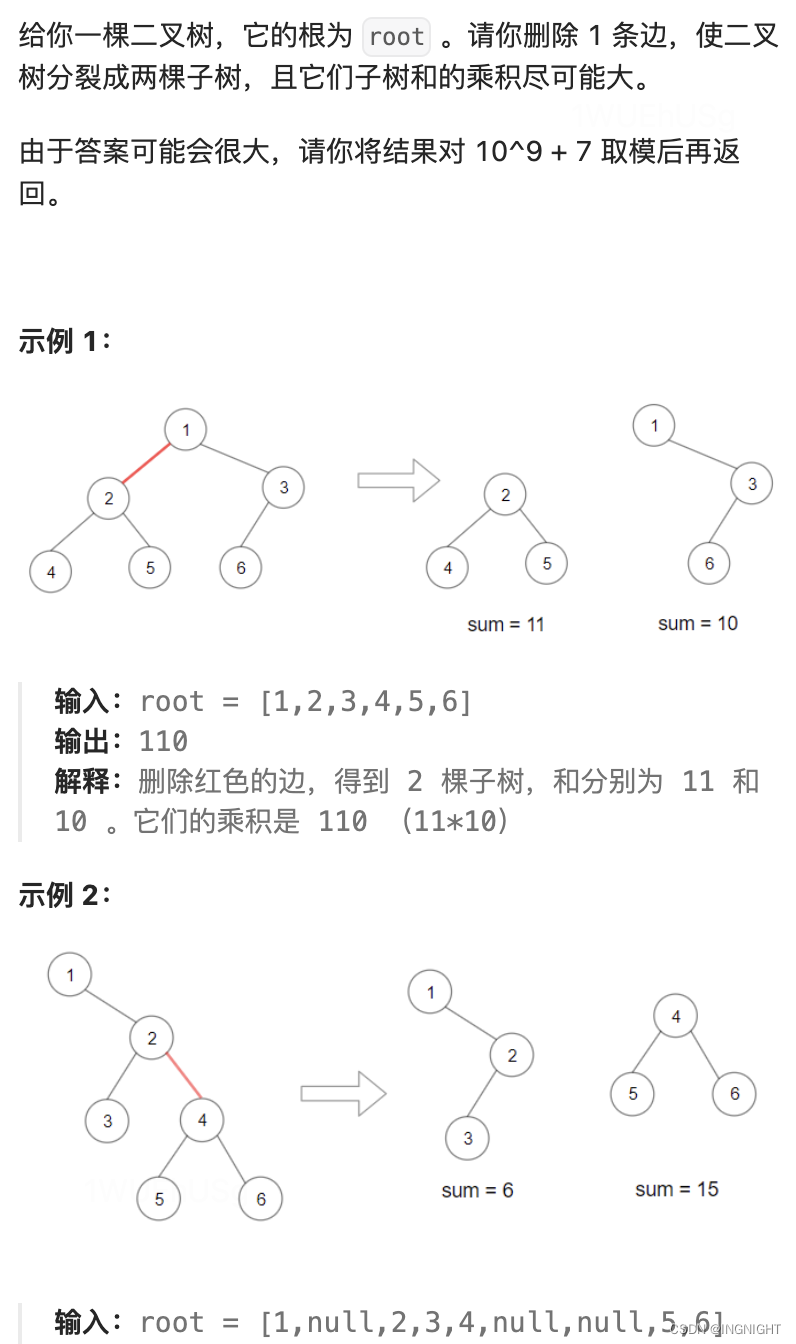
目录
使用ChatGPT进行数据格式化转换
代码示例
ChatGPT格式化数据提示语
代码示例
批量格式化数据提示语
代码示例
ChatGPT生成的格式化批处理代码
使用ChatGPT合并不同数据源的数据
合并数据提示语
自动合并数据提示语
ChatGPT生成的自动合并代码
结论
数据合并是处理多个数据源的关键步骤,它允许我们将不同来源的数据整合到一个统一的数据集中。无论是合并CSV文件、SQLite数据库还是其他数据源,正确处理数据合并对于获得准确和全面的分析结果至关重要。

使用ChatGPT进行数据格式化转换
当需要进行数据格式化转换时,可以使用ChatGPT来辅助进行转换规则的设计和理解。以下是一些使用ChatGPT进行数据格式化转换的示例场景:
1. 数据格式描述:您可以向ChatGPT提供一个数据格式的描述,并询问它如何将一种格式的数据转换为另一种格式。例如,您可以询问如何将一个JSON对象转换为XML格式,或者如何将一个CSV文件转换为JSON格式。
2. 规则设计:您可以向ChatGPT提供带有示例数据的源格式和目标格式,并询问它如何设计转换规则。例如,在在将日期由 "YYYY-MM-DD" 格式转换为 "DD/MM/YYYY" 格式时,您可以询问它需要编写哪些规则或使用哪些函数来实现。
3. 工具推荐:您可以向ChatGPT询问有关数据格式化转换的工具或库的建议。例如,您可以询问ChatGPT有关Python中的哪个库适用于处理JSON数据,或者询问有哪些在线工具可以执行特定的数据转换任务。
代码示例
当进行数据格式化转换时,您可以使用编程语言(如Python)来实现具体的代码。下面是一个示例,演示如何将JSON数据转换为CSV格式的数据:
import json
import csv
def convert_json_to_csv(json_data, csv_filepath):
# 读取JSON数据
data = json.loads(json_data)
# 获取列名(假设每个对象具有相同的键)
keys = data[0].keys()
# 创建CSV文件并写入列名
with open(csv_filepath, 'w', newline='') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=keys)
writer.writeheader()
# 遍历JSON数据并写入CSV文件
for row in data:
writer.writerow(row)
print("转换完成!")
# 假设有一个JSON数据字符串
json_data = '''
[
{
"name": "Alice",
"age": 25,
"city": "New York"
},
{
"name": "Bob",
"age": 30,
"city": "San Francisco"
},
{
"name": "Charlie",
"age": 35,
"city": "Seattle"
}
]
'''
# 调用函数将JSON数据转换为CSV格式并保存
convert_json_to_csv(json_data, 'output.csv')在上面的示例中,我们定义了一个函数 `convert_json_to_csv` 来执行转换。它将接受一个JSON数据字符串和一个指定的CSV文件路径作为参数。函数首先加载JSON数据,提取键作为CSV文件的列名,并使用`csv.DictWriter`在CSV文件中写入行数据。

ChatGPT格式化数据提示语
当使用ChatGPT来进行数据格式化时,您可以使用以下提示语来引导对话:
1. "我有一些数据需要进行格式化转换,你能帮助我吗?"
2. "我有一段JSON数据,我想将其转换为CSV格式,你知道怎么做吗?"
3. "我需要将日期数据从 'YYYY-MM-DD' 格式转换为 'DD/MM/YYYY' 格式,你有什么建议吗?"
4. "有没有什么工具或库可以用来处理数据格式化转换?"
5. "我想将一个文本文件中的数据转换为JSON格式,你能给我一些指导吗?"
通过以上提示语,您可以向ChatGPT提出具体的问题或要求,以便它能够提供更有针对性的回答和建议。请记住,尽管ChatGPT可以提供信息和指导,但最终的实际实现仍然需要您结合ChatGPT的建议和自身编程知识来完成。
代码示例
当进行数据格式化时,代码示例可以根据具体的格式转换需求而异。以下是一个示例,演示如何将日期格式从 "YYYY-MM-DD" 转换为 "DD/MM/YYYY":
import datetime
def format_date(date_str):
# 解析日期字符串为日期对象
date_obj = datetime.datetime.strptime(date_str, "%Y-%m-%d")
# 格式化日期为 "DD/MM/YYYY" 格式
formatted_date = date_obj.strftime("%d/%m/%Y")
return formatted_date
# 示例日期字符串
date_string = "2023-08-21"
# 调用函数进行日期格式转换
formatted_date = format_date(date_string)
print("转换前日期格式:", date_string)
print("转换后日期格式:", formatted_date)在上面的示例中,我们定义了一个函数 `format_date`,它将接收一个日期字符串作为参数,并返回格式化后的日期字符串。函数使用 `datetime.strptime` 解析日期字符串为日期对象,然后使用 `strftime` 方法将日期对象格式化为 "DD/MM/YYYY" 格式的字符串。
批量格式化数据提示语
当需要批量格式化数据时,您可以使用以下提示语与ChatGPT交互:
1. "我有一批日期数据需要格式化,你能告诉我如何一次性对它们进行格式转换吗?"
2. "我有一个包含多个JSON对象的文件,我想将它们批量转换为CSV格式,你有什么建议吗?"
3. "有没有一种简便的方法可以批量处理文本文件中的数据并将其转换为特定的格式?"
4. "我需要将多个图片文件转换为另一种图像格式,你知道有什么工具或库可以批量处理吗?"
5. "我有一批音频文件,我想将它们格式化并提取特定的音频特征,你可以给我一些指导吗?"

代码示例
当需要批量处理数据进行格式化时,代码示例可以根据具体的需求和数据类型而异。以下是一个示例,演示如何批量将一批文本文件中的数据进行格式化处理:
import os
def format_text_files(input_folder, output_folder):
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
input_filepath = os.path.join(input_folder, filename)
output_filepath = os.path.join(output_folder, filename)
# 打开输入文件并读取数据
with open(input_filepath, 'r') as input_file:
data = input_file.read()
# 进行数据格式转换和处理
# 例如,将文本转换为大写或小写
formatted_data = data.upper()
# 将格式化后的数据写入输出文件
with open(output_filepath, 'w') as output_file:
output_file.write(formatted_data)
# 示例输入文件夹和输出文件夹路径
input_folder = '/path/to/input/folder'
output_folder = '/path/to/output/folder'
# 执行批量格式化处理
format_text_files(input_folder, output_folder)在上面的示例中,我们定义了一个函数 `format_text_files` 来处理批量的文本文件格式化。该函数接收一个输入文件夹路径和一个输出文件夹路径作为参数。函数将遍历输入文件夹中的所有文件,读取文件数据,对数据进行格式化处理(在示例中为转换为大写),然后将格式化后的数据写入到输出文件夹中的相应文件。
ChatGPT生成的格式化批处理代码
如果你想使用ChatGPT API来帮助你格式化数据,你可以通过向API发送请求,然后解析和处理返回的回复来实现。以下是一个示例代码,演示如何使用Python的requests库来调用ChatGPT API进行数据格式化:
import requests
def format_data_with_chatgptapi(data):
# ChatGPT API请求的URL
api_url = 'https://api.openai.com/v1/chat/completions'
# 你的访问令牌
api_key = 'YOUR_API_KEY'
# 设置请求头
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
# 设置请求体
payload = {
'messages': [{'role': 'system', 'content': '你好,我有一些数据需要格式化。'}],
'max_tokens': 50,
'temperature': 0.6,
'stop': '\n'
}
# 添加需要格式化的数据到请求体
payload['messages'].append({'role': 'user', 'content': data})
try:
# 发送POST请求到ChatGPT API
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status()
# 解析返回的JSON数据
result = response.json()
# 提取ChatGPT的回复
formatted_data = result['choices'][0]['message']['content']
return formatted_data
except requests.exceptions.RequestException as e:
print('发送请求到ChatGPT API时出错:', str(e))
return None
# 示例数据需要格式化
data = '这是需要格式化的数据'
# 调用ChatGPT API进行数据格式化
formatted_data = format_data_with_chatgptapi(data)
# 输出格式化后的数据
print("格式化后的数据:", formatted_data)在上面的示例中,你需要替换`YOUR_API_KEY`为你的OpenAI API访问密钥。你可以在OpenAI的网站上获取你的API密钥。此外,你还可以根据你的具体需求和ChatGPT API的响应进行额外的处理和解析。

使用ChatGPT合并不同数据源的数据
要使用ChatGPT合并不同数据源的数据,您可以通过交互式对话与ChatGPT进行自然语言的交流,并逐步生成代码来实现数据合并的过程。以下是一个示例对话,展示了与ChatGPT对话来合并不同数据源的数据的过程:
用户:我有两个不同的数据源,一个是CSV文件,另一个是SQLite数据库,我想将它们合并成一个数据集。你有什么建议吗?
ChatGPT:你可以使用pandas库来处理CSV文件和读取SQLite数据库。首先,你需要分别读取CSV文件和SQLite数据库中的数据,然后将它们合并成一个数据集,最后可以将结果保存到新的CSV文件或SQLite数据库中。
用户:那么我如何进行数据合并的代码开发?
ChatGPT:下面是一个简单的代码框架,可以作为你开始编写代码的思路参考:
import pandas as pd
import sqlite3
# 从CSV文件读取数据
csv_data = pd.read_csv('/path/to/csv_file.csv')
# 从SQLite数据库中读取数据
conn = sqlite3.connect('/path/to/database.db')
sql_data = pd.read_sql_query('SELECT * FROM table_name', conn)
# 合并数据集
merged_data = pd.concat([csv_data, sql_data], axis=0)
# 保存合并后的数据到CSV文件
merged_data.to_csv('/path/to/merged_data.csv', index=False)
# 或者保存到SQLite数据库
merged_data.to_sql('table_name', conn, if_exists='replace', index=False)
conn.close()请注意,在上述示例中,你需要将`/path/to/csv_file.csv`和`/path/to/database.db`替换为你的实际文件路径和SQLite数据库路径,并根据需要修改表名和保存路径。此外,你可能还需要根据实际情况进行错误处理和数据清洗操作。
合并数据提示语
当您与ChatGPT合作合并不同数据源的数据时,您可以使用以下提示语与ChatGPT进行对话:
- "我有两个不同的数据源,一个是CSV文件,另一个是SQLite数据库,我想将它们合并成一个数据集。你有什么建议吗?"
- "哪种方法可以帮助我将两个不同数据源的数据合并在一起?"
- "我怎样用Python代码将CSV文件和SQLite数据库中的数据合并?"
- "我如何处理两个数据源中的数据重复和缺失值,以便在合并时获得准确的结果?"
- "有没有示例代码可以展示如何合并不同数据源的数据?"
- "请告诉我如何使用pandas库将不同数据源的数据合并成一个数据集。"
- "请给我一个合并CSV文件和SQLite数据库数据的步骤指南。"
- "有没有一些最佳实践来处理不同数据源的数据合并?"
通过与ChatGPT进行交互,并提供关于您的数据源、合并方式和最佳实践的上下文信息,ChatGPT将可以提供更专业化的建议和代码示例来帮助您实现数据合并操作。请确保与ChatGPT进行明确和详细的对话,以确保您得到最准确和适合的代码建议。

自动合并数据提示语
在与ChatGPT进行对话时,可以使用以下提示语来获取关于自动合并数据的建议:
- "我有多个数据源,想要自动合并它们。有什么建议吗?"
- "有没有一种方法可以自动识别和合并多个数据源的数据?"
- "我需要一个自动化的解决方案来处理多个数据源的数据合并。你有什么推荐吗?"
- "有没有一些工具或技术可以帮助我自动合并数据,而不需要手动干预?"
- "我想要一个自动化脚本,可以自动合并多个数据源的数据。有什么思路吗?"
- "有没有一些库或算法可以自动识别和匹配多个数据源的关键字段,然后进行数据合并?"
- "请给我一些关于自动合并数据的最佳实践和原则。"
通过与ChatGPT进行交互,并提供关于自动合并数据的背景信息和上下文,ChatGPT将能够提供针对自动化合并数据的更具体建议和指导。请确保与ChatGPT进行细致和清晰的对话,以便获得最准确和适应的代码和策略方案。
ChatGPT生成的自动合并代码
以下是ChatGPT生成的示例自动合并数据的代码:
import pandas as pd
# 读取所有数据源的数据
data_sources = [
"/path/to/data_source1.csv",
"/path/to/data_source2.csv",
"/path/to/data_source3.csv"
]
data_frames = []
for source in data_sources:
df = pd.read_csv(source)
data_frames.append(df)
# 自动合并数据
merged_data = pd.concat(data_frames, ignore_index=True)
# 保存合并后的数据
merged_data.to_csv("/path/to/merged_data.csv", index=False)
print("数据合并完成并保存为merged_data.csv")请注意,生成的代码只是一个示例,需要根据实际情况进行修改和调整。上述代码假设数据源是CSV文件,并且使用pandas库来读取和合并数据。你需要将`/path/to/data_sourceX.csv`替换为实际的数据源路径,并根据需要进行适当的数据清洗和处理。
结论
数据合并是数据处理中的重要环节,它可以帮助我们获得更全面、准确的数据视图。我们要根据特定情况对代码进行修改和优化,并根据数据的特性进行适当的数据清洗和处理,以确保合并的结果尽可能准确和有用。