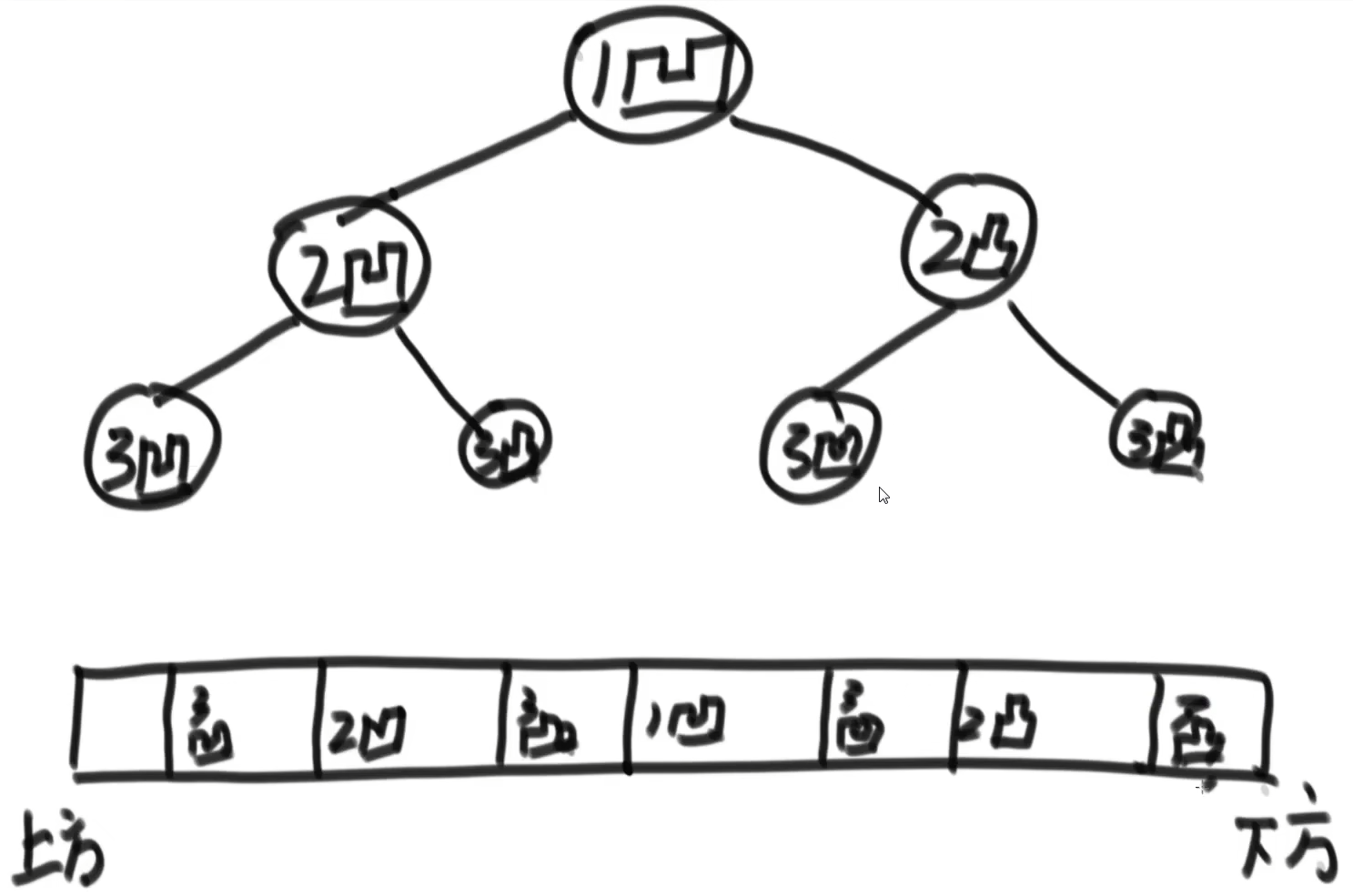
任务轮转工作由任务调度器来完成的,任务调度器就是操作系统中用于把任务轮流调度上处理器运行的一个软件模块,它是操作系统的一部分。调度器在内核中维护一个任务表(也称进程表、线程表或调度表),然后按照一定的算法,从任务表中选择一个任务,然后把该任务放到处理器上运行,当任务运行的时间片到期后,再从任务表中找另外一个任务放到处理器上运行,周而复始,让任务表中的所有任务都有机会运行 。 正是因为有了调度器,多任务操作系统才能得以实现,它是多任务系统的核心,它的好坏直接影响了系统的效率 。
处理器只知道加电后按照程序计数器中的地址不断地执行下去,在不断执行的过程中,我们把程序计数器中的下一条指令地址所组成的执行轨迹称为程序的控制执行流,让我们再深入描述一下。执行流就是一段逻辑上独立的指令区域,是人为给处理器安排的处理单元。指令是具备“能动性”的数据,因此只有指令才有“执行”的能力,它相当于是动作的发出者,由它指导处理器产生相应的行为。指令是由处理器来执行的,它引领处理器“前进”的方向,用“流”来表示处理器中程序计数器的航向,借此比喻处理器依次把此区域中的指令执行完后,所形成的像河流一样曲直不一的执行轨迹、执行路径(由顺序执行指令及跳转指令导致)。
执行流对应于代码,大到可以是整个程序文件,即进程,小到可以是一个功能独立的代码块,即函数,而线程本质上就是函数。
执行流是独立的,它的独立性体现在每个执行流都有自己的栈、一套自己的寄存器映像和内存资源,这是 Intel 处理器在硬件上规定的,其实这正是执行流的上下文环境。因此,我们要想构造一个执行流,就要为其提供这一整套的资源。不知道我说清楚了没有,我的意思是其实任何代码块,无论大小都可以独立成为执行流,只要在它运行的时候,我们提前准备好它所依赖的上下文环境就行,这个上下文环境就是它所使用的寄存器映像、栈、内存等资源。
在任务调度器的眼里,只有执行流才是调度单元,即处理器上运行的每个任务都是调度器给分配的执行流,只要成为执行流就能够独立上处理器运行了,也就是说处理器会专门运行执行流中的指令。
我们软件中所做的任务切换,本质上就是改变了处理器中程序计数器的指向,即改变了处理器的“执行流”。
任务只是人为划分的、逻辑上的概念,人们把一个个的执行单元称为任务,我们所说的执行单元就
是这些彼此独立的执行流,因此,独立的执行流成了调度器的调度单元,并使之成为了处理器的基本执行单位。

处理器不是把线程中调用的函数和其他指令混在一块执行的,或者说不是在执行整个进程时顺便执行了该函数,而是单独、专门执行了此函数。
在线程中调用函数是让所运行的函数能够以调度单元的身份独立上处理器运行,当函数可以独
立运行时,就会有更大的好处,那就是可以让程序中的多个函数(执行流)以并行的方式运行(当然是伪并行),为程序提速。
线程是在进程之后才提出的概念,在没有线程之前,进程就是理所当然的执行流,或者说进程只是一个大的执行流(也许执行流没有大小之分,但有数量之别)。在有了线程的概念后(仅仅是在名词概念之后,其实线程这玩意一直存在,后面会提到),执行流便专指粒度更细的线程,因此线程是最小的执行单元。处理器执行任何程序,其过程都是一步步跟随程序中下一步要执行的指令,所以说程序都有执行流,若未显式创建线程,则当前进程中的指令自然也是执行流,也就是只存在一个线程喽。因此纯粹的进程实际上就相当于单一线程的进程,也就是前面所说的单线程进程。进程中若显式创建了多个线程时,就会有多个执行流,也就是多线程进程。
为什么要有线程这一称呼?为了给程序提速,确切地说是给进程提速,因为线程必然属于某一进程,线程要运行必须要有相应的资源,而进程就是这个资源的提供者,因此线程存在于进程之中利用线程提速,原理就是实现多个执行流的伪并行 。 任务其实就是执行流,要么是大的执行流——单线程的进程,要么是小的执行流一一线程。
进程采用多个执行流和其他进程抢处理器资源,这样就节省了单个进程的总执行时间。提速的原理很简单,就是想办法让处理器多执行自己进程中的代码,这样进程执行完成得就快 。看似其他任务都是在和自己竞争处理器资源,这影响了任何任务的执行速度 。 但如果其他任务或者大部分任务都是帮任务 A 做事,任务 A 不就很快执行完成了吗?这就是线程提速的原理之一 。
线程另一个提速的原理是避免了阻塞整个进程,当然这指的是内核级线程的实现
只有线程才具备能动性,它才是处理器的执行单元,因此它是调度器眼中的调度单位。进程只是个资源整合体,它将进程中所有线程运行时用到资源收集在一起,供进程中的所有线程使用,真正上
处理器上运行的其实都叫线程,进程中的线程才是一个个的执行实体、执行流,因此,经调度器送上处理器执行的程序都是线程。

在用户进程中实现线程有以下优点。
- 线程的调度算法是由用户程序自己实现的,可以根据实现应用情况为某些线程加权调度。
- 将线程的寄存器映像装载到 CPU 时,可以在用户空间完成,即不用陷入到内核态,这样就免去了进入内核时的入栈及出栈操作。
当然,任何事物都有两方面,用户级线程也会有以下缺点。
- 进程中的某个线程若出现了阻塞(通常是由于系统调用造成的),操作系统不知道进程中存在线程,它以为此进程是传统型进程(单线程进程),因此会将整个进程挂起,即进程中的全部线程都无法运行,得,这下因小失大了。
- 线程未在内核空间中实现,因此对于操作系统来说,调度器的调度单元是整个进程,并不是进程
中的线程,所以时钟中断只能影响进程一级的执行流。 - 最后,线程在用户空间实现,和在内核空间实现相比,只是在内部调度时少了陷入内核的代价,
确实相当于提速,但由于整个进程占据处理器的时间片是有限的,这有限的时间片还要再分给内部的线程,所以每个线程执行的时间片非常非常短暂,再加上进程内线程调度器维护线程表、运行调度算法的时间片消耗,反而抵销了内部调度带来的提速。
在内核空间实现线程的优点:
- 相比在用户空间中实现线程,内核提供的线程相当于让进程多占了处理器资源,比如系统中运行有进程 A 和一传统型进程 B,此时进程 A 中显式创建了 3 个线程,这样一来,进程 A 加上主线程便有了 4 个线程,加上进程 B,内核调度器眼中便有了 5 个独立的执行流,尽管其中 4 个都属于进程 A,但对调度器来说这 4个线程和进程一样被调度,因此调度器调度完一圈后,进程 A 使用了 80% 的处理器资源,这才是真正的提速。
- 当进程中的某一线程阻塞后 , 由于线程是由内核空间实现的,操作系统认识线程,所以就只会阻塞这一个线程,此线程所在进程内的其他线程将不受影响,这又相当于提速了 。
缺点是用户进程需要通过系统调用陷入内核,这多少增加了 一些现场保护的枝操作,这还是会消耗一些处理器时间,但和上面的大幅度提速相比,这不算什么大事。
ABI 是 Application Binary Interface,即应用程序二进制接口,也许部分同学只听说过 API, API 是 Application Programming lnterface,即应用程序可编程接口,不过这是库函数和操作系统的系统调用之间的接口 。 ABI 与此不同, ABI 规定的是更加底层的一套规则,属于编译方面的约定,比如参数如何传递,返回值如何存储,系统调用的实现方式,目标文件格式或数据类型等。只要操作系统和应用程序都遵守同一套 ABI 规则,编译好的应用程序可以无需修改直接在另一套操作系统上运行 。
当我们用汇编语言写了个函数,而且是用 C 程序来调用这个汇编函数时,就需要考虑ABI。
/* 自定义通用函数类型,它将在很多线程函数中做为形参类型 */
typedef void thread_func(void*);
/* 进程或线程的状态 */
enum task_status {
TASK_RUNNING,
TASK_READY,
TASK_BLOCKED,
TASK_WAITING,
TASK_HANGING,
TASK_DIED
};
/*********** 中断栈intr_stack ***********
* 此结构用于中断发生时保护程序(线程或进程)的上下文环境:
* 进程或线程被外部中断或软中断打断时,会按照此结构压入上下文
* 寄存器, intr_exit中的出栈操作是此结构的逆操作
* 此栈在线程自己的内核栈中位置固定,所在页的最顶端
********************************************/
struct intr_stack {
uint32_t vec_no; // kernel.S 宏VECTOR中push %1压入的中断号
uint32_t edi;
uint32_t esi;
uint32_t ebp;
uint32_t esp_dummy; // 虽然pushad把esp也压入,但esp是不断变化的,所以会被popad忽略
