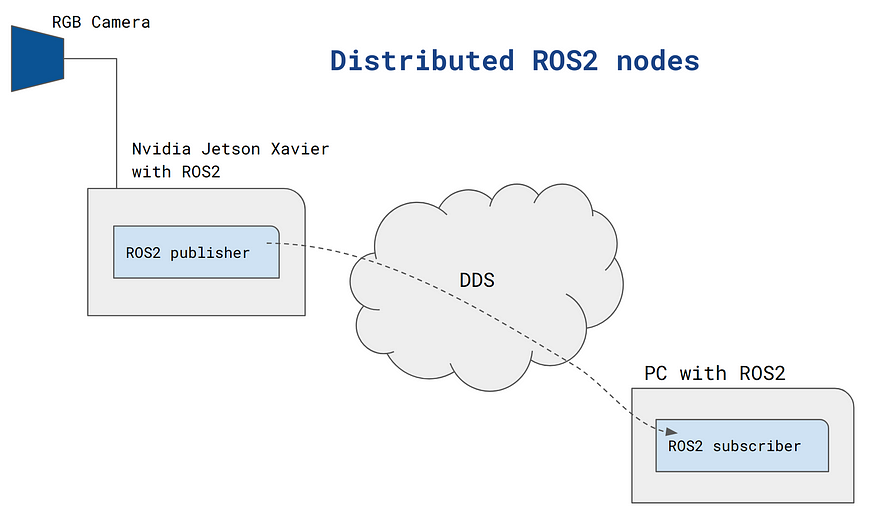
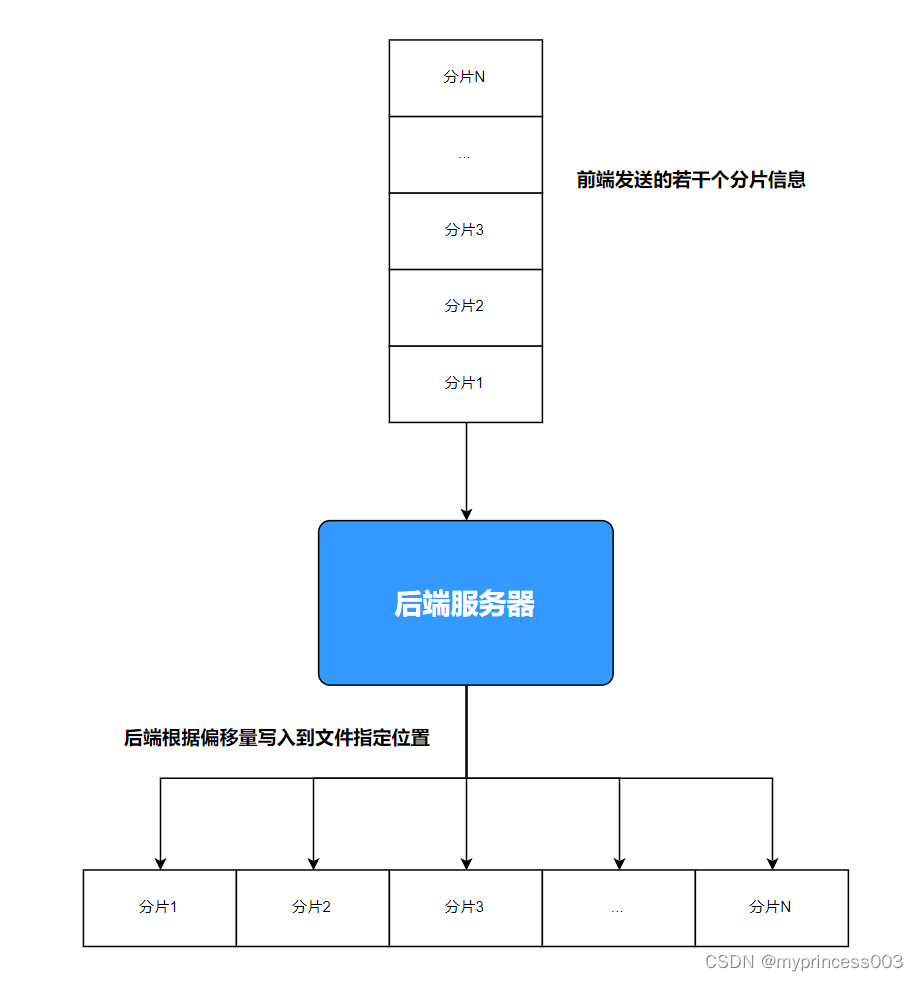
对于大文件的处理,无论是用户端还是服务端,如果一次性进行读取发送、接收都是不可取,很容易导致内存问题。所以对于大文件上传,采用切块分段上传,从上传的效率来看,利用多线程并发上传能够达到最大效率。
一、为什么要使用该技术方案
如果前端一次性上传一个非常大的文件(如1G),不采用分片/断点续传等技术方案,主要会面临以下几个隐患或问题:
1、网络传输速度慢
上传时间长大文件einmal性完整上传需要占用持续稳定的上行带宽,如果网络条件不好,上传会非常慢,损耗用户体验。
2、中间失败需重新上传
上传过程中如果由于网络等原因发生中断,整个传输会失败。这就需要用户重新再上传一遍完整文件,重复劳动。
3、服务器压力大
服务端需要占用较多资源持续处理一个大文件,对服务器性能压力较大,可能影响到其他服务。
4、流量资源浪费
一次完整上传大文件,如果遇到已经存在相同文件,会重复消耗大量网络流量,是数据浪费。
5、难以实现上传进度提示
用户无法感知上传进度,如果上传失败也不知道已经上传了多少数据。
所以为了解决这些问题,使用分片、断点续传等技术就非常重要。它可以分批次上传数据块,避免一次性全量上传的弊端。同时结合校验、记录已上传分片等手段,可以使整个上传过程可控、可恢复、节省流量,大幅提升传输效率。
二、什么是秒传
我就以本项目通俗易懂的来讲解一下秒传的实现逻辑。
1、客户端Vue在上传文件时,先计算该文件的MD5值,然后将MD5值发送到SpringBoot服务器。
2、SpringBoot服务器收到MD5值后,使用MyBatis查询MySQL数据库,检查是否已存在相同MD5值的文件。
3、如果存在,表示该文件已上传过,服务器直接从数据库查询到该文件存在哪些分片,并返回给客户端。
4、客户端拿到文件分片信息后,会直接组装完整的文件,而不再上传实际文件内容。
5、如果数据库不存在该MD5值,表示文件未上传过,服务器会返回需要客户端上传整个文件。
6、客户端上传完文件后,服务器才会在MySQL数据库中新增该文件与MD5的对应关系,以及存储文件分片信息。
7、下次再上传同样文件时,通过MD5值就可以实现秒传了。
所以核心就是利用MySQL数据库记录每个文件的MD5和分片信息,在上传时通过MD5查询,MySQL以判断是否允许秒传,从而避免重复上传相同文件。
三、什么是断点续传
接着我再以本项目通俗易懂讲解一下断点续传的概念。
1、前端Vue在上传文件时,将文件切成多个小块,每次上传一个小块。
2、每上传一个小块,后端SpringBoot会记录这个小块的信息,比如该小块的序号、文件MD5、内容Hash等。可以保存在MySQL数据库中。
3、如果上传中断了,Vue端可以向SpringBoot询问已经上传了哪些小块。
4、SpringBoot从数据库中查询,返回已上传小块的信息给Vue。
5、Vue就可以接着只上传中间中断的那一部分小块。
6、SpringBoot会根据小块的序号、文件MD5来把这些小块重新拼接成完整的文件。
7、以后如果这个文件再次上传,通过MD5值就可以知道该文件已经存在了,则直接返回上传成功,无需上传实际内容。这样通过切片上传和持久化记录已上传切片的信息,就可以实现断点续传。
关键是SpringBoot要提供接口记录和获取已上传切片信息,Vue端要切片并按顺序上传,最后SpringBoot拼文件,简单的来说就是由于网络等原因导致上传中断,通过记录已传输的数据量,在中断后继续上传剩余数据的一种技术方案。
四、什么是分片上传
最后我还是结合本项目通俗易懂讲解一下分片上传的概念。
1、分片上传的目的是将大文件切割为多个小块,实现并发上传以提高传输速度。
2、可以按配置的分片大小(例如50M一个分片)将大文件分割。
3、Vue项目将切割的每个分片按顺序上传至SpringBoot服务器,然后一块块按顺序进行上传。
4、SpringBoot服务器收到分片后可以暂存于本地,并记录这个分片的特征信息,如分片序号、文件MD5等,写入到数据库。
5、全部分片上传完成后,SpringBoot按序号顺序重新组装成原完整文件。
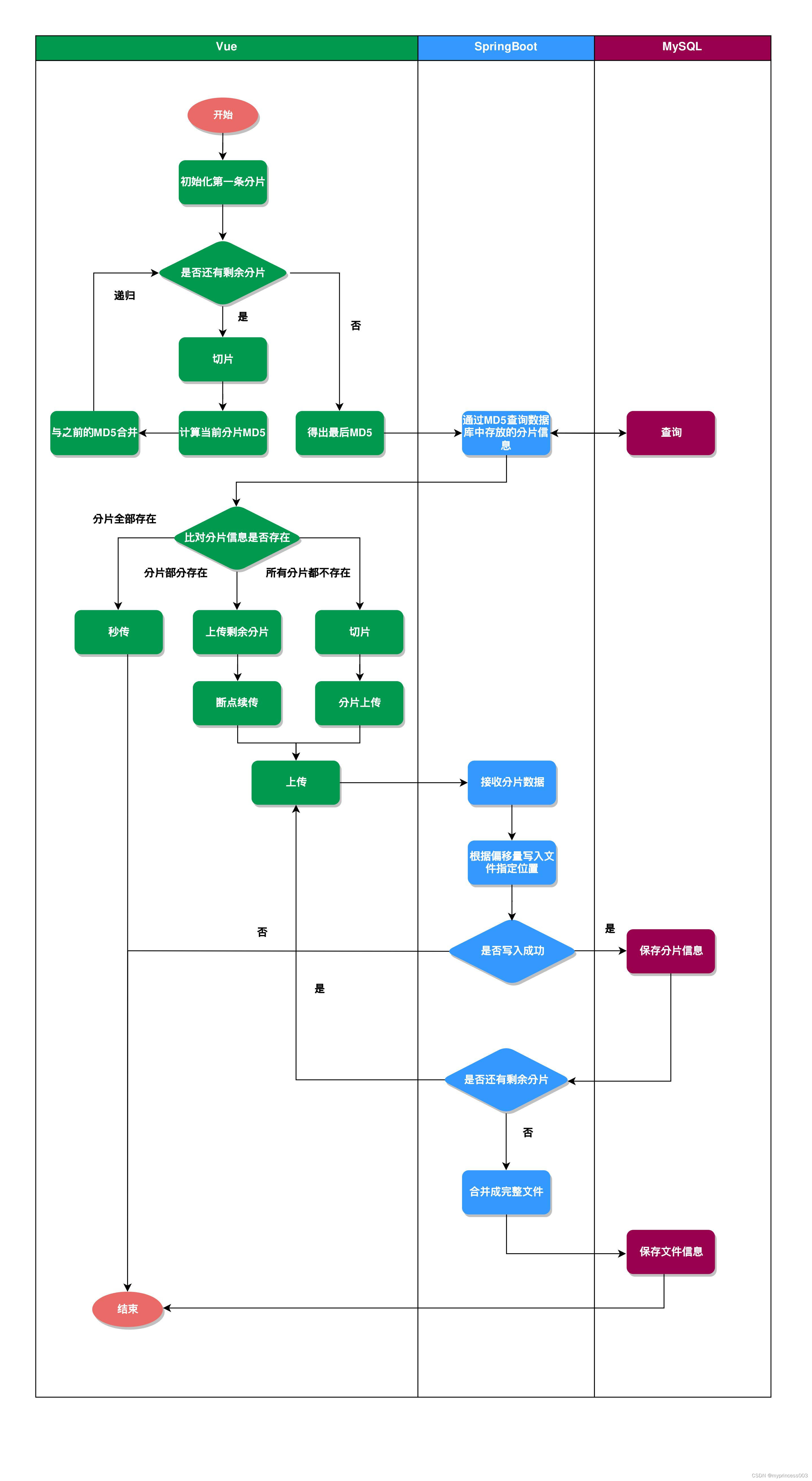
五、上传流程
前端切片处理逻辑:
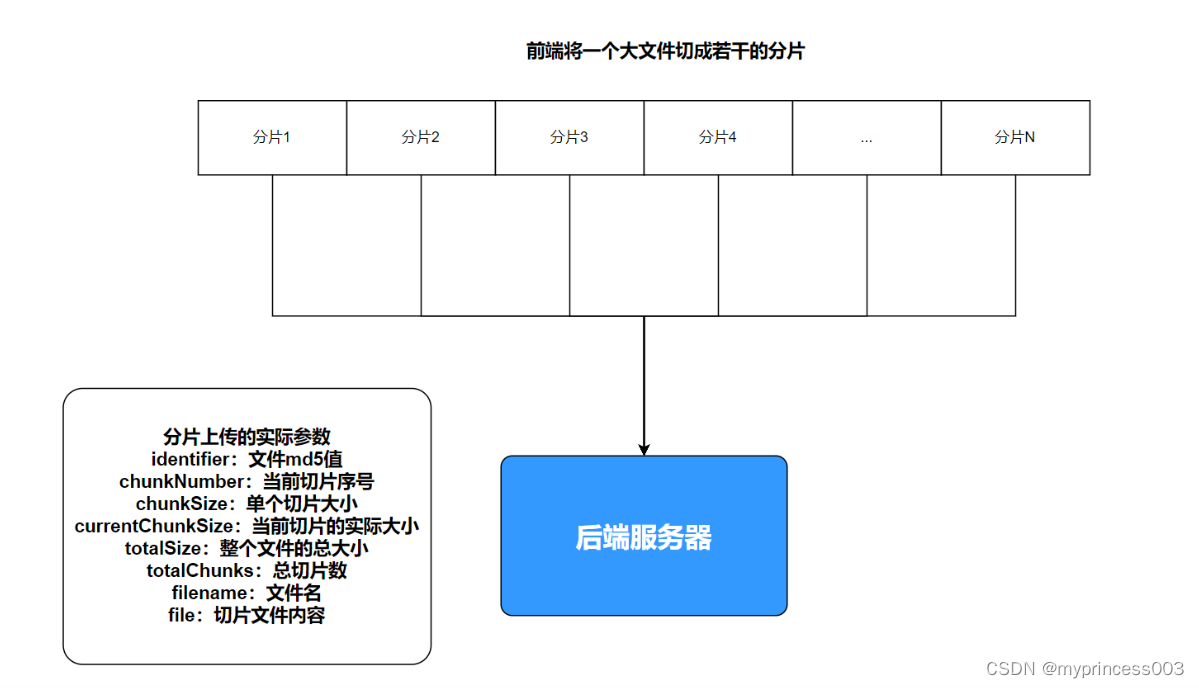
后端处理切片的逻辑:
1、在created时,初始化uploader组件,指定分片大小、上传方式等配置。
2、在onFileAdded方法中,当选择文件计算MD5后,调用file.resume()开始上传。
3、file.resume()内部首先发送一个GET请求,询问服务端该文件已上传的分片。
4、服务端返回一个JSON,里面包含已上传分片的列表。
5、uploader组件调用checkChunkUploadedByResponse,校验当前分片是否在已上传的列表中。
6、对未上传的分片,file.resume()会继续触发上传该分片的POST请求。
7、POST请求会包含一个分片的数据和偏移量等信息。
8、服务端接收分片数据,写入文件的指定位置并返回成功响应。
9、uploader组件会记录该分片已上传完成。
10、依次上传完所有分片后,服务器端合并所有分片成一个完整的文件。
11、onFileSuccess被调用,通知上传成功。
12、这样通过GET请求询问已上传分片+POST上传未完成分片+校验的方式,实现了断点续传/分片上传。
六、搭建SpringBoot项目
6.1、准备工作
6.1.1、导入pom依赖
这就是后端完整的依赖信息。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 常用工具类 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<!-- MySQL依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<!-- Mybatis依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<!-- Lombok依赖 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
6.1.2、yml配置文件
主要配置后端端口为9090、文件单次限制最大为100MB、MySQL的配置信息以及MyBatis的配置信息。
server:
port: 9090
spring:
servlet:
multipart:
max-request-size: 100MB
max-file-size: 100MB
datasource:
username: 用户名
password: 密码
url: jdbc:mysql://localhost:3306/数据库名?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
# MyBatis配置
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.example.**.domain
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath:mapping/*.xml
# 加载全局的配置文件
configLocation: classpath:mybatis/mybatis-config.xml
6.1.3、mybatis-config.xml配置文件
在resource文件夹下面新建一个mybatis文件夹,用于存放mybatis的配置文件。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 全局参数 -->
<settings>
<!-- 使全局的映射器启用或禁用缓存 -->
<setting name="cacheEnabled" value="true" />
<!-- 允许JDBC 支持自动生成主键 -->
<setting name="useGeneratedKeys" value="true" />
<!-- 配置默认的执行器.SIMPLE就是普通执行器;REUSE执行器会重用预处理语句(prepared statements);BATCH执行器将重用语句并执行批量更新 -->
<setting name="defaultExecutorType" value="SIMPLE" />
<!-- 指定 MyBatis 所用日志的具体实现 -->
<setting name="logImpl" value="SLF4J" />
<!-- 使用驼峰命名法转换字段 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
</configuration>
6.1.4、SQL文件
存储文件分片表:
CREATE TABLE `file_chunk` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`identifier` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '文件md5',
`chunk_number` int NULL DEFAULT NULL COMMENT '当前分块序号',
`chunk_size` bigint NULL DEFAULT NULL COMMENT '分块大小',
`current_chunk_size` bigint NULL DEFAULT NULL COMMENT '当前分块大小',
`total_size` bigint NULL DEFAULT NULL COMMENT '文件总大小',
`total_chunks` int NULL DEFAULT NULL COMMENT '分块总数',
`filename` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '文件名',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '文件分片表' ROW_FORMAT = DYNAMIC;
存储文件信息表:
CREATE TABLE `file_info` (
`id` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '主键',
`origin_file_name` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '文件源名',
`file_name` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '新存放文件名',
`file_path` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '文件存放路径',
`file_size` bigint NULL DEFAULT NULL COMMENT '文件总大小',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '文件信息表' ROW_FORMAT = Dynamic;
6.2、常量类
6.2.1、HttpStatus常见返回状态码常量
package com.example.bigupload.constant;
/**
* 返回状态码
* @author HTT
*/
public class HttpStatus
{
/**
* 操作成功
*/
public static final int SUCCESS = 200;
/**
* 对象创建成功
*/
public static final int CREATED = 201;
/**
* 请求已经被接受
*/
public static final int ACCEPTED = 202;
/**
* 操作已经执行成功,但是没有返回数据
*/
public static final int NO_CONTENT = 204;
/**
* 资源已被移除
*/
public static final int MOVED_PERM = 301;
/**
* 重定向
*/
public static final int SEE_OTHER = 303;
/**
* 资源没有被修改
*/
public static final int NOT_MODIFIED = 304;
/**
* 参数列表错误(缺少,格式不匹配)
*/
public static final int BAD_REQUEST = 400;
/**
* 未授权
*/
public static final int UNAUTHORIZED = 401;
/**
* 访问受限,授权过期
*/
public static final int FORBIDDEN = 403;
/**
* 资源,服务未找到
*/
public static final int NOT_FOUND = 404;
/**
* 不允许的http方法
*/
public static final int BAD_METHOD = 405;
/**
* 资源冲突,或者资源被锁
*/
public static final int CONFLICT = 409;
/**
* 不支持的数据,媒体类型
*/
public static final int UNSUPPORTED_TYPE = 415;
/**
* 系统内部错误
*/
public static final int ERROR = 500;
/**
* 接口未实现
*/
public static final int NOT_IMPLEMENTED = 501;
}
6.3、实体类
6.3.1、AjaxResult统一结果封装
package com.example.bigupload.domain;
import com.example.bigupload.constant.HttpStatus;
import org.apache.commons.lang3.ObjectUtils;
import java.util.HashMap;
/**
* 操作消息提醒
*
* @author HTT
*/
public class AjaxResult extends HashMap<String, Object>
{
private static final long serialVersionUID = 1L;
/** 状态码 */
public static final String CODE_TAG = "code";
/** 返回内容 */
public static final String MSG_TAG = "msg";
/** 数据对象 */
public static final String DATA_TAG = "data";
/**
* 初始化一个新创建的 AjaxResult 对象,使其表示一个空消息。
*/
public AjaxResult()
{
}
/**
* 初始化一个新创建的 AjaxResult 对象
*
* @param code 状态码
* @param msg 返回内容
*/
public AjaxResult(int code, String msg)
{
super.put(CODE_TAG, code);
super.put(MSG_TAG, msg);
}
/**
* 初始化一个新创建的 AjaxResult 对象
*
* @param code 状态码
* @param msg 返回内容
* @param data 数据对象
*/
public AjaxResult(int code, String msg, Object data)
{
super.put(CODE_TAG, code);
super.put(MSG_TAG, msg);
if (ObjectUtils.isNotEmpty(data))
{
super.put(DATA_TAG, data);
}
}
/**
* 返回成功消息
*
* @return 成功消息
*/
public static AjaxResult success()
{
return AjaxResult.success("操作成功");
}
/**
* 返回成功数据
*
* @return 成功消息
*/
public static AjaxResult success(Object data)
{
return AjaxResult.success("操作成功", data);
}
/**
* 返回成功消息
*
* @param msg 返回内容
* @return 成功消息
*/
public static AjaxResult success(String msg)
{
return AjaxResult.success(msg, null);
}
/**
* 返回成功消息
*
* @param msg 返回内容
* @param data 数据对象
* @return 成功消息
*/
public static AjaxResult success(String msg, Object data)
{
return new AjaxResult(HttpStatus.SUCCESS, msg, data);
}
/**
* 返回错误消息
*
* @return
*/
public static AjaxResult error()
{
return AjaxResult.error("操作失败");
}
/**
* 返回错误消息
*
* @param msg 返回内容
* @return 警告消息
*/
