMap,beanName作为Key,beanDefinition作为Value,beanDefinitionNames是一个集合,里面存放了beanName。打个断点,第一次运行到这里,监视这两个变量:
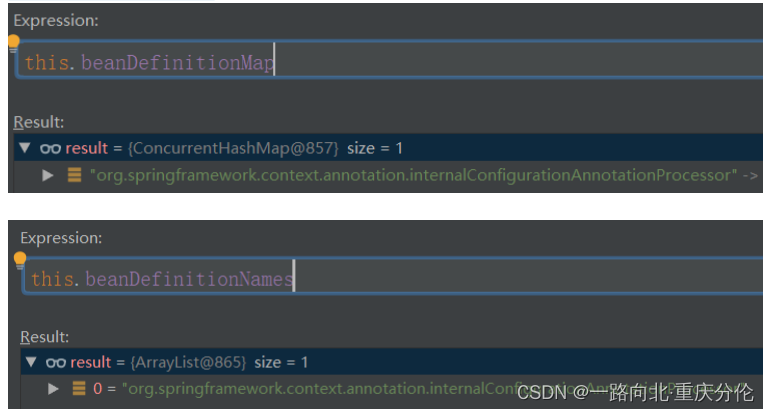
DefaultListableBeanFactory中的beanDefinitionMap,beanDefinitionNames也是相当重要的,以后会经常看到它,最好看到它,第一时间就可以反应出它里面放了什么数据。
这里仅仅是注册,可以简单的理解为把一些原料放入工厂,工厂还没有真正的去生产。上面已经介绍过,这里会一连串注册好几个Bean,在这其中最重要的一个Bean(没有之一)就是BeanDefinitionRegistryPostProcessor Bean。
ConfigurationClassPostProcessor实现BeanDefinitionRegistryPostProcessor接口,
BeanDefinitionRegistryPostProcessor接口又扩展了BeanFactoryPostProcessor接口,
BeanFactoryPostProcessor是Spring的扩展点之一,ConfigurationClassPostProcessor是Spring极为重要的一个类,必须牢牢的记住上面所说的这个类和它的继承关系。
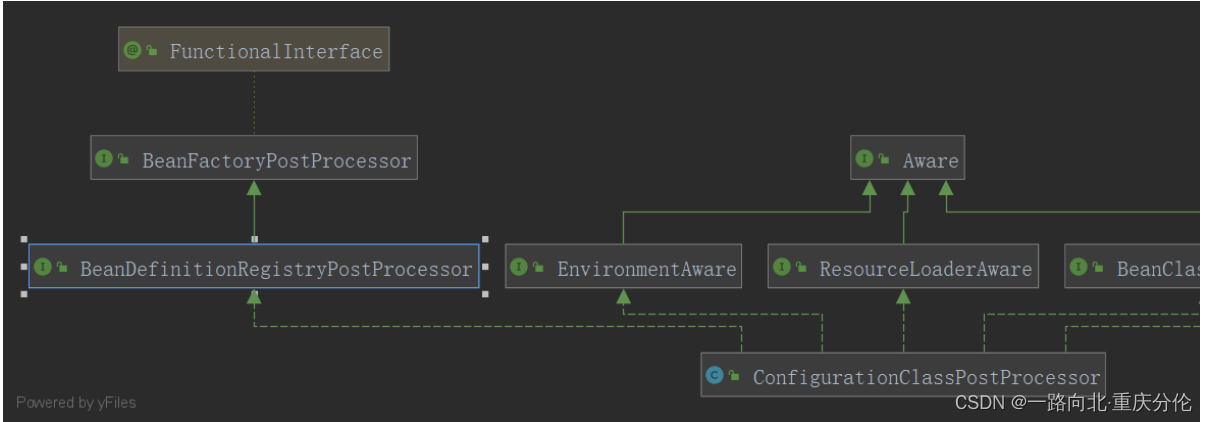
除了注册了ConfigurationClassPostProcessor,还注册了其他Bean,其他Bean也都实现了其他接口,比如BeanPostProcessor等。BeanPostProcessor接口也是Spring的扩展点之一。至此,实例化AnnotatedBeanDefinitionReader reader分析完毕。
-
4.创建BeanDefinition扫描器:ClassPathBeanDefinitionScanner
由于常规使用方式是不会用到AnnotationConfigApplicationContext里面的scanner的,这里的scanner仅仅是为了程序员可以手动调用AnnotationConfigApplicationContext对象的scan方法。所以这里就不看scanner是如何被实例化的了。 -
5.注册配置类为BeanDefinition: register(annotatedClasses);
把目光回到最开始,再分析第二行代码:
register(annotatedClasses);
这里传进去的是一个数组,最终会循环调用如下方法:
<T> void doRegisterBean(Class<T> annotatedClass, @Nullable Supplier<T> instanceSupplier, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, BeanDefinitionCustomizer... definitionCustomizers) {
//存储@Configuration注解注释的类
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(annotatedClass);
//判断是否需要跳过注解,spring中有一个@Condition注解,当不满足条件,这个bean就不会被解析
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(instanceSupplier);
//解析bean的作用域,如果没有设置的话,默认为单例
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
abd.setScope(scopeMetadata.getScopeName());
//获得beanName
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
//解析通用注解,填充到AnnotatedGenericBeanDefinition,解析的注解为Lazy,Primary,DependsOn,Role,Description
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
if (Primary.class == qualifier) {
abd.setPrimary(true);
}
else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
}
else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
for (BeanDefinitionCustomizer customizer : definitionCustomizers) {
customizer.customize(abd);
}
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
//注册,最终会调用DefaultListableBeanFactory中的registerBeanDefinition方法去注册,
//DefaultListableBeanFactory维护着一系列信息,比如beanDefinitionNames,beanDefinitionMap
//beanDefinitionNames是一个List<String>,用来保存beanName
//beanDefinitionMap是一个Map,用来保存beanName和beanDefinition
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
在这里又要说明下,以常规方式去注册配置类,此方法中除了第一个参数,其他参数都是默认值。
- 通过AnnotatedGenericBeanDefinition的构造方法,获得配置类的BeanDefinition,这里是不是似曾相似,在注册ConfigurationClassPostProcessor类的时候,也是通过构造方法去获得BeanDefinition的,只不过当时是通过RootBeanDefinition去获得,现在是通过AnnotatedGenericBeanDefinition去获得。
- 判断需不需要跳过注册,Spring中有一个@Condition注解,如果不满足条件,就会跳过这个类的注册。
- 然后是解析作用域,如果没有设置的话,默认为单例。
- 获得BeanName。
- 解析通用注解,填充到AnnotatedGenericBeanDefinition,解析的注解为Lazy,Primary,DependsOn,Role,Description。
- 限定符处理,不是特指@Qualifier注解,也有可能是Primary,或者是Lazy,或者是其他(理论上是任何注解,这里没有判断注解的有效性)。
- 把AnnotatedGenericBeanDefinition数据结构和beanName封装到一个对象中(这个不是很重要,可以简单的理解为方便传参)
- 注册,最终会调用DefaultListableBeanFactory中的registerBeanDefinition方法去注册:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
//获取beanName
String beanName = definitionHolder.getBeanName();
//注册bean
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
//Spring支持别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
这个registerBeanDefinition是不是又有一种似曾相似的感觉,没错,在上面注册Spring内置的Bean的时候,已经解析过这个方法了,这里就不重复了,此时,让我们再观察下beanDefinitionMap,beanDefinitionNames两个变量,除了Spring内置的Bean,还有我们传进来的Bean,这里的Bean当然就是我们的配置类了:
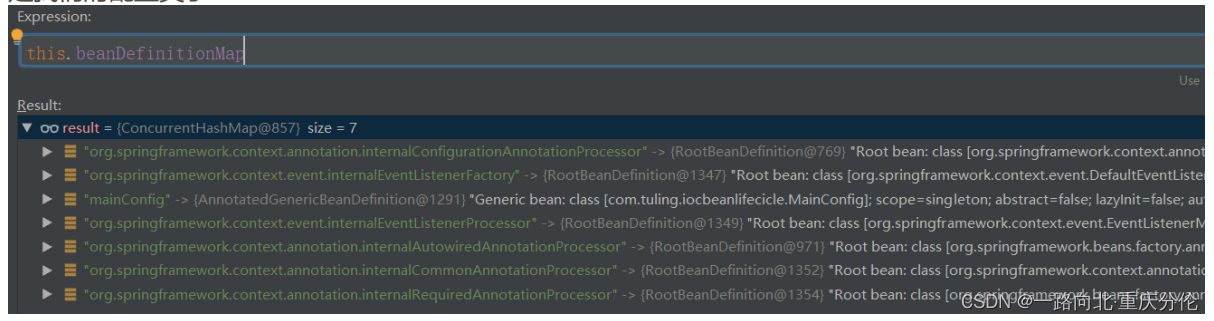
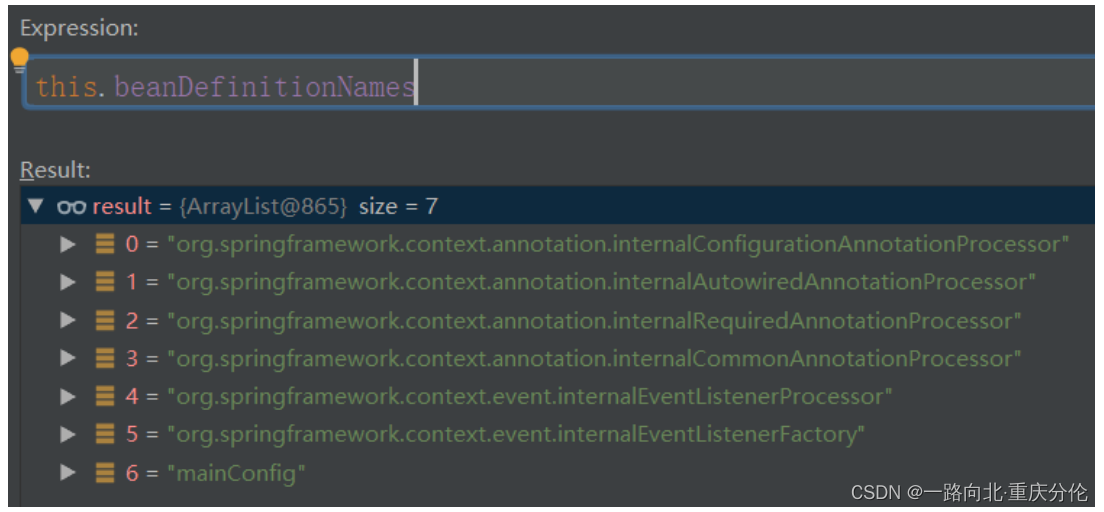
到这里注册配置类也分析完毕了。
- 6:refresh()
大家可以看到其实到这里,Spring还没有进行扫描,只是实例化了一个工厂,注册了一些内置的Bean和我们传进去的配置类,真正的大头是在第三行代码:
refresh();
这个方法做了很多事情,让我们点开这个方法:
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//1:准备刷新上下文环境
//刷新预处理,和主流程关系不大,就是保存了容器的启动时间,启动标志等
prepareRefresh();
//2:获取告诉子类初始化Bean工厂 不同工厂不同实现
//和主流程关系也不大,最终获得了DefaultListableBeanFactory,
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//3:对bean工厂进行填充属性
//还是一些准备工作,添加了两个后置处理器:ApplicationContextAwareProcessor,ApplicationListenerDetector
//还设置了 忽略自动装配 和 允许自动装配 的接口,如果不存在某个bean的时候,spring就自动注册singleton bean
//还设置了bean表达式解析器 等
prepareBeanFactory(beanFactory);
try {
// 第四:留个子类去实现该接口
//这是一个空方法
postProcessBeanFactory(beanFactory);
// 调用我们的bean工厂的后置处理器. 1. 会在此将class扫描成beanDefinition 2.bean工厂的后置处理器调用
//执行自定义的BeanFactoryProcessor和内置的BeanFactoryProcessor
invokeBeanFactoryPostProcessors(beanFactory);
// 注册我们bean的后置处理器
// 注册BeanPostProcessor
registerBeanPostProcessors(beanFactory);
// 初始化国际化资源处理器.
initMessageSource();
// 创建事件多播器
initApplicationEventMulticaster();
// 这个方法同样也是留个子类实现的springboot也是从这个方法进行启动tomcat的.
// 空方法
onRefresh();
//把我们的事件监听器注册到多播器上
registerListeners();
// 实例化我们剩余的单实例bean.
finishBeanFactoryInitialization(beanFactory);
// 最后容器刷新 发布刷新事件(Spring cloud也是从这里启动的)
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
6.1 prepareRefresh
从命名来看,就知道这个方法主要做了一些刷新前的准备工作,和主流程关系不大,主要是保存了容器的启动时间,启动标志等。
6.2 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory()
这个方法和主流程关系也不是很大,可以简单的认为,就是把beanFactory取出来而已。XML模式下会在这里读取BeanDefinition。
6.3 prepareBeanFactory

这代码相比前面两个就比较重要了,我们需要点进去好好看看,做了什么操作:
/**
* 为我们的bean工厂填充内部属性
* @param beanFactory the BeanFactory to configure
*/
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
//设置bean工厂的类加载器为当前application应用的加载器
beanFactory.setBeanClassLoader(getClassLoader());
//为bean工厂设置我们标准的SPEL表达式解析器对象StandardBeanExpressionResolver
beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader()));
//为我们的bean工厂设置了一个propertityEditor 属性资源编辑器对象(用于后面的给bean对象赋值使用)
beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this, getEnvironment()));
//注册了一个完整的ApplicationContextAwareProcessor 后置处理器用来处理ApplicationContextAware接口的回调方法
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
/**
*
* 忽略以下接口的bean的 接口函数方法。 在populateBean时
* 因为以下接口都有setXXX方法, 这些方法不特殊处理将会自动注入容器中的bean
*/
beanFactory.ignoreDependencyInterface(EnvironmentAware.class);
beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class);
beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class);
beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class);
beanFactory.ignoreDependencyInterface(MessageSourceAware.class);
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
/**
* 当注册了依赖解析后,例如当注册了对 BeanFactory.class 的解析依赖后,
* 当 bean 的属性注 入的时候, 一旦检测到属性为 BeanFactory 类型便会将 beanFactory 的实例注入进去。
* 知道为什么可以
* @Autowired
* ApplicationContext applicationContext 就是因为这里设置了
*/
beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
//注册了一个事件监听器探测器后置处理器接口
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this));
// 处理aspectj的
if (beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
// Set a temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
//注册了bean工厂的内部的bean
if (!beanFactory.containsLocalBean(ENVIRONMENT_BEAN_NAME)) {
//环境
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment());
}
if (!beanFactory.containsLocalBean(SYSTEM_PROPERTIES_BEAN_NAME)) {
//环境系统属性
beanFactory.registerSingleton(SYSTEM_PROPERTIES_BEAN_NAME, getEnvironment().getSystemProperties());
}
if (!beanFactory.containsLocalBean(SYSTEM_ENVIRONMENT_BEAN_NAME)) {
//系统环境
beanFactory.registerSingleton(SYSTEM_ENVIRONMENT_BEAN_NAME, getEnvironment().getSystemEnvironment());
}
}
主要做了如下的操作:
- 设置了一个类加载器
- 设置了bean表达式解析器
- 添加了属性编辑器的支持
- 添加了一个后置处理器:ApplicationContextAwareProcessor,此后置处理器实现了BeanPostProcessor接口
- 设置了一些忽略自动装配的接口
- 设置了一些允许自动装配的接口,并且进行了赋值操作
- 在容器中还没有XX的bean的时候,帮我们注册beanName为XX的singleton bean
6.4 postProcessBeanFactory(beanFactory)
这是一个空方法,可能以后Spring会进行扩展把。
6.5-invokeBeanFactoryPostProcessors(beanFactory)
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
// 获取两处存储BeanFactoryPostProcessor的对象 传入供接下来的调用
// 1.当前Bean工厂,2.和我们自己调用addBeanFactoryPostProcessor的自定义BeanFactoryPostProcessor
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
让我们看看第一个小方法的第二个参数:
public List<BeanFactoryPostProcessor> getBeanFactoryPostProcessors() {
return this.beanFactoryPostProcessors;
}
这里获得的是BeanFactoryPostProcessor,当我看到这里的时候,愣住了,通过IDEA的查找引用功能,我发现这个集合永远都是空的,
根本没有代码为这个集合添加数据,很久都没有想通,后来才知道我们在外部可以手动添加一个后置处理器,而不是交给Spring去扫描,
即
AnnotationConfigApplicationContext annotationConfigApplicationContext =
new AnnotationConfigApplicationContext(AppConfig.class);
annotationConfigApplicationContext.addBeanFactoryPostProcessor(XXX);
只有这样,这个集合才不会为空,但是应该没有人这么做吧,当然也有可能是我孤陋寡闻。
点开invokeBeanFactoryPostProcessors方法:
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
//调用BeanDefinitionRegistryPostProcessor的后置处理器 Begin
// 定义已处理的后置处理器
Set<String> processedBeans = new HashSet<>();
//判断我们的beanFactory实现了BeanDefinitionRegistry(实现了该结构就有注册和获取Bean定义的能力)
if (beanFactory instanceof BeanDefinitionRegistry) {
//强行把我们的bean工厂转为BeanDefinitionRegistry,因为待会需要注册Bean定义
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
//保存BeanFactoryPostProcessor类型的后置 BeanFactoryPostProcessor 提供修改
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
//保存BeanDefinitionRegistryPostProcessor类型的后置处理器 BeanDefinitionRegistryPostProcessor 提供注册
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
//循环我们传递进来的beanFactoryPostProcessors
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
//判断我们的后置处理器是不是BeanDefinitionRegistryPostProcessor
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
//进行强制转化
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
//调用他作为BeanDefinitionRegistryPostProcessor的处理器的后置方法
registryProcessor.postProcessBeanDefinitionRegistry(registry);
//添加到我们用于保存的BeanDefinitionRegistryPostProcessor的集合中
registryProcessors.add(registryProcessor);
}
else {//若没有实现BeanDefinitionRegistryPostProcessor 接口,那么他就是BeanFactoryPostProcessor
//把当前的后置处理器加入到regularPostProcessors中
regularPostProcessors.add(postProcessor);
}
}
//定义一个集合用户保存当前准备创建的BeanDefinitionRegistryPostProcessor
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
//第一步:去容器中获取BeanDefinitionRegistryPostProcessor的bean的处理器名称
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
//循环筛选出来的匹配BeanDefinitionRegistryPostProcessor的类型名称
for (String ppName : postProcessorNames) {
//判断是否实现了PriorityOrdered接口的
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
//显示的调用getBean()的方式获取出该对象然后加入到currentRegistryProcessors集合中去
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
//同时也加入到processedBeans集合中去
processedBeans.add(ppName);
}
}
//对currentRegistryProcessors集合中BeanDefinitionRegistryPostProcessor进行排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 把当前的加入到总的里面去
registryProcessors.addAll(currentRegistryProcessors);
/**
* 在这里典型的BeanDefinitionRegistryPostProcessor就是ConfigurationClassPostProcessor
* 用于进行bean定义的加载 比如我们的包扫描,@import 等等。。。。。。。。。
*/
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
//调用完之后,马上clea掉
currentRegistryProcessors.clear();
