一、说明
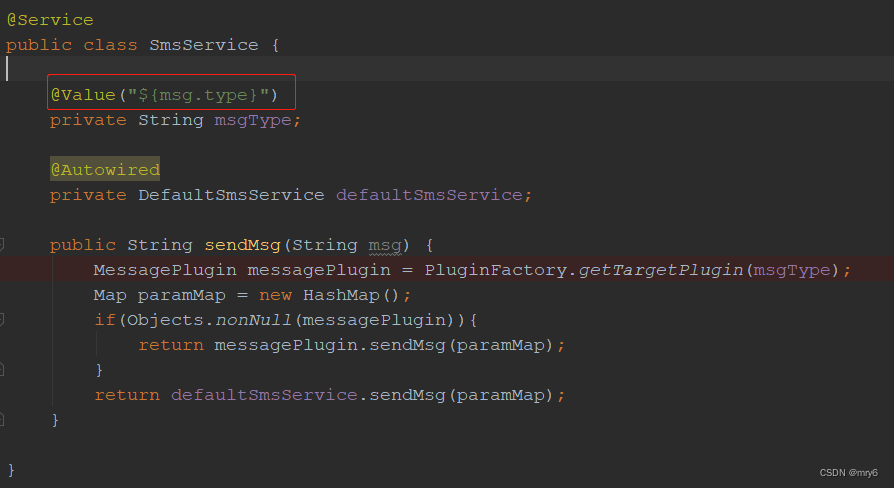
本文介绍了一个示例,说明如何使用 spaCy(用于 NLP 的领先开源 Python 库)从用户输入中提取含义。
二、如何从用户输入中提取含义
以编程方式从用户输入中提取含义可能非常具有挑战性,但并非不可能。很明显,你不能依赖句子中单个单词的含义——同一个单词可能会表达不同的含义,这取决于它在特定句子中的句法功能。这可以通过示例来最好地理解。请看以下两句话:
I’d like to order a cake.
I want to cancel my order. 在这两个话语中,你可以看到“顺序”一词。然而,在每种情况下,它都有不同的句法功能并具有不同的含义。在第一种情况下,“order”是一个动作(传递)动词,作用于名词“蛋糕”——句子的直接宾语。相比之下,第二个话语中的“order”是接收句子动作的名词——也就是说,它充当句子的直接宾语,其中“取消”是传递动词。
句子中单词的语言特征(如上例中的及物动词或直接宾语)也称为语言特征。spaCy 会自动为应用了 spaCy 文本处理管道的句子中的每个标记分配语言特征。然后,分析语言特征可以帮助识别这个特定句子中单词的含义。我们将在本文后面的 在 NLP 中使用语言特征 部分中讨论如何使用语言特征来完成意义提取任务。
三、准备您的工作环境
若要按照本文中提供的代码进行操作,需要在计算机上安装以下软件组件:
python 2.7+∕3.4+
spaCy v2.0+
预先训练的spaCy英语模型
您可以在相应的站点上找到安装说明。确保环境准备就绪的最快方法是,可以在 Python 会话中输入以下代码行:
import spacy
nlp = spacy.load('en') 如果一切正常,您应该没有错误消息。
四、在 NLP 中使用语言特征
功能(如词性标记和句法依赖关系标签)专门设计用于支持开发能够智能处理原始文本的应用程序。以下脚本说明了如何使用 spaCy 提取句子中每个单词的语言特征:
import spacy
nlp = spacy.load('en')
doc = nlp(u'I have to send them a notification.')
for token in doc:
print(token.text, token.pos_, token.tag_, token.dep_)在上面的脚本中,您提取并输出所提交句子中每个标记的粗粒度词性标签 (pos_)、细粒度词性标签 (tag_) 和语法依赖关系标签 (dep_)。因此,脚本应提供以下输出(为便于阅读而列出):
I PRON PRP nsubj
have VERB VBP ROOT
to PART TO aux
send VERB VB xcomp
them PRON PRP dative
a DET DT det
notification NOUN NN dobj
. PUNCT . Punct 如果你不熟悉 spaCy,上面分别在第三列和第四列中输出的细粒度词性标签和语法依赖关系标签可能看起来有点混乱。要了解这些列中的值的含义,您可以在 Data formats · spaCy API Documentation 或使用 spacy.explain() 函数查看 spacy 的文档,该函数返回给定语言特征的描述。在下面的循环中,您将输出示例句子中每个标记的细粒度词性标记的描述:
for token in doc:
print(token.text, spacy.explain(token.tag_)) 这应该会给你以下输出:
I pronoun, personal
have verb, non-3rd person singular present
to infinitival to
send verb, base form
them pronoun, personal
a determiner
notification noun, singular or mass
. punctuation mark, sentence closer 同样,您可以使用 spacy.explain() 函数获取粗粒度词性标记和语法依赖关系标签的说明。
五、从话语中提取意向
现在让我们看一个示例,说明如何利用语言功能从用户输入中提取含义。假设需要从提交的语句中提取意向。例如,点餐聊天机器人的用户提交以下语句:
I want to order a photo cake. 显然,“订单”和“蛋糕”这两个词最能描述这句话所表达的意图。在这种特殊情况下,这些词分别表示及物动词和直接宾语。实际上,在大多数情况下,在确定请求话语中表达的意图时,传递谓词/直接宾语对是最具描述性的。从图表上看,这可能如下所示:

![]()
在许多请求话语中,及物谓词及其直接宾语最能描述短语的意图。
上图中描述的操作可以在使用 spaCy 的 Python 脚本中轻松执行,如下所示:
import spacy
nlp = spacy.load('en')
doc = nlp(u'I want to order a photo cake.')
for token in doc:
if token.dep_ == 'dobj':
print(token.head.text + token.text.capitalize()) 在此脚本中,将文本处理管道应用于示例句子,然后循环访问标记,查找依赖项标签为 dobj 的令牌。找到它后,您可以通过获取直接对象的句法头来确定相应的传递动词。最后,连接及物动词及其直接宾语,以单个单词的形式表达意图(这通常是处理脚本的要求)。
因此,脚本应生成:
orderCake 在实际应用程序中,用户可能会对每个意向使用一组广泛的短语。这意味着实际应用程序必须识别用户输入中的同义短语。有关这些细节,您可以查看我的新书《使用Python的自然语言处理》,其中包括许多关于使用spaCy执行不同NLP任务的示例。
此外,在我最近为 Oracle 杂志撰写的 Oracle 数字助理技能的生成意图和实体文章中可以找到意图提取技术在实践中可能使用的真实示例。