uint32_t ebx;
uint32_t edx;
uint32_t ecx;
uint32_t eax;
uint32_t gs;
uint32_t fs;
uint32_t es;
uint32_t ds;
/* 以下由cpu从低特权级进入高特权级时压入 */
uint32_t err_code; // err_code会被压入在eip之后
void (*eip) (void);
uint32_t cs;
uint32_t eflags;
void* esp;
uint32_t ss;
};
/*********** 线程栈thread_stack ***********
* 线程自己的栈,用于存储线程中待执行的函数
* 此结构在线程自己的内核栈中位置不固定,
* 用在switch_to时保存线程环境。
* 实际位置取决于实际运行情况。
******************************************/
struct thread_stack {
uint32_t ebp;
uint32_t ebx;
uint32_t edi;
uint32_t esi;
/* 线程第一次执行时,eip指向待调用的函数kernel_thread
其它时候,eip是指向switch_to的返回地址*/
void (*eip) (thread_func* func, void* func_arg);
/***** 以下仅供第一次被调度上cpu时使用 ****/
/* 参数unused_ret只为占位置充数为返回地址 */
void (*unused_retaddr);
thread_func* function; // 由Kernel_thread所调用的函数名
void* func_arg; // 由Kernel_thread所调用的函数所需的参数
};
/* 进程或线程的pcb,程序控制块 */
struct task_struct {
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
enum task_status status;
uint8_t priority; // 线程优先级
char name[16];
uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
};
#define PG_SIZE 4096
/* 由kernel_thread去执行function(func_arg) */
static void kernel_thread(thread_func* function, void* func_arg) {
function(func_arg);
}
/* 初始化线程栈thread_stack,将待执行的函数和参数放到thread_stack中相应的位置 */
void thread_create(struct task_struct* pthread, thread_func function, void* func_arg) {
/* 先预留中断使用栈的空间,可见thread.h中定义的结构 */
pthread->self_kstack -= sizeof(struct intr_stack);
/* 再留出线程栈空间,可见thread.h中定义 */
pthread->self_kstack -= sizeof(struct thread_stack);
struct thread_stack* kthread_stack = (struct thread_stack*)pthread->self_kstack;
kthread_stack->eip = kernel_thread;
kthread_stack->function = function;
kthread_stack->func_arg = func_arg;
kthread_stack->ebp = kthread_stack->ebx = kthread_stack->esi = kthread_stack->edi = 0;
}
/* 初始化线程基本信息 */
void init_thread(struct task_struct* pthread, char* name, int prio) {
