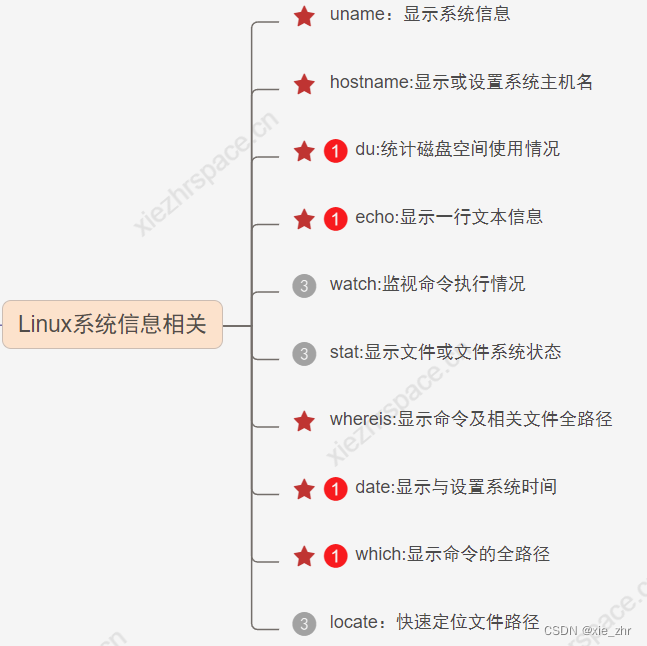
目录
- string类
- string类接口函数及基本用法
- 构造函数,析构函数及赋值重载函数
- 元素访问相关函数
- operator[]
- at
- back和front
- 迭代器iterator
- 容量操作
- size()和length()
- capacity()
- max_size
- clear
- empty
- reserve
- resize
- shrink_to_fit
- string类对象修改操作
- operator+=
- push_back
- append
- assign
- insert
- erase
- replace
- swap
- pop_back
- 字符串操作
- c_str
- substr
- find和rfind
- find_first_of,find_last_of,find_first_not_of,find_last_not_of
- 非成员重载函数
- 关系操作符
- 流插入,流提取
- getline
- 类型转换函数
- VS下string的结构
string类
在C语言中,字符串都是以‘\0’位结尾的一些字符的集合,为了方便操作,C标准库中已经给定了一些字符串操作函数,库中的函数与对象是分离的,不符合C++的封装思想
所以在C++中,string成为了一种容器,它有属于自己的结构和函数
如果想使用string类,需要#include<string>和using namespace std
我们时常把
string和STL中其他容器归到一起,但是实际上string不是STL中的,string类是在STL之前出现的用来专门解决字符串处理的问题
后来STL才在惠普实验室中发明出来
而string在C++标准库中,STL也在C++标准库中
string类接口函数及基本用法
构造函数,析构函数及赋值重载函数
string类中定义了7个构造函数
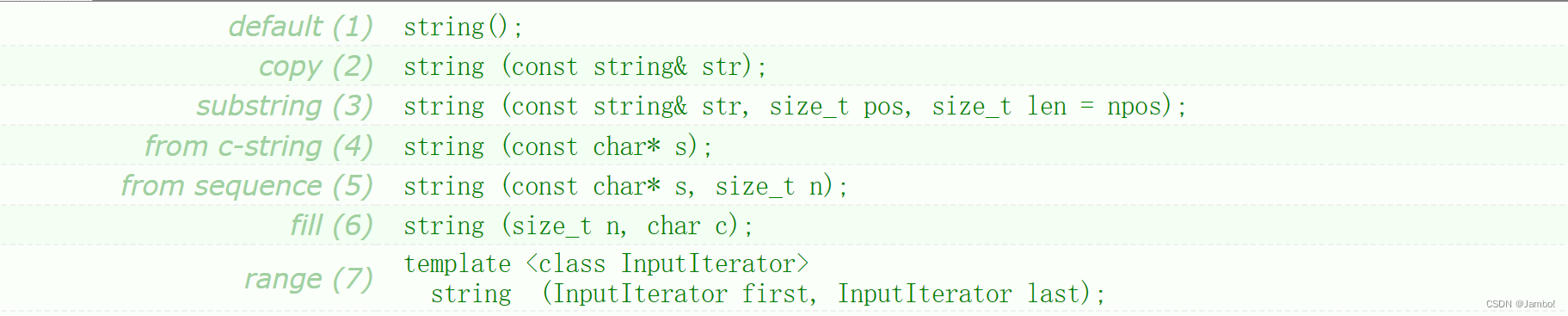
string(),无参构造,会构造出空的的string类对象,即空字符串string(const string& str),拷贝构造string(const string& str, size_t pos, size_t len = npos),用string类型对象str,从pos位置开始,len个长度的字串构造出2一个新对象 ,这里的参数len是一个缺省参数,它的缺省参数为npos,而这个npos是string中定义的成员常量,它的值为-1,len的类型为无符号整型,所以把-1赋值给len后,len的值就是整形的最大值,一个非常大的数。也就是如果传参时不传第二个参数,就从pos位置开始直到字符串结束进行构造。
npos:

string (const char* s),用一个字符串进行构造string (const char* s, size_t n)用字符串s的前n个字符进行构造string (size_t n, char c),在字符串中用连续复制n个字符c进行构造template <class InputIterator> string (InputIterator first, InputIterator last)用迭代器进行构造,按照[first,last)左闭右开,按照字节序进行构造
