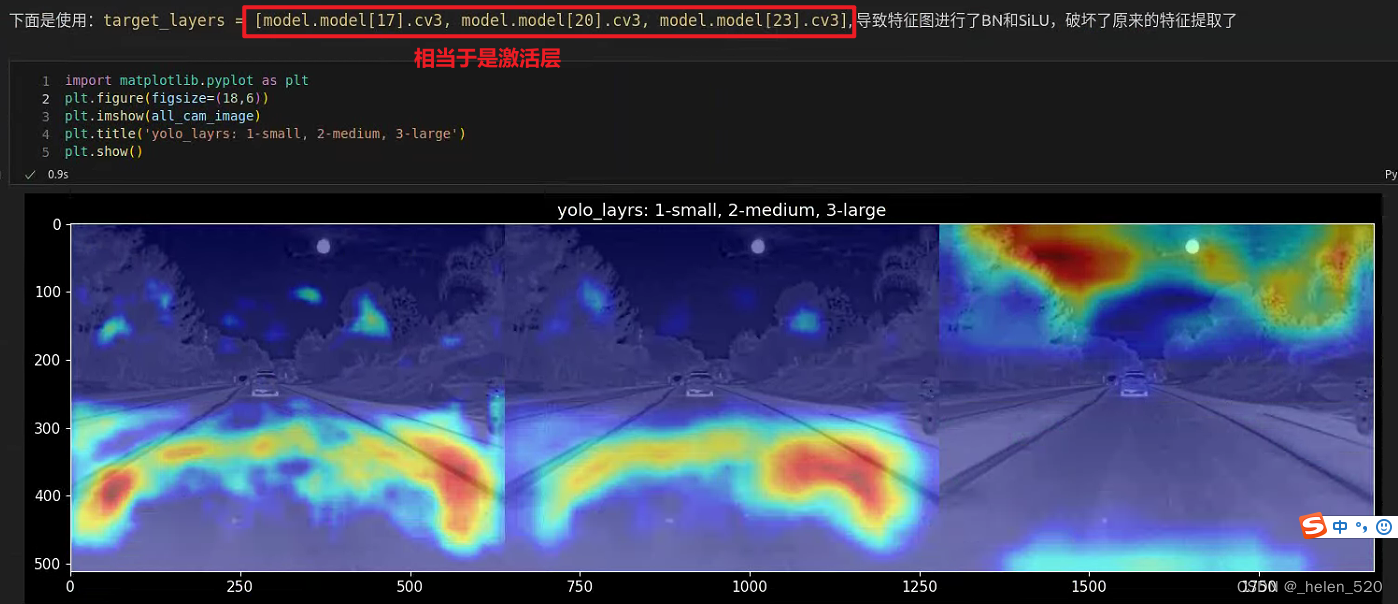
一、前言
前几天,有人让我帮他下载王者荣耀英雄海报,便想着利用Python写个程序,要不然一个个下载太麻烦,也不是咱的作风
二、库安装
pip install beautifulsoup4
pip install lxml
三、编辑代码
import requests, re
from bs4 import BeautifulSoup
url = "https://pvp.qq.com/web201605/herolist.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203"}
html = requests.request("get", url=url, headers=headers).text
soup = BeautifulSoup(html, "lxml")
list = []
for i in soup.find_all(attrs={"class": "herolist clearfix"}):
for o in i.find_all("a"):
list.append(f"https://pvp.qq.com/web201605/" + o.get("href"))
count = 1
for ix in list:
htm = requests.get(url=ix, headers=headers)
htm.encoding = "GBK"
soup1 = BeautifulSoup(htm.text, "lxml")
for z in soup1.find_all(attrs={"class": "zk-con1"}):
name = soup1.find(attrs={"class": "cover-name"}).get_text()
# print(z)
ZG = z.get("style")
img_urls = re.search("//.*?.jpg", str(ZG))
imgs = f"http:" + img_urls.group()
pic = requests.get(imgs).content
with open(f"{name}.jpg", "wb") as f:
f.write(pic)
print(f"正在下载 === {name} == 英雄图片,这是第{count}张图片")
count += 1
print("图片下载完毕!")四、效果