发现的问题
在微服务开发中,gRPC 的应用绝对少不了,一般情况下,内部微服务交互,通常是使用 RPC 进行通信,如果是外部通信的话,会提供 https 接口文档
对于 gRPC 的基本使用可以查看文章 gRPC介绍
对于 gRPC ,我们需要基本知道如下的一些知识点:
-
gRPC 的基本四种模式的应用场景
- 请求响应模式
- 客户端数据流模式
- 服务端数据流模式
- 双向流模式
- Proto 文件的定义和使用
-
gRPC 拦截器的应用 , 基本的可以查看这篇 gRPC 拦截器
- 实际上有客户端拦截器 和 服务端拦截器,具体详细的可以自行学习
- gRPC 的设计原理细节
- Go-Kit 的使用
当然今天并不是要聊 gRPC 的应用或者原理,而是想聊我们在开发过程中很容易遇到的问题:
- 未复用 gRPC 客户端连接,影响性能
最近审查各个服务代码中,发现整个部门使用 gRPC 客户端请求服务端接口的时候,都是会新建一个连接,然后调用服务端接口,使用完毕之后就 close 掉, 例如这样
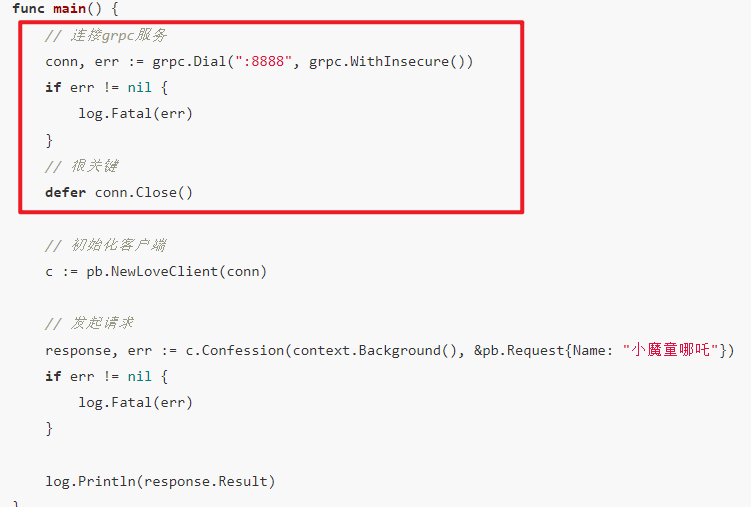
这会有什么问题呢?
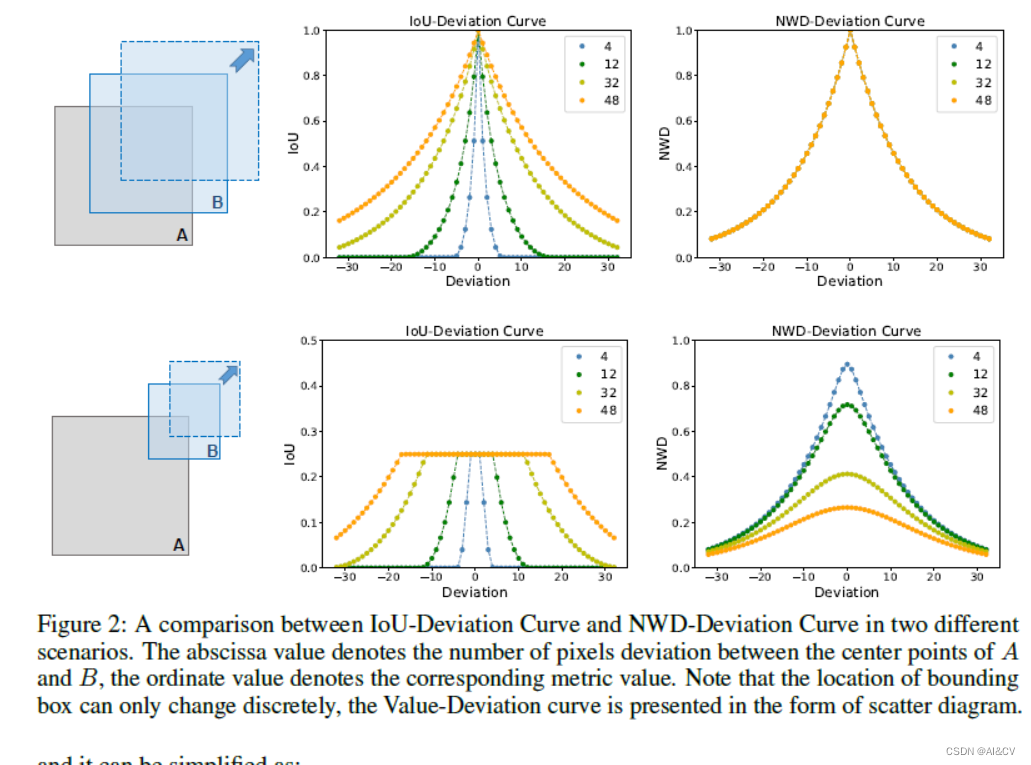
正常简单的使用不会有啥问题,但如果是面临高并发的情况,性能问题很容易就会出现,例如我们在做性能测试的时候,就会发现,打一会性能测试,客户端请求服务端的时候就会报错:
rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp xxx:xxx: connect: connection refused
实际去查看问题的时候,很明显,这是 gRPC 的连接数被打满了,很多连接都还未完全释放
那这个时候,简单思考一下,我们是没有必要对于每一次客户端请求服务端接口的时候,都新建立一次连接,并且调用完毕之后就马上关闭连接
我们知道,gRPC 的通信本质上也是 TCP 的连接,那么一次连接就需要三次握手,和四次挥手,每一次建立连接和释放连接的时候,都需要走这么一个过程,如果我们频繁的建立和释放连接,这对于资源和性能其实都是一个大大的浪费
我们还知道 gRPC 是一个高性能、开源和拥有统一规定的 RPC框架,面向对象的 http/2 通信协议,能够能节省空间和 IO 密集度的开销 ,但是我们并没有很好的将他运用起来,gRPC 服务端的连接管理不用我们操心,但是我们对于 gRPC 客户端的连续非常有必要关心,咱们要想办法复用客户端的连接
gRPC 连接池
复用连接,我们可以使用连接池的方式
对于这种复用资源,我们其实也接触了不少,例如复用线程 worker 的线程池,go 中的协程池 …
简单来说,连接池 ,就是提前创建好一定数量的 tcp 连接句柄放在池子中,咱们需要和外部通信的时候,就去池子中取一个连接来用,用完了之后,咱们就放回去
连接池解决了什么问题
很明显,连接池解决了上述咱们频繁创建连接和释放连接带来的资源和性能上的损耗,咱们节省了这部分开销后,自然就提高了咱们的性能