void test1()
{
string s1;//无参构造,空字符串
string s2(s1);//拷贝构造
string s3("abcdefg");//用一个字符串进行构造
string s4(s3, 2, 3);//在s3的2位置开始跨3个字符进行构造
string s5(s3, 2);//在s3的2位置构造到最后
string s6("abcde", 2);//复制"abcde"的前2个字符
string s7(10, 'a');//构造连续10个字符'a'
}
string的析构函数只有一个:
~string();
赋值重载函数

string类中实现了string对象,字符串,和字符的赋值重载
void test2()
{
string s1;
string s2("111");
s1 = "abcde";
s1 = s2;
s1 = 'a';
}
元素访问相关函数
operator[]
在C语言的字符串中,数据是存放在数组里的,我们可以使用[]访问某一下标处的字符
那么其实在C++中的string类中也可以,string类中实现了[]的重载

char& operator[] (size_t pos),可以进行读写操作
const char& operator[] (size_t pos) const只能进行读的操作,不可以进行写的操作
void test3()
{
string s1("abcdefg");
for (size_t i = 0; i < 7; i++)
{
//通过[]访问
cout << s1[i] << " ";
}
cout << endl;
for (size_t i = 0; i < 7; i++)
{
//通过[]修改
s1[i]++;
}
cout << s1 << endl;
}
在operater[]内部,对于越界的判断是使用assert(),如果越界,就断言

string s1 = "hello"; char s2[] = "hello"
对string对象s1和字符数组s2进行访问:s1[0],s2[0]
s1[0]和s2[0]虽然看上去相似,但是底层实现原理不同
s1[0]实际上是运算符重载s1.operator[](0)
s2[0]是指针的解引用*(s2+0)
at
char& at (size_t pos);
const char& at (size_t pos) const;
at函数和operatro[]相似,都是返回pos位置的字符的引用
void test4()
{
string s("123");
cout << s.at(0) << s.at(1) << s.at(2) << endl;
}
与operator[]的区别在于如果越界,at会抛异常
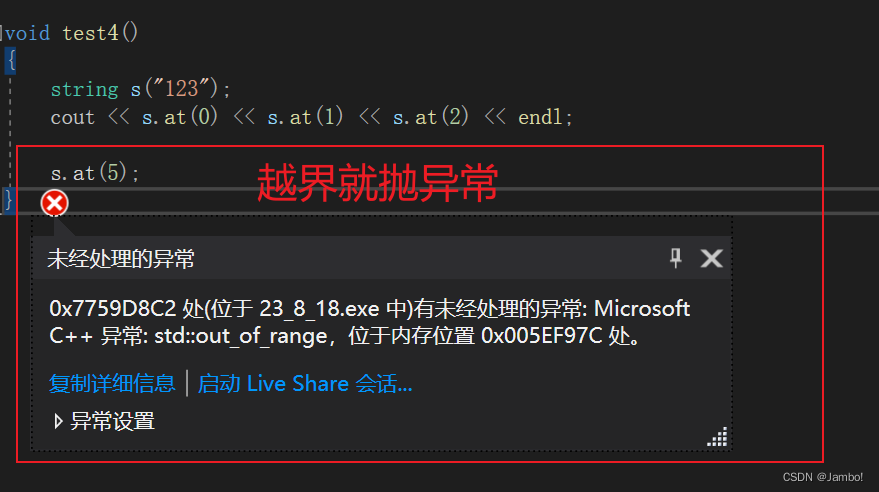
但是at函数我们很少用,对于访问字符串元素,我们operator[]用的多
back和front
char& back();
const char& back() const;
char& front();
const char& front() const;
back()返回字符串中最后一个字符的引用front()返回字符串中第一个字符的引用back和front都有可以支持读写和只读的2个函数- 空字符串不可以调用这2个函数
back和front是C++11中才出现的- 这2个函数不常用,完全可以用
operatro[]替代
迭代器iterator
迭代器iterator的作用是用来访问容器中的元素,不同的容器有属于自己的指针,迭代器像指针一样,但不一定是指针
在string容器中,迭代器是指针
迭代器iterator提供了一种统一的方式访问和修改容器的数据
- 普通迭代器:
begin(),end()
beign()指向字符串的第一个字符
end()指向字符串的最后一个字符的下一个位置
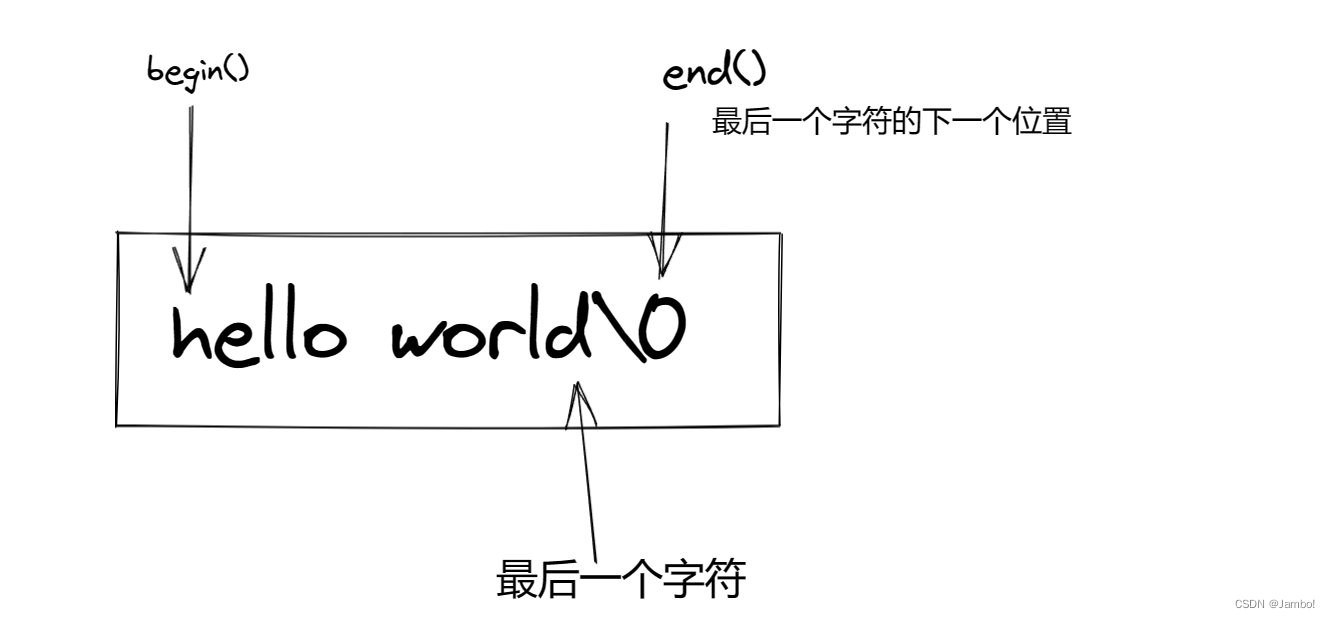
所以我们又有了一种可以遍历字符串的方法,就是使用迭代器
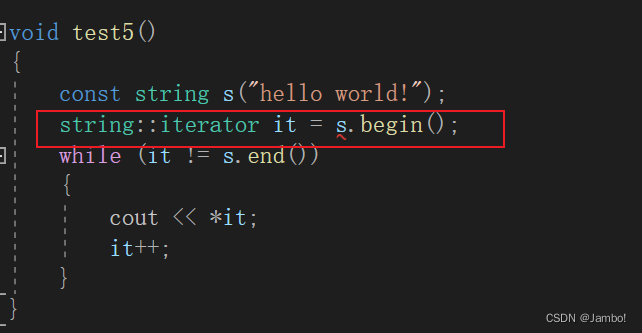
void test5()
{
string s("hello world!");
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it;
it++;
}
}
- 反向迭代器: rbegin(),rend()
rbegin()指向最后一个元素,rend()指向第一个元素的下一个元素
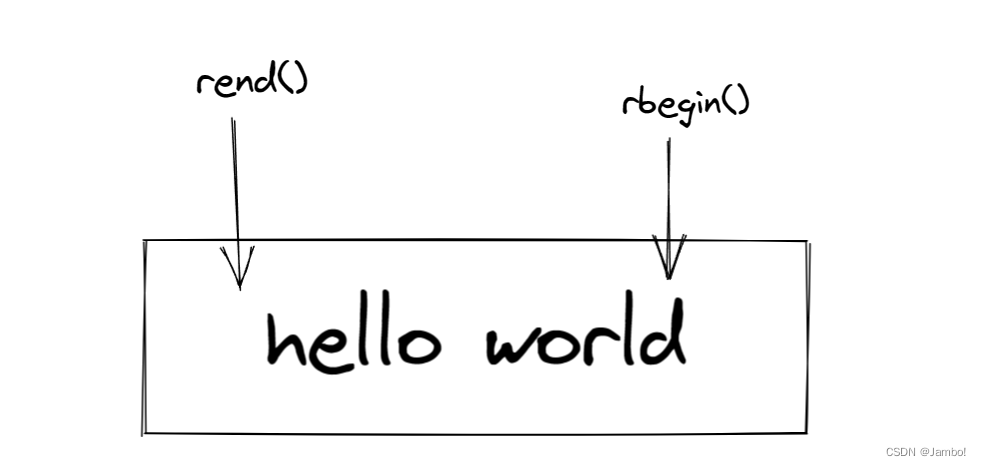
反向迭代器的类型是string::reverse_iterator
string::reverse_iterator rit = s.rbegin前面的类型写起来太长,我们可以用auto替代:auto rit = s.rbegin
void test5()
{
string s("hello world!");
auto rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit;
rit++;
}
}
- const迭代器
如果用普通类型的迭代器去接收const类型字符串的迭代器会报错
所以这里还有一种const迭代器,有四种:cbegin(),cend(),crbegin(),crend()
普通迭代器可读可写,const迭代器只能写
const string s("hello wolrd");
string::const_iterator cit1= s1.cbegin();
string::const_iterator cit2= s1.cend();
string::const_reverse_iterator crit1 = s1.crbegin()
string::const_reverse_iterator crit2 = s1.crend()
const迭代器是C++11中定义的
容量操作
size()和length()
size()和length()都返回字符串有效长度
在string类中,不把最后的
\0认为是有效长度,计算\0前面字符串的长度
2个函数作用是一样的,那么底层实现是一样的吗?
我们先转到库文件里看看源码
_NODISCARD _CONSTEXPR20_CONTAINER size_type length() const noexcept {
return _Mypair._Myval2._Mysize;
}
_NODISCARD _CONSTEXPR20_CONTAINER size_type size() const noexcept {
return _Mypair._Myval2._Mysize;
}
可以看到,2个函数的源码是相同的,那么为什么要定义2个作用一样的函数呢?
原因是,length()是从C语言中延续过来的
在有STL后,用length表示其他容器的大小不是特别确切,于是用size()函数返回容器的大小
为了兼容STL中的size()函数,所以在string中也定义了一个size()
capacity()
string类中是有capacity的,类似于顺序表,因为string需要扩容
capacity()的作用就是返回capacity
max_size
max_size()返回字符串最大尺度,但是在不同环境,不同平台下,max_size()返回的值不同
所以max_size(0很少用
clear
clear清空有效字符,使size为0,capacity不变
empty
判断字符串是否为空串
如果是空串返回true,否则返回false
reserve
void reserve (size_t n = 0);
reserve作用是改变capacity纯开空间,不会改变size
如果我们知道某一字符串需要多大的空间,那么就可以直接用reserve扩容那么大的空间,就不需要多次扩容了,减少了扩容时的消耗
n如果大于现有的容量,就会使capacity扩大到n(或者更大,这取决于编译器)
n如果小于现有的容量,缩小字符串容量是非约束性条件,容量是否缩小取决于平台和编译器
void test6()
{
string s("hello world");
cout << s.size() << endl;
cout << s.capacity() << endl;
s.reserve(20);
cout << "s.reserve(20)" << endl;
cout << s.size() << endl;
cout << s.capacity() << endl;
s.reserve(5);
cout << "s.reserve(5)" << endl;
cout << s.size() << endl;
cout << s.capacity() << endl;
}
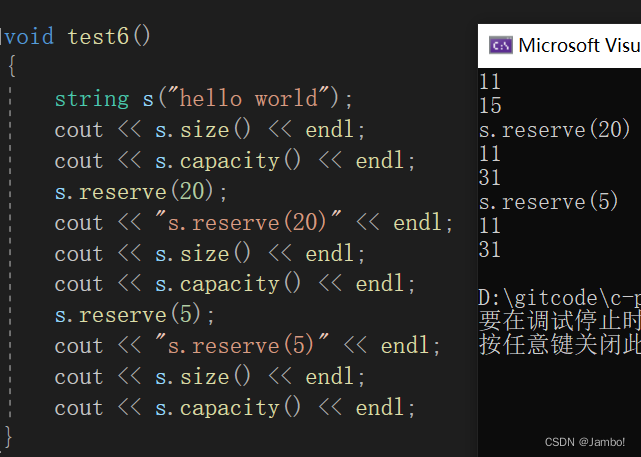
从上面的输出结果可以看出,reserve(20)最终被编译器处理,扩容到了31,编译器也没有处理reserve(5)的缩容量要求
在string中,capacity认为是有效字符容量,所以字符串结尾的
\0不算在其中
s.reserve(n)表面上是把容量阔为n,但是底层是扩大为n+1大小,就是为了容纳结尾的\0
resize
void resize (size_t n);
void resize (size_t n, char c);
resize改变
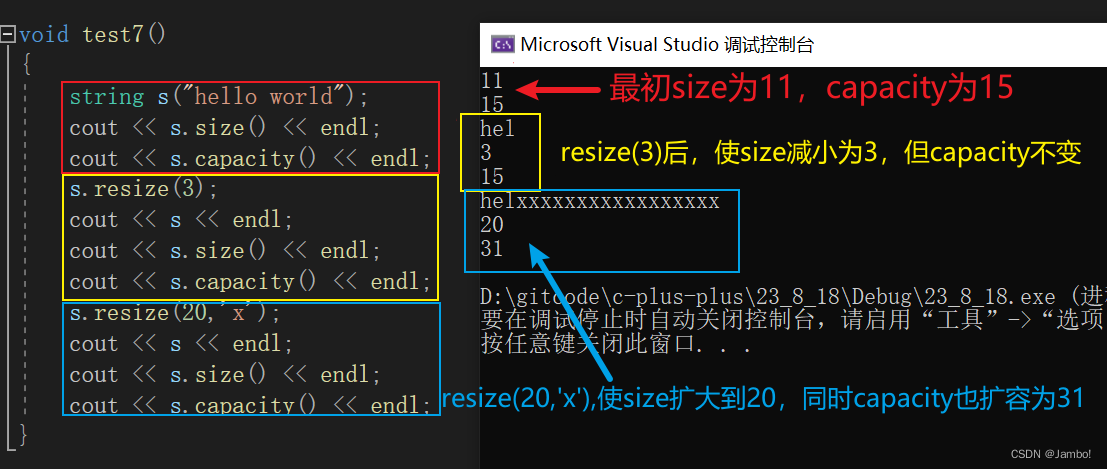
如果n比size小,就把字符串缩短到前 n 个字符,并删除 n 字符以外的字符,不会是capacity减小。
如果n比size大,则在字符串末尾插入所需的字符来扩展当前内容默认填充'\0,以达到 n 的大小。如果指定了 c,则新元素将被初始化为c 。在这个过程中如果容量满了,还会进行扩容
void test7()
{
string s("hello world");
cout << s.size() << endl;
cout << s.capacity() << endl;
s.resize(3);
cout << s << endl;
cout << s.size() << endl;
cout << s.capacity() << endl;
s.resize(20,'x');
cout << s << endl;
cout << s.size() << endl;
cout << s.capacity() << endl;
}
shrink_to_fit
要求字符串缩小容量,以适应其大小。
该请求是非约束性的,容器实现可以自由地进行其他优化,使字符串的容量大于其大小,是否减小capacity取决于编译器
此函数不会影响字符串的长度,也不会改变其内容。
shrink_to_fit是C++11中才有的
string类对象修改操作
operator+=
string& operator+= (const string& str);
string& operator+= (const char* s);
string& operator+= (char c);
operator+=的作用是在字符串后面追加一个字符串或字符
string& operator+= (const string& str)和string& operator+= (const char* s)是追加字符串
string& operator+= (char c)是追加一个字符
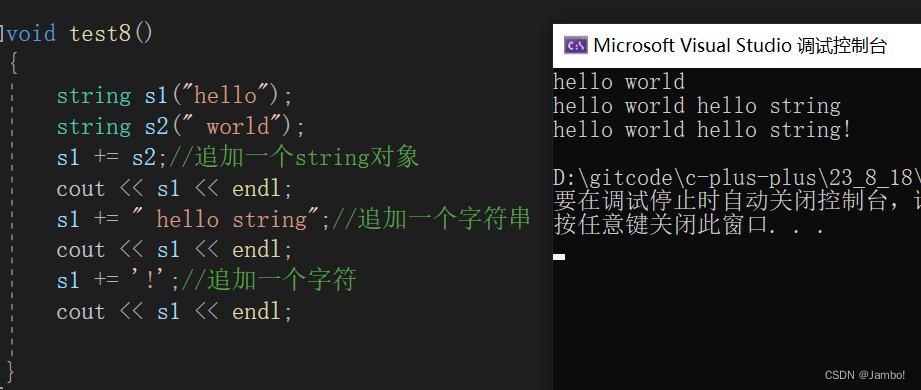
void test8()
{
string s1("hello");
string s2(" world");
s1 += s2;//追加一个string对象
cout << s1 << endl;
s1 += " hello string";//追加一个字符串
cout << s1 << endl;
s1 += '!';//追加一个字符
cout << s1 << endl;
}
push_back
void push_back (char c);
作用是在字符串后追加一个字符
void test8()
{
string s1("hello world");
s1.push_back('!');
cout<<s1<<endl;
}
结果输出:hello world!
append

作用是在字符串后面追加一个字符串
我们可以看到append重载了6种函数,我们可以通过参数判断出函数的用法,其实和构造函数是相同的
string& append (const string& str),在字符串后追加strstring& append (const string& str, size_t subpos, size_t sublen),在str的subpos位置开始,追加sublen长度的字符串string& append (const char* s),追加字符串sstring& append (const char* s, size_t n,追加字符串s的前n个字符string& append (size_t n, char c),连续追加n个字符ctemplate <class InputIterator> string& append (InputIterator first, InputIterator last);按顺序添加 [first,last] 范围内字符序列
void test9()
{
string s1;
string s2(" world");
s1.append("hello");//hello
s1.append(s2);//hello world
string s3;
s3.append(s2, 2, 5);//llo w
s3.append(5, 'x');//llo wxxxxx
s3.append("string", 4);//llo wxxxxxstri
s3.append(s1.begin(), s1.end());//llo wxxxxxstrihello world
}
assign

为字符串赋值,替换当前内容
根据参数我们也可以看出每个函数的用法,与构造函数和append函数类似
assign我们用的少,它的特点就是赋值+覆盖
void test10()
{
std::string str;
std::string base = "The quick brown fox jumps over a lazy dog.";
str.assign(base);
std::cout << str << '\n'; //"The quick brown fox jumps over a lazy dog."
str.assign(base, 10, 9);
std::cout << str << '\n'; // "brown fox"
str.assign("pangrams are cool", 7);
std::cout << str << '\n'; // "pangram"
str.assign("c-string");
std::cout << str << '\n'; // "c-string"
str.assign(10, '*');
std::cout << str << '\n'; // "**********"
str.assign(base.begin() + 16, base.end() - 12);
std::cout << str << '\n'; // "fox jumps over"
}
insert

在pos位置或迭代器p位置处字符前插入附加字符串
void test11()
{
string str = "to be question";
string str2 = "the ";
string str3 = "or not to be";
string::iterator it;
str.insert(6, str2); // to be the question
str.insert(6, str3, 3, 4); // to be not the question
str.insert(10, "that is cool", 8); // to be not that is the question
str.insert(10, "to be "); // to be not to be that is the question
str.insert(15, 1, ':'); // to be not to be: that is the question
it = str.insert(str.begin() + 5, ','); // to be, not to be: that is the question
str.insert(str.end(), 3, '.'); // to be, not to be: that is the question...
}
erase
string& erase (size_t pos = 0, size_t len = npos);
iterator erase (iterator p);
iterator erase (iterator first, iterator last);
- string& erase (size_t pos = 0, size_t len = npos),删除字符串中从字符位置 pos 开始并跨越 len 字符的部分,参数pos和len都是缺省参数,如果都传参,就会将字符串全部删除
- iterator erase (iterator p),删除迭代器p位置处的字符
- iterator erase (iterator first, iterator last),删除[first,last]区间中的字符部分
replace

用新内容替换字符串中从字符 pos 开始、跨 len 字符的部分(迭代器[i1,i2]区间字符的部分)
void test12()
{
std::string base = "this is a test string.";
std::string str2 = "n example";
std::string str3 = "sample phrase";
std::string str4 = "useful.";
//0123456789*123456789*12345
std::string str = base; // "this is a test string."
str.replace(9, 5, str2); // "this is an example string."
str.replace(19, 6, str3, 7, 6); // "this is an example phrase."
str.replace(8, 10, "just a"); // "this is just a phrase."
str.replace(8, 6, "a shorty", 7); // "this is a short phrase."
str.replace(22, 1, 3, '!'); // "this is a short phrase!!!"
}
swap
void swap (string& str);
交换2个字符串的值
void test13()
{
string s1("hello world");
string s2("let`s rock");
s1.swap(s2);
cout << s1 << endl;//let`s rock
cout << s2 << endl;//hello world
}
pop_back
void pop_back();
删除最后一个元素
void test13()
{
string s1("hello world");
s1.pop_back();
cout << s1; //“hello worl”
}
字符串操作
c_str
const char* c_str() const;
获取等价C的字符串
返回一个指针,指针指向一个字符串
void test14()
{
string s("let`s rock");
const char* str = s.c_str();
cout << str;//"let`s rock"
}
substr
string substr (size_t pos = 0, size_t len = npos) const;
返回子串
子串是对象中从字符位置 pos 开始、跨 len 字符(或直到字符串结束,以先到者为准)的部分。
find和rfind
find

在字符串中搜索参数指定序列的首次出现,如果找到了指定序列,返回指定序列首次出现的位置,如果没找到,返回npos
如果指定了 pos,只从pos位置开始(包括pos)向后进行搜索
参数n 指的是查找字符串前n个字符
下面我们划分一个网址的协议,域名,资源
void test16()
{
string url("https://blog.csdn.net/weixin_64116522?spm=1000.2115.3001.5343");
size_t pos1 = url.find("://");
if (pos1 != string::npos)
{
string protocol = url.substr(0,pos1);
cout << protocol << endl;
}
size_t pos2 = url.find("/", pos1 + 3);
if (pos2 != string::npos)
{
string domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << domain <<endl;
string uri = url.substr(pos2 + 1);
cout << uri << endl;
}
}
我们先从头开始搜索":\\",把找到的位置存放到pos1中,然后用substr函数提取处协议字串propocol
然后我们就要从blog.csdn.net/weixin_64116522?spm=1000.2115.3001.5343里面搜索/,也就是从pos1+3位置开始搜索,把找到的位置存放到pos2中,使用substr函数,从pos1+3位置开始,提取长度为pos2 - (pos1 + 3)的字串就是域名,剩下的就是资源了
rfind

在字符串中查找参数指定序列的最后一次出现。
如果指定了 pos,则搜索只包括从 pos 位置或之前开始的字符序列,而忽略从 pos 位置之后开始的任何可能的匹配。
find_first_of,find_last_of,find_first_not_of,find_last_not_of
size_t find_first_of (const string& str, size_t pos = 0) const;
size_t find_first_of (const char* s, size_t pos = 0) const;
size_t find_first_of (const char* s, size_t pos, size_t n) const;
size_t find_first_of (char c, size_t pos = 0) const;
size_t find_last_of (const string& str, size_t pos = npos) const;
size_t find_last_of (const char* s, size_t pos = npos) const;
size_t find_last_of (const char* s, size_t pos, size_t n) const;
size_t find_last_of (char c, size_t pos = npos) const;
find_first_of搜索字符串中与其参数中指定的任何字符相匹配的第一个字符。
如果指定了 pos,则搜索只包括 pos 位置上或之后的字符,而忽略 pos 之前可能出现的任何字符。
find_last_of搜索字符串中与参数中指定的任何字符相匹配的最后一个字符。
如果指定了 pos,则搜索只包括 pos 位置或之前的字符,忽略 pos 之后可能出现的字符。
void test17()
{
string str("helloiqa");
size_t pos1 = str.find_first_of("aeiou");
//返回"aeiou"中任一个字符在str中第一次出现的位置,第一次出现的是e,位置是1
cout << pos1 << endl;
size_t pos2 = str.find_last_of("aeiou");
//返回"aeiou"中任一个字符在str中最后一次出现的位置,最后一次出现的是a,位置是7
cout << pos2 << endl;
}
size_t find_first_not_of (const string& str, size_t pos = 0) const;
size_t find_first_not_of (const char* s, size_t pos = 0) const;
size_t find_first_not_of (const char* s, size_t pos, size_t n) const;
size_t find_first_not_of (char c, size_t pos = 0) const;
size_t find_last_not_of (const string& str, size_t pos = npos) const;
size_t find_last_not_of (const char* s, size_t pos = npos) const;
size_t find_last_not_of (const char* s, size_t pos, size_t n) const;
size_t find_last_not_of (char c, size_t pos = npos) const;
find_first_not_of 搜索字符串中第一个不匹配参数中指定字符的字符。
如果指定了 pos,则搜索只包括位置 pos 上或之后的字符,而忽略该字符之前可能出现的任何字符。
find_last_not_of 搜索字符串中最后一个不匹配参数中指定字符的字符。
如果指定了 pos,则搜索只包括 pos 位置或之前的字符,忽略 pos 之后可能出现的字符。
void test17()
{
string str("helloiqa");
size_t pos1 = str.find_first_not_of("aeiou");
//返回第一个不匹配"aeiou"中指定字符的字符,是h,位置为0
cout << pos1 << endl;
size_t pos2 = str.find_last_not_of("aeiou");
//返回最后一个不匹配"aeiou"中指定字符的字符,是q,位置为6
cout << pos2 << endl;
}
非成员重载函数
关系操作符

比较大小,这里不多说
流插入,流提取
string也重载了operator<<和operator>>
流提取就是输出字符串
void test18()
{
string str("hello");
cout<<str;//流提取运算符
}
流插入运算符
void test18()
{
string str;
cin>>str;//流提取运算符
}
这里有一个问题,如果输入一个连续的字符串,可以成功得从缓冲区中读取到
如果输入一个字符串中间有空格,就只会读取到空间前的部分

这时就需要用到getline函数了
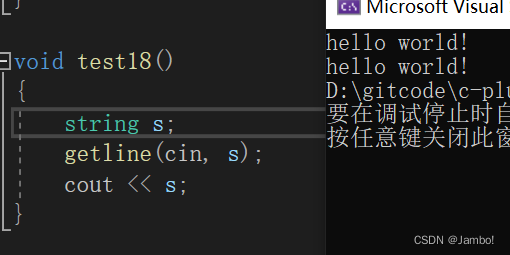
getline
istream& getline (istream& is, string& str, char delim);
istream& getline (istream& is, string& str);
getline(cin,s),这样就可以读取到空格后面的字符串了
类型转换函数
string类中还内置一些类型转换函数

VS下string的结构
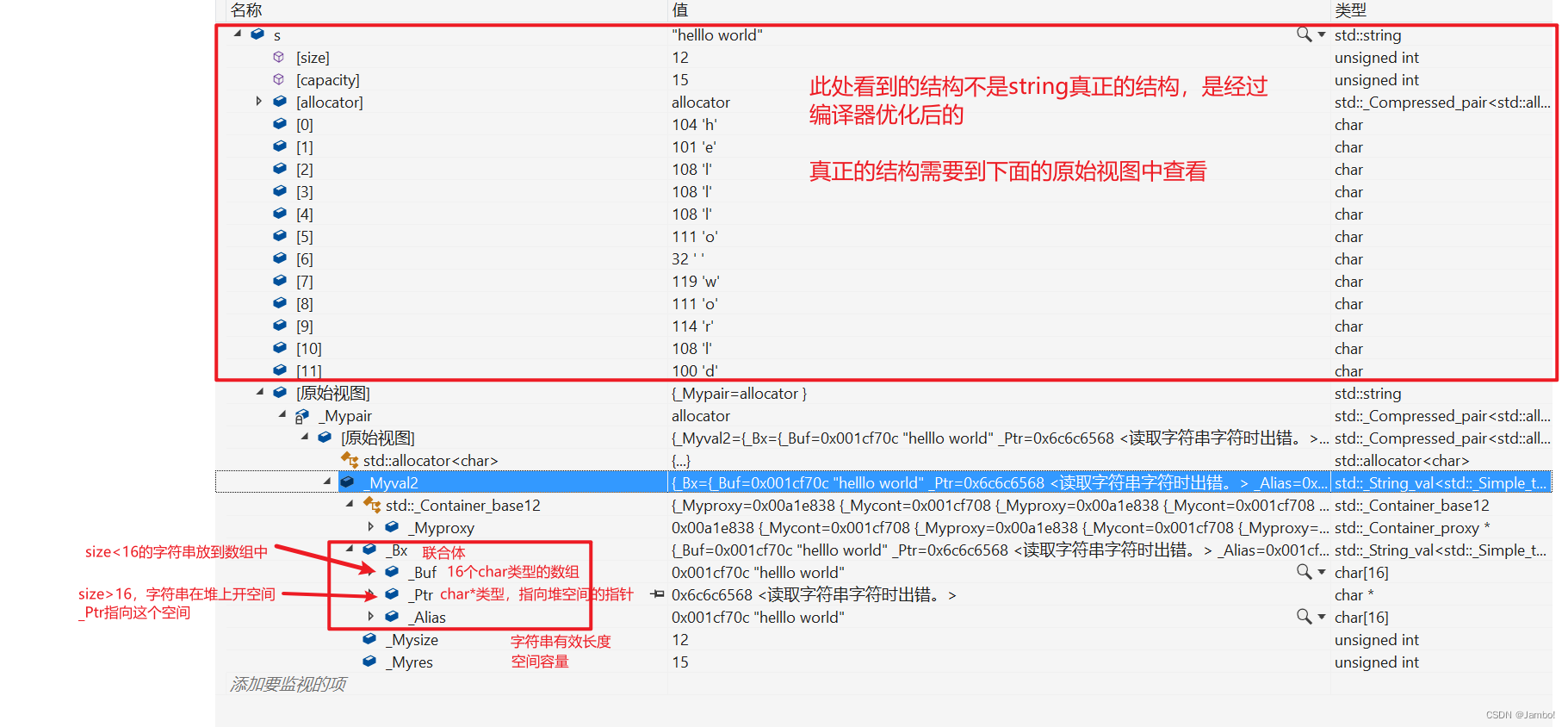
string总共占28字节,内部结构是比较复杂的
有一个联合体,联合体用来定义string中字符串的存储空间
- 当字符串长度小于16时,使用内部固定的字符数组存放
- 当字符串长度大于16时,从堆上开空间,只在联合体内存放一个指向堆空间的指针
- 这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高
- 还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量




![[ MySQL ] — 常见函数的使用](https://img-blog.csdnimg.cn/8039b9ae158b43a7a34ff8a79088bf00.png)