//---------------------------------------调用内置实现PriorityOrdered接口ConfigurationClassPostProcessor完毕--优先级No1-End----------------------------------------------------------------------------------------------------------------------------
//去容器中获取BeanDefinitionRegistryPostProcessor的bean的处理器名称(内置的和上面注册的)
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
//循环上一步获取的BeanDefinitionRegistryPostProcessor的类型名称
for (String ppName : postProcessorNames) {
//表示没有被处理过,且实现了Ordered接口的
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
//显示的调用getBean()的方式获取出该对象然后加入到currentRegistryProcessors集合中去
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
//同时也加入到processedBeans集合中去
processedBeans.add(ppName);
}
}
//对currentRegistryProcessors集合中BeanDefinitionRegistryPostProcessor进行排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
//把他加入到用于保存到registryProcessors中
registryProcessors.addAll(currentRegistryProcessors);
//调用他的后置处理方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
//调用完之后,马上clea掉
currentRegistryProcessors.clear();
//-----------------------------------------调用自定义Order接口BeanDefinitionRegistryPostProcessor完毕-优先级No2-End-----------------------------------------------------------------------------------------------------------------------------
//调用没有实现任何优先级接口的BeanDefinitionRegistryPostProcessor
//定义一个重复处理的开关变量 默认值为true
boolean reiterate = true;
//第一次就可以进来
while (reiterate) {
//进入循环马上把开关变量给改为false
reiterate = false;
//去容器中获取BeanDefinitionRegistryPostProcessor的bean的处理器名称
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
//循环上一步获取的BeanDefinitionRegistryPostProcessor的类型名称
for (String ppName : postProcessorNames) {
//没有被处理过的
if (!processedBeans.contains(ppName)) {
//显示的调用getBean()的方式获取出该对象然后加入到currentRegistryProcessors集合中去
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
//同时也加入到processedBeans集合中去
processedBeans.add(ppName);
//再次设置为true
reiterate = true;
}
}
//对currentRegistryProcessors集合中BeanDefinitionRegistryPostProcessor进行排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
//把他加入到用于保存到registryProcessors中
registryProcessors.addAll(currentRegistryProcessors);
//调用他的后置处理方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
//进行clear
currentRegistryProcessors.clear();
}
//-----------------------------------------调用没有实现任何优先级接口自定义BeanDefinitionRegistryPostProcessor完毕--End-----------------------------------------------------------------------------------------------------------------------------
//调用 BeanDefinitionRegistryPostProcessor.postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
//调用BeanFactoryPostProcessor 自设的(没有)
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
//若当前的beanFactory没有实现了BeanDefinitionRegistry 说明没有注册Bean定义的能力
// 那么就直接调用BeanDefinitionRegistryPostProcessor.postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
//-----------------------------------------所有BeanDefinitionRegistryPostProcessor调用完毕--End-----------------------------------------------------------------------------------------------------------------------------
//-----------------------------------------处理BeanFactoryPostProcessor --Begin-----------------------------------------------------------------------------------------------------------------------------
//获取容器中所有的 BeanFactoryPostProcessor
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
//保存BeanFactoryPostProcessor类型实现了priorityOrdered
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
//保存BeanFactoryPostProcessor类型实现了Ordered接口的
List<String> orderedPostProcessorNames = new ArrayList<>();
//保存BeanFactoryPostProcessor没有实现任何优先级接口的
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
//processedBeans包含的话,表示在上面处理BeanDefinitionRegistryPostProcessor的时候处理过了
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
//判断是否实现了PriorityOrdered 优先级最高
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
//判断是否实现了Ordered 优先级 其次
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
//没有实现任何的优先级接口的 最后调用
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// 排序
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 先调用BeanFactoryPostProcessor实现了 PriorityOrdered接口的
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
//再调用BeanFactoryPostProcessor实现了 Ordered.
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
//调用没有实现任何方法接口的
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
//-----------------------------------------处理BeanFactoryPostProcessor --End-----------------------------------------------------------------------------------------------------------------------------
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
//------------------------- BeanFactoryPostProcessor和BeanDefinitionRegistryPostProcessor调用完毕 --End-----------------------------------------------------------------------------------------------------------------------------
}
首先判断beanFactory是不是BeanDefinitionRegistry的实例,当然肯定是的,然后执行如下操作:
- 定义了一个Set,装载BeanName,后面会根据这个Set,来判断后置处理器是否被执行过了。
- 定义了两个List,一个是regularPostProcessors,用来装载BeanFactoryPostProcessor,一个是registryProcessors用来装载
BeanDefinitionRegistryPostProcessor,其中BeanDefinitionRegistryPostProcessor扩展了BeanFactoryPostProcessor。BeanDefinitionRegistryPostProcessor有两个方法,一个是独有的postProcessBeanDefinitionRegistry方法,一个是父类的postProcessBeanFactory方法。 - 循环传进来的beanFactoryPostProcessors,上面已经解释过了,一般情况下,这里永远都是空的,只有手动add
beanFactoryPostProcessor,这里才会有数据。我们假设beanFactoryPostProcessors有数据,进入循环,判断postProcessor是
不是BeanDefinitionRegistryPostProcessor,因为BeanDefinitionRegistryPostProcessor扩展了BeanFactoryPostProcessor,所以这里先要判断是不是BeanDefinitionRegistryPostProcessor,是的话,执行postProcessBeanDefinitionRegistry方法,然后把对象装到registryProcessors里面去,不是的话,就装到regularPostProcessors。 - 定义了一个临时变量:currentRegistryProcessors,用来装载BeanDefinitionRegistryPostProcessor。
- getBeanNamesForType,顾名思义,是根据类型查到BeanNames,这里有一点需要注意,就是去哪里找,点开这个方法的
话,就知道是循环beanDefinitionNames去找,这个方法以后也会经常看到。这里传了BeanDefinitionRegistryPostProcessor.class,就是找到类型为BeanDefinitionRegistryPostProcessor的后置处理器,并且赋值给postProcessorNames。一般情况下,只会找到一个,就是
