1 cuda架构

硬件方面
-
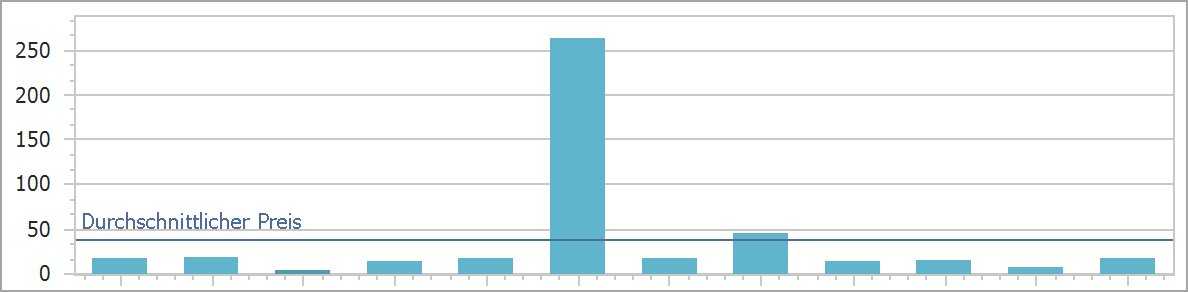
SP (streaming Process) ,SM (streaming multiprocessor) 是硬件(GPUhardware) 概念。而thread,block,grid,warp是软件上的(CUDA) 概念
-
SP:最基本的处理单元,streaming processor,也称为CUDA core,最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
-
SM: 多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register, shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads因此,这些有限的资源就便每个SM中active warps有非常严格的限制,也就限制了并行能力,每个SM包念的SP数量依据GPU架构而不同
软件方面
- Wrap:(线程束)GPU执行程序时的调度单位,一起执行,目前cuda的warp的大小为32,同在一个Warp :的线程,以不同数据资源执行相同的指令。
- grid、block、thread: 在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread.其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和GPU本身的硬件特性。
强推
https://face2ai.com/program-blog/#GPU%E7%BC%96%E7%A8%8B%EF%BC%88CUDA%EF%BC%89
2 利用图形API和CUDA进行GPU通用计算的性能差别
需要将问题转化成图形学,而CUDA使用C语言编写,适合做通用计算
GPU指令和CPU指令 最大区别:CPU需要运行OS,不但要处理中断,还要负责存储器空间分配回收,GPU不需要做这些,所以GPU很空闲
3 GPU架构缺点
-
复杂性: GPU架构通常比CPU复杂,因为它们需要管理大量的并行单元、内存层次结构和调度器。这使得设计、开发和调试GPU架构变得更加复杂。
-
通用计算限制: 初衷是为图形渲染设计的GPU架构在执行通用计算时可能受到一些限制。例如,一些硬件特性和指令集可能不适用于所有类型的计算任务。
-
内存层次结构: GPU具有复杂的内存层次结构,包括全局内存、共享内存和寄存器等。管理和优化数据在这些内存层次之间的传输和访问是挑战之一,可能影响性能。
-
数据传输成本: 在GPU计算中,数据传输成本往往较高,特别是在主机内存和GPU内存之间传输数据。这可能导致在处理大量数据时产生性能瓶颈。
-
程序设计复杂性: 为了充分利用GPU的并行计算能力,需要编写高度并行的代码,涉及线程、块、网格等概念。这可能增加了程序设计的复杂性,容易引入并发错误。
-
并发调度和同步: 在GPU上管理并发执行和同步操作是复杂的任务。正确管理并发执行以避免竞态条件和死锁需要仔细的设计和编程。
如果让我设计GPU架构,我可能会考虑以下方面:
-
通用计算优化: 设计一种架构,既能够优化图形渲染任务,又能够高效执行通用计算任务。这可能涉及设计更多通用计算单元、灵活的指令集等。
-
内存和数据传输优化: 确保内存层次结构能够有效地管理数据传输和访问,最小化数据传输成本。可能需要更智能的缓存管理和数据预取策略。
-
简化编程模型: 设计更简化的编程模型,减少编写并行代码的复杂性。可能通过更高级别的抽象、自动并行化工具等来实现。
-
高效的并发管理: 设计一种可靠且高效的并发管理机制,能够自动处理并发调度、同步和互斥操作,降低并发编程的难度。
-
灵活性: 考虑在架构中引入一定程度的灵活性,以适应不同类型的计算任务。可能通过可配置的硬件模块、指令扩展等方式实现。
-
能效优化: 设计能够在高性能的同时保持良好能效的架构。可能需要在硬件级别上优化功耗管理和调度策略。
需要指出的是,设计一种全面优化且符合所有需求的GPU架构是一个极具挑战性的任务,涉及硬件、软件、算法等多个方面的考虑。实际的GPU架构设计通常需要平衡不同需求,并在性能、能效、成本等方面做出权衡。
