计算机视觉是人工智能领域的一个重要分支,它旨在构建能够理解和处理图像、视频等视觉信息的计算机系统。在计算机视觉领域中,图像分类、图像识别和目标检测是三个重要的任务,当然目标跟踪、图像生成也是新的方向和延伸。
其实下面这幅图已经非常准确地说明图像分类、图像识别和目标检测的区别和共同点。

一、图像分类
图像分类的目的是将一张图像分到某个预定义的类别中。一般意义上的图像分类是指单标签分类,和上述图不太一样。
图像分类是一个监督学习的过程,它通常由两个阶段组成:训练和测试。在训练阶段,算法会使用标注好类别的图像作为输入,通过学习图像的特征和类别标签之间的关系,生成一个分类器。在测试阶段,算法会使用训练好的分类器对新的图像进行分类。
在深度学习算法中,卷积神经网络(CNN)是目前最为流行的算法之一。CNN通过卷积层和池化层来提取图像的特征,通过全连接层来进行分类。图像分类经典神经网络的发展历史:Lenet --> Alexnet --> ZFnet --> VGG --> NIN --> GoogLeNet -->ResNet--> DenseNet -->ResNeXt ---> EfficientNet
二、目标检测
目标检测是在图像中检测和识别出多个物体,并给出它们的位置信息。与图像识别不同的是,目标检测需要对物体进行定位,即给出物体在图像中的位置和大小。
目标检测通常包括两个任务,即目标定位和目标分类。目标定位是指在图像中准确地定位目标的位置和大小,而目标分类则是对定位出的目标进行分类。
常见的目标检测算法包括基于区域的方法、单阶段检测方法、双阶段检测方法等。基于区域的方法通常采用候选框提取和分类的方法,如RCNN、Fast RCNN、Faster RCNN等。单阶段检测方法是指直接从图像中预测物体的位置和类别,如RetinaNet、SSD、YOLO系列(YOLOV1、YOLOV2、YOLOV3、YOLOV4、YOLOV5、YOLOV6、YOLOV7、YOLOV8)等。双阶段检测方法则是将目标检测任务分为两个阶段,如R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN、SPP-Net等。
三、图像识别
图像识别是将一张图像中的物体进行识别,即对图像中出现的每个物体进行标记和分类。与图像分类不同的是,图像识别任务需要对每个物体进行区分和分类,而不是将整个图像分类。图像识别通常是指多标签分类,即每张图片可能属于多个类别。图像识别包括语义分割、实例分割、物体检测等类型,常见的语义分割如FCN模型、U-Net模型、3D U-Net
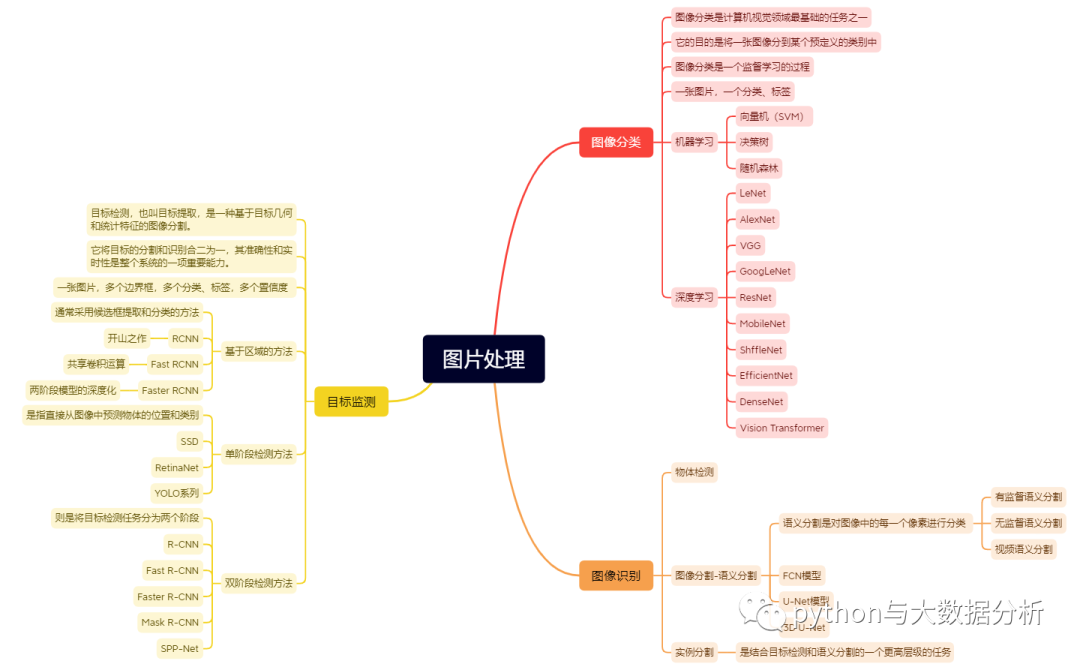
后续从哪里入手呢?还是先从目标检测来吧,我只是一个看不懂数学公式的人工智能爱好者,对着B站学了很久还是不得其法,既然如此那就不求甚解下去吧
最后欢迎关注公众号:python与大数据分析