文章目录
- 链接
- 主要贡献
- 模型
- 一些思考
- 啥是Q-former
- 为什么position embedding可以辅助学到temporal的信息
- 代码
- 视觉处理
- 一些惊喜
链接
https://github.com/DAMO-NLP-SG/Video-LLaMA
主要贡献
- 能够捕捉到一小小短时间(temporal)里视觉的变化
- 使用了Q-former 去做视频上的encoding,通过 视频转文字的方式去做理解 - 符合人类对视频理解的套路,即声音+视觉 信号
- 套用了Facebook的 imagebind 给 LLM 做多模态的embedding的buff, 不然介于语音数据的稀有,如果没有 imagebind, 那么就不太能将语音的信息用进去
模型
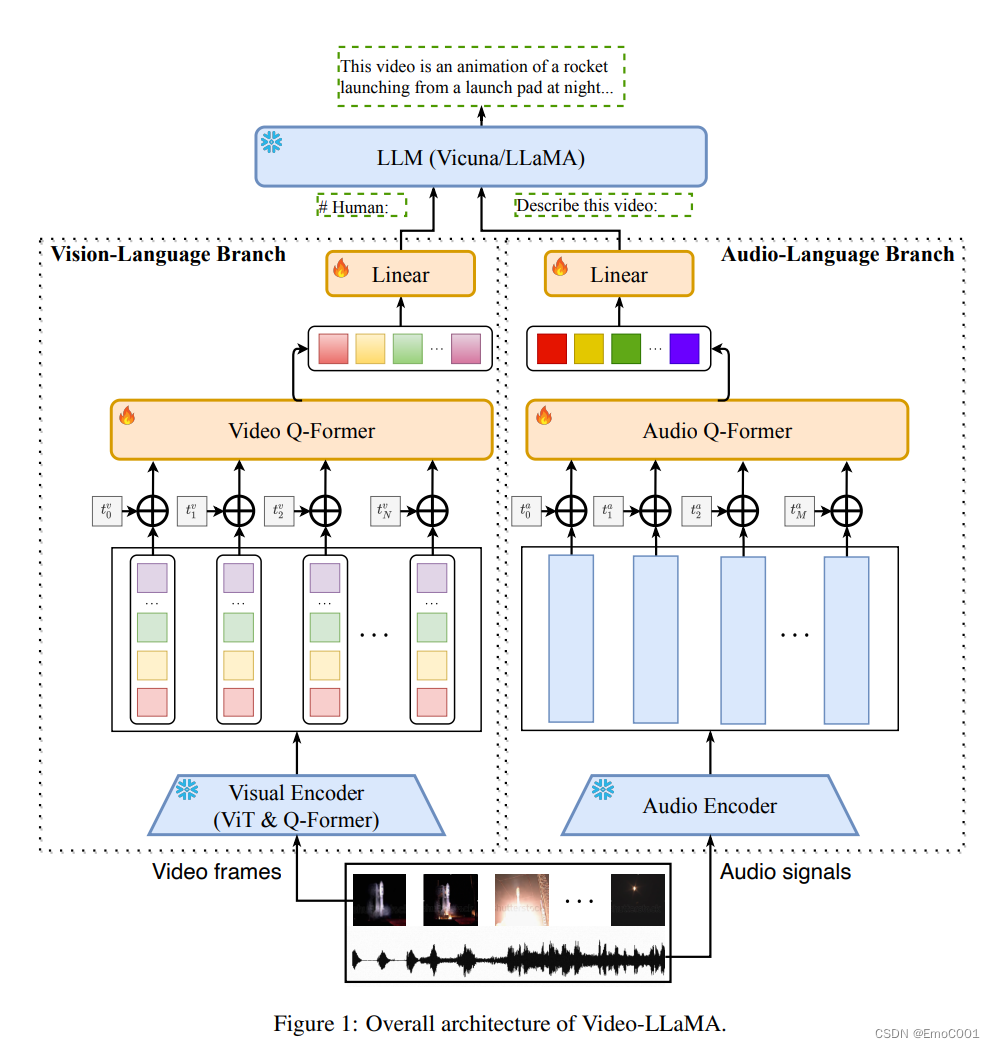
整个模型,蓝色的blocks都是可以被拿来直接用的,橙色部分是一定要经过训练,以促成Llama video 模型正常联通使用的。
视觉和语音部分都大同小异:
相同点:
- 都使用了Qformer,并且通过其中learnable的 position 捕捉 temporal的信息
- 都用到了pretrained 的模型作为数据的encoder
- 数据是多份的(图像:每帧;语音:sample M 个 2秒片段。)
不同点:
4. 数据类型和格式
5. 根据数据类型对Qformer结构做了些调整
6. 图像encoder 用的是 Blip-2 中专门做图像语义理解的部分,这个部分的结构:EVA CLIP + Q-former
7. 语音encoder 用的是 Facebook 的 imagebind
模型训练是分段的:
第一阶段 : 粗训(相当于小朋友的兴趣班),用 图像-caption 数据
第二阶段 :精细训(相当于上完兴趣班再上专业集训),用质量高的数据(根据想要的效果来)。比如都是跳舞,但这里可以是专业芭蕾或者专业民族舞,再或者街舞
- 把图片当作1帧的视频来训练
一些思考
啥是Q-former
这个内容在 BLIP-2里。基本上video-lama 就是base在这个模型里改的。
为什么position embedding可以辅助学到temporal的信息
self.video_frame_position_embedding:
nn.Embedding(max_frame_pos, self.Qformer.config.hidden_size)
代码
整个代码里的部件权重加载在 video_llama.py完成,其中,尽管我们之前下载了那么多权重,但是依然有些权重需要临时下载并加载(一般在.cache这个folder):
例如:blip2_pretrained_flant5xxl.pth
和语音模型相关的由 LlamaForCausalLM处理:
Causal LM(CLM):This is the standard left-to-right auto-regressive language model pre-training, used in many standard pre-trained models, like GPT, LLaMA-7B