memset(pthread, 0, sizeof(*pthread));
strcpy(pthread->name, name);
pthread->status = TASK_RUNNING;
pthread->priority = prio;
/* self_kstack是线程自己在内核态下使用的栈顶地址 */
pthread->self_kstack = (uint32_t*)((uint32_t)pthread + PG_SIZE);
pthread->stack_magic = 0x19870916; // 自定义的魔数
}
/* 创建一优先级为prio的线程,线程名为name,线程所执行的函数是function(func_arg) */
struct task_struct* thread_start(char* name, int prio, thread_func function, void* func_arg) {
/* pcb都位于内核空间,包括用户进程的pcb也是在内核空间 */
struct task_struct* thread = get_kernel_pages(1);
init_thread(thread, name, prio);
thread_create(thread, function, func_arg);
asm volatile ("movl %0, %%esp; pop %%ebp; pop %%ebx; pop %%edi; pop %%esi; ret" : : "g" (thread->self_kstack) : "memory");
return thread;
}
/* 在线程中运行的函数 */
// 仅仅实现单线程
void k_thread_a(void* arg) {
/* 用void*来通用表示参数,被调用的函数知道自己需要什么类型的参数,自己转换再用 */
char* para = arg;
while(1) {
put_str(para);
}
}
int main(void) {
put_str("I am kernel\n");
init_all();
thread_start("k_thread_a", 31, k_thread_a, "argA ");
while(1);
return 0;
}
使用双向链表进行多线程调度
/********** 定义链表结点成员结构 ***********
*结点中不需要数据成元,只要求前驱和后继结点指针*/
struct list_elem {
struct list_elem* prev; // 前躯结点
struct list_elem* next; // 后继结点
};
/* 链表结构,用来实现队列 */
struct list {
/* head是队首,是固定不变的,不是第1个元素,第1个元素为head.next */
struct list_elem head;
/* tail是队尾,同样是固定不变的 */
struct list_elem tail;
};
/* 进程或线程的pcb,程序控制块 */
struct task_struct {
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
enum task_status status;
char name[16];
uint8_t priority; // 优先级越高,ticks就越多
uint8_t ticks; // 每次在处理器上执行的时间嘀嗒数
/* 此任务自上cpu运行后至今占用了多少cpu嘀嗒数,
* 也就是此任务执行了多久*/
uint32_t elapsed_ticks;
/* general_tag的作用是用于线程在一般的队列(如就绪队列)中的结点 */
struct list_elem general_tag;
/* all_list_tag的作用是用于线程队列thread_all_list中的结点 */
struct list_elem all_list_tag;
uint32_t* pgdir; // 进程自己页表的虚拟地址
uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
};
#define PG_SIZE 4096
struct task_struct* main_thread; // 主线程PCB
