页框回收算法
Linux中有一点很有意思,在为用户态进程与内核分配动态内存时,所作的检查是马马虎虎的。
比如,对单个用户所创建进程的RAM使用总量并不作严格检查(第三章的“进程资源限制”一节提到的限制只针对单个进程);
对内核使用的许多磁盘高速缓存和内存高速缓存大小也同样不作限制。
减少控制是一种设计选择,这使内核以最好的可行方式使用可用的RAM。
当系统负载较低时,RAM的大部分由磁盘高速缓存占用,很少正在运行的进程可以从中获益。
但是,当系统负载增加时,RAM的大部分则由进程页占用,高速缓存就会缩小从而给后来的进程让出空间。
我们在前面的章节中看到,内存及磁盘高速缓存抓取了那么多的页框但从未释放任何页框。
这是合理的,因为高速缓存系统并不知道进程是否(什么时候)会重新使用某些缓存的数据,因此不能确定高速缓存的哪些部分应该释放。
此外,正是有了第九章描述的请求调页机制,只要用户态进程继续执行,它们就能获得页框;然而,请求调页没有办法强制进程释放不再使用的页框。
因此,迟早所有空闲内存将被分配给进程和高速缓存。
Linux内核的页框回收算法(page frame reclaiming algorithm,PFRA)采取从用户态进程和内核高速缓存“窃取”页框的办法补充伙伴系统的空闲块列表。
实际上,在用完所有空闲内存之前,就必须执行页框回收算法。否则,内核很可能陷入一种内存请求的僵局中,并导致系统崩溃。
也就是说,要释放一个页框,内核就必须把页框的数据写入磁盘;
但是,为了完成这一操作,内核却要请求另一个页框(例如,为I/O数据传送分配缓冲区首部)。因为不存在空闲页框,因此,不可能释放页框。
页框回收算法的目标之一就是保存最少的空闲页框池以便内核可以安全地从“内存紧缺”的情形中恢复过来。
选择目标页
页框回收算法(PFRA)的目标就是获得页框并使之空闲。
显然,PFRA选取的页框肯定不是空闲的,即这些页框原本不在伙伴系统的任何一个free_area数组中(参见第八章的“伙伴系统算法”一节)。
PFRA按照页框所含内容,以不同的方式处理页框。我们将它们区分成:不可回收页、可交换页、可同步页和可丢弃页,如表17-1所示。


在表17-1中,所谓“映射页”是指该页映射了一个文件的某个部分。
比如,属于文件内存映射的用户态地址空间中所有页都是映射页,页高速缓存中的任何其他页也是映射页。
映射页差不多都是可同步的:为回收页框,内核必须检查页是否为脏,而且必要时将页的内容写到相应的磁盘文件中。
相反,所谓的“匿名页”是指它属于一个进程的某匿名线性区(倒如,进程的用户态堆和堆栈中的所有页为匿名页)。
为回收页框,内核必须将页中内容保存到一个专门的磁盘分区或磁盘文件,叫做“交换区”(参见后面“交换”一节)。因此,所有匿名页都是可交换的。
通常,特殊文件系统中的页是不可回收的。唯一的例外是tmpfs特殊文件系统的页,它可以被保存在交换区后被回收。
在第十九章中我们将看到tmpfs特殊文件系统用于IPC 共享内存机制。
当PFRA必须回收属于某进程用户态地址空间的页框时,它必须考虑页框是否为共享的。
共享页框属于多个用户态地址空间,而非共享页框属于单个用户态地址空间。
注意,非共享页框可能属于几个轻量级进程,这些进程使用同一个内存描述符。
当进程创建子进程时,就建立了共享页框。
正如第九章“写时复制”一节所述,子进程页表都从父进程中复制过来的,父子进程因此共享同一个页框。
共享页框的另一个常见情形是:一个或多个进程以共享内存映射的方式访问同一个文件(参见第十六章的“内存映射”一节)(注1)。
PFRA设计
尽管很容易确定回收内存的候选页(粗略地说,任何属于磁盘和内存高速缓存的页,以及属于进程用户态地址空间的页),
但是选择合适的目标页可能是内核设计中最精巧的问题。
事实上,对处理虚拟内存子系统的开发者来说,其最难的工作在于找到一种合适的算法,
这种算法既能确保台式计算机有可接受的性能(在这种计算机上内存的需要是相当有限的,而对系统响应的要求则是十分严格的),
也能确保像大型数据库服务器那样的高级计算机有可接受的性能(在这种计算机上对内存的需要则巨大无比)。
不幸的是,找到一种较佳的页框回收算法是一种相当经验性的工作,很少有理论的支持。
这种情形类似于对决定进程动态优先级的因素进行评估:
主要目的是调整参数以达到较好的性能,不要问太多的为什么。
通常情况下,这仅仅是“让我们试一试这种方法,看看会发生什么……”这么回事。
这种经验主义方法的负面效果就是代码变化快。
因此我们无法保证:
在你阅读本章时,这里讲的Linux 2.6.11使用的内存回收算法与Linux 2.6 的最新版本中所使用的内存回收算法完全一致。
但是,这里所讲的一般原则和主要的启发式准则还会继续使用。
一叶障目,不见泰山。因此,让我们先看看PFRA采用的几个总的原则,这些原则包含在本章后面介绍的几个函数中。
1.首先释放“无害”页
在进程用户态地址空间的页回收之前,必须先回收没有被任何进程使用的磁盘与内存高速缓存中的页。
实际上,回收磁盘与内存高速缓存的页框并不需要修改任何页表项。
我们在本章后面“最近最少使用(LRU)链表”一节会看到,在使用“交换倾向因子(swap tendency factor)”后,这个准则可以做出一些调整。
2.将用户态进程的所有页定为可回收页
除了锁定页,FPRA必须能够窃得任何用户态进程页,包括匿名页。这样,睡眠较长时间的进程将逐渐失去所有页框。
3.同时取消引用一个共享页框的所有页表项的映射,就可以回收该共享页框
当PFRA要释放几个进程共享的页框时,它就清空引用该页框的所有页表项,然后回收该页框。
4.只回收“未用”页
使用简化的最近最少使用(Least Recently Used,LRU)置换算法,PFRA将页分为“在用(in_use)”与“未用(unused)”(注2)。
如果某页很长时间没有被访问,那么它将来被访问的可能性较小,就可以将它看作未用;
另一方面,如果某页最近被访问过,那么它将来被访问的可能性较大,就必须将它看作在用。
PFRA只回收未用页。这就是第二章中“硬件高速缓存”一节所讲局部性原则的另一个应用。
LRU算法的主要思想就是用一个计数器来存放RAM中每一页的页年龄,即上一次访问该页到现在已经过的时间。
这个计数器可使PFRA只回收任何进程的最旧页。
一些计算机平台提供较为成熟的LRU算法(注3)。
不幸的是,80x86处理器不提供这样的硬件功能,因此Linux内核不能依赖页计数器记录每页的页年龄。
为解决这一问题,Linux使用每个页表项中的访问标志位(Accessed),在页被访问时,该标志位由硬件自动置位;
而且,页年龄由页描述符在链表(两个不同的链表之一)中的位置来表示[参见本章后面“最近最少使用(LRU)链表”一节]。
因此,页框回收算法是几种启发式方法的混合:
1.谨慎选择检查高速缓存的顺序。
2.基于页年龄的变化排序(在释放最近访问的页之前,应当释放最近最少使用的页)。
3.区别对待不同状态的页(例如,不脏的页与脏页之间,最好把前者换出,因为前者不必写磁盘)。
反向映射
正如上一节所述,PFRA的目标之一是能释放共享页框。
为达到这个目的,Linux 2.6内核能够快速定位指向同一页框的所有页表项。这个过程就叫做反向映射(reverse mapping)。
反向映射方法的简单解决之道,就是在页描述符中引入附加字段,从而将某页描述符所确定的页框中对应的所有页表项联接起来。
但是,保持更新这样的链表将会大大增加系统开销,因此,就有更成熟的方法设计出来了。
Linux 2.6就有叫做“面向对象的反向映射”的技术。
实际上,对任何可回收的用户态页,内核保留系统中该页所在所有线性区(“对象”)的反向链接,
每个线性区描述符存放一个指针指向一个内存描述符,而该内存描述符又包含一个指针指向一个页全局目录(Page Global Directory)。
因此,这些反向链接使得PFRA能够检索引用某页的所有页表项。
因为线性区描述符比页描述符少,所以更新共享页的反向链接就比较省时间。我们来看看这一方法是如何实现的。
首先,PFRA必须要确定待回收页是共享的或是非共享的,以及是映射页或是匿名页。为做到这一点,内核要查看页描述符的两个字段:_mapcount和mapping。
_mapcount字段存放引用页框的页表项数目。计数器的起始值为-1,这表示没有页表项引用该页框;如果值为0,就表示页是非共享的;
而如果值大于0,则表示页是共享的。
page_mapcount函数接收页描述符地址,返回值为_mapcount+1(这样,如返回值为1,表明是某个进程的用户态地址空间中存放的一个非共享页)。
页描述符的mapping字段用于确定页是映射的或匿名的。说明如下:
1.如果mapping字段空,则该页属于交换高速缓存(参见本章后面“交换高速缓存”一节)。
2.如果mapping字段非空,且最低位是1,表示该页为匿名页;
同时mapping字段中存放的是指向anon_vma描述符的指针(参见下一节“匿名页的反向映射")。
3.如果mapping字段非空,且最低位是0,表示该页为映射页;同时mapping字段指向对应文件的address_space对象(参见第十五章的“address_space对象"一节)。
Linux的address_space对象在RAM中是对齐的,所以其起始地址是4的倍数。
因此其mapping字段的最低位可以用作一个标志位来表示该字段的指针是指向address_space 对象还是anon_vma描述符。
这是一个不规范的编程技巧,但内核要使用大量的页描述符,所以这些数据结构必须尽可能的小。
PageAnon()函数接收页描述符地址作为参数,如果mapping字段的最低位置位,则函数返回1;否则返回0。
try_to_unmap()函数接收页描述符指针作为参数,尝试清空所有引用该页描述符对应页框的页表项。
如果从页表项中成功清除所有对该页框的应用,函数返回SWAP_SUCCESS (0);如果有些引用不能清除,函数返回SWAP_AGAIN(1);
如果出错,函数返回SWAP_FAIL (2)。这个函数很短:
int try_to_unmap(struct page *page)
{
int ret;
if(PageAnon(page))
ret = try_to_unmap_anon(page);
else
ret = try_to_unmap_file(page);
if(!page_mapped(page))
ret = SWAP_SUCCESS;
return ret;
}
函数try_to_unmap_anon()和try_to_unmap_file()分别处理匿名页和映射页。后面会对这两个函数加以说明。
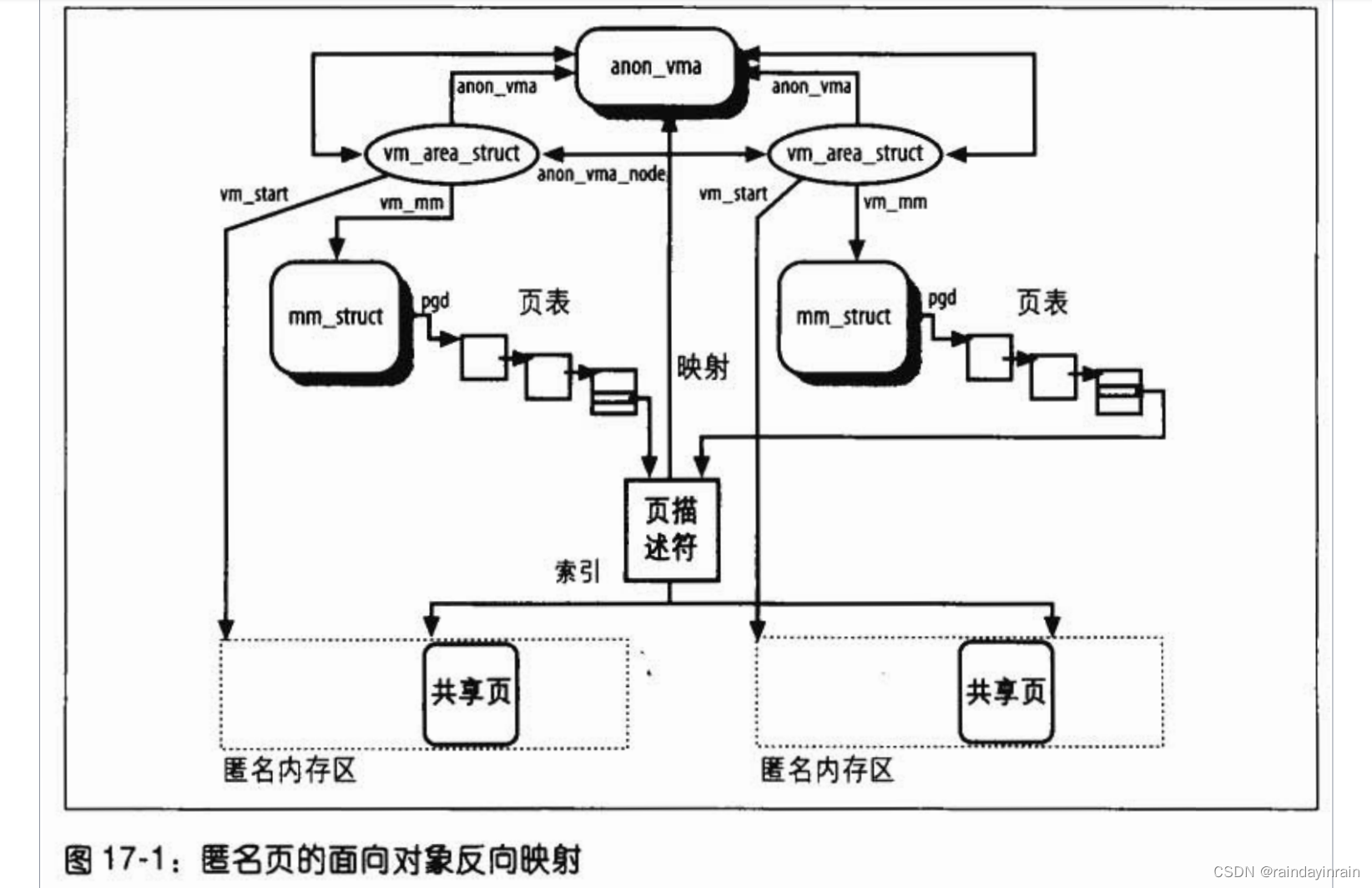
匿名页的反向映射
匿名页经常是由几个进程共享的。
最为常见的情形是:创建新进程,这在第九章中“写时复制”一节里已有描述,父进程的所有页框,包括匿名页,同时也分配给子进程。
另外(但不常见),进程创建线性区时使用两个标志MAP_ANONYMOUS和MAP_SHARED,表明这个区域内的页将由该进程后面的子进程共享。
将引用同一个页框的所有匿名页链接起来的策略非常简单,即将该页框所在的匿名线性区存放在一个双向循环链表中。
要注意的是:即使一个匿名线性区存有不同的页,也始终只有一个反向映射链表用于该区域中的所有页框。
当为一个匿名线性区分配第一页时,内核创建一个新的anon_vma数据结构,它只有两个字段:lock和head。
lock字段是竞争条件下保护链表的自旋锁;
head字段是线性区描述符双向循环链表的头部。
然后,内核将匿名线性区的vm_area_struct描述符插入anon_vma链表。
为实现这个目的,vm_area_struct数据结构中包含有对应该链表的两个字段:anon_vma_node和anon_vma。
anon_vma_node字段存放指向链表中前一个和后一个元素的指针,而anon_vma字段指向anon_vma数据结构。
最后,按前面所述,内核将anon_vma数据结构的地址存放在匿名页描述符的mapping字段。如图17-1所示。
当已被一个进程引用的页框插入另一个进程的页表项时(例如调用fork()系统调用时,参见第三章中“clone()、fork()及vfork()系统调用”一节),
内核只是将第二个进程的匿名线性区插入anon_vma数据结构的双向循环链表,
而第一个进程线性区的anon_vma字段指向该anon_vma数据结构。因此每个anon_vma链表通常包含不同进程的线性区(注4)。
如图17-1所示,借助anon_vma链表,内核可以快速定位引用同一匿名页框的所有页表项。
实际上,每个区域描述符在vm_mm字段中存放内存描述符地址,而该内存描述符又有一个pgd字段,其中存有进程的页全局目录。
这样,页表项就可以从匿名页的起始线性地址得到,而该线性地址可以由线性区描述符以及页描述符的index字段得到。
try_to_unmap_anon()函数
当回收匿名页框时,PFRA必须扫描anon_vma链表中的所有线性区,仔细检查是否每个区域都存有一个匿名页,而其对应的页框就是目标页框。
这一工作就是通过try_to_unmap_anon()函数实现的,它接收目标页框描述符作为参数,执行的主要步骤如下:
1. 获得anon_vma数据结构的自旋锁,页描述符的mapping字段指向该数据结构。
2. 扫描线性区描述符的anon_vma链表。对该链表中的每一个vma线性区描述符,调用try_to_unmap_one()函数,传给它参数vma和页描述符(参见下面)。
如果由于某种原因返回值为SWAP_FAIL,或如果页描述符的_mapcount字段表明已找到所有引用该页框的页表项,那么停止扫描,而不用扫描到链表底部。
3. 释放第1步得到的自旋锁。
4. 返回最后调用try_to_unmap_one()函数得到的值:SWAP_AGAIN(部分成功)或SWAP_FAIL(失败)。
try_to_unmap_one()函数
try_to_unmap_one()函数由try_to_unmap_anon()和try_to_unmap_file()重复调用。
它有两个参数:page和vma。page是一个指向目标页描述符的指针;而vma是指向线性区描述符的指针。该函数执行的主要步骤如下:
1. 计算出待回收页的线性地址,所依据的参数有:
线性区的起始线性地址(vma->vm_start)、被映射文件的线性区偏移量(vma->vmpgoff)和被映射文件内的页偏移量(page->index)。
对于匿名页,vma->vmpgoff字段是0或者vm_start/PAGE_SIZE;相应地,page->index字段是区域内的页索引或是页的线性地址除以PAGE_SIZE。
2. 如果目标页是匿名页,则检查页的线性地址是否在线性区内。
如果不是,则结束并返回SWAP_AGAIN(在介绍匿名页的反向映射时,我们讲过anon_vma链表可能存有不包含目标页的线性区)。
3. 从vma->vm_mm得到内存描述符地址,并获得保护页表的自旋锁vma->vm_mn->page_table_lock。
4. 成功调用pgd_offset()、pud_offset()、pmd_offset()和pte_offset_map()以获得对应目标页线性地址的页表项地址。
5. 执行一些检查来验证目标页可有效回收。下面的检查步骤中,如果任何一步失败,
函数跳到第12步,结束并返回一个有关的错误码:SWAP_AGAIN或SWAP_FAIL。
a.检查指向目标页的页表项。如果不成功,则函数返回SWAP_AGAIN。这可能在以下几种情形下发生:
a.1.指向页框的页表项与COW关联,而vma标识的匿名线性区仍然属于原页框的anon_vma链表。
a.2.mremap()系统调用可重新映射线性区,并通过直接修改页表项将页移到用户态地址空间。
这种特殊情况下,因为页描述符的index字段不能用于确定页的实际线性地址,所以面向对象的反向映射就不能使用了。
a.3.文件内存映射是非线性的(参见第十六章的“非线性内存映射”一节)。
b.验证线性区不是锁定(VM_LOCKED)或保留(VM_RESERVED)的。如果有锁定(VM_LOCKED)或保留情况之一出现,函数就返回SWAP_FAIL。
c.验证页表项中的访问标志位(Accessed)被清0。如果没有,该函数将它清0,并返回SWAP_FAIL。访问标志位置位表示页在用,因此不能被回收。
d.检查页是否属于交换高速缓存(参见本章后面“交换高速缓存”一节),且此时它正由get_user_pages()处理(参见第九章的“分配线性地址区间”一节)。
在这种情形下,为避免恶性竞争条件,函数返回SWAP_FAIL。
6. 页可以被回收。如果页表项的Dirty标志位置位,则将页的PG_dirty标志置位。
7. 清空页表项,刷新相应的TLB。
8. 如果是匿名页,函数将换出页(swapped-out page)标识符插入页表项,以便将来访问时将该页换入(参见本章后面“交换”一节)。
而且,递减存放在内存描述符anon_rss字段中的匿名页计数器。
9. 递减存放在内存描述符rss字段中的页框计数器。
10.递减页描述符的_mapcount字段,因为对用户态页表项中页框的引用已被删除。
10. 递减存放在页描述符_count字段中的页框使用计数器。如果计数器变为负数,
则从活动或非活动链表中删除页描述符[参见本章后面“最近最少使用(LRU)链表”一节],
而且调用free_hot_page()释放页框(参见第八章的“每CPU页框高速缓存”一节)。
12.调用pte_unmap()释放临时内核映射,因为第4步中的pte_offset_map()可能分配了一个这样的映射(参见第八章的“高端内存页框的内核映射”一节)。
13.释放第3步中获得的自旋锁vma->vm_mm->page_table_lock。
14.返回相应的错误码(成功时返回SWAP_AGAIN)。
映射页的反向映射
与匿名页相比,映射页的面向对象反向映射所基于的思想很简单:
我们总是可以获得指向一个给定页框的页表项,方法就是访问相应映射页所在的线性区描述符。
因此,反向映射的关键就是一个精巧的数据结构,这个数据结构可以存放与给定页框有关的所有线性区描述符。
我们在上一节看到,匿名线性区描述符存放在双向循环链表中。
获得引用给定页框的所有页表项,就是对该链表中的元素进行线性扫描。共享匿名页框的数量不是很大,因此这个方法工作得很好。
与匿名页相反,映射页经常是共享的,这是因为不同的进程常会共享同一个程序代码。
例如,几乎所有进程都会共享包含标准C库代码的页(参见第二十章的“库”一节)。
因此,Linux2.6依靠叫做“优先搜索树(priority search tree)”的结构来快速定位引用同一页框的所有线性区。
每个文件对应一个优先搜索树。它存放在address_space对象的i_mmap字段中,该address_space对象包含在文件的索引节点对象中。
因为映射页描述符的mapping字段指向address_space对象,所以总是能够快速检索搜索树的根。
优先搜索树
Linux 2.6使用的优先搜索树(PST)是基于Edward McCreight于1985年提出的一种数据结构,用于表示一组相互重叠的区间。
McCreight树是一个堆和对称搜索树的混合体,且用于对一个区间集进行查询。
例如,“在一个给定区间内有哪些区间?”和“哪些区间与给定区间相交?”这种查询所花的时间与树的高度和结果区间的数量成正比。
PST中的每一个区间相当于一个树的节点,它由基索引(radix index)和堆索引(heap index)两个索引来标识。
基索引表示区间的起始点而堆索引表示终点。PST实际上是一个依赖于基索引的搜索树,并附加一个类堆属性,即一个节点的堆索引不会小于其子节点的堆索引。
Linux优先搜索树与McCreight数据结构的不同有两个重要方面:
第一,Linux树不总是对称的(对称算法要耗费很多的系统空间和执行时间);第二,Linux树被修改成存放线性区而不是线性区间。
每个线性区可以被看成是文件页的一个区间,并由在文件中的起始位置(基索引)和终点位置(堆索引)所确定。
但是,线性区通常是从同一页开始(通常从页索引0开始)。不幸的是,McCreight的原数据结构不能存放起始位置完全一样的区间。
补充解决方案是:除了基索引和堆索引,PST的每个节点附带一个大小索引(size index)。该大小索引的值为线性区大小(页数)减1。
该大小索引使搜索程序能够区分同一起始文件位置的不同线性区。
然而,大小索引会大大增加不同的节点数,会使PST溢出。特别是,当有很多节点具有相同的基索引但堆索引不同时,PST就无法全部容下它们。
为了解决这个问题,PST可以包括溢出子树(overflow subtree),该子树以PST的叶为根,且包含具有相同基索引的节点。
此外,不同进程拥有的线性区可能是映射了相同文件的相同部分(如上面提及的标准C 库)。
在这种情况下,对应这些区域的所有节点具有相同的基索引、堆索引和大小索引。
当必须在PST中插入一个与现存某个节点具有相同索引值(基索引、堆索引和大小索引都相同)的线性区时,
内核将该线性区描述符插入一个以原PST节点为根的双向循环列表。
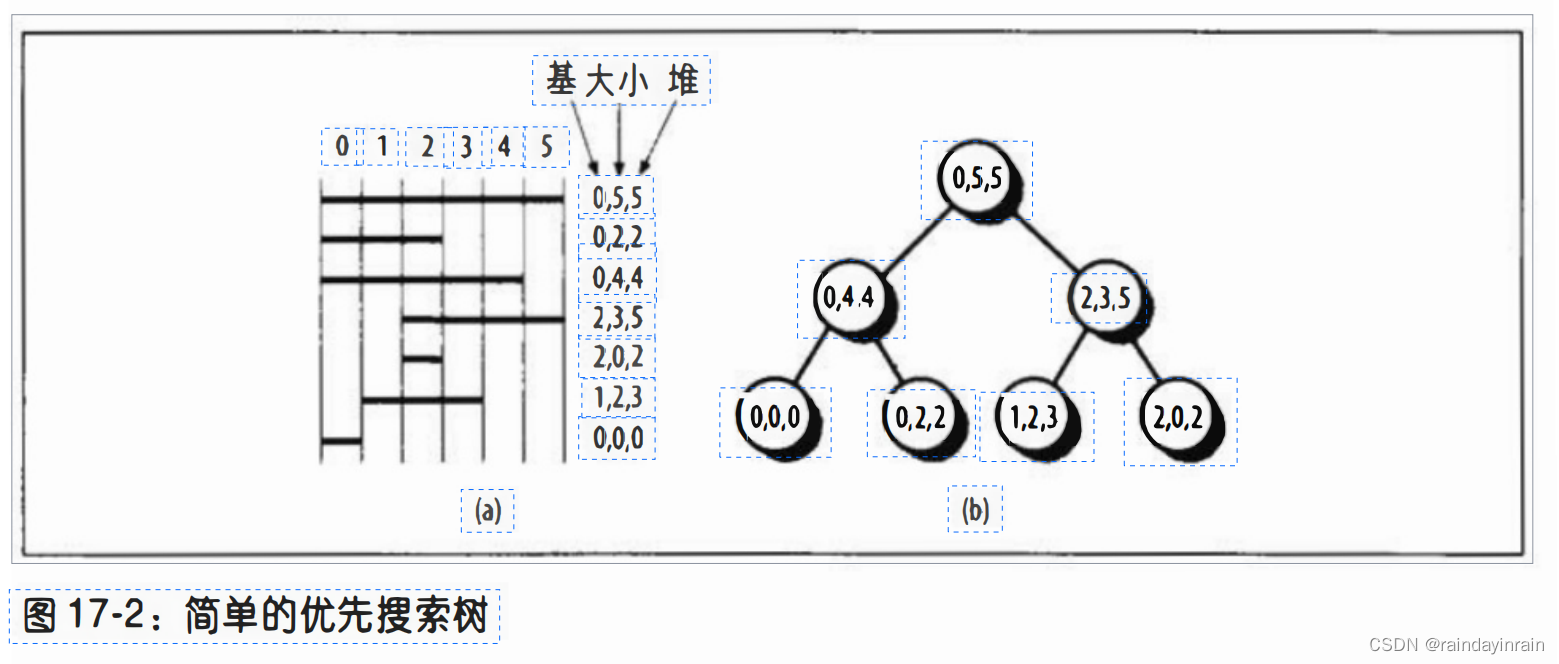
图17-2所示是一个简单的优先搜索树。在图的左侧,我们看到有七个线性区覆盖着一个文件的前六页。
每个区间都标有基索引、堆索引和大小索引。在图的右侧,则是对应的PST。
注意,子节点的堆索引都不大于相应父节点的堆索引。
而且我们可以看到,任意一个节点的左子节点基索引也都不大于右子节点基索引,如果基索引相等,则按照大小索引排序。
让我们假定:PFRA搜索包含某页(索引为5)的全部线性区。
搜索算法从根(0,5,5)开始,因为相应区间包含该页,那么这就是得到的第一个线性区。
然后算法搜索根的左子节点(0,4,4),比较堆索引(4)和页索引,因为堆索引较小,所以区间不包括该页。
而且,有了PST的类堆属性,该节点的所有子节点都不包括该页。
因此,算法直接跳到根的右子节点(2,3,5),其相应区间包含该页,因此得到这个区间。然后,算法搜索子节点(1,2,3)和(2,0,2),但它们都不包含该页。
因篇幅有限,我们对实现Linux PST的数据结构与函数无法作详尽阐述。
我们只讨论由prio_tree_node数据结构表示的一个PST节点。该数据结构在每个线性区描述符的shared.prio_tree_node字段中。
shared.vm_set数据结构作为shared.prio_tree_node 的替代品,可以用来将线性区描述符插入一个PST节点的链表副本。
可以用vma_prio_tree_insert()和vma_prio_tree_remove()函数分别插入和删除PST节点。
两个函数的参数都是线性区描述符地址与PST根地址。
对PST的搜索可调用vma_prio_tree_foreach宏来实现,该宏循环搜索所有线性区描述符,这些描述符在给定范围的线性地址中包含至少一页。
try_to_unmap_file()函数
try_to_unmap_file()函数由try_to_unmap()调用,并执行映射页的反向映射。当为线性内存映射时,该函数就很容易描述(参见第十六章的“内存映射”一节)。
这种情况下,它执行的步骤如下:
1. 获得page->mapping->i_mmap_lock自旋锁。
2. 对搜索树应用vma_prio_tree_foreach()宏,搜索树的根存放在page->mapping->i_mmap字段。
对宏发现的每个vm_area_struct描述符,函数调用try_to_unmap_one(),尝试对该页所在的线性区页表项清0(参见前面“匿名页的反向映射”一节)。
如果由于某种原因,返回SWAP_FAIL,或者如果页描述符的_mapcount字段表明引用该页框的所有页表项都已找到,则搜索过程马上结束。
3. 释放page->mapping->i_mmap_lock自旋锁。
4. 根据所有的页表项清0与否,返回SWAP_AGAIN或SWAP_FAIL。
如果映射是非线性的(参见第十六章的“非线性内存映射”一节),那么try_to_unmap_one()函数可能无法清0某些页表项,
这是因为页描述符的index字段(该字段存放文件中页的位置)不再对应线性区中的页位置,
try_to_unmap_one()函数就无法确定页的线性地址,也就无法得到页表项地址。
唯一的解决方法是对文件非线性线性区的穷尽搜索。
双向链表以文件的所有非线性线性区的描述符所在的page->mapping文件的address-space对象的i_rmap_nonlinear字段为根。
对每个这样的线性区,try_to_unmap_file()函数调用try_to_unmap_cluster(),
而try_to_unmap_cluster()函数会扫描该线性区线性地址所对应的所有页表项,并尝试将它们清0。
因为搜索可能很费时,所以执行有限扫描,而且通过试探法决定扫描线性区的哪一部分,
vma_area_struct描述符的vm_private_data字段存有当前扫描的当前指针。
因此,try_to_unmap_file()函数在某些情况下可能会找不到待停止映射的页。
出现这种情况时,try_to_unmap()函数发现页仍然是映射的,那么返回SWAP_AGAIN而不是SWAP_SUCCESS。
PFRA实现
页框回收算法必须处理多种属于用户态进程、磁盘高速缓存和内存高速缓存的页,而且必须遵照几条试探法准则。
因此,PFRA有很多函数也就不奇怪了。图17-3列出了PFRA的主要函数,箭头表示函数调用。
例如,try_to_free_pages()函数调用shrink_caches()、shrink_slab()和out_of_memory()三个函数。
正如你所看到的,PFRA有几个入口(entry point)。实际上,页框回收算法的执行有三种基本情形:
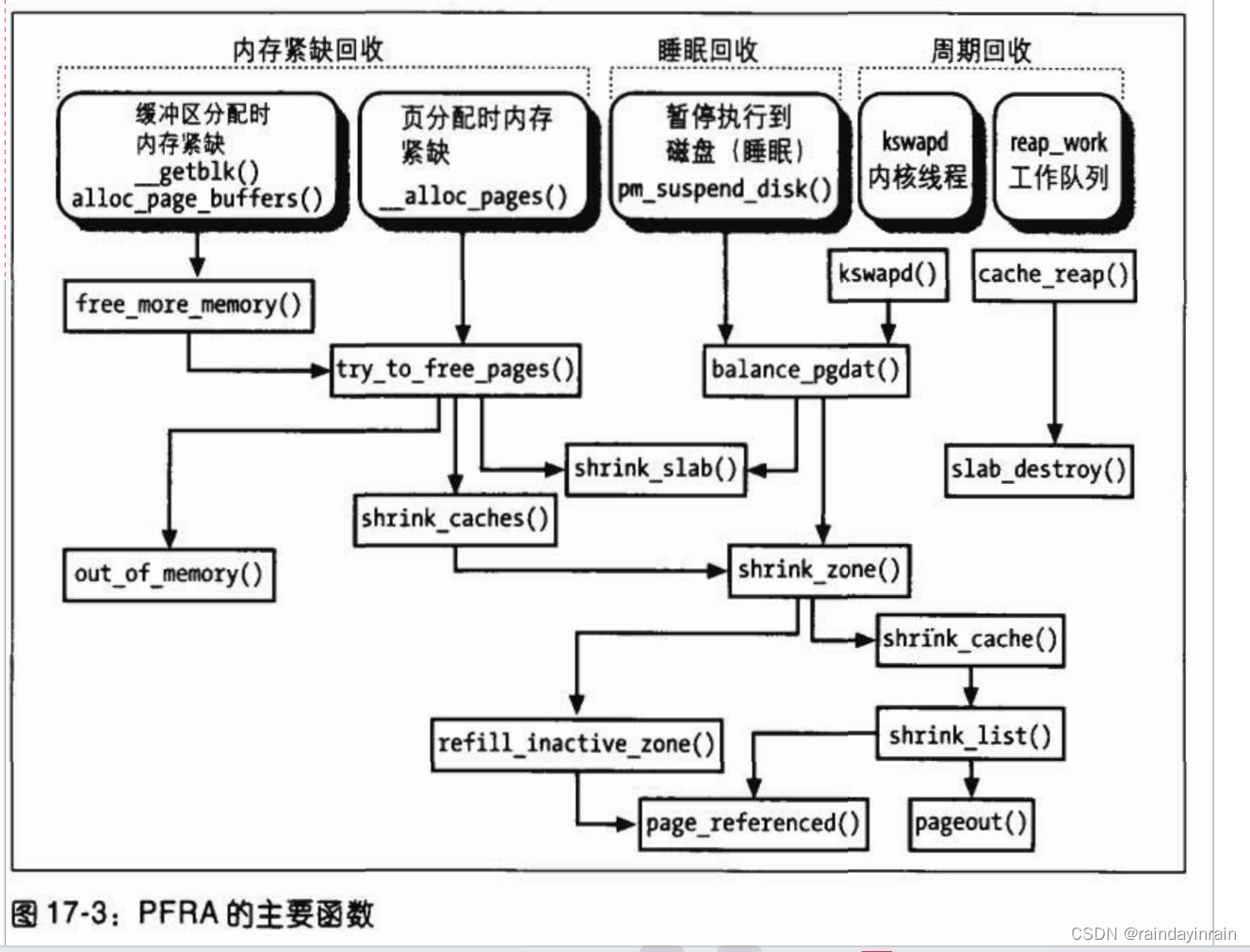
内存紧缺回收
内核发现内存紧缺
睡眠回收
在进入suspend-to-disk状态时,内核必须释放内存(我们不再进一步讨论这种情形)
周期回收
必要时,周期性激活内核线程执行内存回收算法
内存紧缺回收在下列几种情形下激活:
1.grow_buffers()函数(由__getblk()调用)无法获得新的缓冲区页(参见第十五章的“在页高速缓存中搜索块”一节)。
2.alloc_page_buffers()函数(由create_empty_buffers()调用)无法获得页临时缓冲区首部(参见第十六章的“读写文件”一节)。
3.__alloc_pages()函数无法在给定的内存管理区(memory zone)中分配一组连续页框(参见第八章中“伙伴系统算法”一节)。
周期回收由下面两种不同的内核线程激活:
1.kswapd内核线程,它检查某个内存管理区中空闲页框数是否已低于pages_high值的标高(参见后面的“周期回收”一节)。
2/events内核线程,它是预定义工作队列的工作者线程(参见第四章的“工作队列”一节);
PFRA周期性地调度预定义工作队列中的一个任务执行,从而回收slab分配器处理的位于内存高速缓存中的所有空闲slab(参见第八章的“slab分配器”一节)。
最近最少使用(LRU)链表
属于进程用户态地址空间或页高速缓存的所有页被分成两组:活动链表与非活动链表。它们被统称为LRU链表。
前面一个链表用于存放最近被访问过的页;后面的则存放有一段时间没有被访问过的页。显然,页必须从非活动链表中窃取。
页的活动链表和非活动链表是页框回收算法的核心数据结构。
这两个双向链表的头分别存放在每个zone描述符(参见第八章的“内存管理区”一节)的active_list和inactive_list字段,
而该描述符的nr_active和nr_inactive字段表示存放在两个链表中的页数。最后,lru_lock字段是一个自旋锁,保护两个链表免受SMP系统上的并发访问。
如果页属于LRU链表,则设置页描述符中的PG_1ru标志。
此外,如果页属于活动链表,则设置PG_active标志,而如果页属于非活动链表,则清PG_active标志。
页描述符的lru字段存放指向LRU链表中下一个元素和前一个元素的指针。
另外有几个辅助函数处理LRU链表:
add_page_to_active_list()
将页加入管理区的活动链表头部并递增管理区描述符的nr_active字段。
add_page_to_inactive_list()
将页加入管理区的非活动链表头部并递增管理区描述符的nr_inactive字段。
del_page_from_active_list()
从管理区的活动链表中删除页并递减管理区描述符的nr_active字段
del_page_from_inactive_list()
从管理区的非活动链表中删除页并递减管理区描述符的nr_inactive字段。
del_page_from_lru()
检查页的PG_active标志。依据检查结果,将页从活动或非活动链表中删除,
递减管理区描述符的nr_active或nr_inactive字段,且如有必要,将PG_active标志清0。
activate_page()
检查PG_active标志,如果未置位(页在非活动链表中),将页移到活动列表中,依次调用del_page_from_inactive_list()和add_page_to_active_list(),
最后将PG_active标志置位。在移动页之前,获得管理区的lru_lock自旋锁。
lru_cache_add()
如果页不在LRU链表中,将PG_lru标志置位,得到管理区的lru_lock自旋锁,调用add_page_to_inactive_list()把页插入管理区的非活动链表。
lru_cache_add_active()
如果页不在LRU链表中,将PG_lru和PG_active标志置位,得到管理区的lru_lock自旋锁,调用add_page_to_active_list()把页插入管理区的活动链表。
事实上,最后两个函数,lru_cache_add()和lru_cache_add_active()稍有些复杂。
这两个函数实际上并没有立刻把页移到LRU,而是在pagevec类型的临时数据结构中聚集这些页,每个结构可以存放多达14个页描述符指针。
只有当一个pagevec结构写满了,页才真正被移到LRU链表中。这种机制可以改善系统性能,这是因为只当LRU链表实际修改后才获得LRU自旋锁。
在LRU链表之间移动页
PFRA把最近访问过的页集中放在活动链表中,以便当查找要回收的页框时不扫描这些页。
相反,PFRA把很长时间没有访问的页集中放在非活动链表中。当然,应该根据页是否正被访问,把页从非活动链表移到活动链表或者退回。
显然,两个状态(“活动”和“非活动”)是不足以描述所有可能的访问模式的。
例如,假定日志进程每隔1小时把一些数据写入一个页中。尽管这个页是“不活动的”已经很长时间,但是访问使它变为“活动的”,
因此即使这一页在整整1小时内没有被访问,也不回收相应的页框。
当然,对这种问题并没有通用的解决方法,因为PFRA没有办法预测用户态进程的行为;不过,页不应该在每次单独的访问中就改变自己的状态似乎是合理的。
在页描述符中的PG_referenced标志用来把一个页从非活动链表移到活动链表所需的访问次数加倍;
也把一个页从活动链表移到非活动链表所需的“丢失访问”次数加倍(见下面)。
例如,假定在非活动链表中的一个页其PG_referenced标志置为0。
第一次访问把这个标志置为1,但是这一页仍然留在非活动链表中。第二次对该页访问时发现这一标志被设置,因此,把页移到活动链表。
但是,如果第一次访问之后在给定的时间间隔内第二次访问没有发生,那么页框回收算法就可能重置PG_referenced标志。
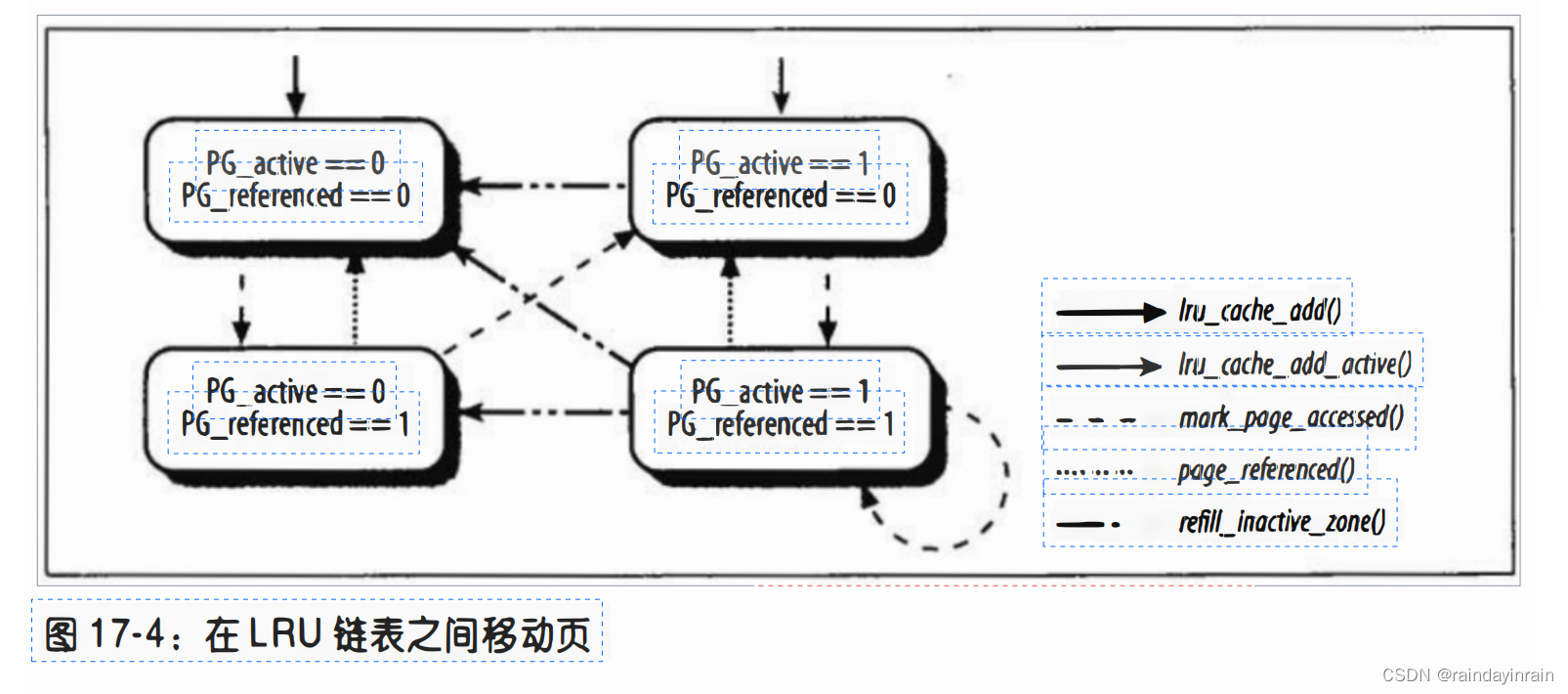
如图17-4所示,PFRA使用mark page_accessed()、page_referenced()和refill_inactive_zane()函数在LRU链表之间移动页。
在图中,包含有页的LRU链表由PG_active标志的状态表示。
mark_page_accessed()函数
当内核必须把一个页标记为访问过时,就调用mark_page_accessed()函数。
每当内核决定一个页是被用户态进程、文件系统层还是设备驱动程序引用时,这种情况就会发生。
例如,在下列情况下调用mark_page_accessed():
1.当按需装入进程的一个匿名页时(由do_anonymous_page()函数执行;参见第九章“请求调页”一节)。
2.当按需装入内存映射文件的一个页时(由filemap_nopage()函数执行;参见第十六章“内存映射的请求调页”一节)。
3.当按需装入IPC共享内存区的一个页时(由shmem_nopage()函数执行;参见第十九章“IPC共享内存”一节)。
4.当从文件读取数据页时(由do_generic_file_read()函数执行;参见第十六章“从文件中读取数据”一节)。
5.当换入一个页时(由do_swap_page()函数执行;参见后面的“换入页”一节)。
6.当在页高速缓存中搜索一个缓冲区页时(参见第十五章“在页高速缓存中搜索块”一节中介绍的__find_get_block()函数)。
mark_page_accessed()函数执行下列代码片段:
if(!PageActive(page)&& PageReferenced(page)&& PageLRU(page)){
activate_page(page);
ClearPageReferenced(page);
} else if(!PageReferenced(page〉)
SetPageReferenced(page);
如图17-4所示,该函数调用前,只有当PG_referenced标志置位,它才把页从非活动链表移到活动链表。
page_referenced()函数
PFRA扫描一页调用一次page_referenced()函数,如果PG_referenced标志或页表项中的某些Accessed标志位置位,则该函数返回1;否则返回0。
该函数首先检查页描述符的PG_referenced标志。如果标志置位则清0。
然后使用面向对象的反向映射方法,对引用该页的所有用户态页表项中的Accessed标志位进行检查并清0。
为此,函数用到三个辅助函数:page_referenced_anon()、page_referenced_file()和page_referenced_one(),
这与本章前面“反向映射”一节中的try_to_unmap_xxx()函数类似。
page_referenced()函数还会用到交换标记(swap token,参见本章后面“交换标记”一节)。
从活动链表到非活动链表移动页不是由page_referenced()函数,而是由refill_inactive_zone()函数实施的。
实际上,refill_inactive_zone()函数除此之外还有其他很多功能,因此我们要进行深入的讨论。
refill_inactive_zone()函数
如图17-3所示,refill_inactive_zone()函数由shrink_zone()调用,
而shrink_zone()函数对页高速缓存和用户态地址空间进行页回收(参见本章后面“内存紧缺回收”一节)。
此函数有两个参数:zone和sc。
指针zone指向一个内存管理区描述符;指针sc指向一个scan_control结构。
PFRA广泛使用scan_control这个数据结构,该结构存放着回收操作执行时的有关信息。表17-2中列出了它的字段。


refill_inactive_zone()函数的工作至关重要,因为,从活动链表将页移到非活动链表就意味着页迟早要被PFRA捕获。
如果函数的掠夺性过强,就会有过多的页从活动链表被移动到非活动链表。因此,PFRA就会回收大量的页框,系统性能会受到影响。
反过来,如果函数太懒惰,就没有足够的未用页来补充非活动链表,PFRA就不能回收内存。
为此,该函数可以调整自己的行为:开始时,对每次调用,扫描非活动链表中少量的页,
但是当PFRA很难回收内存时,refill_inactive_zone()在每次调用时就逐渐增加扫描的活动页数。
scan_control数据结构中priority字段的值控制该函数的行为(低值表示更紧迫的优先级)。
还有一个试探法可以调整refill_inactive_zone()函数行为。LRU链表中有两类页:属于用户态地址空间的页、不属于任何用户态进程且在页高速缓存中的页。
如前所述,PFRA倾向于压缩页高速缓存,而将用户态进程的页留在RAM中。
然而,每一种策略中都没有一个固定的黄金法则保证系统的高性能,
所以refill_inactive_zone()函数使用交换倾向(swap tendency)经验值,由它确定函数是移动所有的页还是只移动不属于用户态地址空间的页(注5)。
函数按如下公式计算交换倾向值:
交换倾向值=映射比率/2+负荷值+交换值
映射比率(mapped ratio)是用户态地址空间所有内存管理区的页(sc->nr_mapped)占所有可分配页框数的百分比。
mapped_ratio的值大表示动态内存大部分用于用户态进程,而值小则表示大部分用于页高速缓存。
负荷值(distress)用于表示PFRA在管理区中回收页框的效率。其依据是前一次PFRA运行时管理区的扫描优先级,
这个优先级存放在管理区描述符的prev_priority字段。负荷值与管理区前一次优先级的对应关系如下:

最后,交换值(swappiness)是一个用户定义常数,通常为60。
系统管理员可以在/proc/sys/vm/swappiness文件内修改这个值,或用相应的sysct1()系统调用调整这个值。
只有当管理区交换倾向值大于等于100时,页才从进程地址空间回收。
那么当系统管理员将交换值设为0时,PFRA就不会从用户态地址空间回收页,除非管理区的前一次优先级为0(这不大可能发生)。
如果系统管理员将交换值设为100,那么PFRA每次调用该函数时都会从用户态地址空间回收页。
下面是refill_inactive_zone()函数执行步骤的一个简要说明: