网络原理
本文主要是介绍TCP/IP协议这里面的核心内容,还是很重要的
TCP/IP协议的层级
应用层
传输的数据如何去使用
传输层
起点和终点的传输
网络层
中间传输过程中的路径规划
数据链路层
相邻节点的传输
物理层
这是最底层的,相当于基础设施
应用层
不同的应用程序,涉及到不同的应用层协议,很多时候都是自定义应用层协议
如何自定义应用层协议
- 考虑在客户端服务器之间要传输哪些数据?[根据需求]
- 考虑信息/数据按照什么格式组织[也是根据需求]
举一个具体的例子点外卖
-
明确传输的信息, 请求里面有什么,响应里面有什么
请求: 用户的位置 用户的偏好
响应: 商家的列表需要包含多个商家的信息,每个商家要包含名称 图片 评分 距离
-
明确数据的格式
网上传输的数据的本质都是bit流,也就是一堆二进制位,不同程序之间的传输格式也是不一样的
但是,自定义应用层协议实在是太灵活了,这并不是一件好事
一些特定的数据传输格式
使用特定的一些数据传输格式,基于这些常用的格式来传输数据, 就会更加通用,更方便
XML
-
HTTP是应用层中最常用最重要的协议(后面会重点讲解)
-
XML是比较典型的数据组织格式,比较经典古老
XML是通过标签的形式来组织 键值对 数据的
类似于这种格式:

在标签里面的名字就是key, 标签里面的内容是value
XML 与 HTML的区别:
虽然HTML也是标签化的格式,但是xml的标签名是自定义的
html的标签名是已经约定好的,不能自定义的
XML的缺点:
- 不美观
- 数据一旦多了,写起来就会很难受
- 数据传输要消耗网络带宽,由于XML含有大量的标签,就导致了网络带宽占用变高了
JSON
JSON是当前最流行的数据组织格式,相当于是XML的替代品
JSON首先是一个{},{}里面包括多组键值对,键值对之间使用分号分隔
键和值之间是用 冒号: 进行分隔
键只能是字符串类型
值可以是字符串 数字 数组 JSON(嵌套)
一个例子:

JSON并没有解决占用较多网络带宽的问题,但是代码量相比于XML减少了,可读性更强了
所以,开发效率就提高了,还是很好的
protobuffer
前面说的XML和JSON的网络带宽占用都比较高,运行效率比较低,也有一些数据组织格式能高效组织数据,最典型的就是protobuffer(谷歌研发出来的)
protobuffer是二进制的格式,所以不方便看,但是这样子的传输效率就会有明显的提升,所以protobuffer适合对运行效率要求很高的场景使用
传输层
传输层关注的是起点和终点
在传输层中最主要的协议是UDP 和 TCP
UDP: 无连接 不可靠传输 面向数据报 全双工
TCP: 有连接 可靠传输 面向字节流 全双工
学习协议主要学习的就是协议的报文格式
UDP
UDP的报文格式
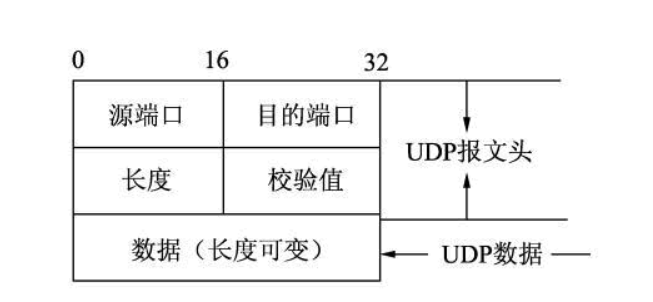
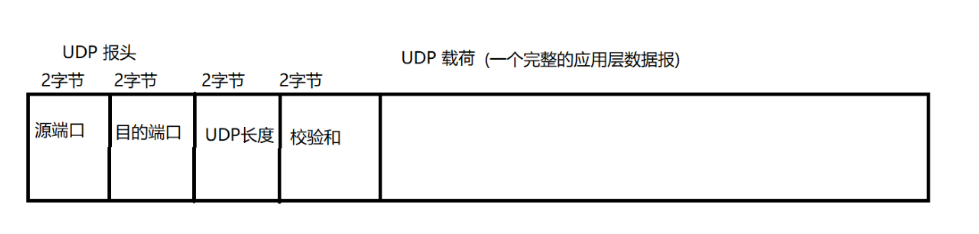
UDP报头是很简单的,里面只有4个字段
在传输层中,表示端口号的长度就是2个字节
也就是16个bit位,所以就是2^16次方 ,也就说明了端口号是0-65535,但是一般我们都是使用1024-65535 的端口号
2个字节时0-65535 换算成KB,就是0-64KB
最大的大小是64KB,但是随着时代的发展,现在64KB已经是很短的长度了
所以,要是使用UDP传输一个比较大的数据,就要考虑进行拆包,将一个大的数据报拆分成多个小的数据报
还有一种方法就是使用TCP,因为TCP是面向字节流的,不限制包的大小
校验和的作用是检查数据是否出错了
在网络传输过程中, 有时候会受到外界因素的干扰,导致数据发生错误,所以就需要接收方收到数据之后,验证这个数据是否正确
校验和可以看传输的数据的大小是否正确来验证
更好的校验和算法是能够与数据内容相关的,接收到不同的内容,就会产生不同的校验和
UDP的校验和使用的是CRC算法(循环冗余校验)
就是将UDP报文中的每个字节都进行累加,将 加和 放到一个2字节的数组中,不用管加的时候是否会溢出
发送方会先计算一下校验和,接收方收到之后也会计算一下校验和,要是值相等,说明数据正确,要是不相等,说明数据出错了
要是多个数据变了,但是正好值不变,这种情况是极少见的,一般也就忽略这种情况了

![[附源码]Python计算机毕业设计SSM基于Java的租房系统(程序+LW)](https://img-blog.csdnimg.cn/6a17cba39e4740ababaa04c96c8ace60.png)