Byzer-Notebook 是专门为 SQL 而研发的一款 Web Notebook。他的第一公民是 SQL,而 Jupyter 则是是以 Python 为第一公民的。
随着 Byzer 引擎对大模型能力的支持日渐完善, Byzer-Notebook 也在不自觉中变得更加强大。我和小伙伴在聊天的过程中才发现他已经具备了如此强的能力。
为了节省大家时间,我们这里把文后涉及到的部分,提前做个总结,帮助您判断是不是要继续阅读下去。
在接下来的内容,我们描述如何在 Byzer-Notebook 中:
使用SQL加载市面主流数据源
对加载的数据进行混算
对SQL不熟悉,可以在Notebook中自己启动一个大模型,然后作为copilot使用
在 SQL 中可以调用大模型对数据做分析
对最后的数据集使用 YAML 描述来做可视化生成
案例背景
今天假设我们有两个 csv 文件,我们需要加载这两个文件,并且做join,拼成一张完整的表,最后简单做个过滤,绘制一个可视化动图,并且使用大模型解读这个数据。
整个过程我们全部会使用 SQL 在 Byzer Notebook中完成。
Byzer Notebook 拥有业界一流的代码提示能力,所以你不要担心里面涉及到一些 SQL 扩展语法。
实现流程
首先是加载 csv 文件, Byzer 支持类似的语法加载市面上几乎所有主流数据源,诸如对象存储,MySQL/Oracle/DB2 等各种关系型数据库数据库,Hadoop文件系统等等。
