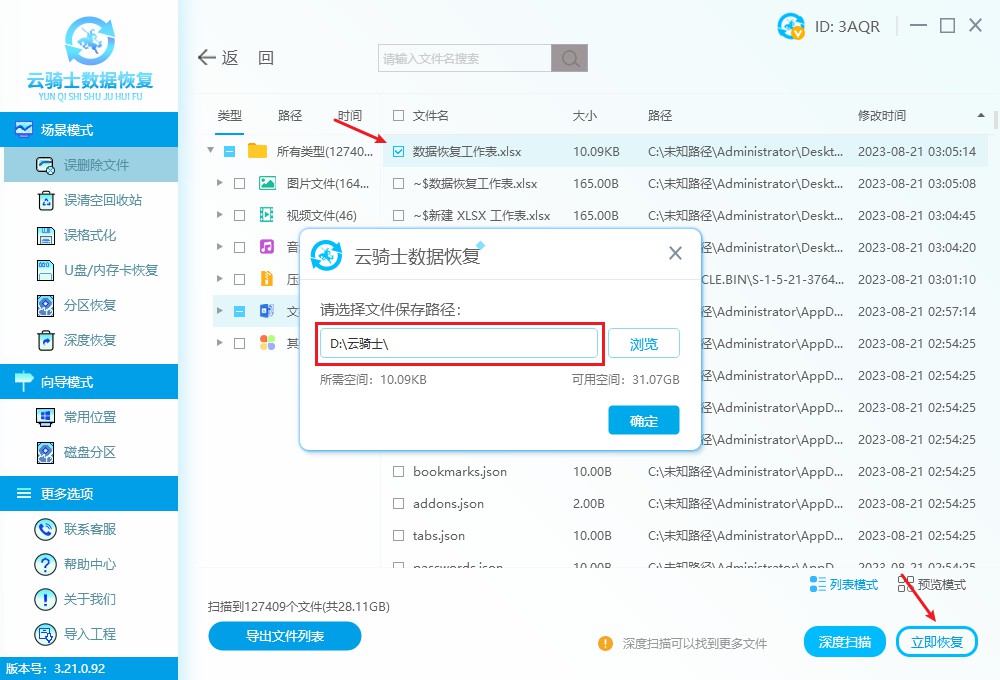
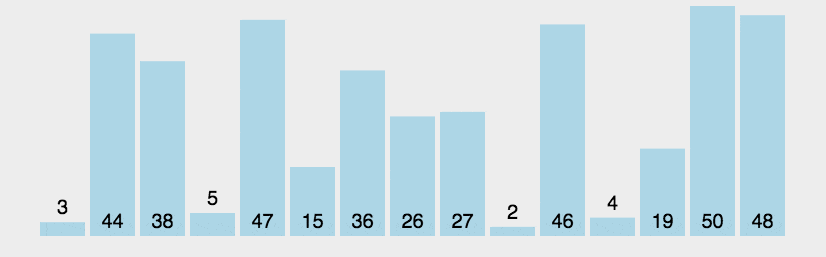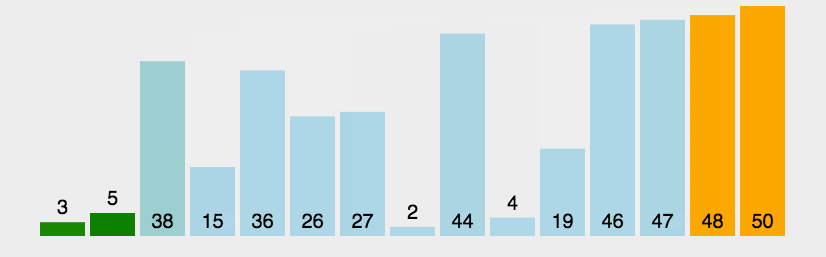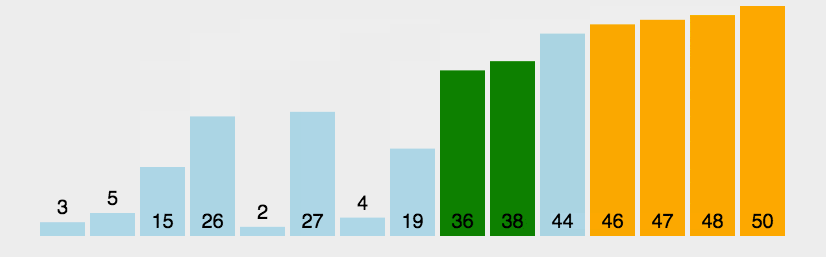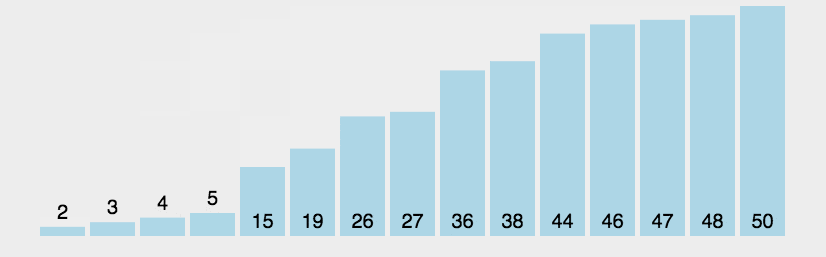CAM方法
- 拉yolov5源码