org.springframework.context.annotation.internalConfigurationAnnotationProcessor,也就是ConfigurationAnnotationProcessor。这个后置处理器在上一节中已经说明过了,十分重要。这里有一个问题,为什么我自己写了个类,实现了BeanDefinitionRegistryPostProcessor接口,也打上了@Component注解,但是这里没有获得,因为直到这一步,Spring还没有完成扫描,扫描是在ConfigurationClassPostProcessor类中完成的,也就是下面第一个invokeBeanDefinitionRegistryPostProcessors方法。 - 循环postProcessorNames,其实也就是
org.springframework.context.annotation.internalConfigurationAnnotationProcessor,判断此后置处理器是否实现了PriorityOrdered接口(ConfigurationAnnotationProcessor也实现了PriorityOrdered接口),如果实现了,把它添加到currentRegistryProcessors这个临时变量中,再放入processedBeans,代表这个后置处理已经被处理过了。当然现在还没有处理,但是马上就要处理了。。。

7. 进行排序,PriorityOrdered是一个排序接口,如果实现了它,就说明此后置处理器是有顺序的,所以需要排序。当然目前这里只有一个后置处理器,就是ConfigurationClassPostProcessor。
8. 把currentRegistryProcessors合并到registryProcessors,为什么需要合并?因为一开始spring只会执行BeanDefinitionRegistryPostProcessor独有的方法,而不会执行BeanDefinitionRegistryPostProcessor父类的方法,即BeanFactoryProcessor接口中的方法,所以需要把这些后置处理器放入一个集合中,后续统一执行BeanFactoryProcessor接口中的方法。当然目前这里只有一个后置处理器,就是ConfigurationClassPostProcessor。
9. 可以理解为执行currentRegistryProcessors中的ConfigurationClassPostProcessor中的postProcessBeanDefinitionRegistry方法,这就是Spring设计思想的体现了,在这里体现的就是其中的热插拔,插件化开发的思想。Spring中很多东西都是交给插件去
处理的,这个后置处理器就相当于一个插件,如果不想用了,直接不添加就是了。这个方法特别重要,我们后面会详细说来。
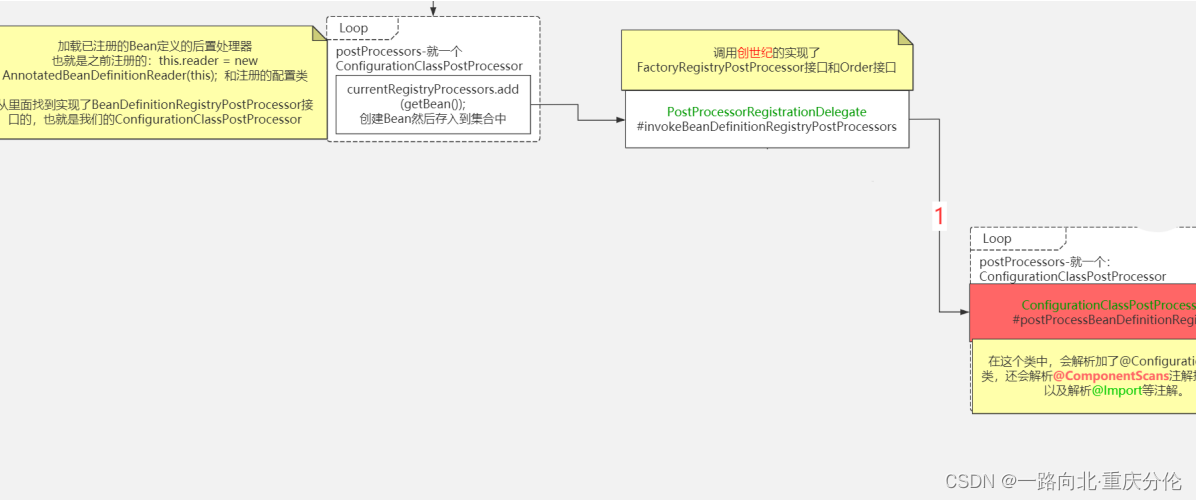
10. 清空currentRegistryProcessors,因为currentRegistryProcessors是一个临时变量,已经完成了目前的使命,所以需要清空,
当然后面还会用到。
11. 再次根据BeanDefinitionRegistryPostProcessor获得BeanName,然后进行循环,看这个后置处理器是否被执行过了,如果没
有被执行过,也实现了Ordered接口的话,把此后置处理器推送到currentRegistryProcessors和processedBeans中。这里就可以获得我们定义的,并且打上@Component注解的后置处理器了,因为Spring已经完成了扫描,但是这里需要注意的是,由于
ConfigurationClassPostProcessor在上面已经被执行过了,所以虽然可以通过getBeanNamesForType获得,但是并不会加入到
currentRegistryProcessors和processedBeans。
12. 处理排序。
13. 合并Processors,合并的理由和上面是一样的。
14. 执行我们自定义的BeanDefinitionRegistryPostProcessor。
15. 清空临时变量。
16. 在上面的方法中,仅仅是执行了实现了Ordered接口的BeanDefinitionRegistryPostProcessor,这里是执行没有实现Ordered接口的BeanDefinitionRegistryPostProcessor。
17. 上面的代码是执行子类独有的方法,这里需要再把父类的方法也执行一次。
18. 执行regularPostProcessors中的后置处理器的方法,需要注意的是,在一般情况下,regularPostProcessors是不会有数据的,只有在外面手动添加BeanFactoryPostProcessor,才会有数据。
19. 查找实现了BeanFactoryPostProcessor的后置处理器,并且执行后置处理器中的方法。和上面的逻辑差不多,不再详细说明。
这就是这个方法中做的主要的事情了,可以说是比较复杂的。但是逻辑还是比较清晰的,在第9步的时候,我说有一个方法会详细说来,
现在就让我们好好看看这个方法究竟做了什么吧。
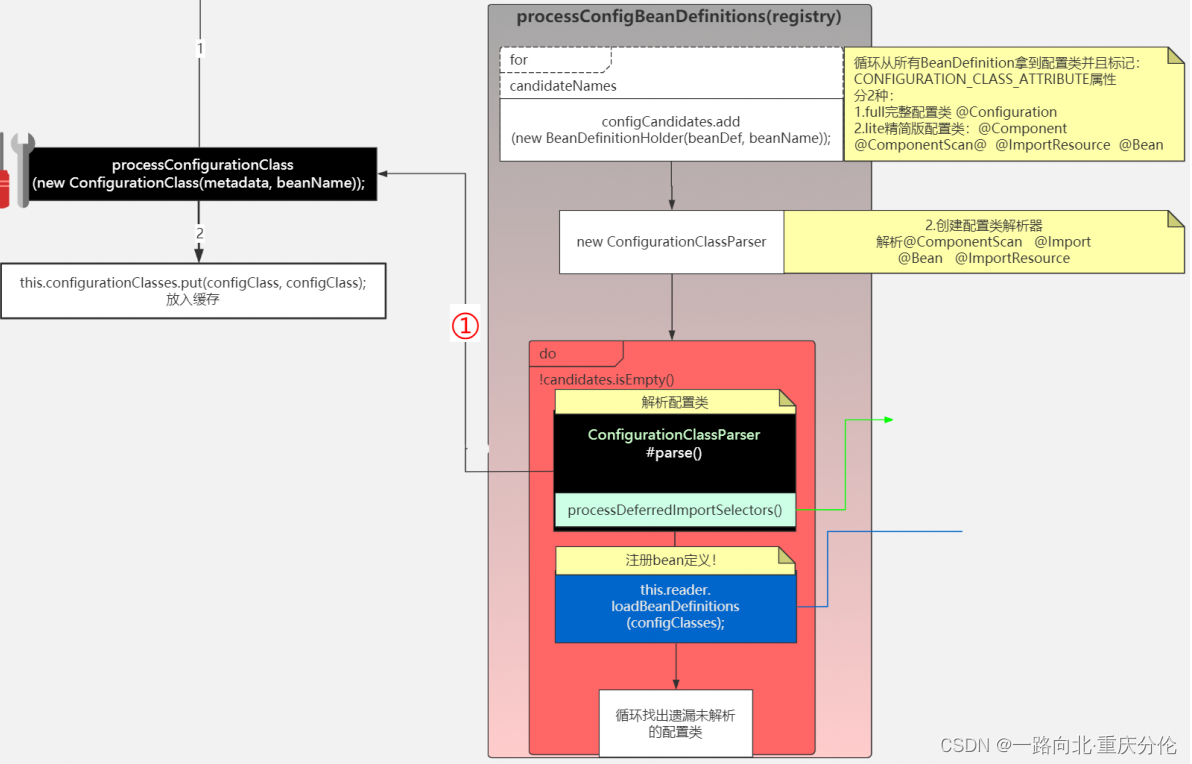
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
//获取IOC 容器中目前所有bean定义的名称
String[] candidateNames = registry.getBeanDefinitionNames();
//循环我们的上一步获取的所有的bean定义信息
for (String beanName : candidateNames) {
//通过bean的名称来获取我们的bean定义对象
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
//判断是否有没有解析过
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) ||
ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
//进行正在的解析判断是不是完全的配置类 还是一个非正式的配置类
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
//满足添加 就加入到候选的配置类集合中
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// 若没有找到配置类 直接返回
if (configCandidates.isEmpty()) {
return;
}
//对我们的配置类进行Order排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// 创建我们通过@CompentScan导入进来的bean name的生成器
// 创建我们通过@Import导入进来的bean的名称
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
//设置@CompentScan导入进来的bean的名称生成器(默认类首字母小写)也可以自己定义,一般不会
this.componentScanBeanNameGenerator = generator;
//设置@Import导入进来的bean的名称生成器(默认类首字母小写)也可以自己定义,一般不会
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
//创建一个配置类解析器对象
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
//用于保存我们的配置类BeanDefinitionHolder放入上面筛选出来的配置类
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
//用于保存我们的已经解析的配置类,长度默认为解析出来默认的配置类的集合长度
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
//do while 会进行第一次解析
do {
//真正的解析我们的配置类
parser.parse(candidates);
parser.validate();
//解析出来的配置类
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 此处才把@Bean的方法和@Import 注册到BeanDefinitionMap中
this.reader.loadBeanDefinitions(configClasses);
//加入到已经解析的集合中
alreadyParsed.addAll(configClasses);
candidates.clear();
//判断我们ioc容器中的是不是>候选原始的bean定义的个数
if (registry.getBeanDefinitionCount() > candidateNames.length) {
//获取所有的bean定义
String[] newCandidateNames = registry.getBeanDefinitionNames();
//原始的老的候选的bean定义
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
//赋值已经解析的
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
//表示当前循环的还没有被解析过
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
//判断有没有被解析过
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
//存在没有解析过的 需要循环解析
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}
- 获得所有的BeanName,放入candidateNames数组。
- 循环candidateNames数组,根据beanName获得BeanDefinition,判断此BeanDefinition是否已经被处理过了。
- 判断是否是配置类,如果是的话。加入到configCandidates数组,在判断的时候,还会标记配置类属于Full配置类,还是Lite配置类,这里会引发一连串的知识盲点:
3.1 当我们注册配置类的时候,可以不加@Configuration注解,直接使用@Component @ComponentScan @Import
@ImportResource等注解,Spring把这种配置类称之为Lite配置类,如果加了@Configuration注解,就称之为Full配置类。
3.2 如果我们注册了Lite配置类,我们getBean这个配置类,会发现它就是原本的那个配置类,如果我们注册了Full配置类,我们getBean这个配置类,会发现它已经不是原本那个配置类了,而是已经被cgilb代理的类了。
3.3 写一个A类,其中有一个构造方法,打印出“你好”,再写一个配置类,里面有两个被@bean注解的方法,其中一个方法new了A类,并且返回A的对象,把此方法称之为getA,第二个方法又调用了getA方法,如果配置类是Lite配置类,会发现打印了两次“你好”,也就是说A类被new了两次,如果配置类是Full配置类,会发现只打印了一次“你好”,也就是说A类只被new了一次,因为这个类被cgilb代理了,方法已经被改写。 - 如果没有配置类直接返回。
- 处理排序。
- 解析配置类,可能是Full配置类,也有可能是Lite配置类,这个小方法是此方法的核心,稍后具体说明。
- 在第6步的时候,只是注册了部分Bean,像 @Import @Bean等,是没有被注册的,这里统一对这些进行注册。
下面是解析配置类的过程:
public void parse(Set<BeanDefinitionHolder> configCandidates) {
/**
* 用于来保存延时的ImportSelectors,最最最著名的代表就是我们的SpringBoot自动装配的的类 AutoConfigurationImportSelector
*/
this.deferredImportSelectors = new LinkedList<>();
// 循环配置类
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
//真正的解析我们的bean定义 :通过注解元数据 解析
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
//处理我们延时的DeferredImportSelectors w我们springboot就是通过这步进行记载spring.factories文件中的自定装配的对象
processDeferredImportSelectors();
}
因为可以有多个配置类,所以需要循环处理。我们的配置类的BeanDefinition是AnnotatedBeanDefinition的实例,所以会进入第一个if:
/**
* 真的解析我们的配置类
* @param metadata 配置类的源信息
* @param beanName 当前配置类的beanName
* @throws IOException
*/
protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException {
/**
* 第一步:把我们的配置类源信息和beanName包装成一个ConfigurationClass 对象
*/
processConfigurationClass(new ConfigurationClass(metadata, beanName));
}
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
//获取处我们的配置类对象
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