视觉Encoder: VideoQformer:
self.video_Qformer,self.video_query_tokens = self.init_video_Qformer(num_query_token = num_video_query_token,\
vision_width=self.Qformer.config.hidden_size, num_hidden_layers =2)
num_video_query_token = 32
hidden_size = 768
音频Encoder: Audio former:
ImageBind: video_llama/models/ImageBind/models/imagebind_model.py
self.audio_encoder,self.audio_hidden_size = \
imagebind_model.imagebind_huge()
num_video_query_token = 8
hidden_size = 1024
self.audio_Qformer,self.audio_query_tokens = self.init_video_Qformer(num_query_token = self.num_audio_query_token,\
vision_width=self.audio_hidden_size, num_hidden_layers =2)
视觉处理
video_llama/processors/video_processor.py
视频默认不管什么尺寸,进入Encoder前,都会被resize成224x224, 受限于transfomer attention的套路,等边长的resolution 比如 512x512, 768x768都可以用。在DETR的变种已经妥善处理了各种尺寸输入输出的问题。
不管输入多少秒的视频,目前都是均匀的从视频里抽8 个帧:
indices = np.arange(start, end, vlen / n_frms).astype(int).tolist()
视频处理resize还要经过mean std的normalisation的处理: (1,3,8,224,224)
然后放进encode_videoQformer_visual(), frame_hidden_state的结果和token接入到bert 得到 llama 相关的embedding,用于后续提问。
output: inputs_llama, atts_llama ===> img_list
问答在:
llm_message = chat.answer(conv=chat_state,
img_list=img_list,
num_beams=num_beams,
temperature=temperature,
max_new_tokens=300,
max_length=2000)[0]
一些惊喜
由于这个模型里的视频帧是均匀抽取8个帧,如果只有一秒的视频,那么很容易抽到的8张图都是一样的,那么描述就会像在说车轱辘话一样,来回重复并颠倒。因此,为了符合这个模型的特点,建议先用长一点的视频,再经过快进处理。这样模型可以能更好区分场景变化和理解视频,而不至于被相同的帧误导。