struct list thread_ready_list; // 就绪队列
struct list thread_all_list; // 所有任务队列,当某线程阻塞时放入
static struct list_elem* thread_tag;// 用于保存队列中的线程结点
//该函数进行线程切换
extern void switch_to(struct task_struct* cur, struct task_struct* next);
/* 获取当前线程pcb指针 */
struct task_struct* running_thread() {
uint32_t esp;
asm ("mov %%esp, %0" : "=g" (esp));
/* 取esp整数部分(高20位)即pcb起始地址 */
return (struct task_struct*)(esp & 0xfffff000);
}
/* 由kernel_thread去执行function(func_arg) */
static void kernel_thread(thread_func* function, void* func_arg) {
// 时钟中断减少ticks,间接导致线程切换
/* 执行function前要开中断,避免后面的时钟中断被屏蔽,而无法调度其它线程 */
intr_enable();
function(func_arg);
}
/* 初始化线程基本信息 */
void init_thread(struct task_struct* pthread, char* name, int prio) {
memset(pthread, 0, sizeof(*pthread));
strcpy(pthread->name, name);
if (pthread == main_thread) {
/* 由于把main函数也封装成一个线程,并且它一直是运行的,故将其直接设为TASK_RUNNING */
pthread->status = TASK_RUNNING;
} else {
pthread->status = TASK_READY;
}
/* self_kstack是线程自己在内核态下使用的栈顶地址 */
pthread->self_kstack = (uint32_t*)((uint32_t)pthread + PG_SIZE);
pthread->priority = prio;
pthread->ticks = prio;
pthread->elapsed_ticks = 0;//执行过的时钟数为0,表示线程尚未执行过
pthread->pgdir = NULL; //线程没有自己的地址空间
pthread->stack_magic = 0x19870916; // 自定义的魔数
}
/* 创建一优先级为prio的线程,线程名为name,线程所执行的函数是function(func_arg) */
struct task_struct* thread_start(char* name, int prio, thread_func function, void* func_arg) {
/* pcb都位于内核空间,包括用户进程的pcb也是在内核空间 */
struct task_struct* thread = get_kernel_pages(1);
init_thread(thread, name, prio);
thread_create(thread, function, func_arg);
/* 确保tag之前不在队列中 */
ASSERT(!elem_find(&thread_ready_list, &thread->general_tag));
/* tag加入就绪线程队列 */
list_append(&thread_ready_list, &thread->general_tag);
/* 确保之前不在队列中 */
ASSERT(!elem_find(&thread_all_list, &thread->all_list_tag));
/* 加入全部线程队列 */
list_append(&thread_all_list, &thread->all_list_tag);
return thread;
}
/* 将kernel中的main函数完善为主线程 */
static void make_main_thread(void) {
/* 因为main线程早已运行,咱们在loader.S中进入内核时的mov esp,0xc009f000,
就是为其预留了tcb,地址为0xc009e000,因此不需要通过get_kernel_page另分配一页*/
main_thread = running_thread();
init_thread(main_thread, "main", 31);
/* main函数是当前线程,当前线程不在thread_ready_list中,
* 所以只将其加在thread_all_list中. */
ASSERT(!elem_find(&thread_all_list, &main_thread->all_list_tag));
//"全部队列"存储所有线程,包括就绪的、阻塞的、正在执行的
list_append(&thread_all_list, &main_thread->all_list_tag);
}
完整的调度过程需要三部分的配合:
- 时钟中断处理函数。
- 调度器 schedule 。
- 任务切换函数 switch to 。
注册时钟中断处理函数
// 将通用中断(其他中断信息)显示的地方做调整
/* 通用的中断处理函数,一般用在异常出现时的处理 */
static void general_intr_handler(uint8_t vec_nr) {
if (vec_nr == 0x27 || vec_nr == 0x2f) { // 0x2f是从片8259A上的最后一个irq引脚,保留
return; //IRQ7和IRQ15会产生伪中断(spurious interrupt),无须处理。
}
/* 将光标置为0,从屏幕左上角清出一片打印异常信息的区域,方便阅读 */
set_cursor(0);
int cursor_pos = 0;
while(cursor_pos < 320) {
put_char(' ');
cursor_pos++;
}
set_cursor(0); // 重置光标为屏幕左上角
put_str("!!!!!!! excetion message begin !!!!!!!!\n");
set_cursor(88); // 从第2行第8个字符开始打印
put_str(intr_name[vec_nr]);
if (vec_nr == 14) { // 若为Pagefault,将缺失的地址打印出来并悬停
int page_fault_vaddr = 0;
asm ("movl %%cr2, %0" : "=r" (page_fault_vaddr)); // cr2是存放造成page_fault的地址
put_str("\npage fault addr is ");put_int(page_fault_vaddr);
}
put_str("\n!!!!!!! excetion message end !!!!!!!!\n");
// 能进入中断处理程序就表示已经处在关中断情况下,
// 不会出现调度进程的情况。故下面的死循环不会再被中断。
while(1);
}
uint32_t ticks; // ticks是内核自中断开启以来总共的嘀嗒数
/* 时钟的中断处理函数 */
static void intr_timer_handler(void) {
struct task_struct* cur_thread = running_thread();
ASSERT(cur_thread->stack_magic == 0x19870916); // 检查栈是否溢出
cur_thread->elapsed_ticks++; // 记录此线程占用的cpu时间嘀
ticks++; //从内核第一次处理时间中断后开始至今的滴哒数,内核态和用户态总共的嘀哒数
if (cur_thread->ticks == 0) { // 若进程时间片用完就开始调度新的进程上cpu
schedule();//将当前线程换下处理器,并在就绪队列中找出下个可运行的程序,将其换上处理器
} else { // 将当前进程的时间片-1
cur_thread->ticks--;
}
}
/* 初始化PIT8253 */
void timer_init() {