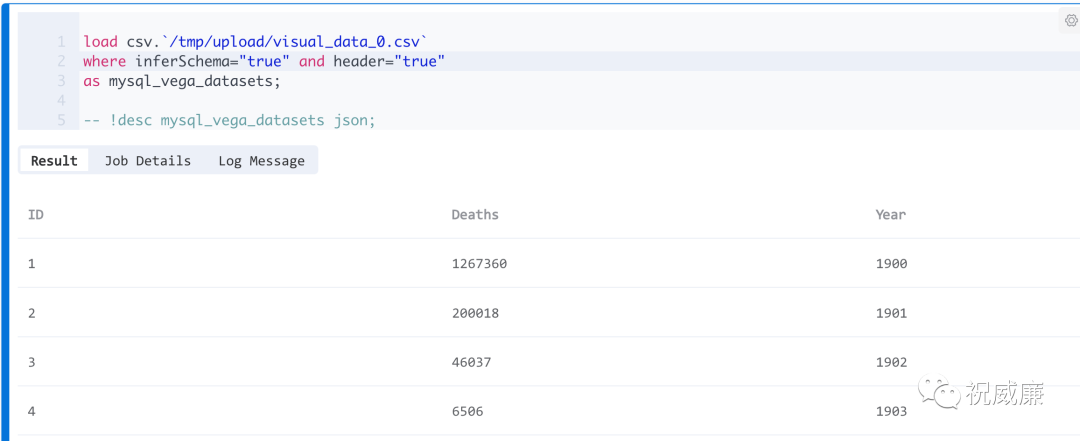
代码如下,执行完后可以点击运行查看csv文件数据:
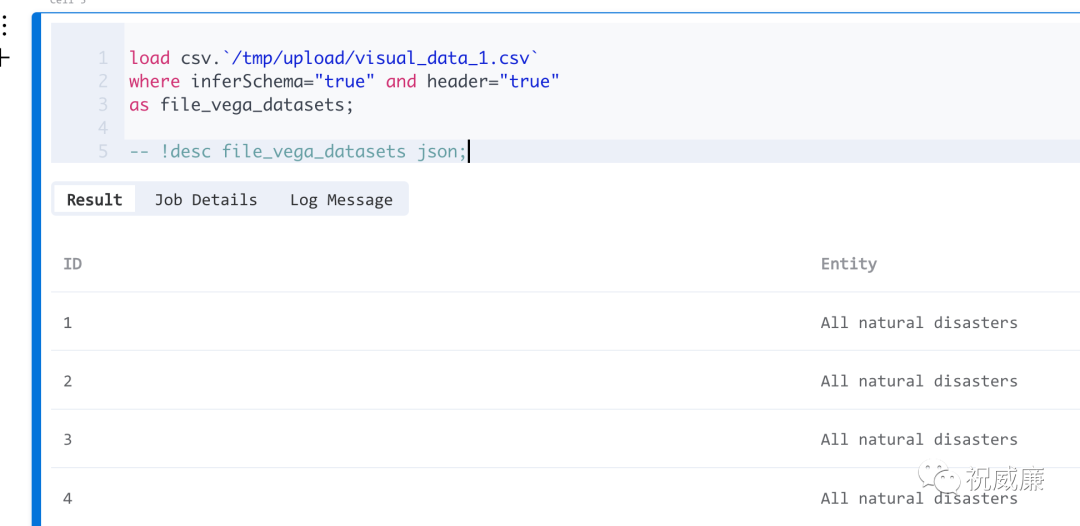
按相同方式加载第二个文件:
现在,我们想把两个表按 ID字段拼接成一个表,但是我对 SQL 不是很熟悉,不怕,我们在 Byzer Notebook中几乎可以部署所有主流开源模型和商业Saas模型。我最近用 Llama比较多,那我就启动一个 Llama 30B 的模型吧。只需要一条命令就可以完成这件事:
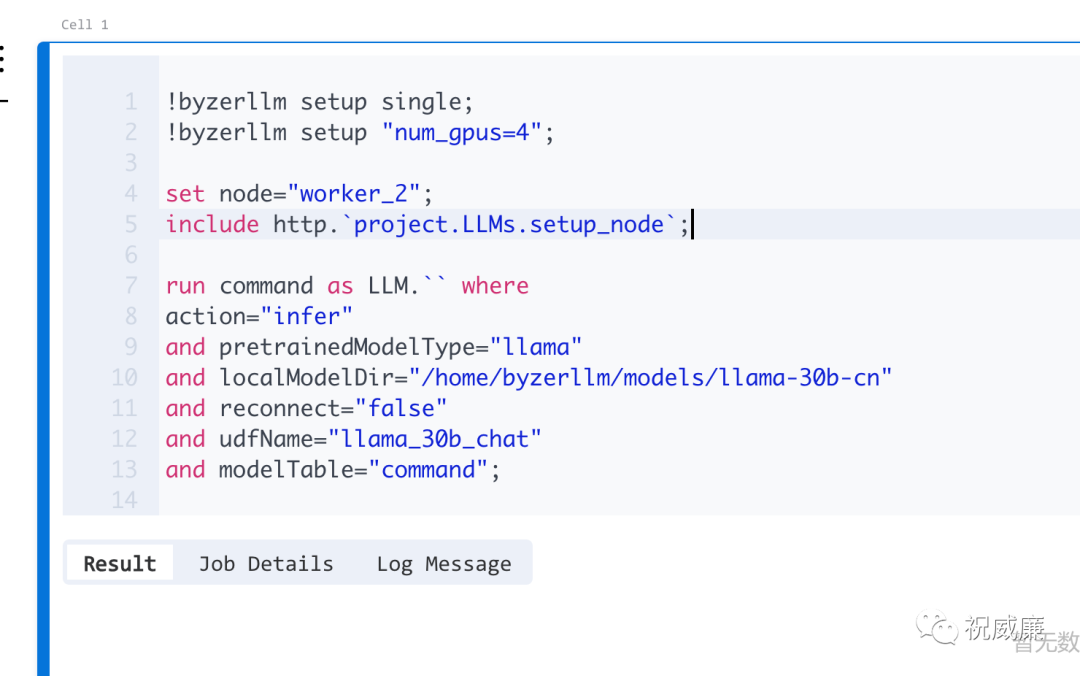
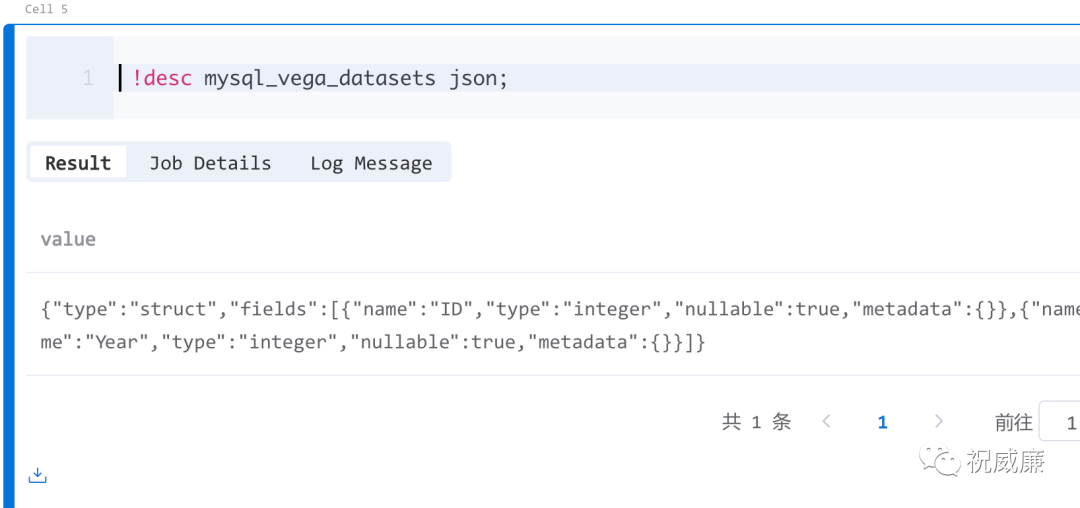