//传入进来的配置类是通过其他配置类的Import导入进来的
if (configClass.isImported()) {
if (existingClass.isImported()) {
//需要合并配置
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
// 所以假如通过@Import导入一个 已存在的配置类 是不允许的,会忽略。
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.递归处理配置类及其超类层次结构。
SourceClass sourceClass = asSourceClass(configClass);
//真正的进行配置类的解析
do {
//解析我们的配置类
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
重点在于doProcessConfigurationClass方法,需要特别注意,最后一行代码,会把configClass放入一个Map,会在上面第7步中用到。
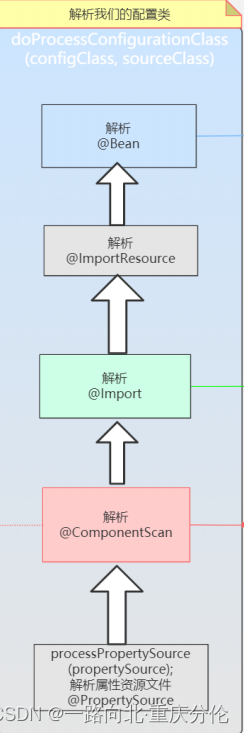
@Nullable
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass);
//处理我们的@propertySource注解的
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.warn("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
//解析我们的 @ComponentScan 注解
//从我们的配置类上解析处ComponentScans的对象集合属性
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
//循环解析 我们解析出来的AnnotationAttributes
for (AnnotationAttributes componentScan : componentScans) {
//把我们扫描出来的类变为bean定义的集合 真正的解析
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
//循环处理我们包扫描出来的bean定义
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
//判断当前扫描出来的bean定义是不是一个配置类,若是的话 直接进行递归解析
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
//递归解析 因为@Component算是lite配置类
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// 处理 @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), true);
// 处理 @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// 处理 @Bean methods 获取到我们配置类中所有标注了@Bean的方法
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// 处理配置类接口 默认方法的@Bean
processInterfaces(configClass, sourceClass);
// 处理配置类的父类的 ,循环再解析
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// 没有父类解析完成
return null;
}
- 递归处理内部类,一般不会使用内部类。
- 处理@PropertySource注解,@PropertySource注解用来加载properties文件。
- 获得ComponentScan注解具体的内容,ComponentScan注解除了最常用的basePackage之外,还有includeFilters,excludeFilters等。
- 判断有没有被@ComponentScans标记,或者被@Condition条件带过,如果满足条件的话,进入if,进行如下操作:
4.1 执行扫描操作,把扫描出来的放入set,这个方法稍后再详细说明。
4.2 循环set,判断是否是配置类,是的话,递归调用parse方法,因为被扫描出来的类,还是一个配置类,有@ComponentScans注解,或者其中有被@Bean标记的方法 等等,所以需要再次被解析。 - 处理@Import注解,@Import是Spring中很重要的一个注解,正是由于它的存在,让Spring非常灵活,不管是Spring内部,还
是与Spring整合的第三方技术,都大量的运用了@Import注解,@Import有三种情况,一种是Import普通类,一种是Import
ImportSelector,还有一种是Import ImportBeanDefinitionRegistrar,getImports(sourceClass)是获得import的内容,返回的是一个set,这个方法稍后再详细说明。 - 处理@ImportResource注解。
- 处理@Bean的方法,可以看到获得了带有@Bean的方法后,不是马上转换成BeanDefinition,而是先用一个set接收。
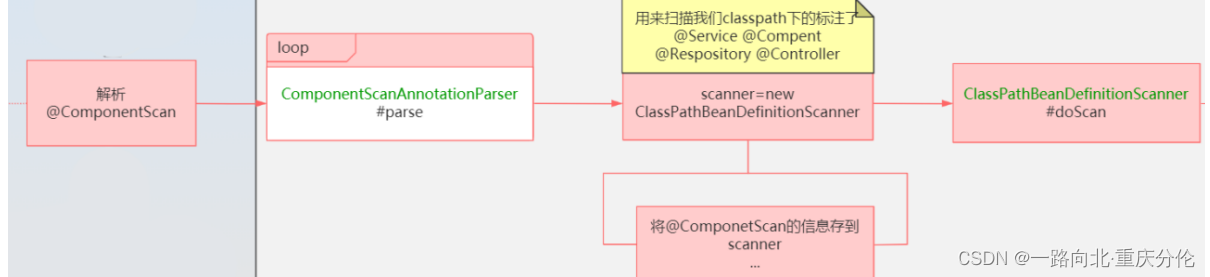
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
//为我们的扫描器设置beanName的生成器对象
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
/**
* 解析@Scope的ProxyMode属性, 该属性可以将Bean创建问jdk代理或cglib代理
*/
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
//设置CompentScan对象的includeFilters 包含的属性
for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addIncludeFilter(typeFilter);
}
}
//设置CompentScan对象的excludeFilters 包含的属性
for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addExcludeFilter(typeFilter);
}
}
/**
* 是否懒加载,此懒加载为componentScan延迟加载所有类
*/
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
//包路径com.tuling.iocbeanlifecicle
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
//真正的进行扫描解析
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
- 定义了一个扫描器scanner,还记不记在new AnnotationConfigApplicationContext的时候,会调用AnnotationConfigApplicationContext的构造方法,构造方法里面有一句 this.scanner = new
ClassPathBeanDefinitionScanner(this);当时说这个对象不重要,这里就是证明了。常规用法中,实际上执行扫描的只会是这里的scanner对象。 - 处理includeFilters,就是把规则添加到scanner。
- 处理excludeFilters,就是把规则添加到scanner。
- 解析basePackages,获得需要扫描哪些包。
- 添加一个默认的排除规则:排除自身。
- 执行扫描,稍后详细说明。
这里需要做一个补充说明,添加规则的时候,只是把具体的规则放入规则类的集合中去,规则类是一个函数式接口,只定义了一个虚方法的接口被称为函数式接口,函数式接口在java8的时候大放异彩,这里只是把规则方塞进去,并没有真正执行匹配规则。我们来看看到底是怎么执行扫描的:
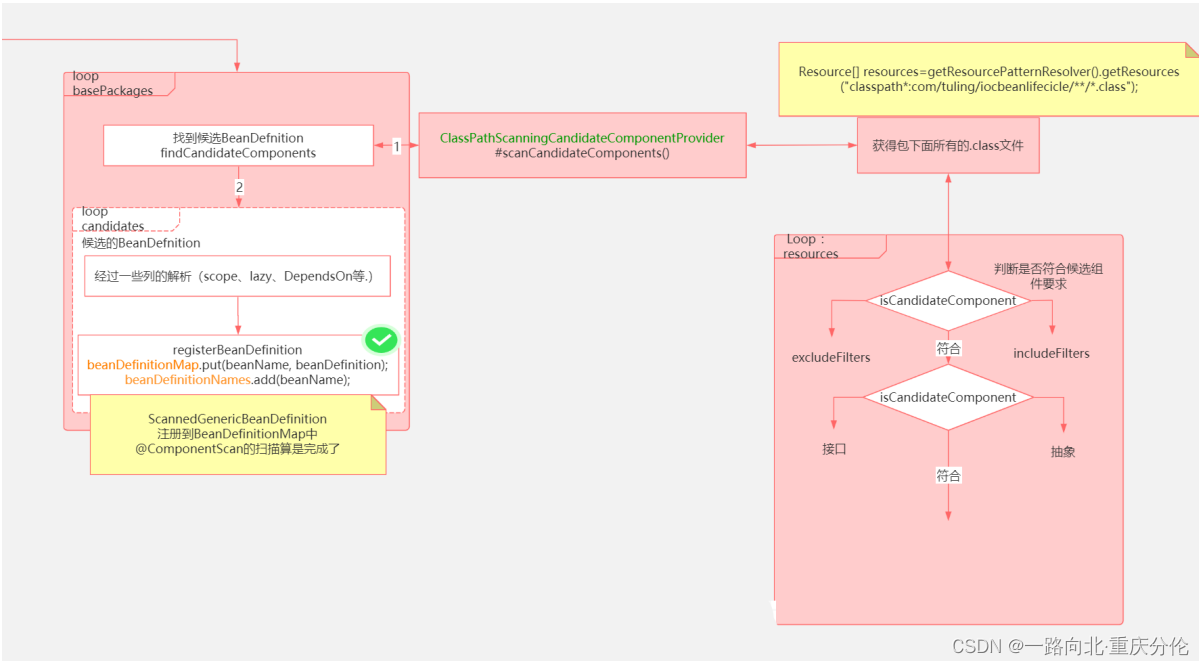
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
//创建bean定义的holder对象用于保存扫描后生成的bean定义对象
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
//循环我们的包路径集合
for (String basePackage : basePackages) {
//找到候选的Components
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
//设置我们的beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//这是默认配置 autowire-candidate
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//获取@Lazy @DependsOn等注解的数据设置到BeanDefinition中
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//把我们解析出来的组件bean定义注册到我们的IOC容器中(容器中没有才注册)
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
因为basePackages可能有多个,所以需要循环处理,最终会进行Bean的注册。下面再来看看findCandidateComponents方法:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
Spring支持component索引技术,需要引入一个组件,大部分项目没有引入这个组件,所以会进入scanCandidateComponents方法:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
//把我们的包路径转为资源路径 cn/tulingxueyuan/MainConfig
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
//扫描指定包路径下面的所有.class文件
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
//需要我们的resources集合
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
//判断当的是不是可读的
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
//是不是候选的组件
if (isCandidateComponent(metadataReader)) {
//包装成为一个ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
//并且设置class资源
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
//加入到集合中
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
//返回
return candidates;
}
- 把传进来的类似命名空间形式的字符串转换成类似类文件地址的形式,然后在前面加上classpath,即:
com.xx=>classpath:com/xx/**/*.class。 - 根据packageSearchPath,获得符合要求的文件。
- 循环符合要求的文件,进一步进行判断。
最终会把符合要求的文件,转换为BeanDefinition,并且返回。
@Import解析:
直到这里,上面说的4.1中提到的方法终于分析完毕了,让我们再看看上面提到的第5步中的处理@Import注解方法:

//这个方法内部相当相当复杂,importCandidates是Import的内容,调用这个方法的时候,已经说过可能有三种情况
//这里再说下,1.Import普通类,2.Import ImportSelector,3.Import ImportBeanDefinitionRegistrar
//循环importCandidates,判断属于哪种情况
//如果是普通类,会进到else,调用processConfigurationClass方法
//这个方法是不是很熟悉,没错,processImports这个方法就是在processConfigurationClass方法中被调用的
//processImports又主动调用processConfigurationClass方法,是一个递归调用,因为Import的普通类,也有可能被加了Import注解,@ComponentScan注解 或者其他注解,所以普通类需要再次被解析
//如果Import ImportSelector就跑到了第一个if中去,首先执行Aware接口方法,所以我们在实现ImportSelector的同时,还可以实现Aware接口
//然后判断是不是DeferredImportSelector,DeferredImportSelector扩展了ImportSelector
//如果不是的话,调用selectImports方法,获得全限定类名数组,在转换成类的数组,然后再调用processImports,又特么的是一个递归调用...
