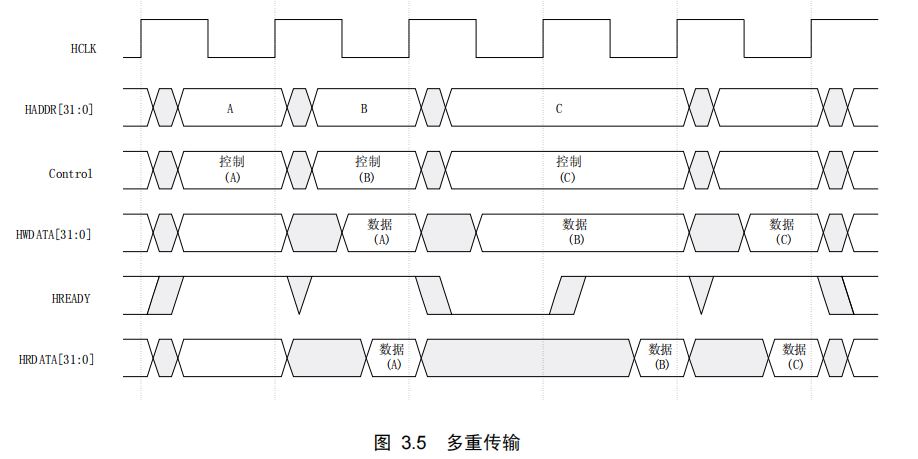
缓存预热
“
宕机
”
服务器启动后迅速宕机
问题排查
1.
请求数量较高
2.
主从之间数据吞吐量较大,数据同步操作频度较高
,
因为刚刚启动时,缓存中没有任何数据
解决方案
准备工作:
1.
日常例行统计数据访问记录,统计访问频度较高的热点数据
2.
将统计结果中的数据分类,根据级别,
redis
优先加载级别较高的热点数据
实施:
1.
使用脚本程序固定触发数据预热过程
2.
如果条件允许,使用了
CDN
(内容分发网络),效果会更好
******
CDN
的全称是
Content Delivery Network
,即内容分发网络。其基本思路是尽可能避开
互联网
上
有可能影响数据传输速度和稳定性的
瓶颈
和环节,使内容传输得更快、更稳定。通过在网络各处
放置
节点服务器
所构成的在现有的互联网基础之上的一层智能
虚拟网络
,
CDN
系统能够实时地根
据
网络流量
和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重
新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决
Internet
网络拥挤
的状况,提高用户访问网站的响应速度
******
总结
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查
询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据
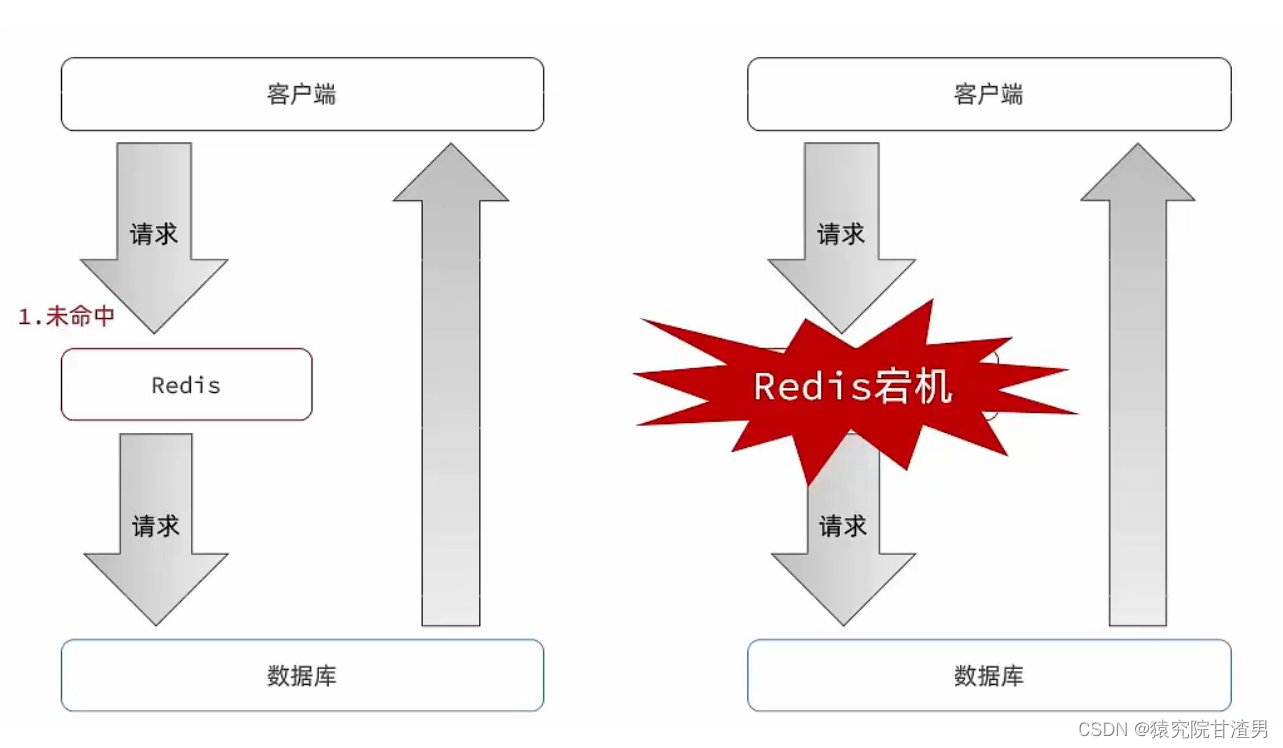
缓存雪崩
缓存雪崩是指在同一时段大量的缓存
key
同时失效或者
Redis
服务宕机,导致大量请求到达数据库带来 巨大压力。
解决方案:
给不同的
Key
的
TTL
添加随机值
利用
Redis
集群提高服务的可用性
给缓存业务添加降级限流策略
给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点
Key
问题,就是一个被高并发访问并且缓存重建业务较复杂的
key
突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
互斥锁
逻辑过期
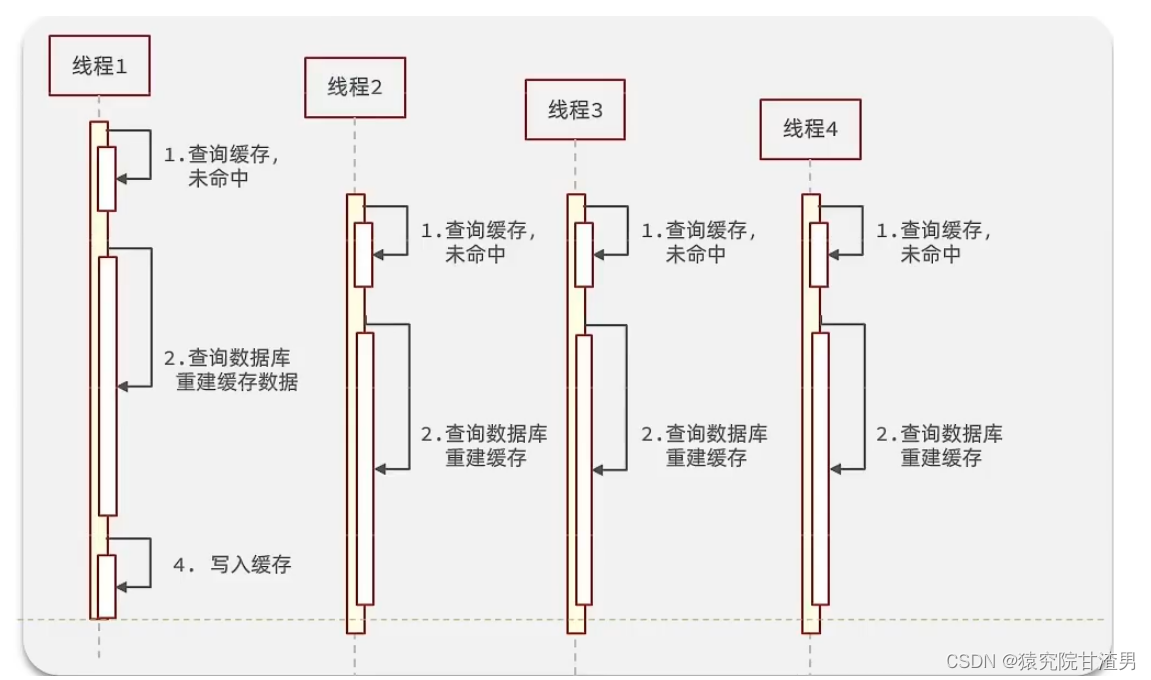
逻辑分析:假设线程
1
在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1
走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程
1
没有走完的时候,后续的线程2
,线程
3
,线程
4
同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大
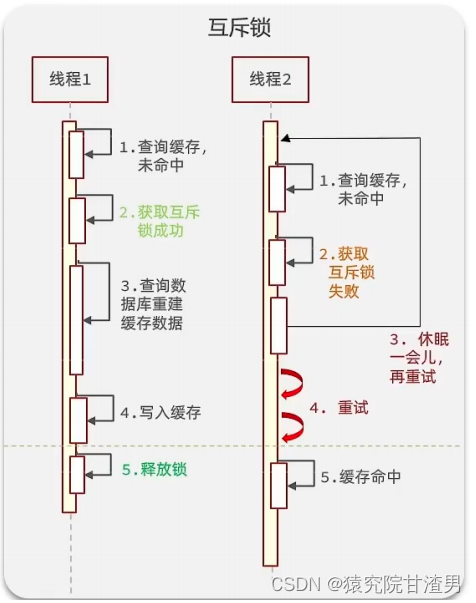
解决方案一、使用锁来解决:
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用tryLock方法
+ double check
来解决这样的问题。
假设现在线程
1
过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程
1
就会一个人 去执行逻辑,假设现在线程2
过来,线程
2
在执行过程中,并没有获得到锁,那么线程
2
就可以进行到休眠,直到线程1
把锁释放后,线程
2
获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。
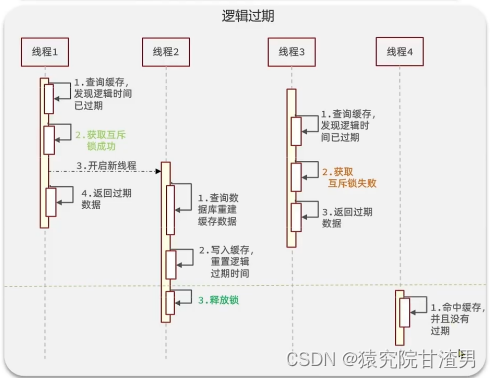
解决方案二、逻辑过期方案
方案分析:我们之所以会出现这个缓存击穿问题,主要原因是在于我们对
key
设置了过期时间,假设我 们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们 内存了吗,我们可以采用逻辑过期方案。我们把过期时间设置在
redis
的
value
中,注意:这个过期时间并不会直接作用于
redis
,而是我们后续 通过逻辑去处理。假设线程1
去查询缓存,然后从
value
中判断出来当前的数据已经过期了,此时线程
1 去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1
直接进行返回,假设现在线程
3
过来访问,由于线程线程2
持有着锁,所以线程
3
无法获得锁,线程
3
也直接返回数据,只有等到新开的线程
2
把重建数据构建完后,其他线程才能走返回正确的数据。这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
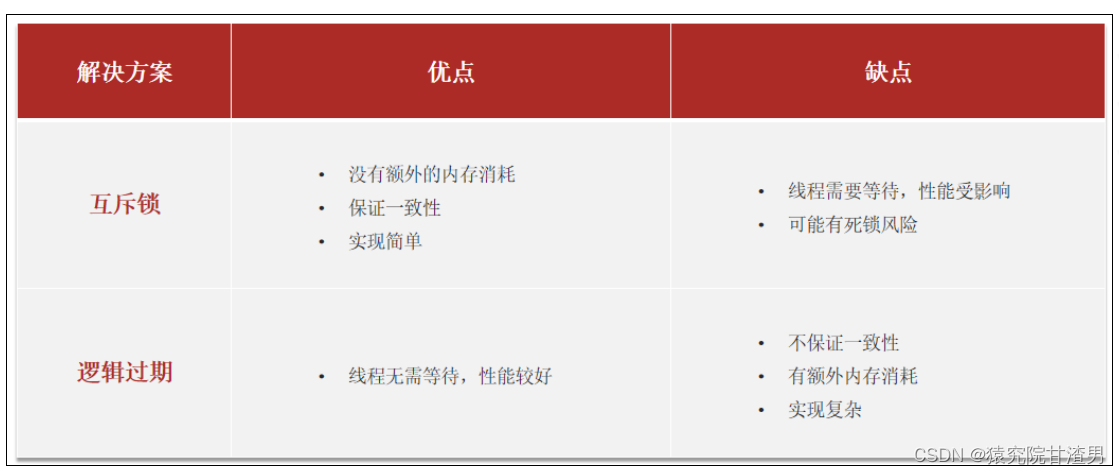
互斥锁方案:
由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到影响
逻辑过期方案:
线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的数据,且实现起来麻烦
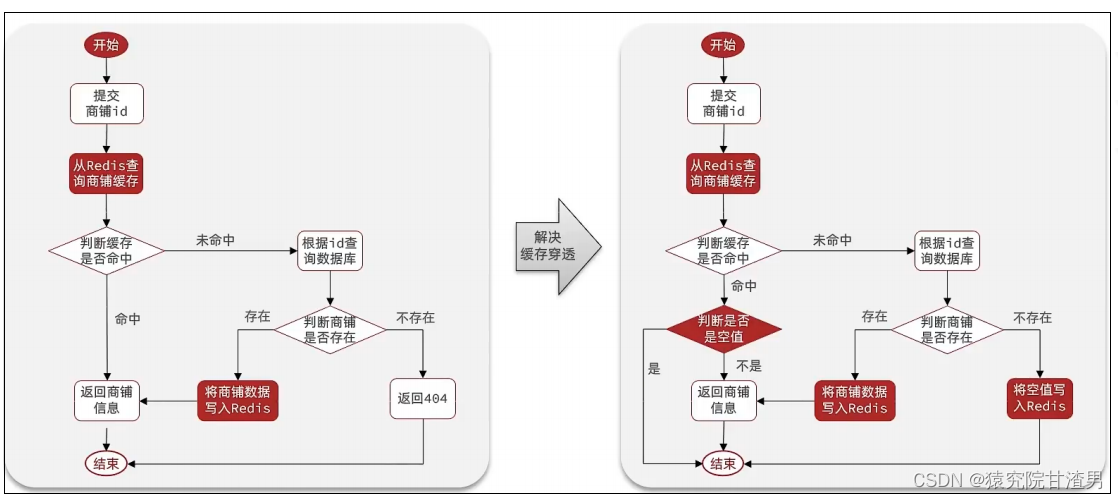
缓存穿透
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
缓存空对象
优点:实现简单,维护方便
缺点:额外的内存消耗可能造成短期的不一致
布隆过滤
优点:内存占用较少,没有多余
key
缺点:实现复杂存在误判可能
缓存空对象思路分析:
当我们客户端访问不存在的数据时,先请求
redis
,但是此时
redis
中没有数据, 此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis
这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis
中也能找到这个数据就不会进入到缓存了
布隆过滤:
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时
redis
中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis
中,假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突