指定下用多少个 GPU, 模型路径在哪即可。为了让大模型助手给我们生成靠谱点的SQL ,我们需要两张表的schema, 获取schema 在 Byzer 中很简单,用 !desc 命令即可:
现在,我们可以问下我们刚才启动的大模型,你可以这么问:
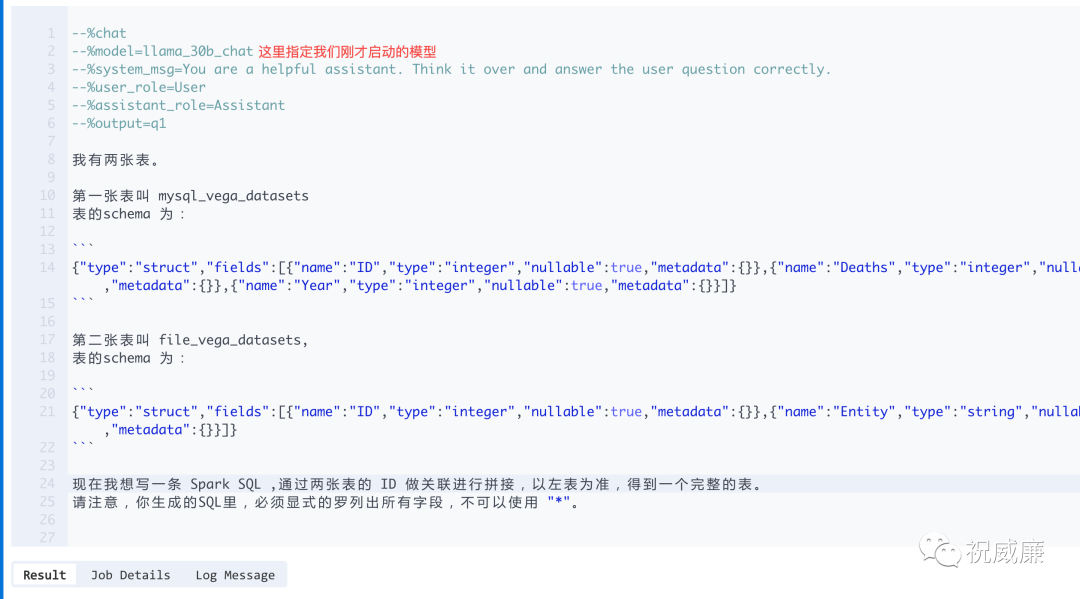
然后他会这样回复你:
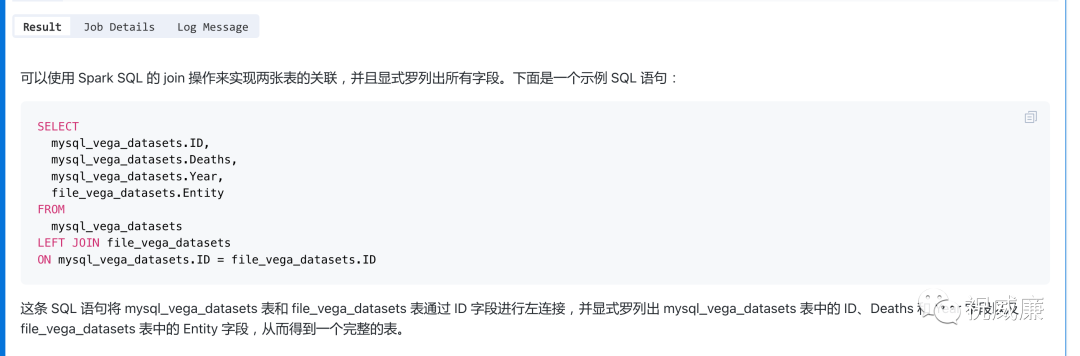
把这条SQL语句拷贝出来,然后加一个 as 表名,执行下:
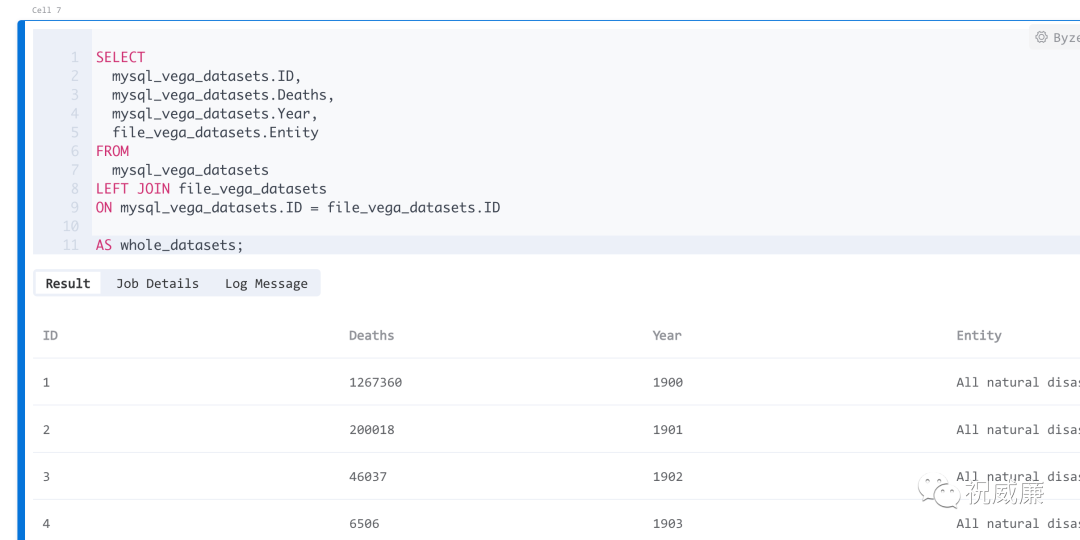
可以看到,数据拼接没啥问题。
