数据分析案例丨商品零售购物篮分析(上)
03
数据预处理
通过对数据探索分析,发现数据数据完整,并不存在缺失值。建模之前需要转变数据的格式,才能使用apriori函数进行关联分析。对数据进行转换,如代码清单1所示。
import pandas as pdinputfile='../data/GoodsOrder.csv'data = pd.read_csv(inputfile,encoding='gbk')# 根据id对“Goods”列合并,并使用“,”将各商品隔开data['Goods'] = data['Goods'].apply(lambda x:','+x)data = data.groupby('id').sum().reset_index()# 对合并的商品列转换数据格式data['Goods'] = data['Goods'].apply(lambda x :[x[1:]])data_list = list(data['Goods'])# 分割商品名为每个元素data_translation = []for i in data_list:p = i[0].split(',')data_translation.append(p)print('数据转换结果的前5个元素:\n', data_translation[0:5])
代码清单1
04
模型构建
本案例的目标是探索商品之间的关联关系,因此采用关联规则算法,挖掘它们之间的关联关系。关联规则算法主要用于寻找数据中项集之间的关联关系。它揭示了数据项间的未知关系,基于样本的统计规律,进行关联规则分析。根据所分析的关联关系,可从一个属性的信息来推断另一个属性的信息。当置信度达到某一阈值时,就可以认为规则成立。Apriori算法是常用的关联规则算法之一,也是最为经典的分析频繁项集的算法,第一次实现在大数据集上可行的关联规则提取的算法。除此之外,还有FP-Tree算法,Eclat算法和灰色关联算法等。本案例主要使用Apriori算法进行分析。
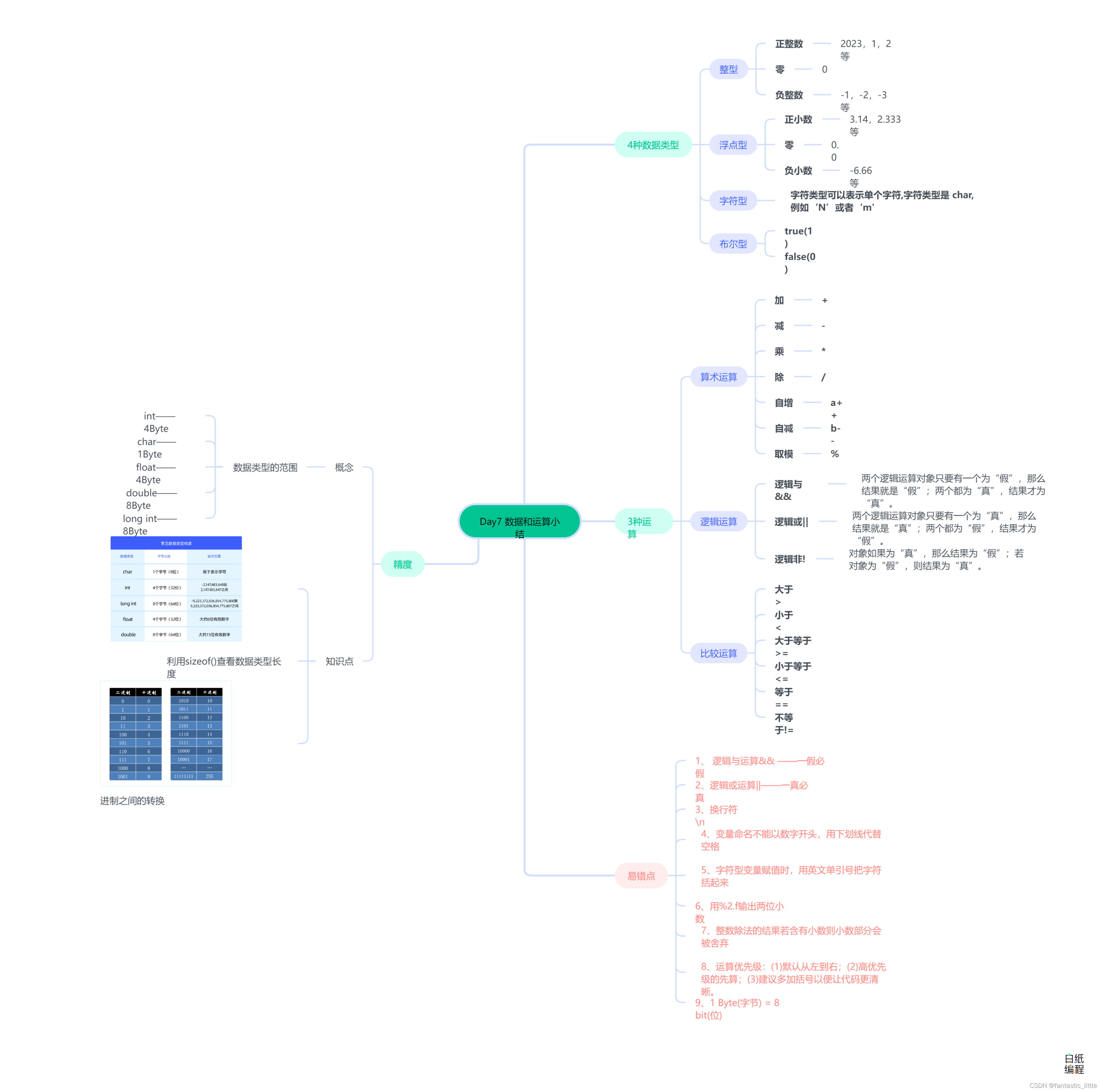
1. 商品购物篮关联规则模型构建
本次商品购物篮关联规则建模的流程如图1所示。
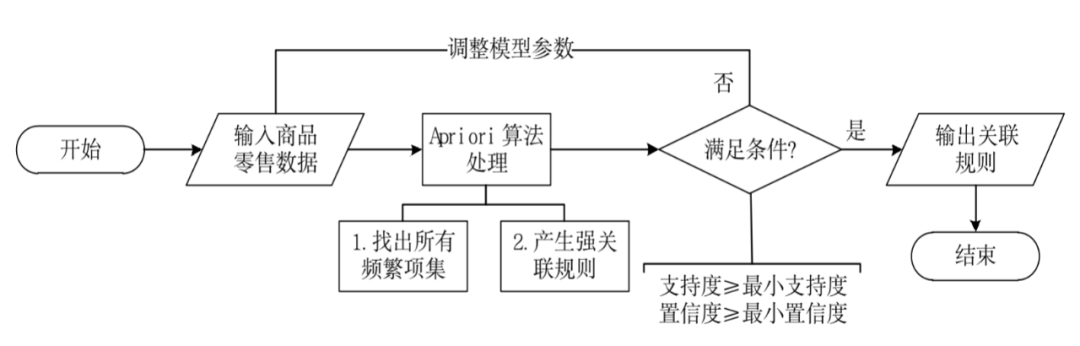
图1 商品购物篮关联规则模型建模流程图
由图1可知,模型主要由输入、算法处理、输出3个部分组成。输入部分包括:建模样本数据的输入;建模参数的输入。算法处理部分是采用Apriori关联规则算法进行处理。输出部分为采用Apriori关联规则算法进行处理后的结果。
模型具体实现步骤为:首先设置建模参数最小支持度、最小置信度,输入建模样本数据;然后采用Apriori关联规则算法对建模的样本数据进行分析,以模型参数设置的最小支持度、最小置信度以及分析目标作为条件,如果所有的规则都不满足条件,则需要重新调整模型参数,否则输出关联规则结果。
目前,如何设置最小支持度与最小置信度,并没有统一的标准。大部分都是根据业务经验设置初始值,然后经过多次调整,获取与业务相符的关联规则结果。本案例经过多次调整并结合实际业务分析,选取模型的输入参数为:最小支持度0.02、最小置信度0.35。其关联规则代码如代码清单2所示。
from numpy import *def loadDataSet():return [['a', 'c', 'e'], ['b', 'd'], ['b', 'c'], ['a', 'b', 'c', 'd'], ['a', 'b'], ['b', 'c'], ['a', 'b'],['a', 'b', 'c', 'e'], ['a', 'b', 'c'], ['a', 'c', 'e']]def createC1(dataSet):C1 = []for transaction in dataSet:for item in transaction:if not [item] in C1:C1.append([item])C1.sort()# 映射为frozenset唯一性的,可使用其构造字典return list(map(frozenset, C1))# 从候选K项集到频繁K项集(支持度计算)def scanD(D, Ck, minSupport):ssCnt = {}for tid in D: # 遍历数据集for can in Ck: # 遍历候选项if can.issubset(tid): # 判断候选项中是否含数据集的各项if not can in ssCnt:ssCnt[can] = 1 # 不含设为1else:ssCnt[can] += 1 # 有则计数加1numItems = float(len(D)) # 数据集大小retList = [] # L1初始化supportData = {} # 记录候选项中各个数据的支持度for key in ssCnt:support = ssCnt[key] / numItems # 计算支持度if support >= minSupport:retList.insert(0, key) # 满足条件加入L1中supportData[key] = supportreturn retList, supportDatadef calSupport(D, Ck, min_support):dict_sup = {}for i in D:for j in Ck:if j.issubset(i):if not j in dict_sup:dict_sup[j] = 1else:dict_sup[j] += 1sumCount = float(len(D))supportData = {}relist = []for i in dict_sup:temp_sup = dict_sup[i] / sumCountif temp_sup >= min_support:relist.append(i)# 此处可设置返回全部的支持度数据(或者频繁项集的支持度数据)supportData[i] = temp_supreturn relist, supportData# 改进剪枝算法def aprioriGen(Lk, k):retList = []lenLk = len(Lk)for i in range(lenLk):for j in range(i + 1, lenLk): # 两两组合遍历L1 = list(Lk[i])[:k - 2]L2 = list(Lk[j])[:k - 2]L1.sort()L2.sort()if L1 == L2: # 前k-1项相等,则可相乘,这样可防止重复项出现# 进行剪枝(a1为k项集中的一个元素,b为它的所有k-1项子集)a = Lk[i] | Lk[j] # a为frozenset()集合a1 = list(a)b = []# 遍历取出每一个元素,转换为set,依次从a1中剔除该元素,并加入到b中for q in range(len(a1)):t = [a1[q]]tt = frozenset(set(a1) - set(t))b.append(tt)t = 0for w in b:# 当b(即所有k-1项子集)都是Lk(频繁的)的子集,则保留,否则删除if w in Lk:t += 1if t == len(b):retList.append(b[0] | b[1])return retListdef apriori(dataSet, minSupport=0.2):# 前3条语句是对计算查找单个元素中的频繁项集C1 = createC1(dataSet)D = list(map(set, dataSet)) # 使用list()转换为列表L1, supportData = calSupport(D, C1, minSupport)L = [L1] # 加列表框,使得1项集为一个单独元素k = 2while (len(L[k - 2]) > 0): # 是否还有候选集Ck = aprioriGen(L[k - 2], k)Lk, supK = scanD(D, Ck, minSupport) # scan DB to get LksupportData.update(supK) # 把supk的键值对添加到supportData里L.append(Lk) # L最后一个值为空集k += 1del L[-1] # 删除最后一个空集return L, supportData # L为频繁项集,为一个列表,1,2,3项集分别为一个元素# 生成集合的所有子集def getSubset(fromList, toList):for i in range(len(fromList)):t = [fromList[i]]tt = frozenset(set(fromList) - set(t))if not tt in toList:toList.append(tt)tt = list(tt)if len(tt) > 1:getSubset(tt, toList)def calcConf(freqSet, H, supportData, ruleList, minConf=0.7):for conseq in H: #遍历H中的所有项集并计算它们的可信度值conf = supportData[freqSet] / supportData[freqSet - conseq] # 可信度计算,结合支持度数据# 提升度lift计算lift = p(a & b) / p(a)*p(b)lift = supportData[freqSet] / (supportData[conseq] * supportData[freqSet - conseq])if conf >= minConf and lift > 1:print(freqSet - conseq, '-->', conseq, '支持度', round(supportData[freqSet], 6), '置信度:', round(conf, 6),'lift值为:', round(lift, 6))ruleList.append((freqSet - conseq, conseq, conf))# 生成规则def gen_rule(L, supportData, minConf0.7):bigRuleList = []for i in range(1, len(L)): # 从二项集开始计算for freqSet in L[i]: # freqSet为所有的k项集# 求该三项集的所有非空子集,1项集,2项集,直到k-1项集,用H1表示,为list类型,里面为frozenset类型,H1 = list(freqSet)all_subset = []getSubset(H1, all_subset) # 生成所有的子集calcConf(freqSet, all_subset, supportData, bigRuleList, minConf)return bigRuleListif __name__ == '__main__':dataSet = data_translationL, supportData = apriori(dataSet, minSupport0.02)rule = gen_rule(L, supportData, minConf0.35)
代码清单2 构建关联规则模型