可是我们再次思考一下,如果这个连接池子就是只能存放固定的连接,那么我们业务扩张的时候,岂不是光等待池子里面有空闲连接就会耗费大量的时间呢?
或者是池子过大,咱们需要的连接数较少,那么开辟那么多连接岂不是一种浪费?
那么我们在设计或者是应用连接池的时候,就需要考虑如下几个方面了:
- 连接池是否支持扩缩容
- 空闲的连接是否支持超时自行关闭,是否支持保活
- 池子满的时候,处理的策略是什么样的
其实关于连接池的设计和库网上都很多,我们可以找一个案例来看看如何来使用连接池,以及它是如何来进行上述几个方面的编码落地的
如何去使用连接池
先来看看客户端如何使用连接池
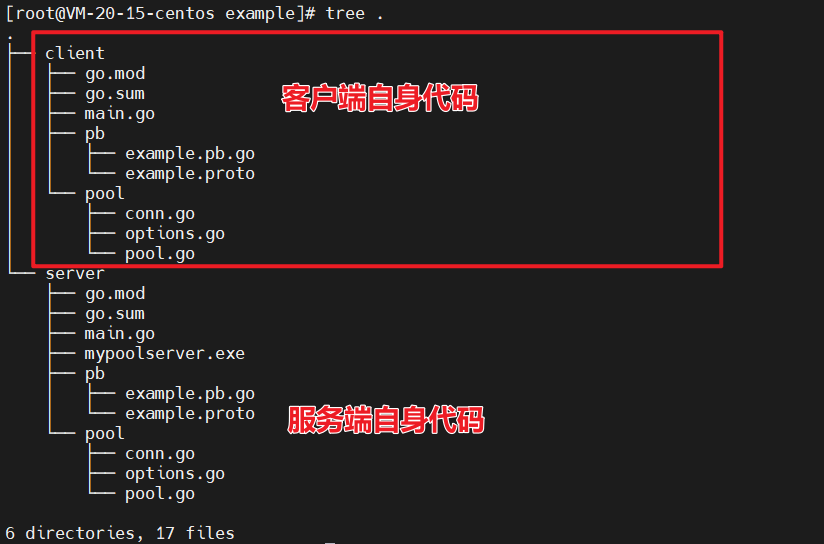
客户端使用 pool
client/main.go
package main
import (
"context"
"flag"
"fmt"
"log"
"time"
"mypoolclient/pool"
"mypoolclient/pb"
)
var addr = flag.String("addr", "127.0.0.1:8888", "the address to connect to")
func main() {
flag.Parse()
p, err := pool.New(*addr, pool.DefaultOptions)
if err != nil {
log.Fatalf("failed to new pool: %v", err)
}
defer p.Close()
conn, err := p.Get()
if err != nil {
log.Fatalf("failed to get conn: %v", err)
}
defer conn.Close()
client := pb.NewTestsvrClient(conn.Value())
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
res, err := client.Say(ctx, &pb.TestReq{Message: []byte("hi")})
if err != nil {
log.Fatalf("unexpected error from Say: %v", err)
}
fmt.Println("rpc response:", res)
}
此处的客户端,我们很明显可以看出来,以前咱们使用客户端去调用服务端接口的时候,总会不自觉的 Dial 一下建立连接
咱们使用连接池的话,就可以直接从池子里面拿一个连接出来直接使用即可
服务端
server/client.go
package main
import (
"context"
"flag"
"fmt"
"log"
"net"
"google.golang.org/grpc"
"mypoolserver/pb"
)
var port = flag.Int("port", 8888, "port number")
// server implements EchoServer.