public static AjaxResult error(String msg)
{
return AjaxResult.error(msg, null);
}
/**
* 返回错误消息
*
* @param msg 返回内容
* @param data 数据对象
* @return 警告消息
*/
public static AjaxResult error(String msg, Object data)
{
return new AjaxResult(HttpStatus.ERROR, msg, data);
}
/**
* 返回错误消息
*
* @param code 状态码
* @param msg 返回内容
* @return 警告消息
*/
public static AjaxResult error(int code, String msg)
{
return new AjaxResult(code, msg, null);
}
/**
* 方便链式调用
*
* @param key 键
* @param value 值
* @return 数据对象
*/
@Override
public AjaxResult put(String key, Object value)
{
super.put(key, value);
return this;
}
}
6.3.2、文件切片类
package com.example.bigupload.domain;
import lombok.Data;
import org.springframework.web.multipart.MultipartFile;
import java.io.Serializable;
import java.util.Date;
@Data
public class FileChunk implements Serializable {
/**
* 主键
*/
private Long id;
/**
* 文件 md5
*/
private String identifier;
/**
* 当前分块序号
*/
private Integer chunkNumber;
/**
* 分块大小
*/
private Long chunkSize;
/**
* 当前分块大小
*/
private Long currentChunkSize;
/**
* 文件总大小
*/
private Long totalSize;
/**
* 分块总数
*/
private Integer totalChunks;
/**
* 文件名
*/
private String filename;
/**
* 创建时间
*/
private Date createTime;
/**
* 文件分片数据
*/
private MultipartFile file;
}
6.3.3、文件信息类
package com.example.bigupload.domain;
import lombok.Data;
import java.util.Date;
@Data
public class FileInfo {
/**
* 主键
*/
private String id;
/**
* 文件源名
*/
private String originFileName;
/**
* 新存放文件名
*/
private String fileName;
/**
* 文件存放路径
*/
private String filePath;
/**
* 文件总大小
*/
private Long fileSize;
/**
* 创建时间
*/
private Date createTime;
}
4、GlobalCorsConfig全局CORS跨域配置
1、@Configuration注解表示这是一个配置类。
2、WebMvcConfigurer接口用于自定义SpringMVC的配置。
3、addCorsMappings方法用于定义跨域访问策略。
4、addMapping(“/**”)表示拦截所有请求路径。
5、allowedOriginPatterns(“*”)表示允许所有域名的请求。
6、allowCredentials(true)表示允许携带cookie。
7、allowedHeaders表示允许的请求头。
8、allowedMethods表示允许的请求方法。
9、maxAge(3600)表示预检请求的有效期为3600秒。
这样就实现了一个全局的CORS跨域配置,允许所有域名的请求访问本服务,可以自由设置请求头和方法,最大有效期为1小时。
package com.example.bigupload.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class GlobalCorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOriginPatterns("*")
.allowCredentials(true)
.allowedHeaders("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("Authorization", "Cache-Control", "Content-Type")
.maxAge(3600);
}
}
6.5、持久层
6.5.1、FileChunkMapper.xml文件
主要撰写了个2个SQL,一个是根据md5加密信息去查询数据库的所有分片信息,还有个便是记录每次分片上传成功的文件信息。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.bigupload.mapper.FileChunkMapper">
<select id="findFileChunkParamByMd5" resultType="com.example.bigupload.domain.FileChunk">
SELECT * FROM file_chunk where identifier =#{identifier}
</select>
<select id="findCountByMd5" resultType="Integer">
SELECT COUNT(*) FROM file_chunk where identifier =#{identifier}
</select>
<insert id="insertFileChunk" parameterType="com.example.bigupload.domain.FileChunk">
INSERT INTO file_chunk
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="identifier != null">identifier,</if>
<if test="chunkNumber != null">chunk_number,</if>
<if test="chunkSize != null">chunk_size,</if>
<if test="currentChunkSize != null">current_chunk_size,</if>
<if test="totalSize != null">total_size,</if>
<if test="totalChunks != null">total_chunks,</if>
<if test="filename != null">filename,</if>
<if test="createTime != null">create_time,</if>
</trim>
<trim prefix="VALUES (" suffix=")" suffixOverrides=",">
<if test="identifier != null">#{identifier},</if>
<if test="chunkNumber != null">#{chunkNumber},</if>
<if test="chunkSize != null">#{chunkSize},</if>
<if test="currentChunkSize != null">#{currentChunkSize},</if>
<if test="totalSize != null">#{totalSize},</if>
<if test="totalChunks != null">#{totalChunks},</if>
<if test="filename != null">#{filename},</if>
<if test="createTime != null">#{createTime},</if>
</trim>
</insert>
</mapper>
6.5.2、FileChunkMapper文件