put_str("timer_init start\n");
/* 设置8253的定时周期,也就是发中断的周期 */
frequency_set(CONTRER0_PORT, COUNTER0_NO, READ_WRITE_LATCH, COUNTER_MODE, COUNTER0_VALUE);
register_handler(0x20, intr_timer_handler);//注册时钟中断处理程序
put_str("timer_init done\n");
}
/* 在中断处理程序数组第vector_no个元素中注册安装中断处理程序function */
void register_handler(uint8_t vector_no, intr_handler function) {
/* idt_table数组中的函数是在进入中断后根据中断向量号调用的,
* 见kernel/kernel.S的call [idt_table + %1*4] */
idt_table[vector_no] = function;
}
实现调度器 schedule
/* 实现任务调度 */
void schedule() {
ASSERT(intr_get_status() == INTR_OFF);
struct task_struct* cur = running_thread(); //获取当前运行线程的PCB
if (cur->status == TASK_RUNNING) { // 若此线程只是cpu时间片到了,还正在执行着,将其加入到就绪队列尾
ASSERT(!elem_find(&thread_ready_list, &cur->general_tag));
list_append(&thread_ready_list, &cur->general_tag);
cur->ticks = cur->priority; // 重新将当前线程的ticks再重置为其priority;
cur->status = TASK_READY;
} else {
/* 若此线程需要某事件发生后才能继续上cpu运行,
不需要将其加入队列,因为当前线程不在就绪队列中。*/
}
ASSERT(!list_empty(&thread_ready_list));
thread_tag = NULL; // thread_tag清空
/* 将thread_ready_list队列中的第一个就绪线程弹出,准备将其调度上cpu. */
thread_tag = list_pop(&thread_ready_list);
struct task_struct* next = elem2entry(struct task_struct, general_tag, thread_tag);
// (struct task_struct*)((int)thread_tag - ((int)(&((struct task_struct*)0)->general_tag)))
// 下一节点的成员地址 - (0地址->成员)偏移 = 下一节点的地址
next->status = TASK_RUNNING;
switch_to(cur, next);//汇编过程
}
宏 elem2entry 的原理,它将转换分为两步:
- 用结构体成员的地址减去成员在结构体中的偏移量,先获取到结构体起始地址 。
- 再通过强制类型转换将第 1 步中的地址转换成结构体类型。
实现任务切换函数 switch_to
无论是执行用户代码,还是执行内核代码,这些代码都属于这个完整的程序,即属于当前任务,并不是说当前任务由用户态进入内核态后当前任务就切换成内核了,这样理解是不对的。任务与任务的区别在于执行流一整套的上下文资源,这包括寄存器映像、地址空间、 IO 位图等
因此,处理器只有被新的上下文资源重新装载后,当前任务才被替换为新的任务,这才叫任务切换。当任务进入内核态时,其上下文资源并未完全替换,只是执行了“更厉害”的代码。
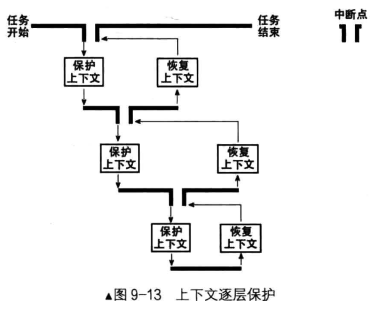
总共经历2层保护,第一次是发生时钟中断,进入中断处理程序前进行保护,第二次是执行switch_to过程时进行保护
总结:
- 上下文保护的第一部分负责保存任务进入中断前的全部寄存器,目的是能让任务恢复到中断前。