type server struct{}
func (s *server) Say(context.Context, *pb.TestReq) (*pb.TestRsp, error) {
fmt.Println("call Say ... ")
return &pb.TestRsp{Message: []byte("hello world")}, nil
}
func main() {
flag.Parse()
listen, err := net.Listen("tcp", fmt.Sprintf("127.0.0.1:%v", *port))
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
s := grpc.NewServer()
pb.RegisterTestsvrServer(s, &server{})
fmt.Println("start server ...")
if err := s.Serve(listen); err != nil {
log.Fatalf("failed to serve: %v", err)
}
fmt.Println("over server ...")
}
连接池的具体实现方式
连接池的具体实现方式,参考了 github https://github.com/shimingyah/pool
具体的实现,都放在上述目录的 pool 下面了 , 也可以访问地址 : https://github.com/qingconglaixueit/mypoolapp
pool 包中包含了 3 个文件,作用如下:
.
├── conn.go
– 关于 grpc 连接的结构定义和方法实现
├── options.go
– 拦截器的常量定义,以及 Dial 建立连接的简单封装, 这个文件可要可不要,看自己的需求
└── pool.go
– 具体 pool 的接口定义和实现
直接来看 pool.go 中的接口定义
type Pool interface {
Get() (Conn, error)
Close() error
Status() string
}
- Get()
获取一个新的连接 , 当关闭连接的时候,会将该连接放入到池子中
- Close()
关闭连接池,自然连接池子中的连接也不再可用
关于 pool 结构的定义 ,conn 结构的定义建议,将上述 github 地址上的源码下载下来进行阅读,下面主要是分享关于
- 连接池子的创建,扩缩容,释放
- 具体 TCP 连接的创建和释放
创建连接池
func New(address string, option Options) (Pool, error) {
if address == "" {
return nil, errors.New("invalid address settings")
}
if option.Dial == nil {
return nil, errors.New("invalid dial settings")
}
if option.MaxIdle <= 0 || option.MaxActive <= 0 || option.MaxIdle > option.MaxActive {
return nil, errors.New("invalid maximum settings")
}
if option.MaxConcurrentStreams <= 0 {
return nil, errors.New("invalid maximun settings")
}
p := &pool{
index: 0,
current: int32(option.MaxIdle),
ref: 0,
opt: option,
conns: make([]*conn, option.MaxActive),
address: address,
closed: 0,
}
for i := 0; i < p.opt.MaxIdle; i++ {
c, err := p.opt.Dial(address)
if err != nil {
p.Close()
return nil, fmt.Errorf("dial is not able to fill the pool: %s", err)
}
p.conns[i] = p.wrapConn(c, false)
}
log.Printf("new pool success: %v\n", p.Status())
return p, nil
}
关于 pool 的接口,可以看成是这样的

对于创建连接池,除了校验基本的参数以外,我们知道池子其实是一个 TCP 连接的切片,长度为 option.MaxActive 即最大的活跃连接数
p.conns[i] = p.wrapConn(c, false) 表示咱们初始化一个连接,并放到连接池中,且初始化的 once 参数置为 false,表示该连接默认保存在池子中,不被销毁
换句话说,当我们需要真实销毁连接池中的连接的时候,就将该链接的 once 参数置为 false 即可,实际上也无需我们使用这去做这一步
实际上 关于每一个连接的建立也是在 New 里面完成的,只要有 1 个连接未建立成功,那么咱们的连接池就算是建立失败,咱们会调用 p.Close() 将之前建立好的连接全部释放掉
// 关闭连接池
func (p *pool) Close() error {
atomic.StoreInt32(&p.closed, 1)
atomic.StoreUint32(&p.index, 0)
atomic.StoreInt32(&p.current, 0)
atomic.StoreInt32(&p.ref, 0)
p.deleteFrom(0)
log.Printf("close pool success: %v\n", p.Status())
return nil
}
// 清除从 指定位置开始到 MaxActive 之间的连接
func (p *pool) deleteFrom(begin int) {
for i := begin; i < p.opt.MaxActive; i++ {
p.reset(i)
}
}
// 清除具体的连接
func (p *pool) reset(index int) {
conn := p.conns[index]
if conn == nil {
return
}
conn.reset()
p.conns[index] = nil
}
这里我们可以看到,当需要从池子中清除具体的连接的时候,最终从连接池子中取出对应位置上的连接 ,conn := p.conns[index], conn.reset() ,实际上是给当前这个连接进行参数赋值
func (c *conn) reset() error {
cc := c.cc
c.cc = nil
c.once = false
if cc != nil {
return cc.Close()
}
return nil
}
func (c *conn) Close() error {
c.pool.decrRef()
if c.once {
return c.reset()
}
return nil
}
最终调用 Close() 将指定的连接清除掉,这些动作都是连接池自动给我们做了,无需我们使用者去担心
我们使用连接池通过 pool.Get() 拿到具体的连接句柄 conn 之后,我们使用 conn.Close() 关闭连接,实际上也是会走到上述的 Close() 实现的位置,但是我们并未指定当然也没有权限显示的指定将 once 置位为 false ,因此对于调用者来说,是关闭了连接,对于连接池来说,实际上是将连接归还到连接池中
关于连接池子的缩容和扩容是在 pool.Get() 中实现的
func (p *pool) Get() (Conn, error) {
// the first selected from the created connections
nextRef := p.incrRef()
p.RLock()
current := atomic.LoadInt32(&p.current)
p.RUnlock()
if current == 0 {
return nil, ErrClosed
}
if nextRef <= current*int32(p.opt.MaxConcurrentStreams) {
next := atomic.AddUint32(&p.index, 1) % uint32(current)
return p.conns[next], nil
}
// the number connection of pool is reach to max active
if current == int32(p.opt.MaxActive) {
// the second if reuse is true, select from pool's connections
if p.opt.Reuse {
next := atomic.AddUint32(&p.index, 1) % uint32(current)
return p.conns[next], nil
}
// the third create one-time connection
c, err := p.opt.Dial(p.address)
return p.wrapConn(c, true), err
}
// the fourth create new connections given back to pool
p.Lock()
current = atomic.LoadInt32(&p.current)
if current < int32(p.opt.MaxActive) && nextRef > current*int32(p.opt.MaxConcurrentStreams) {
// 2 times the incremental or the remain incremental
increment := current
if current+increment > int32(p.opt.MaxActive) {
increment = int32(p.opt.MaxActive) - current
}
var i int32
var err error
for i = 0; i < increment; i++ {
c, er := p.opt.Dial(p.address)
if er != nil {
err = er
break
}
p.reset(int(current + i))
p.conns[current+i] = p.wrapConn(c, false)
}
current += i
log.Printf("grow pool: %d ---> %d, increment: %d, maxActive: %d\n",
p.current, current, increment, p.opt.MaxActive)
atomic.StoreInt32(&p.current, current)
if err != nil {
p.Unlock()
return nil, err
}
}
p.Unlock()
next := atomic.AddUint32(&p.index, 1) % uint32(current)
return p.conns[next], nil
}
从 Get 的实现中,我们可以知道 Get 的逻辑如下
- 先增加连接的引用计数,如果在设定 current*int32(p.opt.MaxConcurrentStreams) 范围内,那么直接取连接进行使用即可
- 若当前的连接数达到了最大活跃的连接数,那么就看我们新建池子的时候传递的 option 中的 reuse 参数是否是 true,若是复用,则随机取出连接池中的任意连接提供使用,如果不复用,则新建一个连接
- 其余的情况,就需要我们进行 2 倍或者 1 倍的数量对连接池进行扩容了
实际上,上述的库中,并没有提供咱们缩容的算法,如果真的有这方面的需求的话
也可以在 Get 的实现上进行缩容,具体的缩容策略可以根据实际情况来定,例如当引用计数 nextRef 只有当前活跃连接数的 20% 的时候(这只是一个例子),就可以考虑缩容了
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
可以进入地址进行体验和学习:https://xxetb.xet.tech/s/3lucCI