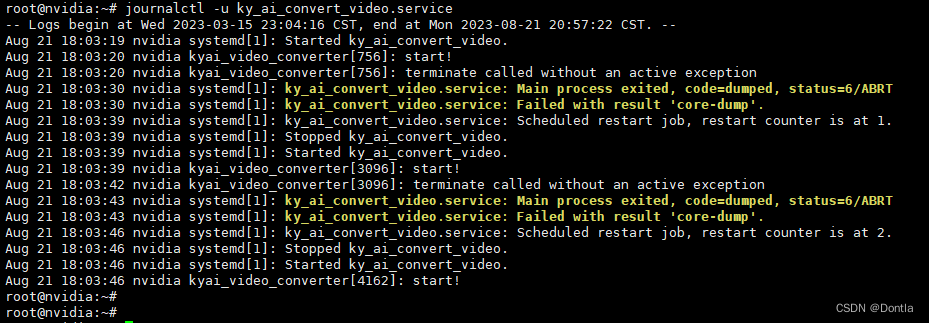
在V5的模型中:第17-C3,20-C3,23-C3是三个yolo层的输出,需要明确一下哪一层的输出捕获到了目标?
- C3的前向传播:C3的 conv3是C3模块的最后输出;通过看C3和bottleNeck的forward代码可以看出;self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
C3(
(cv1): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
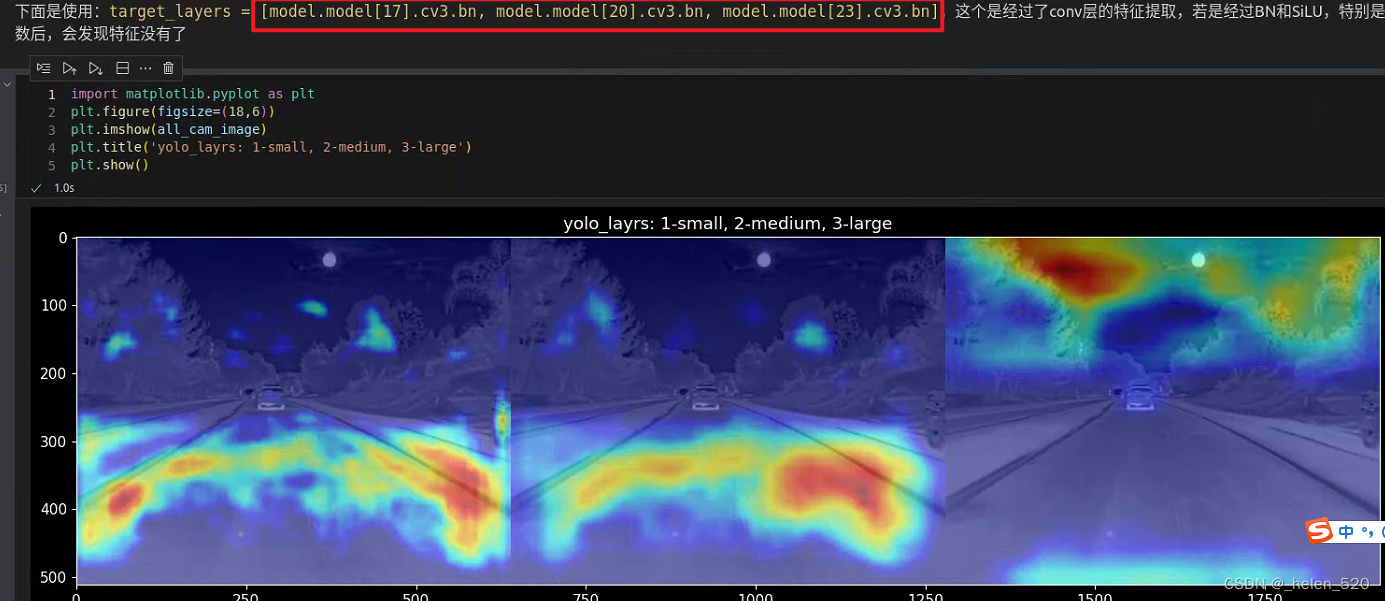
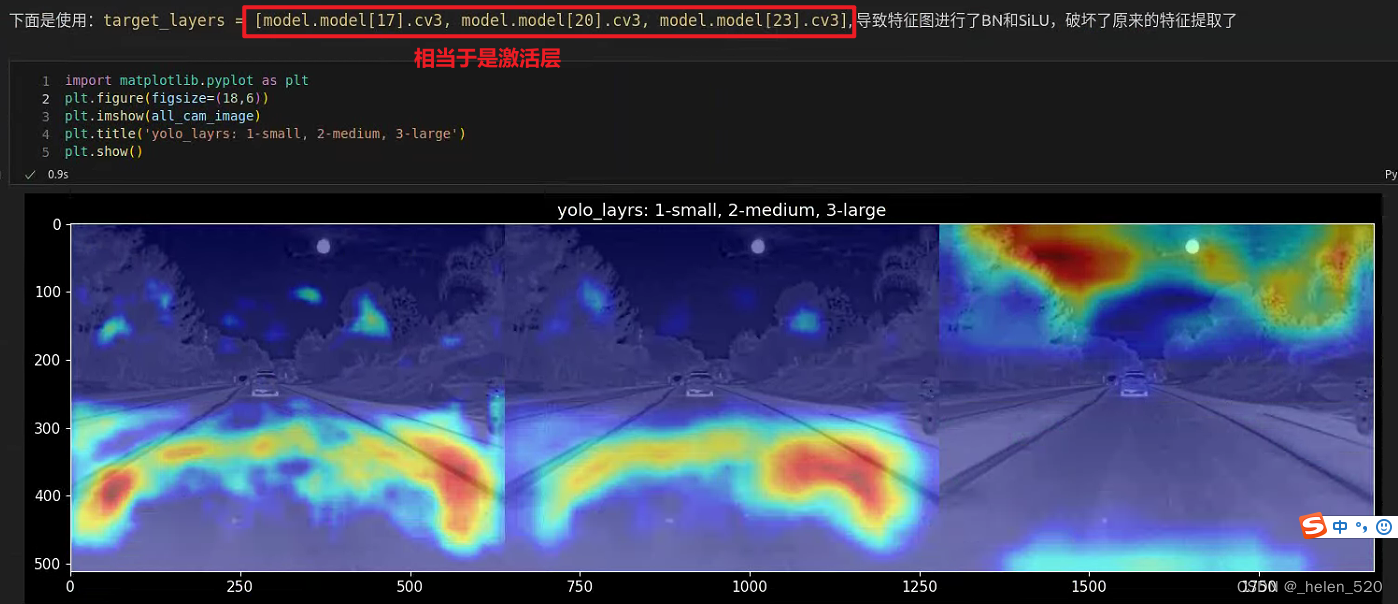
)C3的cv3有:conv, bn, act三部分,选择这三个分别来看特征图的激活情况,如下:
- 大目标层:20x20的层,车有高激活
- 但经过BN后,这个激活减弱了
- 经过act激活层,这个激活就更弱了!
import sys
sys.path.insert(0, '/home/helen/code/deep-learning-for-image-processing/pytorch-grad-cam')
from pytorch_grad_cam import EigenCAM
import warnings
# warnings.filterwarnings('ignore')
# warnings.simplefilter('ignore')
import torch
import cv2
import numpy as np
import requests
import torchvision.transforms as transforms
from pytorch_grad_cam import EigenCAM
from pytorch_grad_cam.utils.image import show_cam_on_image, scale_cam_image
from PIL import Image
COLORS = np.random.uniform(0, 255, size=(80, 3))
img_path = '/home/helen/dataset/FLIR/FLIR_ADAS/val/images/FLIR_00106.jpeg'
# img = np.array(Image.open(img_path))
img = cv2.imread(img_path)
# padded_image = cv2.resize(img, (640,640))
# padded_image = np.pad(img, ((0, 128),(0,0), (0,0)), mode='constant')#, constant_values=img.mean())
# padded_image = np.pad(img, ((0, 128),(0,0), (0,0)), mode='constant', constant_values=img.mean())
padded_image = img
img = np.float32(padded_image) / 255
transform = transforms.ToTensor()
tensor = transform(img).unsqueeze(0)
import yaml
from models.yolo import Model
device = 'cuda:0'
cfg = '/home/helen/code/yolov5/models/yolov5s.yaml'
nc = 2
hypfile = '/home/helen/code/yolov5/data/hyps/hyp.scratch-low.yaml'
with open(hypfile, errors='ignore') as f:
hyp = yaml.safe_load(f)
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
weights = '/home/helen/code/yolov5/best.pt'
ckpt = torch.load(weights, map_location='cpu')
model.load_state_dict(ckpt['model'].float().state_dict(), strict=False)
model.eval()
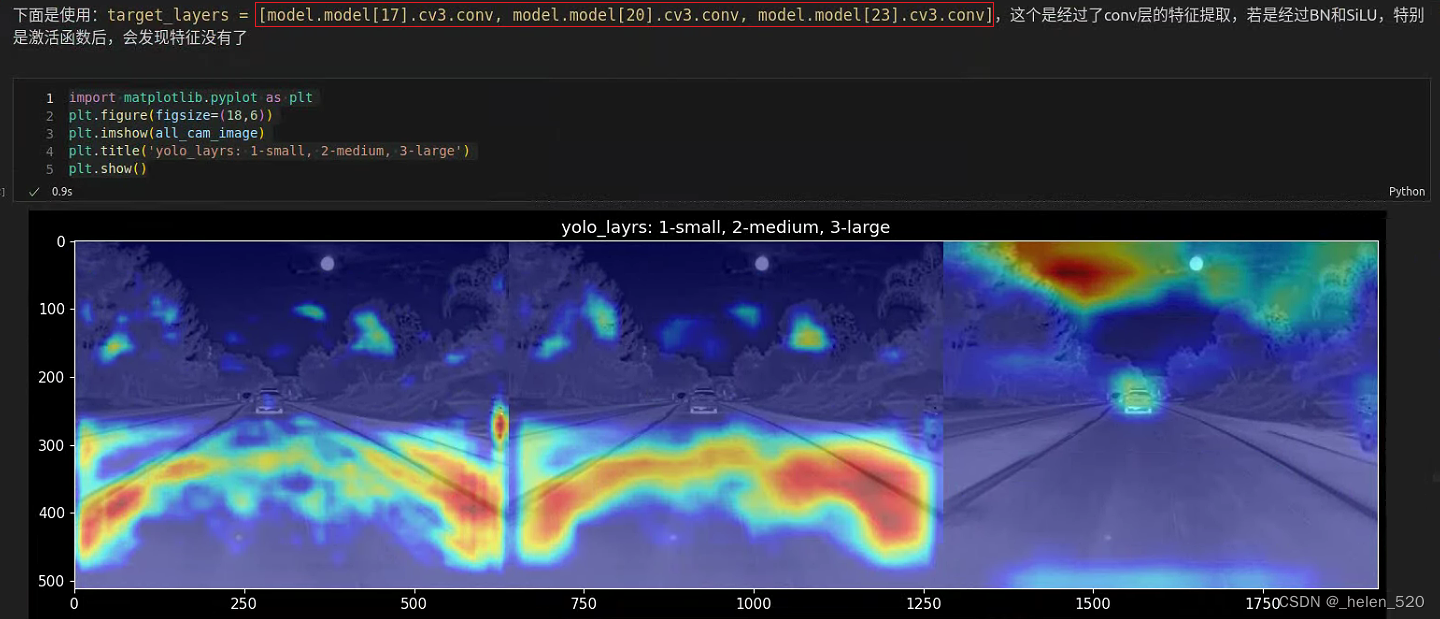
target_layers = [model.model[17].cv3, model.model[20].cv3, model.model[23].cv3]
tensor = tensor.to('cuda:0')
all_cam_image = None
all_gray_cam = None
for l in target_layers:
cam = EigenCAM(model, target_layers=[l], use_cuda=True)
grayscale_cam = cam(tensor.to('cuda:0'), targets=[0])[0, :, :]
cam_image = show_cam_on_image(img, grayscale_cam, use_rgb=True)
if all_cam_image is None:
all_cam_image = cam_image
all_gray_cam = grayscale_cam
else:
all_cam_image = np.hstack((all_cam_image,cam_image))
all_gray_cam = np.hstack((all_gray_cam, grayscale_cam))
plt.imshow(all_cam_image)
plt.title('yolo_layrs: 1大目标, 2中目标, 3小目标')
plt.show()