GPU的缓存管理和数据预取策略
是为了最大程度地减少内存访问延迟,提高访存效率和整体计算性能。由于GPU具有复杂的内存层次结构(如寄存器、共享内存、全局内存等),在设计缓存管理和数据预取策略时需要考虑不同层次的内存以及数据访问模式。以下是一些常见的缓存管理和数据预取策略:
缓存管理策略:
-
层次化缓存: GPU通常具有多级缓存,如L1缓存、L2缓存等。较小但更快的L1缓存可以存储频繁使用的数据,而较大但稍慢的L2缓存可以存储更多的数据。合理地将数据分布到不同级别的缓存中可以减少内存访问延迟。
-
缓存行(Cache Line): 缓存通常以缓存行为单位进行数据加载,即加载一个缓存行大小的数据。设计合适的缓存行大小可以匹配数据访问模式,减少不必要的数据传输。
-
写缓冲(Write Buffer): 为了提高写入操作的效率,GPU可能会采用写缓冲,将写入操作缓存在缓冲区中,然后一次性写回内存。这可以降低写入操作的延迟。
数据预取策略:
-
空间局部性预取: 当GPU访问一个内存位置时,往往会连续访问相邻的内存位置。预取机制可以提前将相邻数据加载到缓存中,以利用空间局部性。
-
时间局部性预取: 当GPU多次访问同一内存位置时,预取机制可以提前将该数据加载到缓存中,以利用时间局部性。
-
非阻塞预取: 在数据预取时,可以使用非阻塞方式加载数据,以避免阻塞计算单元,提高并发性能。
-
自适应预取: 一些GPU架构具有自适应预取功能,可以根据访存模式动态调整预取策略,以适应不同的应用场景。
-
预取距离: 预取时加载数据的距离也是一个重要因素。加载过远的数据可能会浪费带宽,而加载过近的数据可能会引发访存竞争。因此,预取距离的选择需要考虑数据访问模式。
综合来看,缓存管理和数据预取策略的设计需要结合具体的GPU架构、应用场景和数据访问模式。优化这些策略可以在保持高性能的同时,减少内存访问的延迟,提高计算效率。
4 GPU通过并行执行成千上万个线程来隐藏延迟访问,这是其高性能计算的一个关键机制之一。
这种并行模型允许GPU在等待某些线程的数据访问结果时,可以切换到执行其他线程的计算,从而在某些情况下有效地隐藏内存访问延迟。
这种并行执行的机制可以分为以下几个方面:
-
线程块和网格: GPU任务被划分为多个线程块(Thread Block),每个线程块包含多个线程。线程块是调度的基本单元,多个线程块构成一个网格(Grid)。
-
调度器: GPU调度器将线程块分配给可用的多处理器(SM,Streaming Multiprocessor),并在多个线程块之间切换执行,以最大限度地利用可用的计算资源。
-
线程束: 在SM内部,线程块会被分成小的线程束(Thread Warp)。线程束中的线程可以同时执行相同的指令,从而减少指令调度的开销。
-
延迟隐藏: 当一个线程块等待某些数据的到来时(例如,从内存中加载数据),GPU可以切换到执行其他线程块,从而隐藏内存访问的延迟。
-
多级并行: GPU同时支持多个线程块在不同的SM上执行,每个SM内部又支持多个线程束的并行执行,从而实现多级并行的计算。即:GPU通常采用多级并行结构,如线程块(Thread Block)、线程束(Warps)等。线程块中的线程会被划分为多个线程束,每个线程束内的线程共享相同的指令流,但可以独立执行不同的数据操作。这种多级并行结构使得GPU能够同时执行大量的线程,进一步隐藏内存访问延迟。
这种并行模型在大规模并行计算中非常有效,尤其适用于需要大量数据并行计算的任务,如图像处理、深度学习训练等。通过同时执行多个线程块,GPU能够利用可用的计算资源来充分利用计算能力,即使在存在内存访问延迟的情况下也能保持高效率。
需要注意的是,有效利用并行模型需要开发者合理划分任务、优化数据访问模式,并且确保避免竞态条件和数据不一致性等问题。因此,在编写并行GPU代码时,开发者需要考虑线程同步、数据共享和优化等方面的问题。
5 列举一些常用的线程同步、数据共享和优化的方法
在GPU并行计算中,线程同步、数据共享和优化是非常重要的方面,可以影响程序的正确性和性能。以下是一些常用的方法:
线程同步方法:
-
栅栏同步(Barrier): 在线程块内部使用栅栏同步机制,确保所有线程在某个点上等待,直到所有线程都达到该点。
-