//可能又有三种情况,一种情况是selectImports的类是一个普通类,第二种情况是selectImports的类是一个ImportBean DefinitionRegistrar类,第三种情况是还是一个ImportSelector类...
//所以又需要递归调用
//如果Import ImportBeanDefinitionRegistrar就跑到了第二个if,还是会执行Aware接口方法,这里终于没有递归了,会把数据放到ConfigurationClass中的Map<ImportBeanDefinitionRegistrar, AnnotationMetadata> importBeanDefinitionRegistrars中去
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, boolean checkForCircularImports) {
if (importCandidates.isEmpty()) {
return;
}
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
//获取我们Import导入进来的所有组件
for (SourceClass candidate : importCandidates) {
//判断该组件是不是实现了ImportSelector的
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
Class<?> candidateClass = candidate.loadClass();
//实例化我们的SelectImport组件
ImportSelector selector = BeanUtils.instantiateClass(candidateClass, ImportSelector.class);
//调用相关的aware方法
ParserStrategyUtils.invokeAwareMethods(
selector, this.environment, this.resourceLoader, this.registry);
//判断是不是延时的DeferredImportSelectors,是这个类型 不进行处理
if (this.deferredImportSelectors != null && selector instanceof DeferredImportSelector) {
this.deferredImportSelectors.add(
new DeferredImportSelectorHolder(configClass, (DeferredImportSelector) selector));
}
else {//不是延时的
//调用selector的selectImports
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
// 所以递归解析-- 直到成普通组件
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames);
processImports(configClass, currentSourceClass, importSourceClasses, false);
}
}
//判断我们导入的组件是不是ImportBeanDefinitionRegistrar,这里不直接调用,只是解析
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
// Candidate class is an ImportBeanDefinitionRegistrar ->
// delegate to it to register additional bean definitions
Class<?> candidateClass = candidate.loadClass();
//实例话我们的ImportBeanDefinitionRegistrar对象
ImportBeanDefinitionRegistrar registrar =
BeanUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class);
ParserStrategyUtils.invokeAwareMethods(
registrar, this.environment, this.resourceLoader, this.registry);
//保存我们的ImportBeanDefinitionRegistrar对象 currentSourceClass=所在配置类
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
// 当做配置类再解析,注意这里会标记:importedBy, 表示这是Import的配置的类
// 再执行之前的processConfigurationClass()方法 ,
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass));
}
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configClass.getMetadata().getClassName() + "]", ex);
}
finally {
this.importStack.pop();
}
}
}
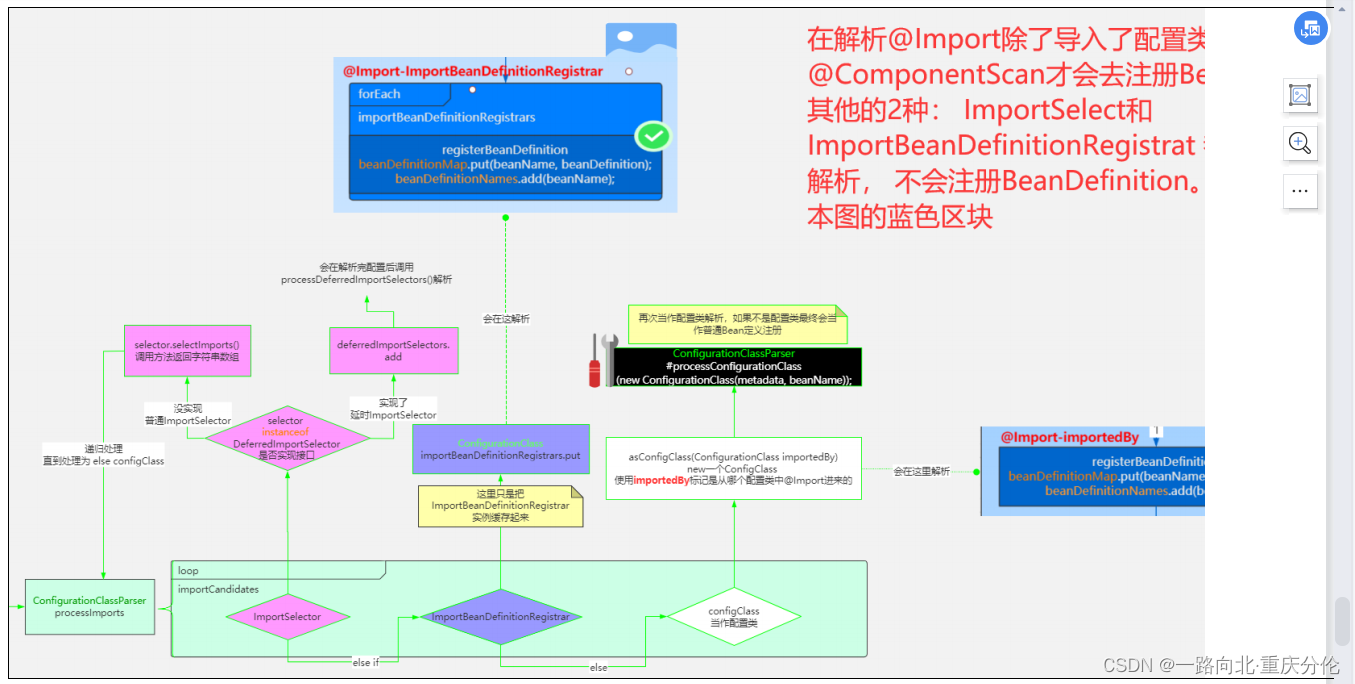
这个方法大概的作用已经在注释中已经写明了,就不再重复了。
直到这里,才把ConfigurationClassPostProcessor中的processConfigBeanDefinitions方法简单的过了一下。但是这还没有结束,这里只会解析@Import的Bean而已, 不会注册。
后续还有个点:processConfigBeanDefinitions是BeanDefinitionRegistryPostProcessor接口中的方法,
BeanDefinitionRegistryPostProcessor扩展了BeanFactoryPostProcessor,还有postProcessBeanFactory方法没有分析,这个方法是
干嘛的,简单的来说,就是判断配置类是Lite配置类,还是Full配置类,如果是配置类,就会被Cglib代理,目的就是保证Bean的作用域。
关于这个方法实在是比较复杂,课程中讲解。
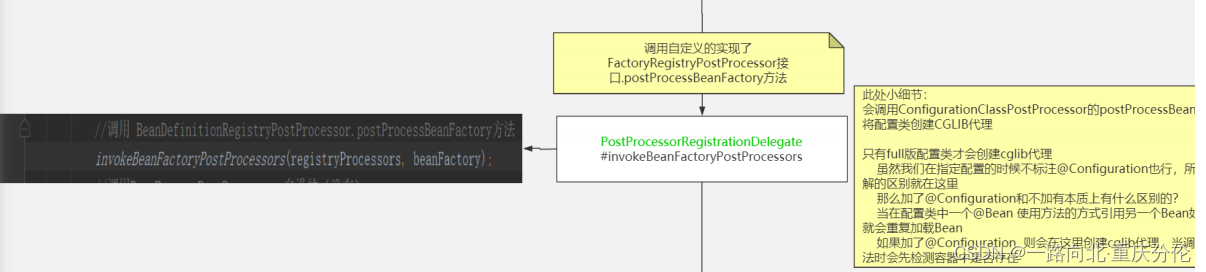
总结,ConfigurationClassPostProcessor中的processConfigBeanDefinitions方法十分重要,主要是完成扫描,最终注册
我们定义的Bean。
6.6-registerBeanPostProcessors(beanFactory);
实例化和注册beanFactory中扩展了BeanPostProcessor的bean。
例如:
AutowiredAnnotationBeanPostProcessor(处理被@Autowired注解修饰的bean并注入)
RequiredAnnotationBeanPostProcessor(处理被@Required注解修饰的方法)
CommonAnnotationBeanPostProcessor(处理@PreDestroy、@PostConstruct、@Resource等多个注解的作用)等。

6.7-initMessageSource()
// 初始化国际化资源处理器. 不是主线代码忽略,没什么学习价值。
initMessageSource();
6.8-initApplicationEventMulticaster()
// 创建事件多播器
事件相关会单独讲解:Spring事件监听机制
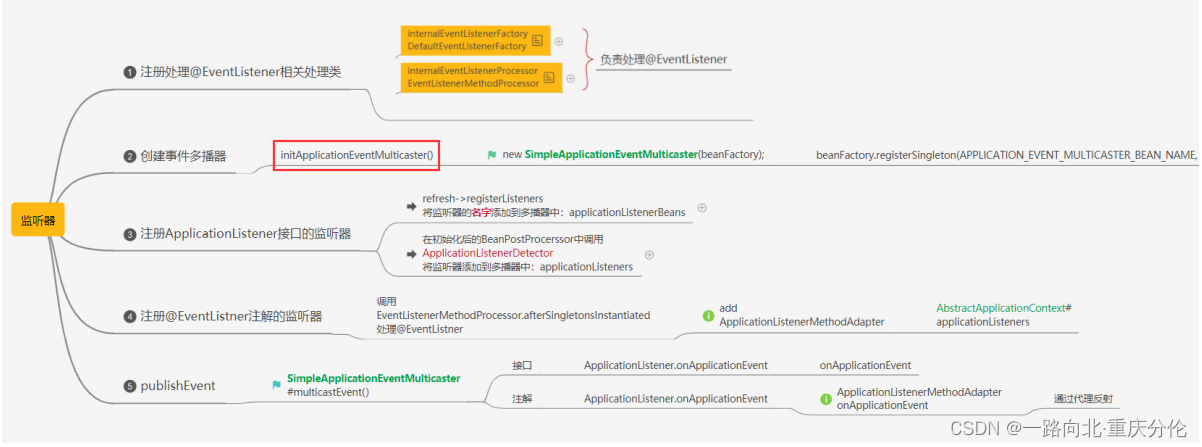
6.9-onRefresh();
模板方法,在容器刷新的时候可以自定义逻辑,不同的Spring容器做不同的事情。
6.10-registerListeners();
注册监听器,广播early application events
事件相关会单独讲解:Spring事件监听机制
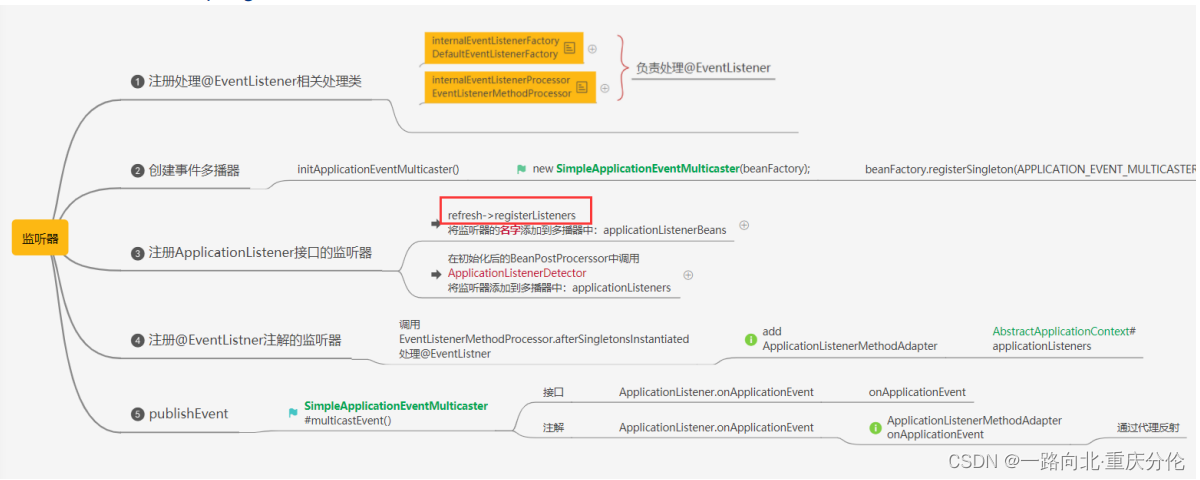
6-11-finishBeanFactoryInitialization(beanFactory);
实例化所有剩余的(非懒加载)单例
比如invokeBeanFactoryPostProcessors方法中根据各种注解解析出来的类,在这个时候都会被初始化。
实例化的过程各种BeanPostProcessor开始起作用。
这个方法是用来实例化懒加载单例Bean的,也就是我们的Bean都是在这里被创建出来的(当然我这里说的的是绝大部分情况是这样的):
finishBeanFactoryInitialization(beanFactory);
我们再进入finishBeanFactoryInitialization这方法,里面有一个beanFactory.preInstantiateSingletons()方法:
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// 为我们的bean工厂创建类型转化器 Convert
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
/**
* public class MainConfig implements EmbeddedValueResolverAware{
*
* public void setEmbeddedValueResolver(StringValueResolver resolver) {
this.jdbcUrl = resolver.resolveStringValue("${ds.jdbcUrl}");
this.classDriver = resolver.resolveStringValue("${ds.classDriver}");
}
}
*/
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// 处理关于aspectj
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
//冻结所有的 bean 定义 , 说明注册的 bean 定义将不被修改或任何进一步的处理
beanFactory.freezeConfiguration();
//实例化剩余的单实例bean
beanFactory.preInstantiateSingletons();
}
我们尝试再点进去,这个时候你会发现这是一个接口,好在它只有一个实现类,所以可以我们来到了他的唯一实现,实现类就是org.springframework.beans.factory.support.DefaultListableBeanFactory,这里面是一个循环,我们的Bean就是循环被创建出来的,我们找到其中的getBean方法:
public void preInstantiateSingletons() throws BeansException {
if (logger.isDebugEnabled()) {
logger.debug("Pre-instantiating singletons in " + this);
}
//获取我们容器中所有bean定义的名称
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
//循环我们所有的bean定义名称
for (String beanName : beanNames) {
//合并我们的bean定义,转换为统一的RootBeanDefinition类型(在), 方便后续处理
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
/**
* 根据bean定义判断是不是抽象的&& 不是单例的 &&不是懒加载的
*/
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
//是不是工厂bean
if (isFactoryBean(beanName)) {
// 是factoryBean会先生成实际的bean &beanName 是用来获取实际bean的
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
//调用真正的getBean的流程
if (isEagerInit) {
getBean(beanName);
}
}
}
else {//非工厂Bean 就是普通的bean
getBean(beanName);
}
}
}
//或有的bean的名称 ...........到这里所有的单实例的bean已经记载到单实例bean到缓存中
for (String beanName : beanNames) {
//从单例缓存池中获取所有的对象
Object singletonInstance = getSingleton(beanName);
//判断当前的bean是否实现了SmartInitializingSingleton接口
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
//触发实例化之后的方法afterSingletonsInstantiated
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
//调用真正的getBean的流程
if (isEagerInit) {
getBean(beanName);
}
这里有一个分支,如果Bean是FactoryBean,如何如何,如果Bean不是FactoryBean如何如何,好在不管是不是FactoryBean,最终还是会调用getBean方法,所以我们可以毫不犹豫的点进去,点进去之后,你会发现,这是一个门面方法,直接调用了doGetBean方法。
@Override
public Object getBean(String name) throws BeansException {
//真正的获取bean的逻辑
return doGetBean(name, null, null, false);
}
再进去,不断的深入,接近我们要寻找的东西。
这里面的比较复杂,但是有我在,我可以直接告诉你,下一步我们要进入哪里,我们要进入
//创建单例bean
if (mbd.isSingleton()) {
//把beanName 和一个singletonFactory 并且传入一个回调对象用于回调
sharedInstance = getSingleton(beanName, () -> {
try {
//进入创建bean的逻辑
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
//创建bean的过程中发生异常,需要销毁关于当前bean的所有信息
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
这里面的createBean方法,再点进去啊,但是又点不进去了,这是接口啊,但是别慌,这个接口又只有一个实现类,所以说 没事,就是干,这个实现类为org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory。这个实现的方法里面又做了很多事情,我们就不去看了,我就是带着大家找到那几个生命周期的回调到底定义在哪里就OK了。
/**
* 该步骤是我们真正的创建我们的bean的实例对象的过程
*/
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
再继续深入doCreateBean方法,这个方法又做了一堆一堆的事情,但是值得开心的事情就是 我们已经找到了我们要寻找的东西了。 创建实例。
首先是创建实例,位于:
if (instanceWrapper == null) {
//创建bean实例化 使用合适的实例化策略来创建新的实例:工厂方法、构造函数自动注入、简单初始化 该方法很复杂也很重要
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
填充属性
其次是填充属性,位于:
//属性赋值 给我们的属性进行赋值(调用set方法进行赋值)
populateBean(beanName, mbd, instanceWrapper);
在填充属性下面有一行代码:
//进行对象初始化操作(在这里可能生成代理对象)
exposedObject = initializeBean(beanName, exposedObject, mbd);
继续深入进去。
aware系列接口的回调
aware系列接口的回调位于initializeBean中的invokeAwareMethods方法:
//若我们的bean实现了XXXAware接口进行方法的回调
invokeAwareMethods(beanName, bean);
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
//我们的bean实现了BeanNameAware
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
//实现了BeanClassLoaderAware接口
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
//实现了BeanFactoryAware
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
BeanPostProcessor的postProcessBeforeInitialization方法
BeanPostProcessor的postProcessBeforeInitialization方法位于initializeBean的
if (mbd == null || !mbd.isSynthetic()) {
//调用我们的bean的后置处理器的postProcessorsBeforeInitialization方法 @PostCust注解的方法
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
@Override
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
//获取我们容器中的所有的bean的后置处理器
for (BeanPostProcessor processor : getBeanPostProcessors()) {
//挨个调用我们的bean的后置处理器的postProcessBeforeInitialization
Object current = processor.postProcessBeforeInitialization(result, beanName);
//若只有有一个返回null 那么直接返回原始的
if (current == null) {
return result;
}
result = current;
}
return result;
}
afterPropertiesSet init-method
afterPropertiesSet init-method位于initializeBean中的
invokeInitMethods(beanName, wrappedBean, mbd);
这里面调用了两个方法,一个是afterPropertiesSet方法,一个是init-method方法:
//回调InitializingBean的afterPropertiesSet()方法
((InitializingBean) bean).afterPropertiesSet();
invokeCustomInitMethod(beanName, bean, mbd);
BeanPostProcessor的postProcessAfterInitialization方法
BeanPostProcessor的postProcessAfterInitialization方法位于initializeBean的
if (mbd == null || !mbd.isSynthetic()) {
//调用我们的bean的后置处理器的postProcessorsBeforeInitialization方法 @PostCust注解的方法
@Override
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
//获取我们容器中的所有的bean的后置处理器
for (BeanPostProcessor processor : getBeanPostProcessors()) {
//挨个调用我们的bean的后置处理器的postProcessBeforeInitialization
Object current = processor.postProcessBeforeInitialization(result, beanName);
//若只有有一个返回null 那么直接返回原始的
if (current == null) {
return result;
}
result = current;
}
return result;
}
当然在实际的开发中,应该没人会去销毁Spring的应用上下文把,所以剩余的两个销毁的回调就不去找了。
Spring Bean的生命周期
Spring In Action以及市面上流传的大部分博客是这样的:
- 实例化Bean对象,这个时候Bean的对象是非常低级的,基本不能够被我们使用,因为连最基本的属性都没有设置,可以理解为连Autowired注解都是没有解析的;
- 填充属性,当做完这一步,Bean对象基本是完整的了,可以理解为Autowired注解已经解析完毕,依赖注入完成了;
