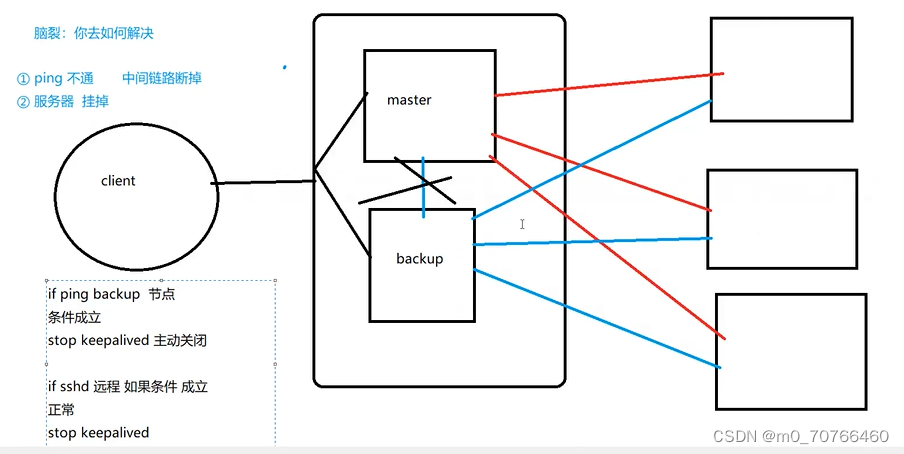
业界实现方案
1. 基于UUID
2. 基于DB数据库多种模式(自增主键、segment)
3. 基于Redis
4. 基于ZK、ETCD
5. 基于SnowFlake
6. 美团Leaf(DB-Segment、zk+SnowFlake)
7. 百度uid-generator()
1.基于UUID生成唯一ID
UUID:
UUID长度128bit,32个16进制字符,占用存储空间多,且生成的ID是无序的;
对于InnoDB这种聚集主键类型的引擎来说,数据会按照主键进行排序,由于UUID的无序性,InnoDB会产生巨大的IO压力,此时不适合使用UUID做物理主键,可以把它作为逻辑主键,物理主键依然使用自增ID。
组成部分:
为了保证UUID的唯一性,规范定义了包括网卡MAC地址,时间戳,名字空间,随机或伪随机数,时序等元素.
优点:
性能非常高:本地生成,没有网络消耗。
缺点:
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
UUID生成策略
UUID Version 1:基于时间的UUID
基于时间的UUID通过计算当前时间戳、随机数和机器MAC地址得到。由于在算法中使用了MAC地址,这个版本的UUID可以保证在全球范围的唯一性。但与此同时,使用MAC地址会带来安全性问题,这就是这个版本UUID受到批评的地方。如果应用只是在局域网中使用,也可以使用退化的算法,以IP地址来代替MAC地址--Java的UUID往往是这样实现的(当然也考虑了获取MAC的难度)
UUID Version 2:DCE安全的UUID
DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
UUID Version 3:基于名字的UUID(MD5)
基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
UUID Version 4:随机UUID
根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但随机的东西就像是买彩票:你指望它发财是不可能的,但狗屎运通常会在不经意中到来。
UUID Version 5:基于名字的UUID(SHA1)
和版本3的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法
UUID应用
UUID Version 1:基于时间的UUID
从UUID的不同版本可以看出
• Version 1/2适合应用于分布式计算环境下,具有高度的唯一性•• Version 3/5适合于一定范围内名字唯一,且需要或可能会重复生成UUID的环境下•• 至于Version 4,建议是最好不用(虽然它是最简单最方便的)•• 通常我们建议使用UUID来标识对象或持久化数据,但以下情况最好不使用UUID:• 映射类型的对象。比如只有代码及名称的代码表。• 人工维护的非系统生成对象。比如系统中的部分基础数据。• 对于具有名称不可重复的自然特性的对象,最好使用Version 3/5的UUID。比如系统中的用户。如果用户的UUID是Version 1的,如果你不小心删除了再重建用户,你会发现人还是那个人,用户已经不是那个用户了。(虽然标记为删除状态也是一种解决方案,但会带来实现上的复杂性。

2.基于DB数据库多种模式(自增主键、segment)
基于DB的自增主键方案
实现原理:
基于MySQL,最简单的方法是使用auto_increment 来生成全局唯一递增ID,但最致命的问题是在高并发情况下,数据库压力大,DB单点存在宕机风险
优点:
实现简单、基于数据库底层机制
缺点:
高并发情况下,数据库压力大,DB单点存在宕机风险
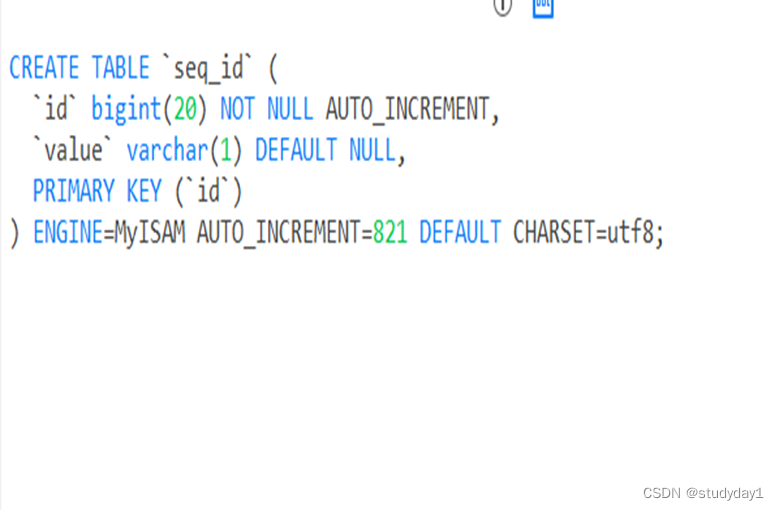
基于DB多主模式方案
在分布式系统中我们可以多部署几台机器,
每台机器设置不同的初始值,且步长和机器数相等。
比如有两台机器。设置步长step为2,
TicketServer1的初始值为1(1,3,5,7,9,11…)、
TicketServer2的初始值为2(2,4,6,8,10…)。
这是Flickr团队在2010年撰文介绍的一种主键生成策略
(Ticket Servers: Distributed Unique Primary Keys on the Cheap )
如下所示,为了实现上述方案分别设置两台机器对应的参数,
TicketServer1从1开始发号,
TicketServer2从2开始发号,
两台机器每次发号之后都递增2
基于DB号段实现方案
实现原理:
每次向db申请一个号段,加载到内存中,然后采用自增的方式来生成id,这个号段用完后,再次向db申请一个新的号段,这样对db的压力就减轻了很多,同时内存中直接生成id。向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
优点:
利用了缓存,减轻DB压力,性能提升
缺点:
依然存在DB模式下的性能瓶颈,ID最大值的限制
3.基于Redis实现分布式ID
- 因为Redis是单线程的,所以天然没有资源争用问题,可以采用 incr 指令,实现ID的原子性自增。
- 但是因为Redis的数据备份-RDB,会存在漏掉数据的可能,所以理论上存在已使用的ID再次被使用,所以备份方式可以加上AOF方式,这样的话性能会有所损耗。
4.基于Zookeeper实现分布式ID
原理:
利用zookeeper中的顺序节点的特性,制作分布式的序列号生成器(ID生成器)
5.基于ETCD实现分布式ID
原理:
每个tx事务有唯一事务ID,在etcd中叫做main ID,全局递增不重复。一个tx可以包含多个修改操作(put和delete),每一个操作叫做一个revision(修订),共享同一个main ID。
一个tx内连续的多个修改操作会被从0递增编号,这个编号叫做sub ID。
每个revision由(main ID,sub ID)唯一标识。
6.美团Leaf-基于ZK的SnowFlake算法
Leaf-snowflake方案完全沿用snowflake方案的bit位设计.
即是“1+41+10+12”的方式组装ID号。
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。
Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性
自动对snowflake节点配置wokerID

7.百度uid-generator分布式ID生成器
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。
UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略,
从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制;
采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,
避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
其实现原理和雪花算法并无二致,自定义号段,并且采用RingBuffer作为缓冲从而提升性能。详见官网地址:
https://github.com/baidu/uidgenerator/blob/master/README.zh_cn.md