现在我们希望使用大模型对这个数据集进行分析,第一步是要把数据集转化成json格式的文本,然后再给到大模型,假设我也不太会,但是我知道第一步是要把每一条记录里多个字段变成一个字段,所以我这么问大模型:
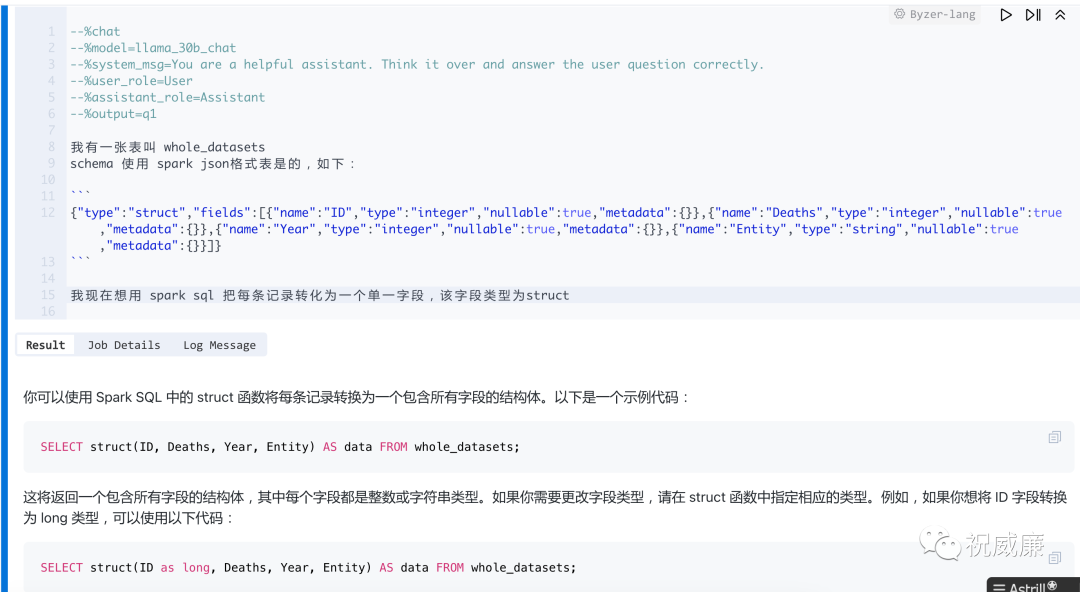
很棒,接着我再追问一句,是不是可以几万条记录合并成一条呀,我知道有个 collect_list 方法,但是我知道具体怎么用,那么可以继续追问:
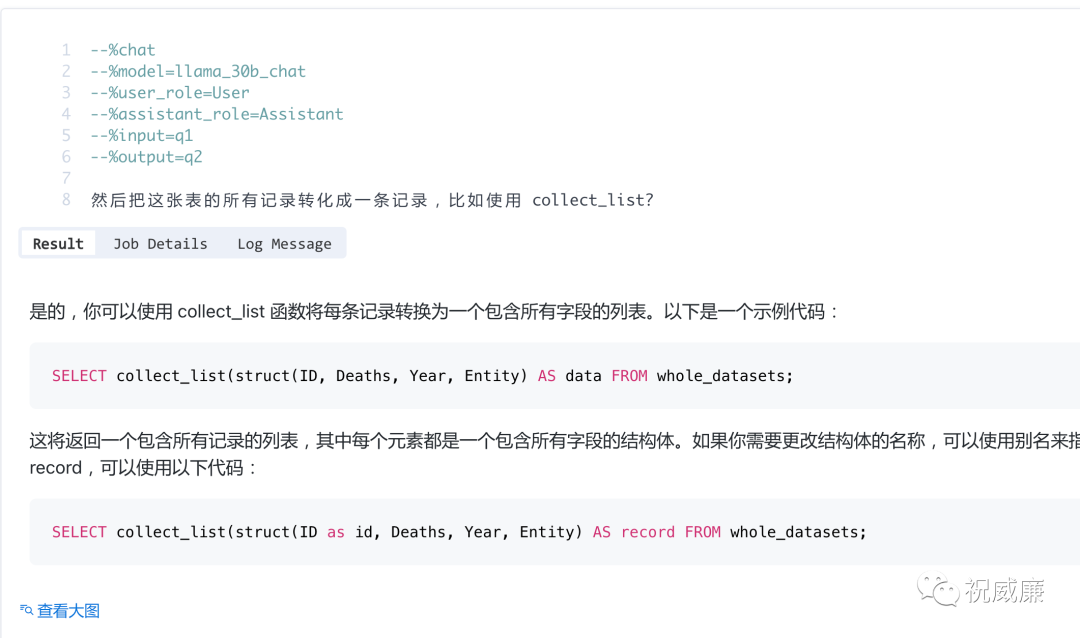
简单改造实际执行下:
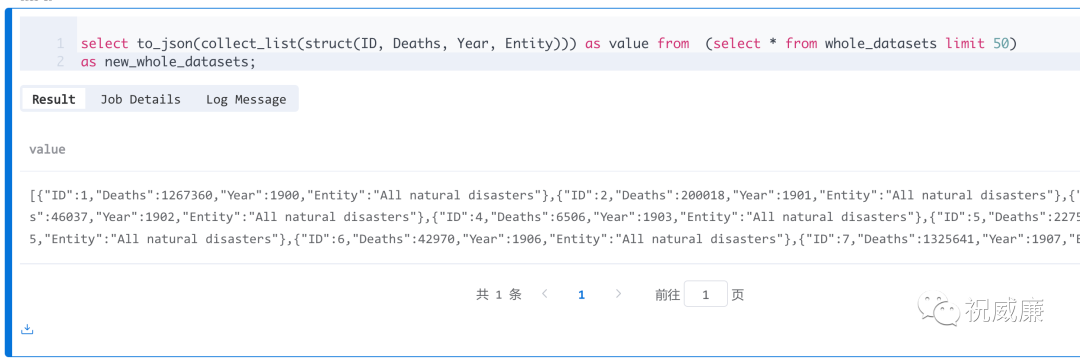
确实是work的。
恩,那现在开始对这个json字符串做个解读吧:
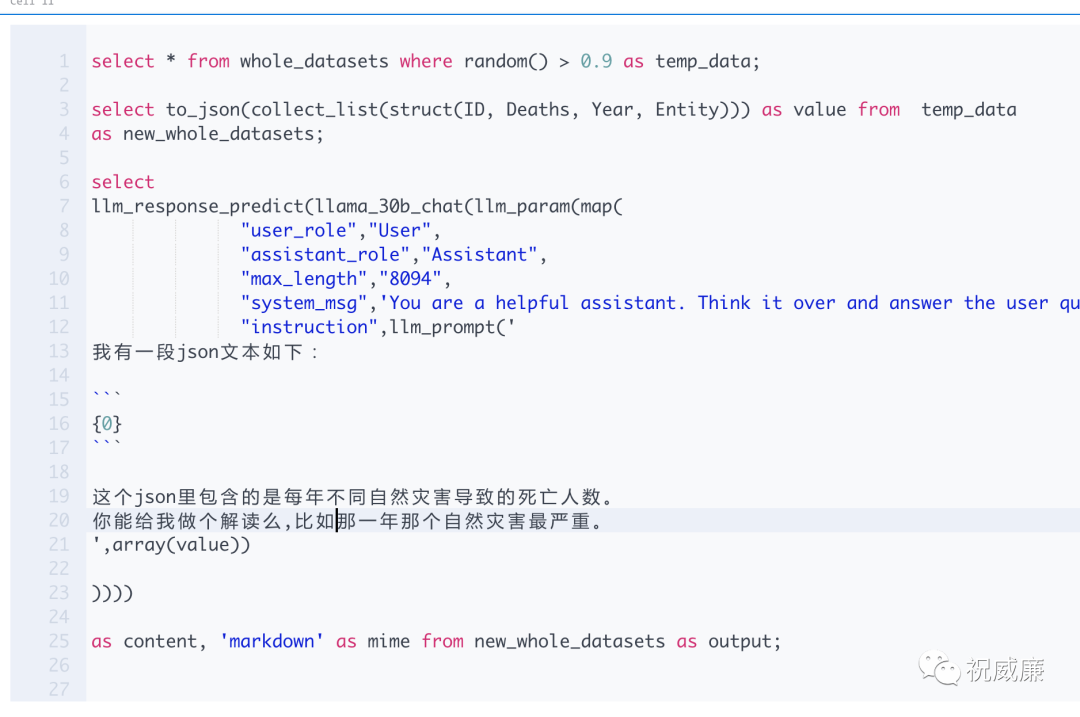
这里有一些新函数,具体用法要参考下 Byzer 文档了,后续我们提供一个知道 Byzer 语言的大模型(经过我们微调),或者我们会知识库的方式提供对 Byzer 特有函数的一些解答。现在我们假设你辛苦参考文档写下了上面的那段SQL代码。
最后模型给我的回答出人意料,尼玛,丢了一个python 代码让我自己统计:
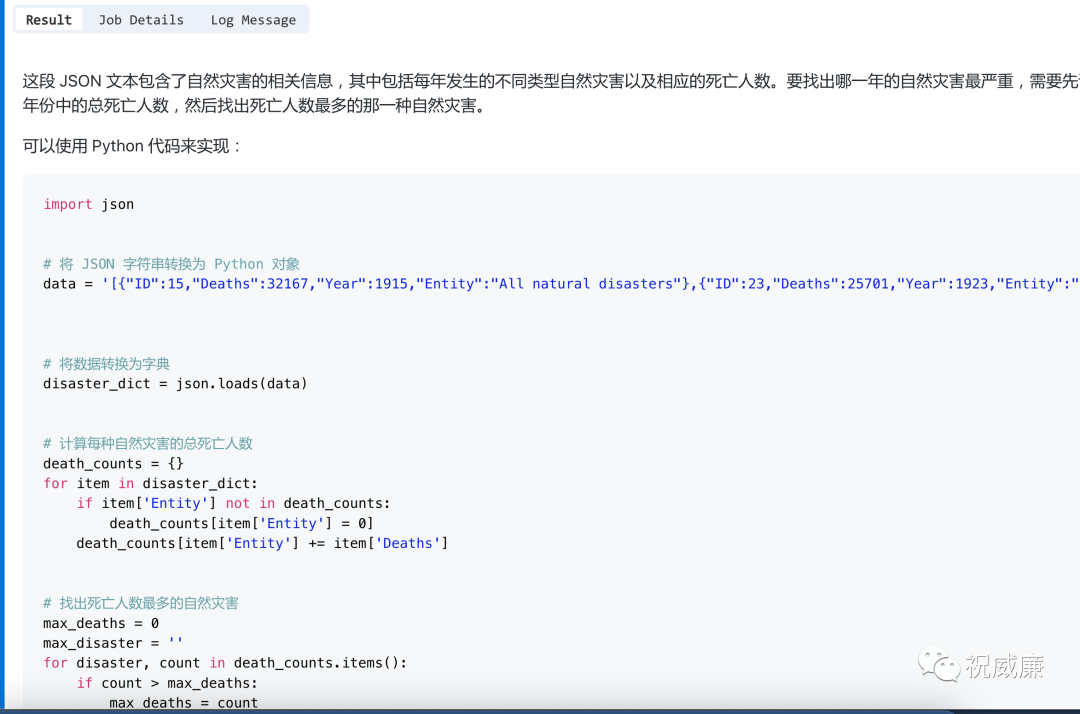
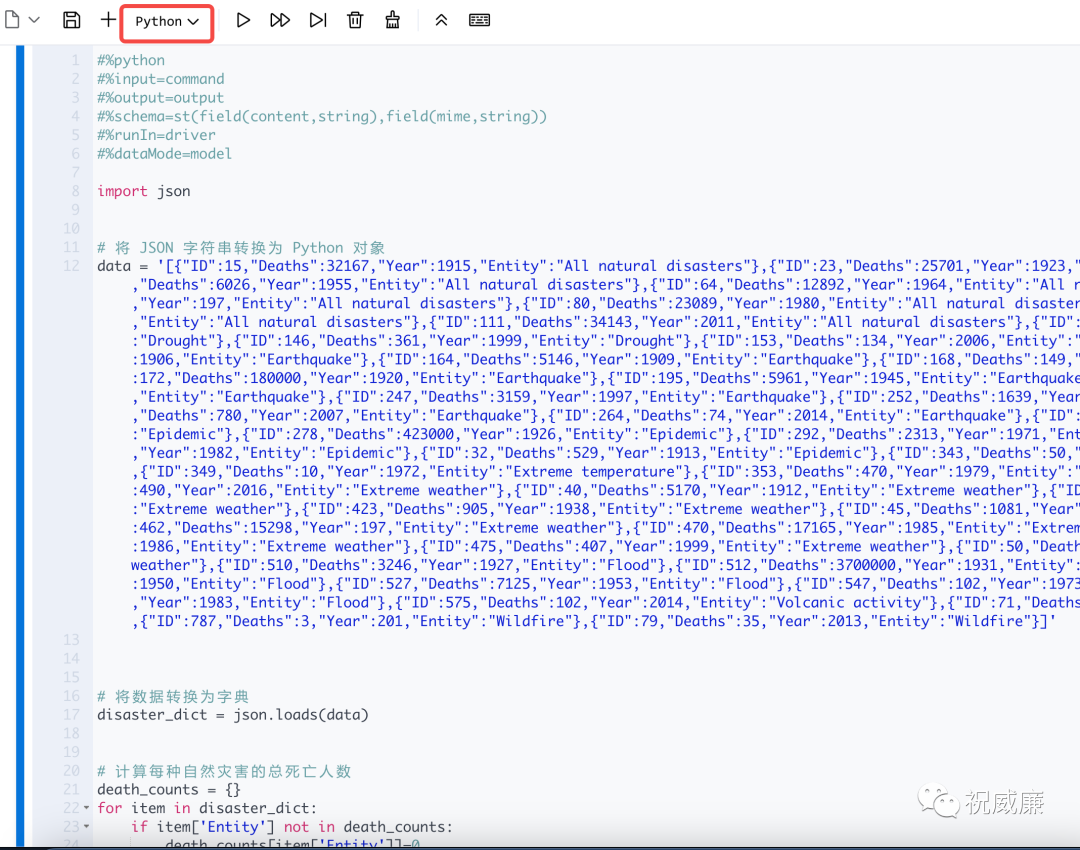
好吧,算你知道自己是大模型,计算能力不咋地,Byzer Notebook 不但支持 Python解释器,而且还强大的一塌糊涂,所以我们直接在 Byzer Notebook 验证下大模型给的这段代码吧:
这是最后的执行结果:
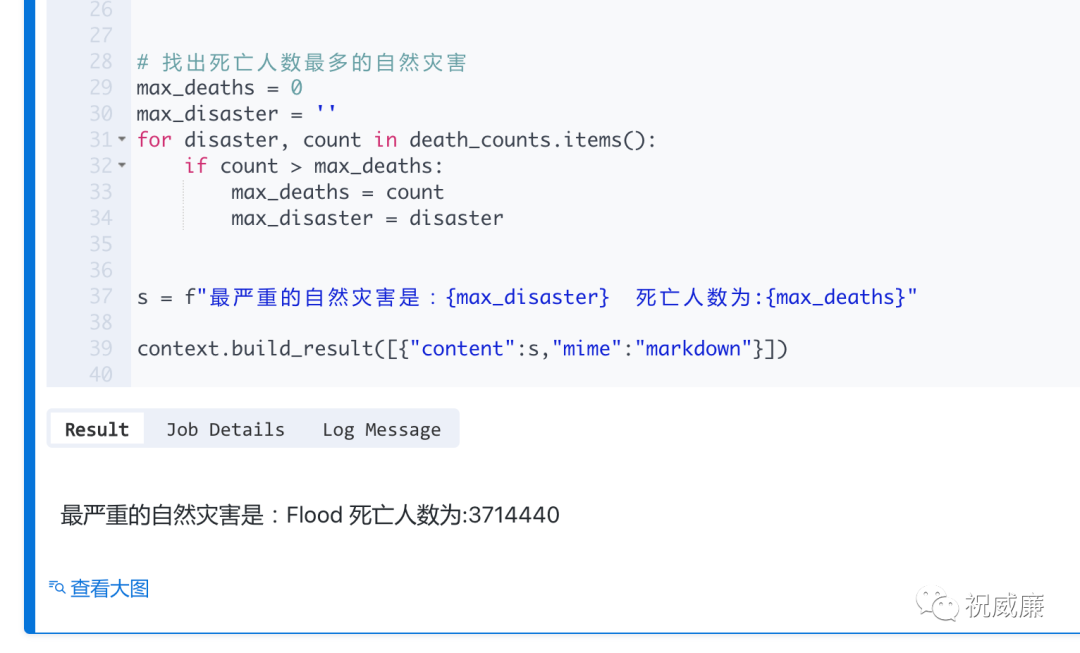
给的代码实际上有丢丢错误,不过难不倒我,调试通过了。
如果你不做计算,让他给个简单解读,也开始可以的:
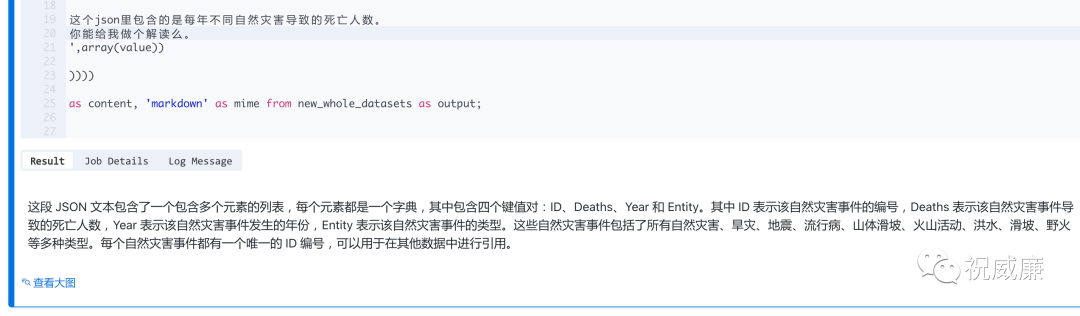
每个字段的含义都解读很准确,并且还罗列了自然灾害的类型等等。还是很不错的。
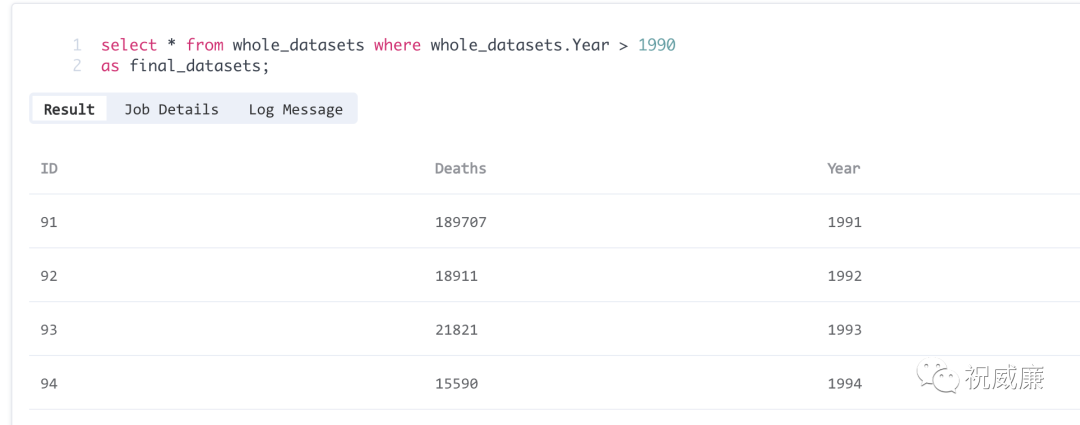
好了,大模型解读完毕,该做可视化了。先对数据简单做个过滤:
然后做可视化:
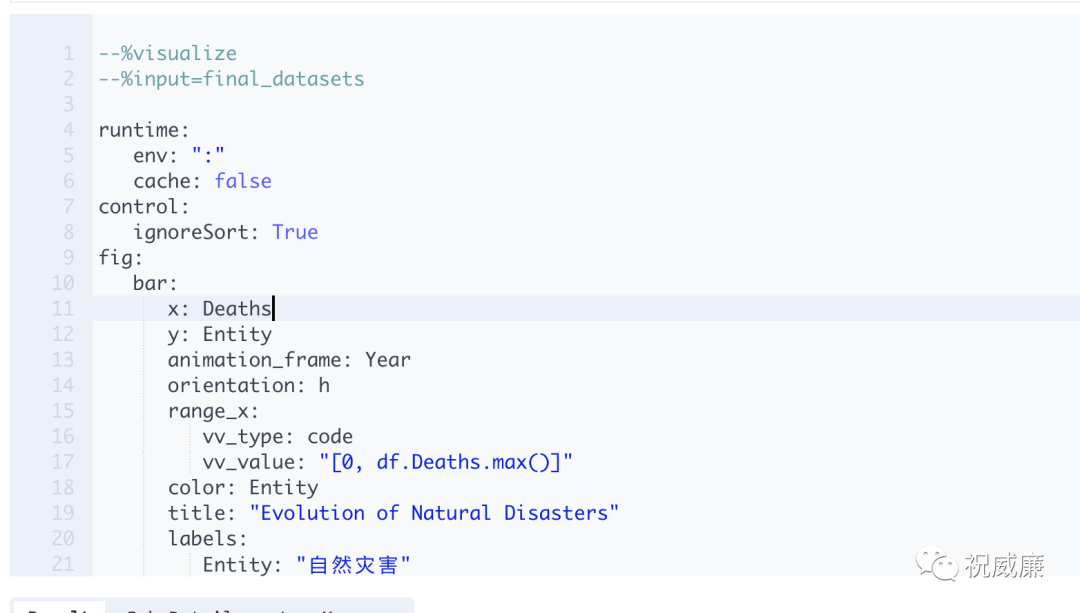