原子操作(Atomic Operations): 使用原子操作来确保在多个线程同时访问共享数据时的数据一致性,如原子加法、原子比较交换等。
-
互斥锁(Mutex): 可以使用互斥锁来保护临界区,防止多个线程同时访问共享资源。但在GPU中,锁可能引入较大的性能开销,因此需要慎重使用。
-
Semaphore(信号量): 信号量是一种同步机制,允许一定数量的线程同时访问共享资源。GPU中使用信号量可以协调线程对有限资源的访问。
以下是关于常见线程同步方法的代码示例,以及它们的优缺点和适用范围。
示例 1: Barrier(栅栏)
__global__ void kernel_with_barrier() {
// 执行一些计算操作
// 等待所有线程完成计算,然后继续执行
__syncthreads();
// 继续后续操作
}
优点:
- 适用于需要在线程块内进行协同操作的场景。
- 提供了明确的同步点,确保所有线程在继续执行之前达到同步。
缺点:
- 栅栏同步可能导致线程的等待时间增加,影响性能。
适用范围:
- 在线程块内需要同步操作的情况下,如某些计算依赖其他线程的结果。
示例 2: Atomic Operations(原子操作)
__global__ void kernel_with_atomic(int* data) {
int threadId = threadIdx.x;
// 原子增加共享变量
atomicAdd(data, threadId);
// 继续后续操作
}
优点:
- 适用于需要对共享变量进行原子操作的情况,以避免竞态条件, 使用原子操作来确保在多个线程同时访问共享数据时的数据一致性,如原子加法、原子比较交换等。
- 确保数据的一致性,无需额外的锁。
缺点:
- 原子操作可能引入性能开销。
适用范围:
- 当多个线程需要更新共享变量时,以避免竞态条件。
示例 3: Mutex(互斥锁)
__global__ void kernel_with_mutex(int* data, mutex_t* lock) {
int threadId = threadIdx.x;
// 加锁
lock_mutex(lock);
// 访问共享资源
(*data) += threadId;
// 解锁
unlock_mutex(lock);
// 继续后续操作
}
优点:
- 适用于需要保护共享资源的情况,确保一次只有一个线程能够访问。
- 提供明确的同步和互斥机制。
缺点:
- 使用互斥锁可能会导致性能下降,因为锁可能引起线程阻塞。
适用范围:
- 在需要保护共享资源、避免并发冲突的情况下。
示例 4: Semaphore(信号量)
__global__ void kernel_with_semaphore(int* data, semaphore_t* sem) {
int threadId = threadIdx.x;
// 等待信号量
wait_semaphore(sem);
// 访问共享资源
(*data) += threadId;
// 释放信号量
release_semaphore(sem);
// 继续后续操作
}
优点:
- 适用于需要限制对有限资源的并发访问数量的情况。
- 可以防止资源的过度使用。
缺点:
- 错误的使用信号量可能导致死锁或资源争夺等问题。
适用范围:
- 当需要限制对某些资源的并发访问数量时,如连接池或线程池等。
请注意,这些示例只是基本演示,实际应用中需要根据具体需求和GPU编程框架进行适当的修改和实现。在选择线程同步方法时,需要权衡其性能、复杂性以及适用范围,并根据具体情况进行调整。
数据共享方法:
- 共享内存: 在线程块内部使用共享内存来共享数据,这种内存可以在线程块内高效地进行读写,有助于减少对全局内存的访问。
__global__ void kernel_with_shared_memory(float* input, float* output) {
extern __shared__ float shared_data[];
int tid = threadIdx.x;
shared_data[tid] = input[tid]; // 将数据从全局内存拷贝到共享内存
__syncthreads(); // 等待所有线程完成数据拷贝
// 在共享内存中进行数据操作
// ...