- 如果Bean实现了BeanNameAware接口,则调用setBeanName方法;
- 如果Bean实现了BeanClassLoaderAware接口,则调用setBeanClassLoader方法;
- 如果Bean实现了BeanFactoryAware接口,则调用setBeanFactory方法;
- 调用BeanPostProcessor的postProcessBeforeInitialization方法;
- 如果Bean实现了InitializingBean接口,调用afterPropertiesSet方法;
- 如果Bean定义了init-method方法,则调用Bean的init-method方法;
- 调用BeanPostProcessor的postProcessAfterInitialization方法;当进行到这一步,Bean已经被准备就绪了,一直停留在应用的上下文中,直到被销毁;
- 如果应用的上下文被销毁了,如果Bean实现了DisposableBean接口,则调用destroy方法,如果Bean定义了destory-method声明了销毁方法也会被调用。
6-12-finishRefresh();
refresh做完之后需要做的其他事情。
清除上下文资源缓存(如扫描中的ASM元数据)
初始化上下文的生命周期处理器,并刷新(找出Spring容器中实现了Lifecycle接口的bean并执行start()方法)。
发布ContextRefreshedEvent事件告知对应的ApplicationListener进行响应的操作。
protected void finishRefresh() {
// Clear context-level resource caches (such as ASM metadata from scanning).清除上下文级别的资源缓存(例如来自扫描的ASM元数据)
clearResourceCaches();
// Initialize lifecycle processor for this context.
// 注册lifecycleProcessor 声明周期处理器
// 作用:当ApplicationContext启动或停止时,它会通过LifecycleProcessor来与所有声明的bean的周期做状态更新
initLifecycleProcessor();
// Propagate refresh to lifecycle processor first.
// 为实现了SmartLifecycle并且isAutoStartup 自动启动的Lifecycle调用start()方法
getLifecycleProcessor().onRefresh();
// Publish the final event.
// 发布容器启动完毕事件
publishEvent(new ContextRefreshedEvent(this));
// Participate in LiveBeansView MBean, if active.
// 注册当前spring容器到LiveBeansView
// 提供servlet(LiveBeansViewServlet)在线查看所有的bean json 、 为了支持Spring Tool Suite的智能提示
LiveBeansView.registerApplicationContext(this);
}
1:这里单独介绍下publishEvent
protected void publishEvent(Object event, @Nullable ResolvableType eventType) {
Assert.notNull(event, "Event must not be null");
if (logger.isTraceEnabled()) {
logger.trace("Publishing event in " + getDisplayName() + ": " + event);
}
// Decorate event as an ApplicationEvent if necessary
ApplicationEvent applicationEvent;
if (event instanceof ApplicationEvent) {
applicationEvent = (ApplicationEvent) event;
}
else {
applicationEvent = new PayloadApplicationEvent<>(this, event);
if (eventType == null) {
eventType = ((PayloadApplicationEvent<?>) applicationEvent).getResolvableType();
}
}
// Multicast right now if possible - or lazily once the multicaster is initialized
// 这里是唯一添加早期事件的地方。所以一定要发布事件才能添加早期事件
// 只有当执行力refresh-->registerListeners 才会将earlyApplicationEvents赋为null,所以registerListeners之前发布的事件都是早期事件
if (this.earlyApplicationEvents != null) {
this.earlyApplicationEvents.add(applicationEvent);
}
else {
getApplicationEventMulticaster().multicastEvent(applicationEvent, eventType);
}
// Publish event via parent context as well...
// 如果是父容器,也会向父容器里广播一份
if (this.parent != null) {
if (this.parent instanceof AbstractApplicationContext) {
((AbstractApplicationContext) this.parent).publishEvent(event, eventType);
}
else {
this.parent.publishEvent(event);
}
}
}
2.使用事件广播器广播事件到相应的监听器multicastEvent
@Override
public void multicastEvent(final ApplicationEvent event, @Nullable ResolvableType eventType) {
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
//从多播器中获取出所有的监听器
for (final ApplicationListener<?> listener : getApplicationListeners(event, type)) {
//判断多播器中是否支持异步多播的
Executor executor = getTaskExecutor();
if (executor != null) {
//异步播发事件
executor.execute(() -> invokeListener(listener, event));
}
else {//同步播发
invokeListener(listener, event);
}
}
}
3.2 调用监听器invokeListener
protected void invokeListener(ApplicationListener<?> listener, ApplicationEvent event) {
ErrorHandler errorHandler = getErrorHandler();
if (errorHandler != null) {
try {
doInvokeListener(listener, event);
}
catch (Throwable err) {
errorHandler.handleError(err);
}
}
else {
doInvokeListener(listener, event);
}
}
doInvokeListener(listener, event);
private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) {
try {
listener.onApplicationEvent(event);
}
catch (ClassCastException ex) {
String msg = ex.getMessage();
if (msg == null || matchesClassCastMessage(msg, event.getClass())) {
// Possibly a lambda-defined listener which we could not resolve the generic event type for
// -> let's suppress the exception and just log a debug message.
Log logger = LogFactory.getLog(getClass());
if (logger.isDebugEnabled()) {
logger.debug("Non-matching event type for listener: " + listener, ex);
}
}
else {
throw ex;
}
}
}
这样,当 Spring 执行到 finishRefresh 方法时,就会将 ContextRefreshedEvent 事件推送到MyRefreshedListener 中。跟ContextRefreshedEvent 相似的还有:ContextStartedEvent、ContextClosedEvent、ContextStoppedEvent,有兴趣的可以自己看看这几个事件的使用场景。当然,我们也可以自定义监听事件,只需要继承 ApplicationContextEvent 抽象类即可。
问题:
1.BeanFactory和FactoryBean的区别?
2.请介绍BeanFactoryPostProcessor在Spring中的用途。
3.SpringIoC的加载过程。
4.Bean的生命周期。
5.Spring中有哪些扩展接口及调用时机


![[附源码]Node.js计算机毕业设计高校教务管理系统Express](https://img-blog.csdnimg.cn/1e17b6b9ec6d40f197c2ba7819d0765b.png)



![[附源码]计算机毕业设计的网上点餐系统Springboot程序](https://img-blog.csdnimg.cn/86f742bd67ab44738fe16aa907107c4a.png)