运行代码清单2得到的结果如下。
frozenset({'水果/蔬菜汁'}) --> frozenset({'全脂牛奶'}) 支持度 0.02664 置信度:0.368495 lift值为:1.44216frozenset({'人造黄油'}) --> frozenset({'全脂牛奶'}) 支持度 0.024199 置信度:0.413194 lift值为:1.617098... ... ... ...frozenset({'根茎类蔬菜', '其他蔬菜'}) --> frozenset({'全脂牛奶'}) 支持度 0.023183 置信度:0.48927 lift值为:1.914833
2.模型分析
根据代码清单2运行结果,我们得出了26个关联规则。根据规则结果,可整理出购物篮关联规则模型结果,如表1所示。
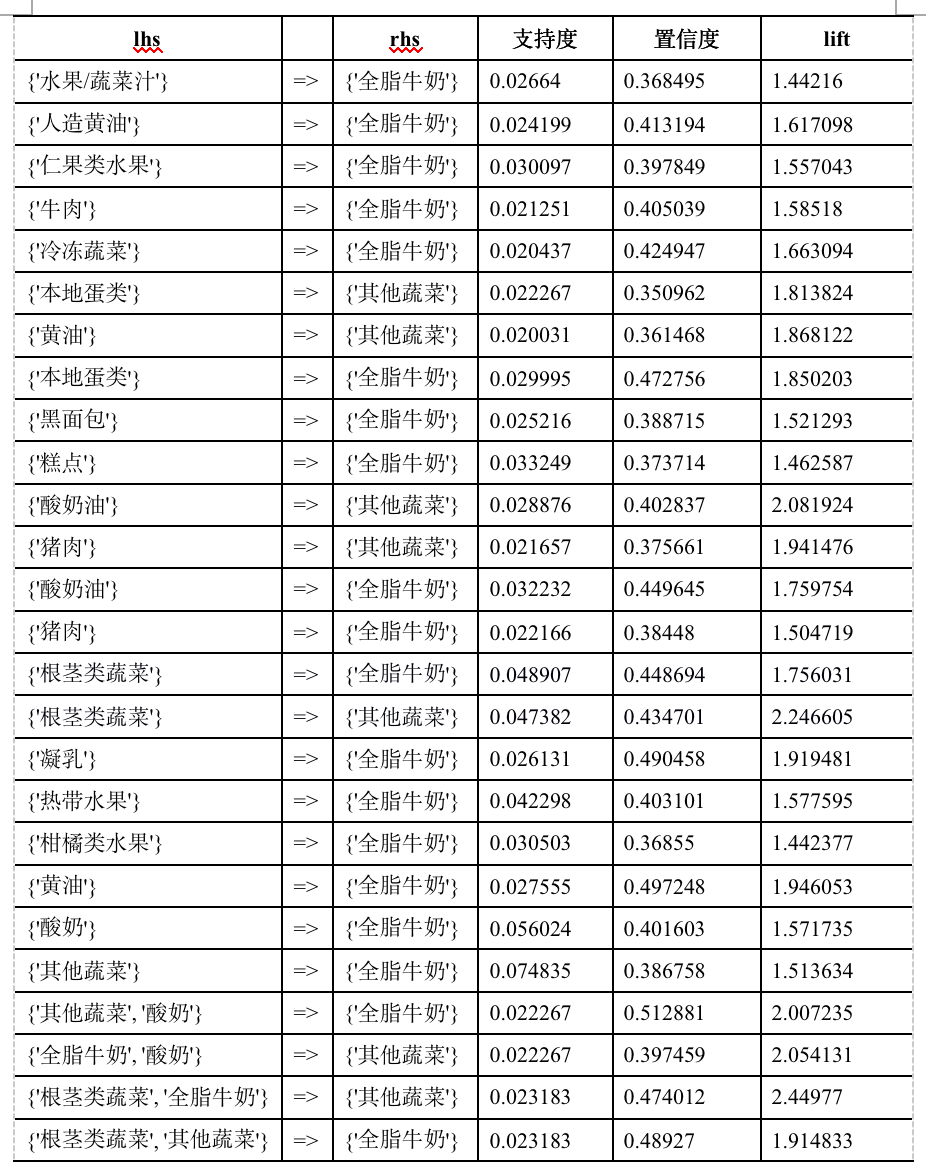
表1 购物篮关联规则模型结果
根据表1中的输出结果,对其中4条进行解释分析如下。
(1) {'其他蔬菜', '酸奶'}=>{'全脂牛奶'}支持度为2.23%,置信度最大为51,29%。说明同时购买酸奶,其他蔬菜和全脂牛奶这3种商品的概率达51,29%,而这种情况发生的可能性为2.23%。
(2) {'其他蔬菜'}=>{'全脂牛奶'}支持度最大为7.48%,置信度为38.68%。说明同时购买其他蔬菜和全脂牛奶这2种商品的概率达38.68%,而这种情况发生的可能性为7.48%。
(3) {'根茎类蔬菜'}=>{'全脂牛奶'}支持度为4.89%,置信度为44.87%。说明同时购买根茎类蔬菜和全脂牛奶这三种商品的概率达44.87%,而这种情况发生的可能性为4.89%。
(4) {'根茎类蔬菜'}=>{'其他蔬菜'}支持度为4.74%,置信度为43.47%。说明同时根茎类蔬菜和其他蔬菜这2种商品的概率达43.47%,而这种情况发生的可能性为4.74%。
综合表1以及输出结果分析,顾客购买酸奶和其他蔬菜的时候会同时购买全脂牛奶,其置信度最大达到51,29%。其他蔬菜、根茎类蔬菜和全脂牛奶同时购买的概率较高。
对于模型结果,从购物者角度进行分析:现代生活中,大多数购物者为家庭煮妇,购买的商品大部分是食品,随着生活质量和健康意识的增加,其他蔬菜、根茎类蔬菜和全脂牛奶均为现代家庭每日饮食所需品,因此,其他蔬菜、根茎类蔬菜和全脂牛奶同时购买的概率较高符合现代人们的生活健康意识。
2.模型应用
模型结果表明顾客购买商品的时候会同时购买全脂牛奶。因此,商场应该根据实际情况将全脂牛奶放在顾客购买商品的必经之路,或者商场显眼位置,方便顾客拿取。其他蔬菜、根茎类蔬菜、酸奶油、猪肉、黄油、本地蛋类和多种水果同时购买的概率较高,可以考虑捆绑销售,或者适当调整商场布置,将这些商品的距离尽量拉近,提升购物体验
了解更多数据分析案例,可持续关注哟~