output[tid] = shared_data[tid]; // 将数据从共享内存拷贝回全局内存
}
- 线程束通信: 在某些GPU架构中,线程束内的线程可以通过特定的指令进行快速通信,可以用于线程级别的数据共享。
优化方法:
- 内存访问模式优化: 优化内存访问模式,尽量保证线程在访问内存时是连续的,以提高缓存命中率。例如,使用合并访问、空间局部性等方法。
__global__ void optimized_memory_access(float* input, float* output) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// 每个线程处理多个数据,减少全局内存访问次数
for (int i = tid; i < N; i += blockDim.x * gridDim.x) {
output[i] = input[i] * 2.0f; // 计算并写回结果
}
}
- 循环展开: 对循环进行展开,将多次迭代的计算放在同一个循环中,以减少循环开销。
__global__ void loop_unrolling(float* input, float* output) {
int tid = threadIdx.x;
int idx = blockIdx.x * blockDim.x + tid;
// 循环展开,每次处理多个数据
for (int i = 0; i < 4; ++i) {
output[idx + i * blockDim.x] = input[idx + i * blockDim.x] * 2.0f;
}
}
- 数据复用: 尽量复用计算中的中间结果,避免重复计算,减少计算开销。
__global__ void data_reuse(float* input, float* output) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float value = input[tid];
float result = value * 2.0f;
// 多次使用同一个中间结果
for (int i = 0; i < 10; ++i) {
result += value;
}
output[tid] = result;
}
# 数据精度优化 避免使用过高的精度
__global__ void data_precision(float* input, double* output) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
double value = static_cast<double>(input[tid]); // 将数据转换为双精度
output[tid] = value * 2.0;
}
-
向量化: 使用SIMD(单指令多数据)指令集,将多个数据元素一起处理,提高计算密集型任务的性能。
-
避免分支: 尽量避免在并行代码中使用分支,因为分支可能导致线程束内的线程执行不同的路径,降低并行性。
-
减少全局内存访问: 尽量减少对全局内存的访问,使用共享内存、常量内存等来存储常用数据。
-
编译器优化: 使用适当的编译器标志和优化选项,以便编译器能够生成更高效的机器码。
-
并行模式选择: 根据问题的特点,选择适合的并行模式,如数据并行、任务并行等。
总的来说,GPU并行计算的优化是一个综合考虑硬件特性、算法、数据布局等多个方面的任务。需要根据具体的问题和硬件架构进行调整和优化,以实现最佳的性能和效率。
6 cuda编程同步方法及其示例代码
在CUDA编程中,有几种常见的同步方法用于协调线程之间的执行顺序和数据一致性。以下是一些常用的CUDA编程同步方法及其示例代码:
1. __syncthreads(): 这是在线程块内同步线程的最常见方法。它确保在调用该函数之前的所有线程都完成了各自的操作,然后才允许线程继续执行。
示例代码:
__global__ void kernel_with_syncthreads(float* data) {
int tid = threadIdx.x;
// 执行一些操作
// 等待所有线程完成操作,然后继续
__syncthreads();
// 继续后续操作
}
2. atomicAdd(): 这是一种原子操作,用于对全局内存中的共享变量执行原子增加操作。它可以避免多个线程同时更新共享变量时的竞态条件。 允许多个线程在无竞争的情况下对共享变量执行原子更新,以避免竞态条件
示例代码:
__global__ void kernel_with_atomic_add(int* data) {
int tid = threadIdx.x;
// 原子增加共享变量
atomicAdd(data, tid);
// 继续后续操作
}
3. 互斥锁(Mutex): 通过CUDA提供的mutex库,可以在线程块内使用互斥锁来实现临界区的保护,确保一次只有一个线程可以进入。
示例代码:
#include <cuda_runtime.h>
#include <device_functions.h>
__global__ void kernel_with_mutex(int* data, int* mutex) {
int tid = threadIdx.x;
// 加锁
while (atomicCAS(mutex, 0, 1) != 0) {
// 等待锁被释放
}
// 访问共享资源
(*data) += tid;
// 解锁
atomicExch(mutex, 0);
// 继续后续操作
}
4. 共享内存(Shared Memory): 共享内存是在线程块内部的线程共享的内存空间,可以用于在线程之间传递数据,以及提高数据访问效率。
示例代码:
__global__ void kernel_with_shared_memory(float* input, float* output) {
extern __shared__ float shared_data[];
int tid = threadIdx.x;
shared_data[tid] = input[tid];
// 等待共享内存中的数据准备完成
__syncthreads();
// 在共享内存中进行数据操作
// ...
