-----------------------------------------------------------------------------------------------------------------------------
由于本人主修嵌入式方向最多使用的就是C语言,由于物联网这个专业的特殊性,javaweb没少
写,所以java也用了一些,这次我使用了目前最火的python语言来实现我的大数据课设对我来说
是一次挑战。还好最后有惊无险的在规定时间内完成了。前端和数据分析这里还有一些问题没有
真正解决,数据用的也是虚拟数据,后面如果有机会继续深入学习大数据知识的话我会将这里完
善,并且随着嵌入式学习的深入,数据采集这里预计明年会将它完善。莫名其妙没保存上希望官方
可以修复一下这个bug,太痛了,几乎5/6都是重写的!!!!!!!!!!!!
-----------------------------------------------------------------------------------------------------------------------------
目录
一、环境配置
python包
Hbase
二、创建数据库
三、模拟人的流动
四、数据处理
五、前端程序
一、环境配置
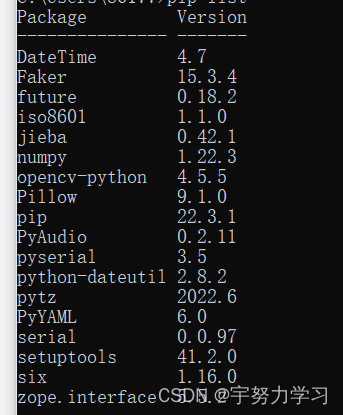
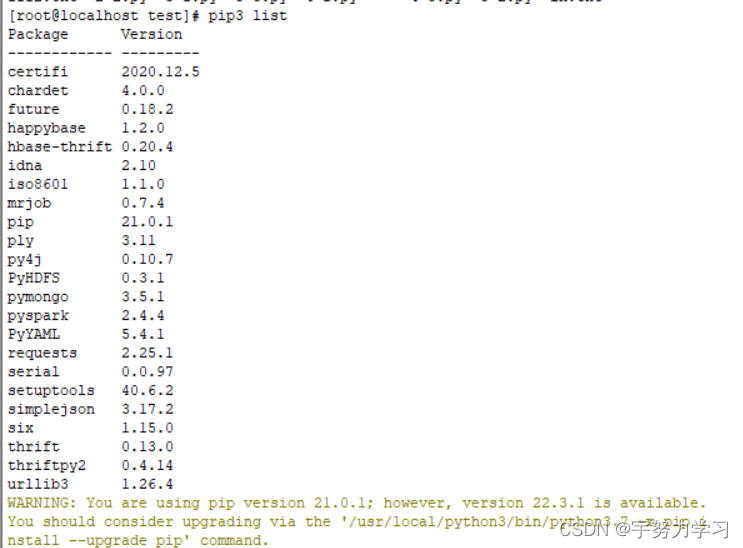
python包
pip install package
package:
Hbase
HBase——安装配置与shell操作_Devin01213的博客-CSDN博客
在/etc/profile中添加hbase的环境
之后试一下hbase shell
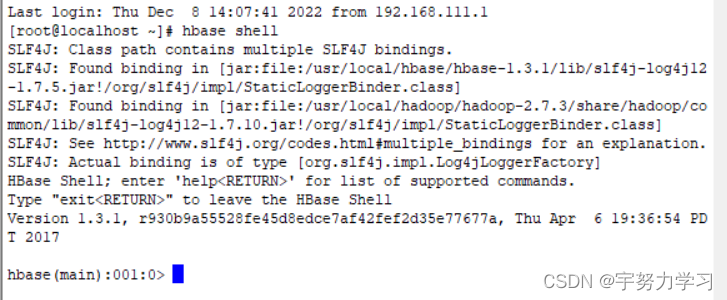
如果不好使多半是多开窗口了,这样只有配置的那个窗口和以后新建的窗口好使。
二、创建数据库
import happybase
#确定链接的ip和项目名称
connection = happybase.Connection('localhost', table_prefix='mybigdata')
connection.open()
print(connection.tables())
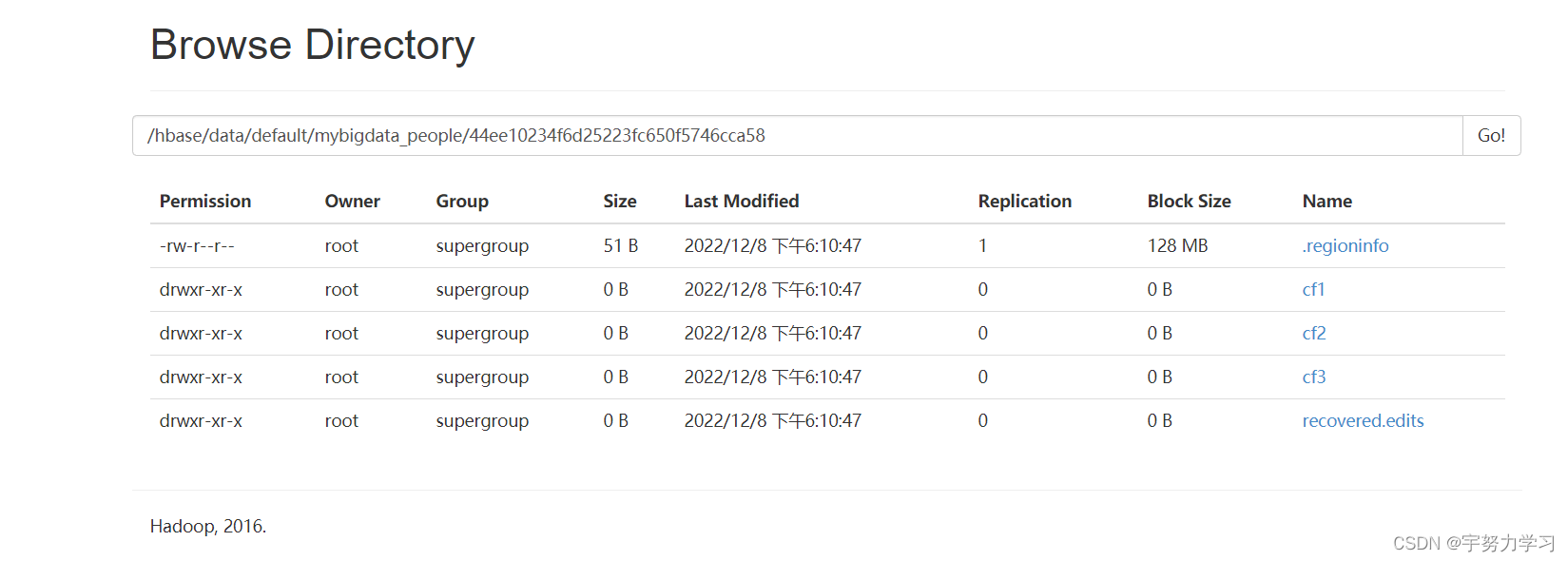
connection.create_table(
'people',
{
'cf1': dict(max_versions=10),#最大生命周期是10
'cf2': dict(max_versions=5, block_cache_enabled=False),#无块缓存
'cf3': dict(), # use defaults
} )
table = connection.table('people')
print(table)
将csv的数据读取并存入数据库:
import happybase
import csv
from faker import Faker
import pandas
import numpy as np
fake = Faker(locale='zh_CN') # 设置中文
my_matrix = pandas.read_csv('test.csv')#,header=0,index_col=0)
row = np.array(my_matrix)
#connection = happybase.Connection('localhost', table_prefix='mybigdata')
connection = happybase.Connection('localhost')
connection.open()
print(connection.tables())
def data1(a):
return row[a][0]
def data2(a):
return str(row[a][1])
def data3(a):
return str(row[a][2])
table = connection.table('people')
print(table) #<happybase.table.Table name=b'lrx_test'>
# 获取表实例,返回一个 happybase.table.Table 对象(返回表名)
table = happybase.Table('people',connection)
print(table) #<happybase.table.Table name='lrx_test'>
# 插入数据,无返回值 ----在 row1 行,data:1 列插入值 value1
for i in range(2500):
with table.batch() as bat:
bat.put(data1(i), {'cf1:name': 'name', 'cf1:uid': data1(i), 'cf1:address': '0001', 'cf1:number': '15160216049'})
bat.put(data1(i), {'cf3:locus': data2(i),'cf3:time': data3(i)})
bat.put(data1(i), {'cf2:danger': '3', 'cf2:chemod': '0', 'cf2:48': '3'})
三、模拟人的流动
这里我选择使用faker包来随机生成
人员流动:
import csv
from faker import Faker
fake = Faker(locale='zh_CN') # 设置中文
def uid():
return fake.ssn(min_age=0, max_age=100)
def locus():
return fake.password(length=4,special_chars=False, digits=True, upper_case=False, lower_case=False)
def time():
return fake.password(length=4,special_chars=False, digits=True, upper_case=False, lower_case=False)
headers = ['uid','locus','time']
'''
rows = [('202001','张三','98'),
('202002','李四','95'),
('202003','王五','92')]
'''
with open('test.csv','w',encoding='utf8',newline='') as f :
writer = csv.writer(f)
writer.writerow(headers)
for i in range(50):
sid = uid()
for i in range(50):
writer.writerows([(sid,locus()[0:3],time()[0:3])])
个人信息的生成:
import csv
from faker import Faker
fake = Faker(locale='zh_CN') # 设置中文
def name():# 随机名字
return fake.name()
def uid():
return fake.ssn(min_age=0, max_age=100)
def address():
return fake.address()
def phone():
return fake.phone_number()
headers = ['uid','name','address','number']
with open('test1.csv','w',encoding='utf8',newline='') as f :
writer = csv.writer(f)
writer.writerow(headers)
for i in range(50):
sid = uid()
writer.writerows([(sid,name(),address(),phone())])
四、数据处理
使用socket进行Windows到虚拟机的数据传输
服务器:
from faker import Faker
import json
import datetime
import socketserver #用于进行都并发,即服务端能同时接收多个客户端的链接通信
import csv
import pandas
import numpy as np
import serial
import time
fake = Faker(locale='zh_CN') # 设置中文
IPSERVER = "192.168.3.5"
PORTSERVER = 8002
my_matrix = pandas.read_csv('test.csv')#,header=0,index_col=0)
row = np.array(my_matrix)
#18+3+3
def recv_csv(a):
#time.sleep(2)
return (str(row[a][0])+'+'+str(row[a][1])+'+'+str(row[a][2])+'\n')
def data1(a):
return str(row[a][0])
def data2(a):
return str(row[a][1])
def data3(a):
return str(row[a][2])
class ETLserver(socketserver.BaseRequestHandler): #通讯
def handle(self): #相当于conn,client_addr=phone.accept(),必须定义一个handle函数
print('========>',self)
print(self.request) #相当于conn
print(self.client_address) #相当于client_addr
a=-1
while True: #通讯循环
a=a+1
data =recv_csv(a)#tcp是基于数据流的,收发的消息不能为空,
if data != b'':
print("receive : ",data)
if str(data).find('+') != -1:
#uid,sid, hum = str(data).split('+')#拆分数据,也可以放到spark中处理
print(data)
self.request.send(data.encode())#重新编码!!!
if __name__ == '__main__': #只在本脚本中执行
#serial = serial.Serial('COM10', 115200, timeout=500) # /dev/ttyUSB0
ip_port =(IPSERVER,PORTSERVER)
obj =socketserver.ThreadingTCPServer(ip_port,ETLserver) #通过tcp线程的实例化对象
obj.serve_forever() #有一个循环,处于链接循环,相当于phone.listen(5),同时会执行handle方法
客户端:
import os
import sys
import json
os.environ["PYSPARE_PYTHON"]="/usr/local/bin/python3"
os.environ["PYSPARE_DRIVER_PYTHON"]="/usr/local/bin/python3"
try:
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
print ("Successfully imported Spark Modules")
except ImportError as e:
print ("Can not import Spark Modules", e)
sys.exit(1)
conf = SparkConf().setAppName('spark-streaming').setMaster('local[2]') #连接spark,一定要加载多核,单核会报错
sc = SparkContext(conf = conf) ##生成SparkContext 对象
ssc = StreamingContext(sc,2)
lines = ssc.socketTextStream("192.168.3.5", 8002)
#rdd = lines.flatMap(lambda x:x.split("+")).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
lines.pprint()###这里可以加一些处理过程,如数据库存储,格式变换
#rdduid = lines.map(lambda x:{'id':x.split("+")[0],'locus':x.split("+")[1],'time':x.split("+")[2]}).pprint()
rdduid = lines.map(lambda x:{'uid':x.split("+")[0],'locus':x.split("+")[1],'time':x.split("+")[2]})
ssc.start() # Start the computation
ssc.awaitTermination() #
五、前端程序
由于时间来不及了,这里使用python写了一个死循环当前端:
import happybase
import csv
from faker import Faker
import pandas
import numpy as np
fake = Faker(locale='zh_CN') # 设置中文
my_matrix = pandas.read_csv('test.csv')#,header=0,index_col=0)
row = np.array(my_matrix)
#connection = happybase.Connection('localhost', table_prefix='mybigdata')
connection = happybase.Connection('localhost')
connection.open()
print(connection.tables())
def data1(a):
return row[a][0]
def data2(a):
return str(row[a][1])
def data3(a):
return str(row[a][2])
table = connection.table('people')
print(table) #<happybase.table.Table name=b'lrx_test'>
# 获取表实例,返回一个 happybase.table.Table 对象(返回表名)
table = happybase.Table('people',connection)
n = 1
print(table) #<happybase.table.Table name='lrx_test'>
while (n == 1):
uid = input("input uid:")
# 通过指定列族中的列来检索数据
row = table.row(uid, columns=['cf1:name', 'cf1:uid','cf1:address','cf1:number','cf2:danger','cf2:48'])
print (row) #[b'value1', b'value1']
n = int(input("input1/0:"))
上面程序是模拟读取个人信息下面程序是模拟行程轨迹
import happybase
import pandas
import numpy as np
#my_matrix = pandas.read_csv('test.csv')#,header=0,index_col=0)
#row = np.array(my_matrix)
#connection = happybase.Connection('localhost', table_prefix='mybigdata')
connection = happybase.Connection('localhost')
connection.open()
print(connection.tables())
table = connection.table('people')
print(table) #<happybase.table.Table name=b'lrx_test'>
# 获取表实例,返回一个 happybase.table.Table 对象(返回表名)
table = happybase.Table('people',connection)
n = 1
print(table) #<happybase.table.Table name='lrx_test'>
while (n == 1):
uid = input("input uid:")
# 通过指定列族中的列来检索数据
locus = table.cells(row = uid, column='cf3:locus')
print ("locus:"+str(locus))
time = table.cells(row = uid, column='cf3:time')
print ("time:"+str(time))
n = int(input("input1/0:"))
有很多需要继续完善的点,这个主意得到了老师们的一致好评,所以我会继续完善它,希望有一天真正的面向全国人民的线上医疗程序可以走进我们的手机。为我们的生活提供便利!!!!!!

![[附源码]Python计算机毕业设计SSM基于Java的租房系统(程序+LW)](https://img-blog.csdnimg.cn/6a17cba39e4740ababaa04c96c8ace60.png)