package com.example.bigupload.mapper;
import com.example.bigupload.domain.FileChunk;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
/**
* @author HTT
*/
@Mapper
public interface FileChunkMapper {
public List<FileChunk> findFileChunkParamByMd5(String identifier);
public Integer findCountByMd5(String identifier);
public int insertFileChunk(FileChunk fileChunk);
}
6.5.3、FileInfoMapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.bigupload.mapper.FileInfoMapper">
<insert id="insert">
INSERT INTO file_info
(id, origin_file_name, file_name, file_path, file_size, create_time)
VALUES
(#{id}, #{originFileName}, #{fileName}, #{filePath}, #{fileSize}, #{createTime});
</insert>
</mapper>
6.5.4、FileInfoMapper文件
package com.example.bigupload.mapper;
import com.example.bigupload.domain.FileInfo;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface FileInfoMapper {
int insert(FileInfo fileInfo);
}
6.6、文件上传核心服务类(重要)
6.6.1、文件上传检查的逻辑
1、根据文件标识identifier(md5)从数据库查询是否已存在该文件。
List<FileChunk> list = fileChunkMapper.findFileChunkParamByMd5(fileChunk.getIdentifier());
Map<String, Object> data = new HashMap<>(1);
2、如果查询不到,表示文件未上传过,返回uploaded=false。
if (list == null || list.size() == 0) {
data.put("uploaded", false);
return AjaxResult.success("文件上传成功",data);
}
3、如果查询到只有一片,则表示整个文件已上传,返回uploaded=true。
if (list.get(0).getTotalChunks() == 1) {
data.put("uploaded", true);
data.put("url", "");
return AjaxResult.success("文件上传成功",data);
4、如果查询到多片数据,则表示这是一个分片上传的大文件。
5、遍历这些分片数据,获取每个文件块的编号保存到uploadedFiles数组中。
6、最后返回uploadedChunks给前端。
// 处理分片
int[] uploadedFiles = new int[list.size()];
int index = 0;
for (FileChunk fileChunkItem : list) {
uploadedFiles[index] = fileChunkItem.getChunkNumber();
index++;
}
data.put("uploadedChunks", uploadedFiles);
return AjaxResult.success("文件上传成功",data);
7、前端拿到这些数据后,就知道该大文件已上传了些什么分片,还剩什么分片需要上传。
8、然后继续断点上传剩余分片,实现断点续传的效果所以这段代码主要是通过查询文件数据库,判断该文件是否全部或部分已存在,从而判断是否需要上传完整文件或者继续断点上传。
这样可以避免重复上传,提高传输效率,是实现秒传和断点续传的关键逻辑。
public AjaxResult checkUpload(FileChunk fileChunk) {
List<FileChunk> list = fileChunkMapper.findFileChunkParamByMd5(fileChunk.getIdentifier());
Map<String, Object> data = new HashMap<>(1);
// 判断文件存不存在
if (list == null || list.size() == 0) {
data.put("uploaded", false);
return AjaxResult.success("文件上传成功",data);
}
// 处理单文件
if (list.get(0).getTotalChunks() == 1) {
data.put("uploaded", true);
data.put("url", "");
return AjaxResult.success("文件上传成功",data);
}
// 处理分片
int[] uploadedFiles = new int[list.size()];
int index = 0;
for (FileChunk fileChunkItem : list) {
uploadedFiles[index] = fileChunkItem.getChunkNumber();
index++;
}
data.put("uploadedChunks", uploadedFiles);
return AjaxResult.success("文件上传成功",data);
}
6.6.2、实现分片上传核心逻辑
这段代码是使用RandomAccessFile实现分片上传写入的逻辑。
具体逻辑:
1、创建一个RandomAccessFile对象,根据文件路径进行存放,以读取和写入的模式打开文件,通过它可以对文件进行随机访问读取和写入。
RandomAccessFile randomAccessFile = new RandomAccessFile(filePath, "rw");
2、计算每个分片的大小chunkSize,如果前端没有传入,则使用默认值(50MB,是我定义的常量)。
public static final long DEFAULT_CHUNK_SIZE = 50 * 1024 * 1024;
long chunkSize = fileChunk.getChunkSize() == 0L ? DEFAULT_CHUNK_SIZE : fileChunk.getChunkSize().longValue();
3、计算当前分片的偏移量offset,通过(分片序号-1)* 分片大小来计算。
long offset = chunkSize * (fileChunk.getChunkNumber() - 1);
4、通过seek()方法定位到该分片的偏移量位置。
randomAccessFile.seek(offset);
5、通过write()方法将当前分片的文件内容bytes写入。
randomAccessFile.write(fileChunk.getFile().getBytes());
6、重复该过程,直到所有分片都写入完成。
7、最后关闭文件。
randomAccessFile.close();
RandomAccessFile可以以任意位置读写文件,所以可以按分片顺序写入指定位置,实现分片上传的效果。这种方式可以充分利用操作系统的文件缓存,比较高效。每个分片只写入一次,不需要再读取修改文件,节约了IO操作。这就是通过RandomAccessFile实现分片上传的常用方式,把各个分片拼接成完整的文件。
下面我通过介绍一个简单的实际例子来通俗易懂的讲解一下:
先介绍一下什么是偏移量:就是用来确定每个分片在整个文件内的位置。
根据这段关键代码:
// 计算每个分片大小
long chunkSize = fileChunk.getChunkSize() == 0L ? DEFAULT_CHUNK_SIZE : fileChunk.getChunkSize().longValue();
// 计算分片的偏移量
long offset = chunkSize * (fileChunk.getChunkNumber() - 1);
偏移量 = 分片大小 * (分片序号 - 1)
以230MB文件为例:
1、分片大小chunkSize是50MB.