output[tid] = shared_data[tid];
}
- Semaphore(信号量):
信号量是一种同步机制,可以用于控制多个线程对有限资源的访问。
示例代码:
__global__ void kernel_with_semaphore(int* data, semaphore_t* sem) {
int tid = threadIdx.x;
// 等待信号量
wait_semaphore(sem);
// 访问共享资源
(*data) += tid;
// 释放信号量
release_semaphore(sem);
}
- Cooperative Groups(协作线程组):
协作线程组是CUDA 9及更高版本引入的概念,允许线程之间在更灵活的方式下进行同步。
示例代码:
#include <cooperative_groups.h>
__global__ void kernel_with_cooperative_groups(float* input, float* output) {
int tid = threadIdx.x;
cooperative_groups::grid_group grid = cooperative_groups::this_grid();
// 执行计算操作
// 等待线程块内所有线程完成计算
grid.sync();
// 继续执行后续操作
}
这些同步方法可以帮助确保线程在执行计算时按预期的顺序进行,同时避免竞态条件和数据不一致性。选择合适的同步方法取决于具体的应用需求和情境。注意,错误的同步使用可能导致死锁、性能下降等问题,因此在实际编程中需要仔细设计和验证。
7 cuda11.4流并行相关
在CUDA编程中,**流(stream)是一种执行序列,可以用来表示在GPU上执行的一系列操作。**CUDA 11.4引入了新的流并行特性,使得在同一设备上可以并发执行多个流,从而进一步提高并行性和性能。以下是关于CUDA 11.4流并行相关的一些信息:
流(Stream):
流是一系列在GPU上执行的操作的序列。每个流内的操作按照添加到流中的顺序执行,但不同流之间的操作可以并行执行。CUDA 11.4引入了流优先级,允许开发者通过显式设置流的优先级来影响操作的调度顺序。
流并行性:
CUDA 11.4引入了新的流并行性特性,允许开发者在同一设备上并发执行多个流。这些流可以在不同的核心、SM(流处理器)上并行执行,从而提高了GPU的利用率和性能。
流并行是CUDA编程中的一个重要概念,它允许多个独立的计算流在GPU上并行执行,从而提高了并行性和性能。流并行可以用于同时执行多个独立的计算任务,从而更好地利用GPU资源。以下是有关流并行的一些进一步信息:
流(Stream):
在CUDA中,流是一系列GPU操作的序列,这些操作可以在设备上异步执行。每个流中的操作按照添加到流中的顺序执行,但不同流之间的操作可以并行执行。流的引入使得不同的计算任务可以同时执行,从而提高了整体的并行性。
流并行性的好处:
- 资源利用率: 通过在同一设备上同时执行多个流,可以更好地利用GPU的计算资源,从而提高系统的资源利用率。
- 任务隔离: 不同的流可以在不同的计算任务之间保持隔离,避免相互干扰。这对于一些需要并行执行的独立任务非常有用。
- 响应性: 通过将一些计算任务放入不同的流中执行,可以使得GPU能够在执行计算的同时响应其他任务,提高系统的响应性。
流的创建和管理:
在CUDA中,可以使用cudaStreamCreate()创建流,使用cudaStreamDestroy()销毁流。可以使用cudaStreamS