- 上下文保护的第二部分负责保存这 4 个寄存器:esi 、 edi 、 ebx 和 ebp ,目的是让任务恢复执行在任务切换发生时剩下尚未执行的内核代码,保证顺利走到退出中断的出口,利用第一部分保护的寄存器环境彻底恢复任务。
任务上下文保护的第一部分已经在 kemel.S 中由 intr%1entry完成,咱们现在要完成第二部分
[bits 32]
section .text
global switch_to
switch_to:
;栈中此处是返回地址
push esi
push edi
push ebx
push ebp
mov eax, [esp + 20] ; 得到栈中的参数cur, cur = [esp+20],当前运行线程的PCB
mov [eax], esp ; 保存栈顶指针esp. task_struct的self_kstack字段,
; self_kstack在task_struct中的偏移为0,
; 所以直接往thread开头处存4字节便可。
;------------------ 以上是备份当前线程的环境,下面是恢复下一个线程的环境 ----------------
mov eax, [esp + 24] ; 得到栈中的参数next, next = [esp+24]
mov esp, [eax] ; pcb的第一个成员是self_kstack成员,用来记录0级栈顶指针,
; 用来上cpu时恢复0级栈,0级栈中保存了进程或线程所有信息,包括3级栈指针
pop ebp
pop ebx
pop edi
pop esi
ret ; 返回到上面switch_to下面的那句注释的返回地址,
; 未由中断进入,第一次执行时会返回到kernel_thread
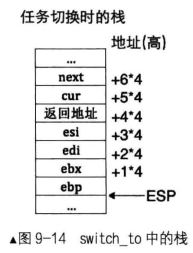
- switch_to 的操作对象是线程栈 struct_thread_stack,对栈中的返回地址及参数的设置可能会感觉有点糊涂。因此建议别只看局部,从全局上看 kernel.S 、 interrupt.c 、 timer.c、thread.c它们之间是密切配合的。
- 上下文的保护工作分为两部分,第一部分用于恢复中断前的状态,这相对好理解。咱们的函数
switch_to 完成的是第二部分,用于任务切换后恢复执行中断处理程序中的后续代码 。
启用线程调度
/* 初始化线程环境 */
void thread_init(void) {
put_str("thread_init start\n");
list_init(&thread_ready_list);
list_init(&thread_all_list);
/* 将当前main函数创建为线程 */
make_main_thread();
put_str("thread_init done\n");
}
/*负责初始化所有模块 */
void init_all() {
put_str("init_all\n");
idt_init(); // 初始化中断
mem_init(); // 初始化内存管理系统
thread_init(); // 初始化线程相关结构
timer_init(); // 初始化PIT
}
int main(void) {
put_str("I am kernel\n");
init_all();
thread_start("k_thread_a", 31, k_thread_a, "argA ");
thread_start("k_thread_b", 8, k_thread_b, "argB ");
intr_enable(); // 打开中断,使时钟中断起作用
while(1) {
put_str("Main ");
};
return 0;
}
/* 在线程中运行的函数 */
void k_thread_a(void* arg) {
/* 用void*来通用表示参数,被调用的函数知道自己需要什么类型的参数,自己转换再用 */
char* para = arg;
while(1) {
put_str(para);
}
}
/* 在线程中运行的函数 */
void k_thread_b(void* arg) {
/* 用void*来通用表示参数,被调用的函数知道自己需要什么类型的参数,自己转换再用 */
char* para = arg;
while(1) {
put_str(para);
}
}