2、第一片分片号fileChunk、getChunkNumber()是1。
3、那么第一片偏移量offset = 50MB * (1 - 1) = 0。
第二片分片号是2,那么第二片偏移量offset = 50MB * (2 - 1) = 50MB。以此类推,可以计算出每一片的偏移量。
第n片的偏移量公式就是: offset = 分片大小 * (第n片分片序号 - 1)。
所以完整的执行过程就是这样:
230MB这个文件会被切分成5个分片:
1、第一个分片:50MB,偏移量为0。
2、第二个分片:50MB,偏移量为50MB。
3、第三个分片:50MB,偏移量为100MB。
4、第四个分片:50MB,偏移量为150MB。
5、第五个分片:30MB,偏移量为200MB。
客户端可以并发上传这5个分片:
1、上传第一个分片,写入偏移量0处。
2、上传第二个分片,写入偏移量50MB处。
3、上传第三个分片,写入偏移量100MB处。
4、上传第四个分片,写入偏移量150MB处。
5、上传第五个分片,写入偏移量200MB处。
服务器端通过RandomAccessFile可以按照偏移量直接写入每个分片的内容。这样就可以通过5个50MB的分片很快上传完成这个230MB的大文件,实现了分片上传的效果,提高了传输速度。
private void uploadFileByRandomAccessFile(String filePath, FileChunk fileChunk) throws IOException {
RandomAccessFile randomAccessFile = new RandomAccessFile(filePath, "rw");
// 分片大小必须和前端匹配,否则上传会导致文件损坏
long chunkSize = fileChunk.getChunkSize() == 0L ? DEFAULT_CHUNK_SIZE : fileChunk.getChunkSize().longValue();
// 偏移量
long offset = chunkSize * (fileChunk.getChunkNumber() - 1);
// 定位到该分片的偏移量
randomAccessFile.seek(offset);
// 写入
randomAccessFile.write(fileChunk.getFile().getBytes());
randomAccessFile.close();
}
6.6.3、文件分片处理
这里最关键的就是uploadFileByRandomAccessFile这个方法,它实现了对文件的分片随机读写,可以把上传的文件分片数据写入到正确的偏移位置。
根据文件的唯一标识(MD5)去查询数据库的分片总数,如果和前端切片的总数相等,则代表此大文件上传完毕,将本次上传的完整文件信息存入数据库。
public AjaxResult uploadChunkFile(FileChunk fileChunk) throws IOException {
String newFileName = fileChunk.getIdentifier() + fileChunk.getFilename();
String filePath = "D:\\大文件分片存放\\" + newFileName;
uploadFileByRandomAccessFile(filePath, fileChunk);
fileChunk.setCreateTime(new Date());
fileChunkMapper.insertFileChunk(fileChunk);
//数据库中已上传的分片总数
Integer count = fileChunkMapper.findCountByMd5(fileChunk.getIdentifier());
if(fileChunk.getTotalChunks().equals(count)){
FileInfo fileInfo = new FileInfo();
String originalFilename = fileChunk.getFile().getOriginalFilename();
fileInfo.setId(UUID.randomUUID().toString());
fileInfo.setOriginFileName(originalFilename);
fileInfo.setFileName(newFileName);
fileInfo.setFilePath(filePath);
fileInfo.setFileSize(fileChunk.getTotalSize());
fileInfo.setCreateTime(new Date());
fileInfoMapper.insert(fileInfo);
}
return AjaxResult.success("文件上传成功");
}
6.6.4、完整代码
package com.example.bigupload.service;
import com.example.bigupload.domain.AjaxResult;
import com.example.bigupload.domain.FileChunk;
import com.example.bigupload.domain.FileInfo;
import com.example.bigupload.mapper.FileChunkMapper;
import com.example.bigupload.mapper.FileInfoMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.*;
/**
* @author HTT
*/
@Slf4j
@Service
public class UploadService {
/**
* 默认的分片大小:50MB
*/
public static final long DEFAULT_CHUNK_SIZE = 50 * 1024 * 1024;
@Resource
private FileChunkMapper fileChunkMapper;
@Resource
private FileInfoMapper fileInfoMapper;
public AjaxResult checkUpload(FileChunk fileChunk) {
List<FileChunk> list = fileChunkMapper.findFileChunkParamByMd5(fileChunk.getIdentifier());
Map<String, Object> data = new HashMap<>(1);
// 判断文件存不存在
if (list == null || list.size() == 0) {
data.put("uploaded", false);
return AjaxResult.success("文件上传成功",data);
}
// 处理单文件
if (list.get(0).getTotalChunks() == 1) {
data.put("uploaded", true);
data.put("url", "");
return AjaxResult.success("文件上传成功",data);
}
// 处理分片
int[] uploadedFiles = new int[list.size()];
int index = 0;
for (FileChunk fileChunkItem : list) {
uploadedFiles[index] = fileChunkItem.getChunkNumber();
index++;
}
data.put("uploadedChunks", uploadedFiles);
return AjaxResult.success("文件上传成功",data);
}
/**
* 上传分片文件
* @param fileChunk
* @return
* @throws Exception
*/
public AjaxResult uploadChunkFile(FileChunk fileChunk) throws IOException {
String newFileName = fileChunk.getIdentifier() + fileChunk.getFilename();
String filePath = "D:\\大文件分片存放\\" + newFileName;
uploadFileByRandomAccessFile(filePath, fileChunk);
fileChunk.setCreateTime(new Date());
fileChunkMapper.insertFileChunk(fileChunk);
//数据库中已上传的分片总数
Integer count = fileChunkMapper.findCountByMd5(fileChunk.getIdentifier());
if(fileChunk.getTotalChunks().equals(count)){
FileInfo fileInfo = new FileInfo();
String originalFilename = fileChunk.getFile().getOriginalFilename();
fileInfo.setId(UUID.randomUUID().toString());
fileInfo.setOriginFileName(originalFilename);
fileInfo.setFileName(newFileName);
fileInfo.setFilePath(filePath);
fileInfo.setFileSize(fileChunk.getTotalSize());
fileInfo.setCreateTime(new Date());
fileInfoMapper.insert(fileInfo);
}
return AjaxResult.success("文件上传成功");
}
private void uploadFileByRandomAccessFile(String filePath, FileChunk fileChunk) throws IOException {
RandomAccessFile randomAccessFile = new RandomAccessFile(filePath, "rw");
// 分片大小必须和前端匹配,否则上传会导致文件损坏
long chunkSize = fileChunk.getChunkSize() == 0L ? DEFAULT_CHUNK_SIZE : fileChunk.getChunkSize().longValue();
// 偏移量
long offset = chunkSize * (fileChunk.getChunkNumber() - 1);
// 定位到该分片的偏移量
randomAccessFile.seek(offset);
// 写入
randomAccessFile.write(fileChunk.getFile().getBytes());
randomAccessFile.close();
}
}
6.7、FileController请求层
写的很简洁,之所以都是相同的/upload的接口,请求方式分别是get和post,是因为uploader组件检验的时候先调用/upload的get请求,然后上传分片会调用/upload的post请求。
1、首先用GET请求校验文件是否存在,决定是否实现秒传、断点续传还是分片上传。
2、然后客户端按顺序用POST请求上传各个分片,服务端收到分片后写入文件。
package com.example.bigupload.controller;
import com.example.bigupload.domain.AjaxResult;
import com.example.bigupload.domain.FileChunk;
import com.example.bigupload.service.UploadService;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
@RestController
@RequestMapping("/file")
public class FileController {
@Resource
private UploadService uploadService;
@GetMapping("/upload")
public AjaxResult checkUpload(FileChunk fileChunk){
return uploadService.checkUpload(fileChunk);
}
@PostMapping("/upload")
public AjaxResult uploadChunkFile(FileChunk fileChunk) throws Exception {
return uploadService.uploadChunkFile(fileChunk);
}
}
七、搭建Vue项目
这边我使用的是Vue2.0,这是项目完整截图
7.1、准备工作
1、安装uploader
npm install --save vue-simple-uploader
2、按照spark-md5
npm install --save spark-md5
3、在main.js中引入组件
import uploader from ‘vue-simple-uploader’
Vue.use(uploader)
7.2、HomeView页面
其实这里面主要的逻辑就是,先通过getFileMD5方法进行切片和生成本次文件的MD5校验码,然后通过file.resume()方法checkChunkUploadedByResponse方法,在调用checkChunkUploadedByResponse方法之前先发送get请求从后端数据库获取当前文件的所有的已上传的分片信息,再通过checkChunkUploadedByResponse方法中的逻辑来进行判断哪些分片还需要上传。
7.2.1、使用uploader组件
这个组件使用的是第三方库vue-uploader,它是一个上传组件。
参数解释:
1、ref:给组件一个引用名,这里是uploader。
2、options:上传的选项,例如上传地址、接受的文件类型等。
3、autoStart:是否自动开始上传,默认是true,这里设置为false。
4、fileStatusText:自定义上传状态提示文字。
5、@file-added:文件添加时的钩子。
6、@file-success:文件上传成功时的钩子。
7、@file-error:文件上传失败时的钩子。
8、@file-progress:文件上传进度的钩子。
包含三个子组件:
1、uploader-unsupport:如果浏览器不支持,显示这个组件。
2、uploader-drop:拖拽上传区域组件,可以自定义内容。
3、uploader-btn:上传按钮组件。
4、uploader-files:已选择待上传文件的列表组件。
所以这个组件实现了选择文件、拖拽上传、显示上传进度、回调上传结果等完整的文件上传功能。我们可以通过options来配置上传参数,通过各种钩子来处理上传结果,并可以自定义上传区域的样式,实现一个完整的上传组件。
完整代码:
<template>
<div class="home">
<uploader
ref="uploader"
:options="options"
:autoStart="false"
:file-status-text="fileStatusText"
@file-added="onFileAdded"
@file-success="onFileSuccess"
@file-error="onFileError"
@file-progress="onFileProgress"
class="uploader-example"
>
<uploader-unsupport></uploader-unsupport>
<uploader-drop>
<p>将文件拖放到此处以上传</p>
<uploader-btn>选择文件</uploader-btn>
</uploader-drop>
<uploader-files> </uploader-files>
</uploader>
<br />
</div>
</template>
7.2.2、初始化data数据
先提前引入Md5工具和初始化分片大小。
import SparkMD5 from "spark-md5";
const CHUNK_SIZE = 50 * 1024 * 1024;
options参数:
1、target:上传的接口地址
2、testChunks:是否开启分片上传校验。分片上传是把文件分成小块后并发上传,可以提高大文件上传效率。
3、uploadMethod:上传方法,默认是POST。
4、chunkSize:分片大小,默认1MB。这个可根据实际情况调整,分片太小会增加请求次数,太大上传失败重传就重传很多。
5、simultaneousUploads:并发上传块数,默认是3,可根据需要调整。
7.2.3、checkChunkUploadedByResponse方法(重要)
这个方法的作用就是校验当前上传的分片是否已经成功上传过了。
此方法只会调用一次upload接口提供的get请求,从后端获取本文件的所有分片信息,它有两个参数:
chunk:当前分片的信息,包含偏移offset等数据。
message:调用upload接口提供的get请求返回的所有分片信息。
如果该方法返回true,表示当前分片已经上传成功,那么就不需要再调用upload方法发送post上传请求了。
函数内部首先把服务端返回的响应内容message解析成JSON对象。
let messageObj = JSON.parse(message);
然后取出data字段作为数据对象。
let dataObj = messageObj.data;
接着判断data对象中是否包含uploaded字段,如果有直接返回uploaded的值,uploaded字段通常是服务端表示分片是否上传完成的标志。
if (dataObj.uploaded !== undefined) {
return dataObj.uploaded;
}
如果已经上传的分块列表为:[1,2],即分块1和分块2已上传成功,分块3和分块4还未上传。
要校验的当前分块是分块2,偏移量offset=1。
那么执行过程是:
1、dataObj.uploadedChunks的值是[1,2]。
2、chunk.offset的值仍是1。
3、chunk.offset+1计算出分块2的序号是2。
4、indexOf(2)在数组[1,2]中查找值2。
5、返回的索引值是1,即找到了。
所以对于分块2来说,返回true,表示该分块已上传成功。
return (dataObj.uploadedChunks || []).indexOf(chunk.offset + 1) >= 0;
return的目的是通过查看服务器返回的已上传分块列表,从而判断当前分块是否已经上传成功过,否则继续调用upload提供的post请求进行上传。
7.2.4、parseTimeRemaining方法
格式化剩余上传时间的方法。会把原始的时间格式化成xx天xx时xx分xx秒的格式。
关键代码:
parseTimeRemaining: function (timeRemaining, parsedTimeRemaining) {
return parsedTimeRemaining
.replace(/\syears?/, "年")
.replace(/\days?/, "天")
.replace(/\shours?/, "小时")
.replace(/\sminutes?/, "分钟")
.replace(/\sseconds?/, "秒");
},
所以这些配置主要是为了实现分片上传,通过切块、并发、校验等机制来提高大文件上传效率和体验。
关键代码:
options: {
target: 'http://127.0.0.1:9090/file/upload',
testChunks: true,
uploadMethod: "post",
chunkSize: CHUNK_SIZE,
// 并发上传数,默认为 3
simultaneousUploads: 3,
checkChunkUploadedByResponse: (chunk, message) => {
let messageObj = JSON.parse(message);
let dataObj = messageObj.data;
if (dataObj.uploaded !== undefined) {
return dataObj.uploaded;
}
return (dataObj.uploadedChunks || []).indexOf(chunk.offset + 1) >= 0;
},
parseTimeRemaining: function (timeRemaining, parsedTimeRemaining) {
return parsedTimeRemaining
.replace(/\syears?/, "年")
.replace(/\days?/, "天")
.replace(/\shours?/, "小时")
.replace(/\sminutes?/, "分钟")
.replace(/\sseconds?/, "秒");
},
},
7.2.5、其他参数
参数作用:
1、fileStatus:定义上传状态的文字描述,会用在显示上传状态的组件中。
2、uploadFileList:已上传成功的文件列表,可以用来保存上传成功的文件信息。
关键代码:
fileStatus: {
success: "上传成功",
error: "上传错误",
uploading: "正在上传",
paused: "停止上传",
waiting: "等待中",
},
uploadFileList: [],
7.2.6、onFileAdded方法(重要)
具体逻辑:
1、把添加的文件添加到上传文件列表uploadFileList中。
2、计算完MD5后,调用 file.resume()。
3、file.resume()内部会构造一个GET请求,包含文件MD5信息,发送到服务器。
4、服务器收到该请求后,根据MD5查询文件是否存在。
5、如果存在,就返回已上传的块信息。
6、前端收到响应后,调用checkChunkUploadedByResponse逻辑。
7、checkChunkUploadedByResponse根据响应数据,校验每个分块的上传状态,根据响应判断哪些分片已上传,哪些未上传。
8、对未上传的块进行上传,对于未上传的分片,file.resume() 会继续触发上传该分片的请求(POST),直到所有分片校验并上传完成。
所以file.resume() 这个方法既包含了checkChunkUploadedByResponse的校验逻辑,也包含了触发实际分片上传的逻辑。
关键代码:
onFileAdded(file) {
this.uploadFileList.push(file);
// 2. 计算文件 MD5 并请求后台判断是否已上传,是则取消上传
this.getFileMD5(file, (md5) => {
if (md5 != "") {
// 修改文件唯一标识
file.uniqueIdentifier = md5;
// 恢复上传
file.resume();
}
});
},
7.2.7、getFileMD5方法(重要)
计算文件上传前的MD5值,边切片边进行MD5累加计算的,大致逻辑是这样的:
首先初始化SparkMD5对象spark来保存MD5的累计值,然后通过FileReader分块读取文件内容,每次读取一个chunk大小的切片,在读取每个切片时,将该切片内容append到spark对象中,进行 MD5累加,接着重复该过程直到全部切片读取完成。最后调用spark.end()得到累计计算的文件整体 MD5 值。
具体逻辑:
1、创建SparkMD5对象spark,用于计算MD5值。
let spark = new SparkMD5.ArrayBuffer();
2、创建FileReader对象fileReader,用于读取文件内容。
let fileReader = new FileReader();
3、获取File对象slice方法的兼容实现,负责获取文件的切片方法。
let blobSlice =
File.prototype.slice ||
File.prototype.mozSlice ||
File.prototype.webkitSlice;
4、计算分片总数chunks,每片大小是CHUNK_SIZE。
let currentChunk = 0;
let chunks = Math.ceil(file.size / CHUNK_SIZE);
5、记录开始时间startTime。
let startTime = new Date().getTime();
6、暂停上传文件file.pause()。
file.pause();
7、loadNext函数是用来加载文件分片的,
具体逻辑:
第一步、计算当前分片的起始位置start,是当前分片序号currentChunk乘以分片大小CHUNK_SIZE。
第二步、计算当前分片的结束位置end: 如果start+分片大小大于等于总大小file.size,则end就是总大小file.size,否则end就是start+分片大小CHUNK_SIZE。
第三步、通过blobSlice方法获取一个文件的分片Blob对象,它截取文件从start到end的部分。其实就是调用切片方法,传入文件对象和范围,进行实际的文件切片操作。
第四步、调用FileReader的readAsArrayBuffer方法读取这个Blob分片对象的内容。
第五步、readAsArrayBuffer会触发FileReader的onload事件,在事件回调中可以获取分片内容并进行后续处理。
所以loadNext的作用就是按照分片大小和序号,获取指定文件的一个分片Blob,然后用FileReader读取这个分片的ArrayBuffer内容。
关键代码:
function loadNext() {
const start = currentChunk * CHUNK_SIZE;
const end =
start + CHUNK_SIZE >= file.size ? file.size : start + CHUNK_SIZE;
fileReader.readAsArrayBuffer(blobSlice.call(file.file, start, end));
}
8、这段代码是FileReader的onload事件回调函数,作用是处理读取分片内容后进行MD5累加计算。
具体逻辑:
第一步、通过spark.append(e.target.result)将读取到的分片ArrayBuffer内容追加到spark中,进行MD5累加。
第二步、判断如果分片序号currentChunk还小于总分片数chunks,则说明还有分片未读:currentChunk自增,调用loadNext()加载下一分片。
第三步、否则,说明所有分片已读取完毕:通过spark、end()计算最终的MD5值md5,打印计算耗时,通过callback回调返回md5值。
第四步、callback函数会在外部接收到md5,判断文件是否重复并决定后续逻辑。
所以这段代码的作用是递归读取文件分片,累加计算MD5,最后返回MD5结果,完成了整个文件的MD5校验。通过分片加载的方式,避免了一次性加载整个大文件导致的性能问题,实现了高效的MD5计算。
关键代码:
fileReader.onload = function (e) {
spark.append(e.target.result);
if (currentChunk < chunks) {
currentChunk++;
loadNext();
} else {
let md5 = spark.end();
console.log(
`MD5计算完毕:${md5},耗时:${new Date().getTime() - startTime} ms.`
);
callback(md5);
}
};
fileReader.onerror = function () {
this.$message.error("文件读取错误");
file.cancel();
};
7.2.8、完整代码
<template>
<div class="home">
<uploader
ref="uploader"
:options="options"
:autoStart="false"
:file-status-text="fileStatusText"
@file-added="onFileAdded"
@file-success="onFileSuccess"
@file-error="onFileError"
@file-progress="onFileProgress"
class="uploader-example"
>
<uploader-drop>
<p>将文件拖放到此处以上传</p>
<uploader-btn>选择文件</uploader-btn>
</uploader-drop>
<uploader-files> </uploader-files>
</uploader>
<br />
</div>
</template>
<script>
import HelloWorld from '@/components/HelloWorld.vue'
import SparkMD5 from "spark-md5";
const CHUNK_SIZE = 50 * 1024 * 1024;
export default {
name: 'HomeView',
components: {
HelloWorld
},
data() {
return {
options: {
target: 'http://127.0.0.1:9090/file/upload',
testChunks: true,
uploadMethod: "post",
chunkSize: CHUNK_SIZE,
simultaneousUploads: 3,
checkChunkUploadedByResponse: (chunk, message) => {
let messageObj = JSON.parse(message);
let dataObj = messageObj.data;
if (dataObj.uploaded !== undefined) {
return dataObj.uploaded;
}
return (dataObj.uploadedChunks || []).indexOf(chunk.offset + 1) >= 0;
},
parseTimeRemaining: function (timeRemaining, parsedTimeRemaining) {
return parsedTimeRemaining
.replace(/\syears?/, "年")
.replace(/\days?/, "天")
.replace(/\shours?/, "小时")
.replace(/\sminutes?/, "分钟")
.replace(/\sseconds?/, "秒");
},
},
fileStatus: {
success: "上传成功",
error: "上传错误",
uploading: "正在上传",
paused: "停止上传",
waiting: "等待中",
},
uploadFileList: [],
};
},
methods: {
onFileAdded(file) {
this.uploadFileList.push(file);
// 2. 计算文件 MD5 并请求后台判断是否已上传,是则取消上传
this.getFileMD5(file, (md5) => {
if (md5 != "") {
// 修改文件唯一标识
file.uniqueIdentifier = md5;
// 恢复上传
file.resume();
}
});
},
onFileSuccess(rootFile, file, response, chunk) {
console.log("上传成功");
},
onFileError(rootFile, file, message, chunk) {
console.log("上传出错:" + message);
},
onFileProgress(rootFile, file, chunk) {
console.log(`当前进度:${Math.ceil(file._prevProgress * 100)}%`);
},
getFileMD5(file, callback) {
let spark = new SparkMD5.ArrayBuffer();
let fileReader = new FileReader();
let blobSlice =
File.prototype.slice ||
File.prototype.mozSlice ||
File.prototype.webkitSlice;
let currentChunk = 0;
let chunks = Math.ceil(file.size / CHUNK_SIZE);
let startTime = new Date().getTime();
file.pause();
loadNext();
fileReader.onload = function (e) {
spark.append(e.target.result);
if (currentChunk < chunks) {
currentChunk++;
loadNext();
} else {
let md5 = spark.end();
console.log(
`MD5计算完毕:${md5},耗时:${new Date().getTime() - startTime} ms.`
);
callback(md5);
}
};
fileReader.onerror = function () {
this.$message.error("文件读取错误");
file.cancel();
};
function loadNext() {
const start = currentChunk * CHUNK_SIZE;
const end =
start + CHUNK_SIZE >= file.size ? file.size : start + CHUNK_SIZE;
fileReader.readAsArrayBuffer(blobSlice.call(file.file, start, end));
}
},
fileStatusText(status) {
console.log(11111)
console.log(status)
if (status === "md5") {
return "校验MD5";
}
return this.fileStatus[status];
},
},
}
</script>
八、运行项目
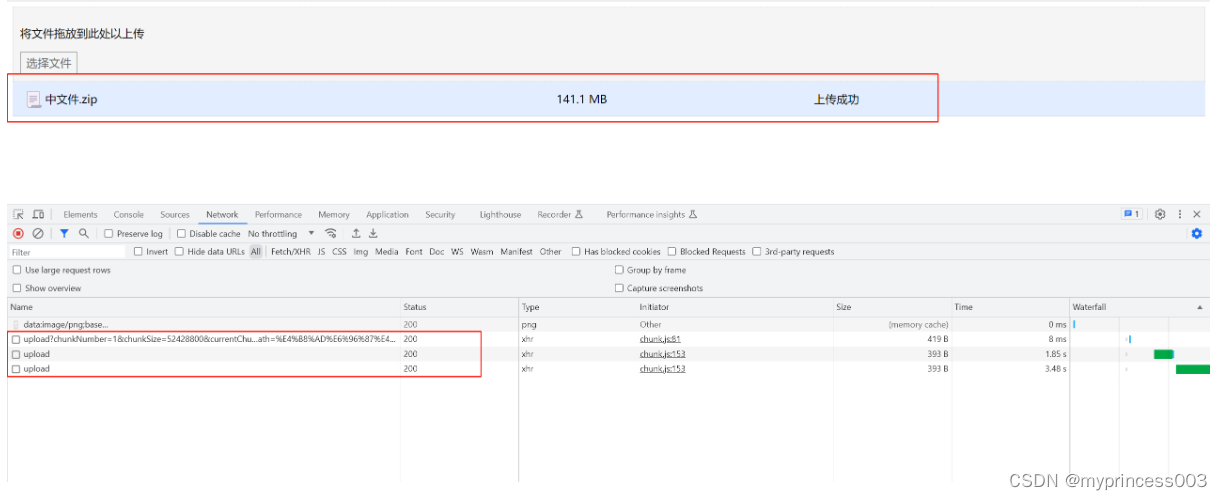
8.1、分片上传
我提前准备了一个大小为141.1MB的文件进行上传,默认切成了2片进行上传。
是数据库的写入的信息:
分片信息:

文件信息:

在这里大家有没有很奇怪,为什么141M的文件不会被切成3块,反而只被切成了2块,而且第2块的大小为91MB,下面我来详细讲解一下原因:
这是因为按理论来说141M的文件会分别切成50MB、50MB和41MB的三个分片文件,但是最后一个41MB不满足50MB,这个时候,切分算法会做优化,将第2块和第3块合并,减少切分次数,所以最终的切片情况是50MB和91MB。
8.2、断点续传
有的时候,可能会出现一些网络原因或者是客户自己想留着剩下的到明天再上传。
下次会继续保留上次的上传进度,直到上传成功为止!
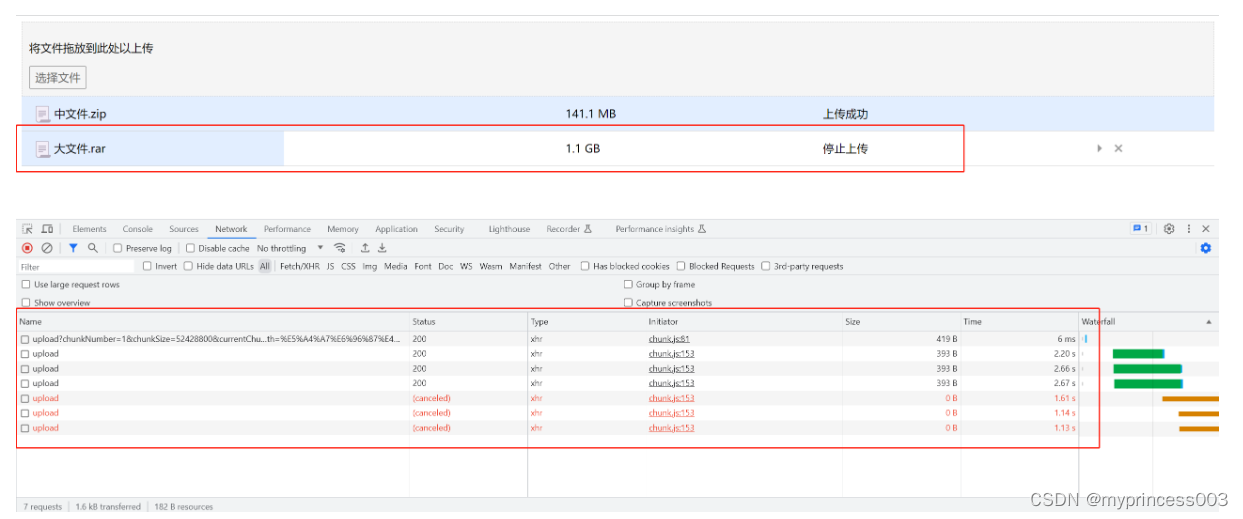
这是数据库的写入的信息:
分片信息:
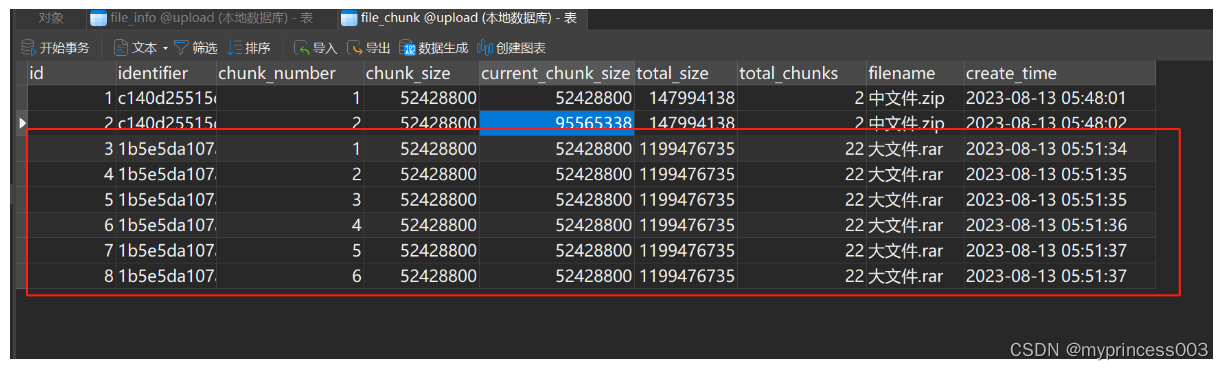
因为只上传了一部分分片信息,不过都会被数据库记录下来。
文件信息:

因为文件还没有上传完整,所以文件信息表不会存储此文件信息。
我们下次接着上次的进度继续上传。
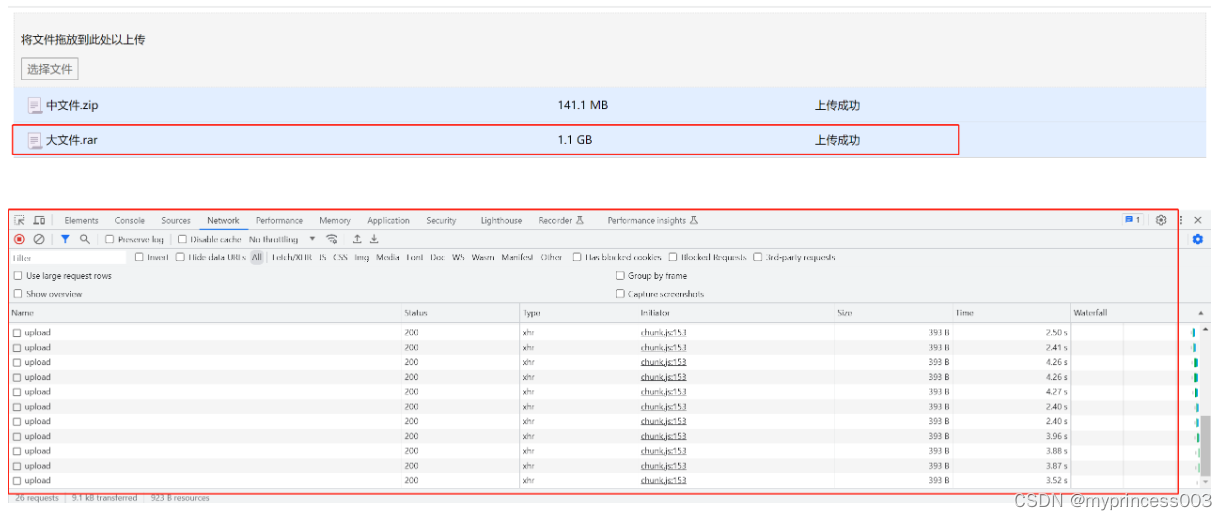
这是数据库写入的信息:
分片信息:
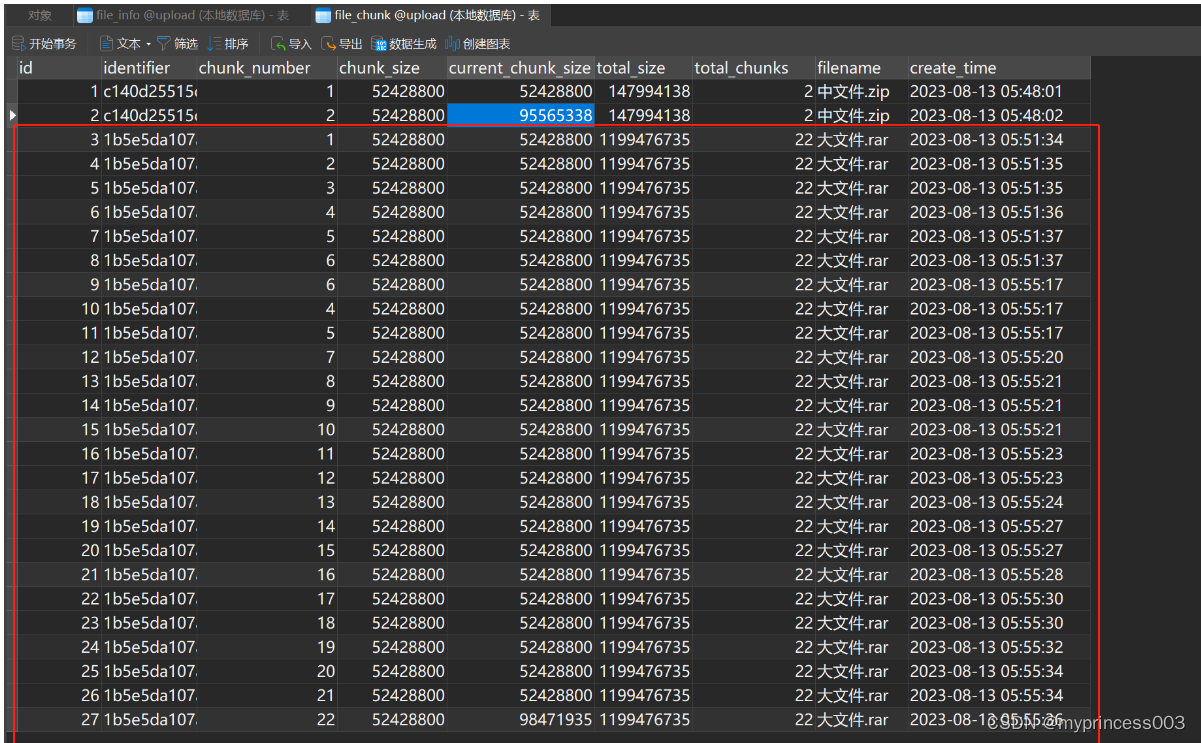
文件信息:

8.3、秒传
秒传就很简单了,我把刚才的大文件再次选择上传一次。
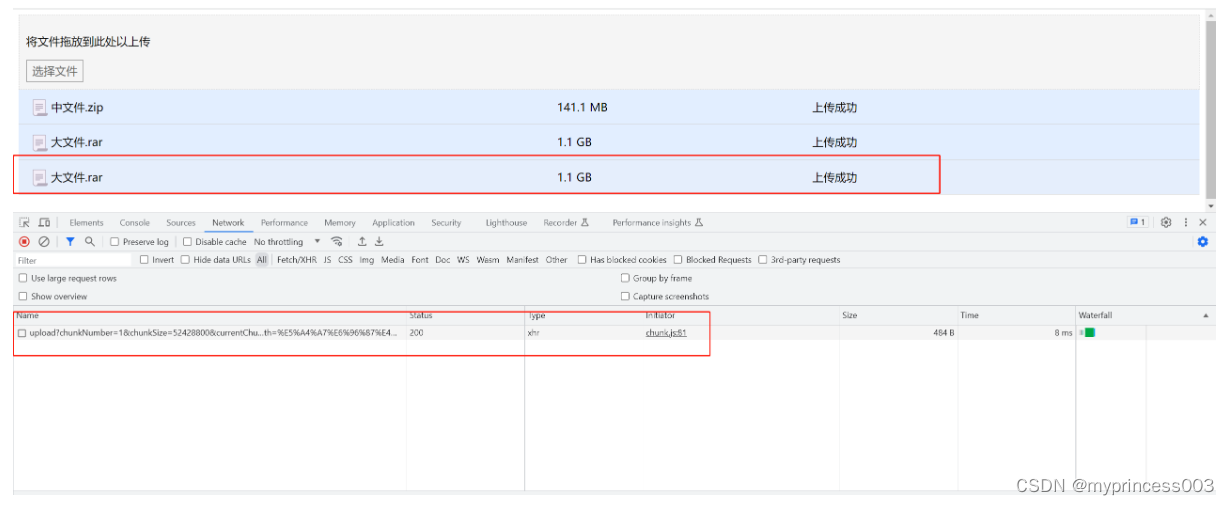
很明显,并没有进行切片,只调用了一次验证接口,从数据库根据MD5查询本文件的所有分片信息返回给前端,和前端的分片信息进行比对,检查到此文件已经完整上传过了,所以在1s内完成了上传!