Byzer 使用 YAML 格式描述可视化。还是很简单的,大家看着文档复制黏贴就可以。
最后结果如下:
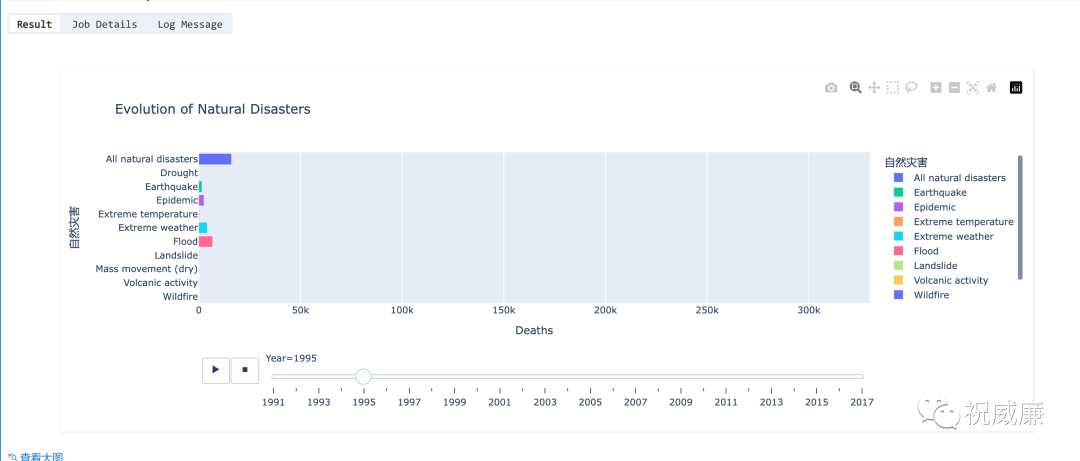
该图会根据时间自动变化,还是很酷的吧。
总结
可以看到, Byzer Notebook可以使用大模型做copilot 辅助我们写SQL ,也可以直接在 SQL 中使用大模型对数据进行分析处理。实际上 Byzer 的能力远不止如此,你还可以使用SQL 对大模型做预训练,微调,我们也提供了对SQL极大的工程增强,诸如模块化,模板,条件分支等特性的支持。
欢迎大家进入 Byzer SQL 的世界。
另外今天讲的案例,单纯的可视化版本我们可以看看我们早先的视频版讲解: