前言
相信大家对扩散模型早有耳闻,其着实大火了一把,效果也确实是好。今天写这篇博客的主要动机就是想真正进入到代码层面去看看其到底是怎么实现的。
其实在看完代码后,会觉得其实现的非常简单,而且也会对原理的理解有一个更好的正反馈。
多说一句,在扩散模型能够生成这么惊艳的图片大背景下,已经有大批研究员悄然开始了研究生成视频的方向,笔者之前也写过一篇,感兴趣的可以穿梭:
https://zhuanlan.zhihu.com/p/570332906
另外其实网上还有很多扩散的代码,大体上核心的地方都一样,笔者在文末也贴出了一些相关的博客,都讲的很好,大家觉得不过瘾的话,可以多看几次。
paper: https://arxiv.org/pdf/2006.11239.pdf
TF版:https://github.com/hojonathanho/diffusion
pytorch版: https://github.com/lucidrains/denoising-diffusion-pytorch
本篇以pytorch版为demo介绍其实现~
原理
在看代码之前,还是得先大体了解一下原理,即了解一下到底我们要实现什么东西?如果大家实在想看细节推导,可以直接看文末的一些资料,这里仅从宏观上帮大家理一下我们要做的事。

首先上图的算法1和2就是具体的train和inference过程,其实要得到这两个公式是有一系列复杂的数学推导的。
但是 我们需要从大的方面来理顺整个逻辑也即我们到底是要做什么:
-
训练阶段:
扩散模型的原理是先扩散再恢复,而我们的目标也即loss就是在恢复阶段使得最终的图像尽可能的接近原图,假设生成原图的概率是p,那loss用数学公式来写的话就是logp,记住哈,一切是从这个源头出发进行推导,经过一系列复杂的推导就得到了上图左边的最终公式。
其实这里面是有两个过程的,一个是扩散的前向过程,另外一个反向过程,一般博主的讲解基本都是会进行推导,这里说实话有点麻烦,大家可以耐心去看,但是总的来说我们最终就是会得到左边的这个优化loss,这也是整个最后的结论,也是落实到代码层面真正要编写的逻辑。
再看一下最后这个公式,其实 就是对标准正态分布的一个采样, 就是原始图经过t时刻扩散后的样子即 , 就是我们的网络,也即要优化的参数,具体的是一个Unet网络,可以看到其把 和t作为输入,来预测当前时刻的噪声,进而和真正的采样噪声 做loss。
至于公式里面的 其实是个常数,其是一系列 连乘,而 是由 得到的,而 在论文中是0.0001~0.002,在前向扩散中不断增大,所以 越来越小,也即越到后面加噪声的力度越来越大。
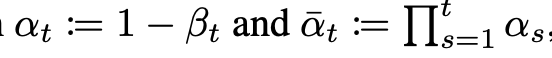
-
推理阶段:
从上面可以看到,训练阶段本身是在训练一个噪声预测模型,具体的就是给定 和t,其就能预测出由 到 这一过程所叠加的噪声。
有了这个噪声预测模型我们就可以知道任意时刻t的噪声,然后再恢复阶段就不断的减噪即一步一步的去噪直到恢复到原图就行啦。
所以看一下上图右边的公式,其实是一个for循环,在一步一步去噪。
大家在看公式的时候,可能还会注意到 ,它其实是
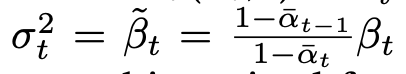
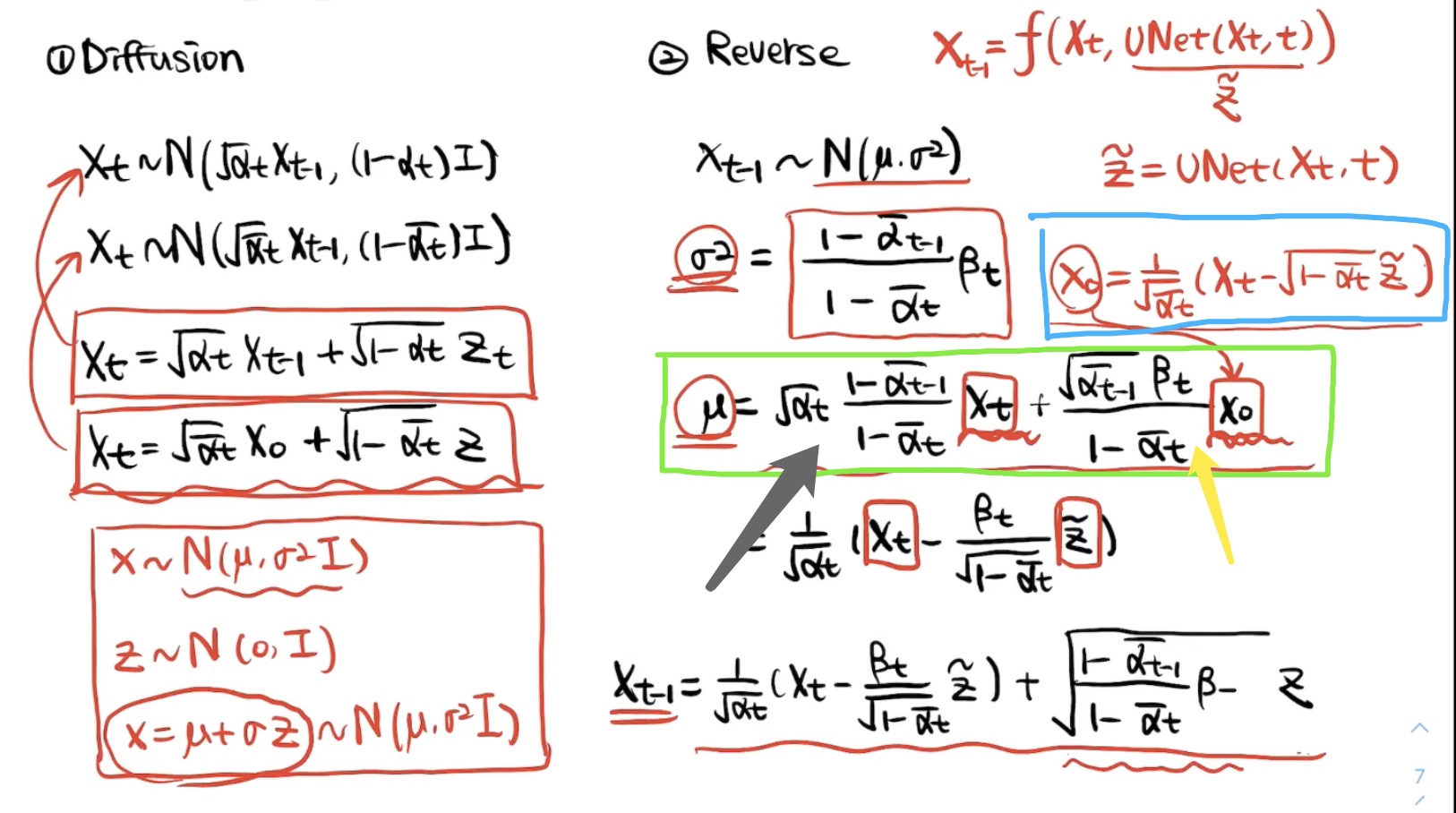
另外再看一下inference阶段对应的这个最后结论性公式的形式

可以把红色框的看成一个均值, 是方差
我们知道假设有一个变量z服从标准的正态分布 ,如果 , 那x也是个正态分布且服从
所以 服从
这个公式看着复杂,其实 就是模型预测出来的噪声,其他的都是定值,都是 和 变化过来的值。
所以可以这么理解:inference阶段的每一步 其实都是一个均值+方差的过程,这个均值其实是上一步 减去模型预测的噪声得到的,当然了还需要加上点方差扰动,可以看到当t==0的时候,也就是最后一步的时候,z=0了,就不需要加方差扰动了,因为已经是最终的清晰照片啦。
其实在看最后代码实现的时候会发现,在inference这里,其实是使用了一个推导的中间过程的(具体可以看文末第一个视频),实现均值的时候是用了绿色框的部分,当然了方差还是用了上面讲的。
-
小结
原理这里我们并没有讲解复杂的推导过程,而是集中精力梳理了一下最终的结论或者说最终落地代码要实现的公式。
总的来说训练阶段就是在训练一个噪声预测器,inference阶段就是在不断的减噪声(训练好的模型预测出来的),且本质上每一步都是个正太分布。
其实要看懂扩散模型复杂的理论部分和代码实现,需要牢牢铭记两个参数和一个分布即可,参数是 和 、分布是标准正态分布。其实 ,所以真正的变量只有一个那就是 ,它是什么呢?它就是个序列,一般有两种即线性和余弦,代码最后用了线性递增序列,代表着随着时间所加噪声的力度越来越大,而具体加的噪声就是标准正态分布。
上面最后这个结论的公式中所有的符号含义都是由 和 变化出来的或者说是 的一个函数,一切的一切都是由 变化得到的,是一个定值,是一个常数!!!
代码
终于要实际看看怎么实现的了。
核心代码全部在这个py文件下看到
https://github.com/lucidrains/denoising-diffusion-pytorch/blob/main/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
这里比较关键的就是GaussianDiffusion和Unet这两个类,前者可以实际看到loss的实现以及推理阶段的实现,后面就是具体的噪声预测模型也即Unet。
-
train loss
看GaussianDiffusion的forward方法,可以看到其是随机抽取了一个t,即打算扩散多少步,然后调用了self.p_losses了
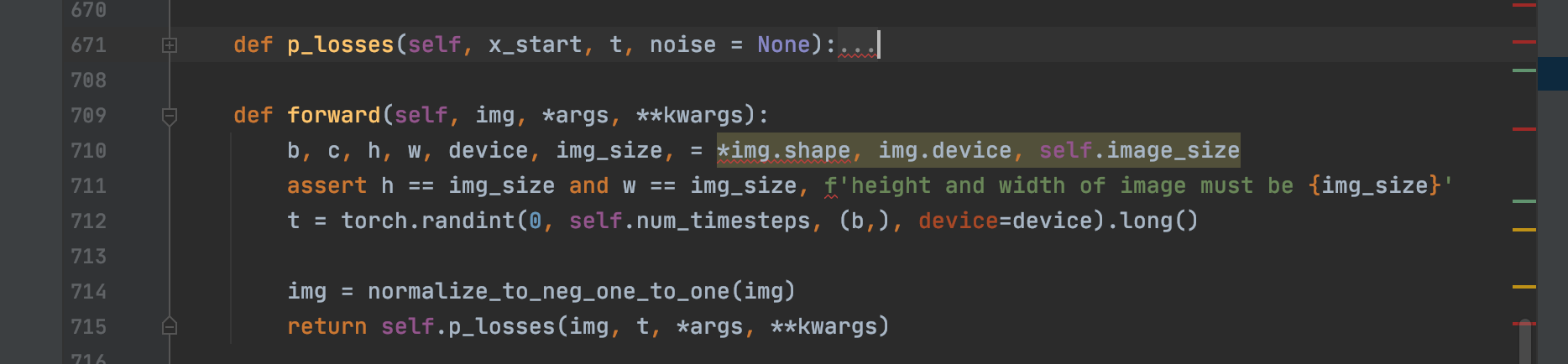
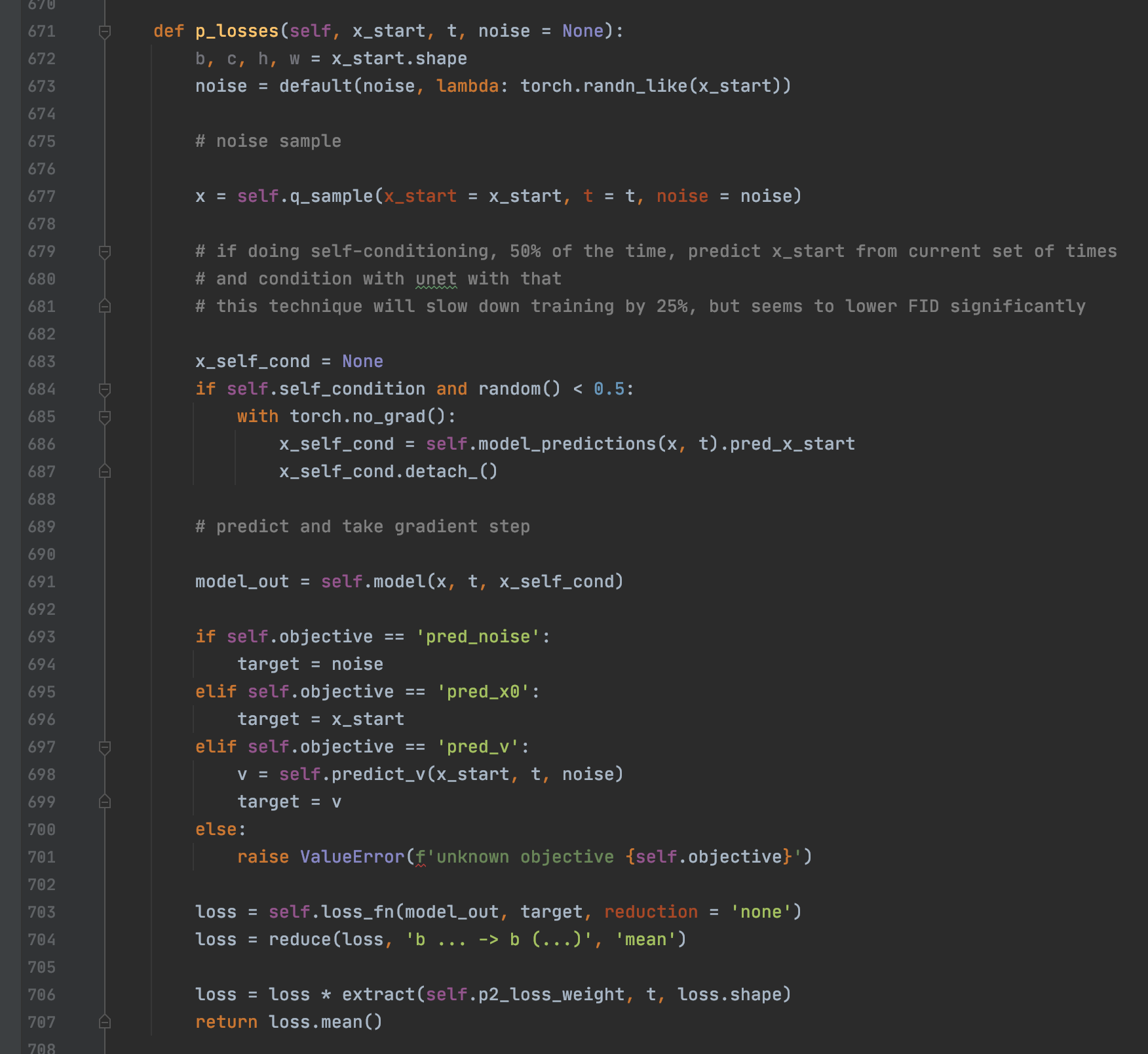
接着我们看self.p_losses,这个就是核心代码实现的逻辑了,我们仔细看。
首先第673行的noise就是真正的采样噪声 ,深入到default函数就可以看到其就是从标准正态分布随机采样得到的。
677行self.q_sample的返回值x其实就是 。同时可以看到691行把x和t作为输入给模型self.model,模型输出model_out其实就是模型预测的噪声。703就是具体的loss啦,就是把预测当前时刻的噪声和的采真正样噪声进行l1作为loss。
到目前为止都比较清晰,其中self.model就是Unet,下面我们来看看self.q_sample是怎么实现的,657行其实就是
的实现也即
,其中x_start就是
也即原始图片;self.sqrt_alphas_cumprod就是
,self.sqrt_one_minus_alphas_cumprod就是
,是不是和论文中的公式严丝合缝的对上啦! 
那么我们再看看self.sqrt_alphas_cumprod和self.sqrt_one_minus_alphas_cumprod具体是什么?self.sqrt_alphas_cumprod是458行的alphas_cumprod的开方,其实alphas_cumprod就是 ,从这里也可以实际看到 就是一系列alphas即 的连乘

alphas具体如下,可以看到是由1-betas得到的,这里的betas就是论文中的

其中 具体是在linear_beta_schedule实现的,可以清楚的看到是一个线性递增序列torch.linspace

-
inference
看GaussianDiffusion的sample方法, 本质上是看self.p_sample_loop这个函数

从这里可以清晰的看到,确实是个for函数,且每一步主要调用了 self.p_sample,所以主逻辑是写在 self.p_sample里面的,同时从585行也可以看到 其实就是从标准正态分布里面随机抽样一个作为恢复阶段最初始的图像,然后一步步去噪。
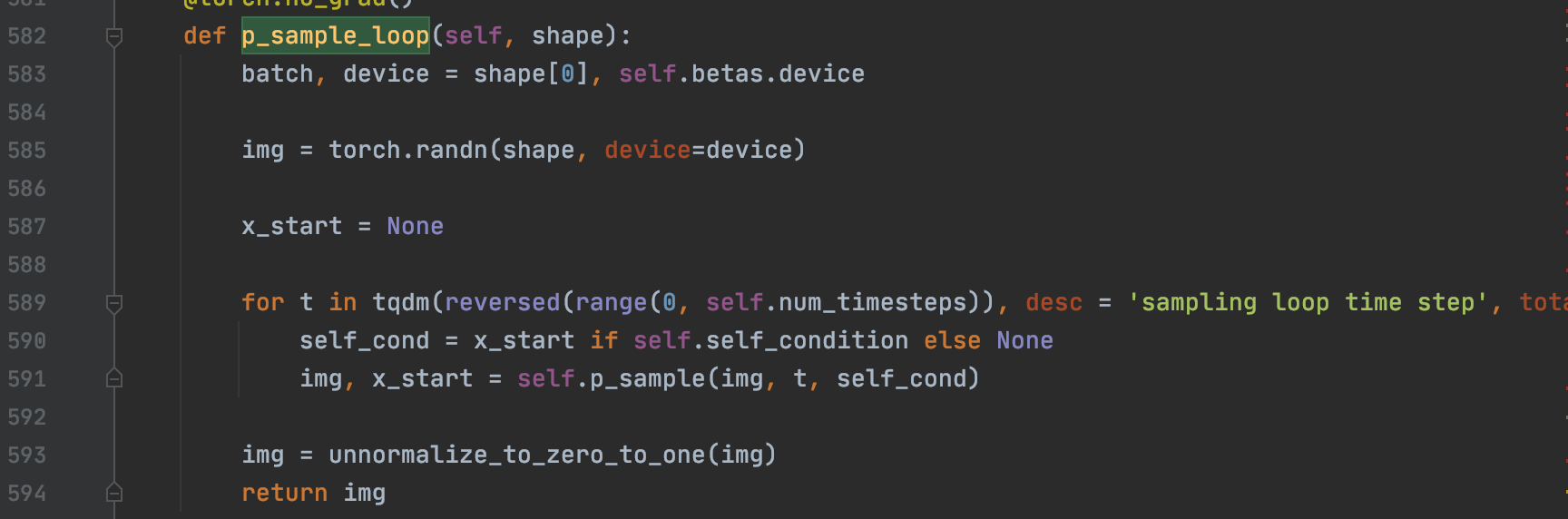
self.p_sample函数如下,从578行一眼就可以看到其实就是个均值+方差的过程(和我们原理一节中讲的一模一样),其中的noise就是个标准的正态分布采样也即论文中的 ,model_mean和(0.5 * model_log_variance).exp()分布代表论文中的 和 .
同时577行也可以看到当是最后一步后就会把方差置0(和理论部分讲的一样)

接着我们看model_mean和(0.5 * model_log_variance).exp()的实现,可以看到关键都是由self.p_mean_variance这个函数生成的model_mean和model_log_variance,其中self.p_mean_variance里面的核心函数是q_posterior,可以看到model_mean和model_log_variance最后对应的其实是posterior_mean和posterior_log_variance_clipped。
其中posterior_mean的代码在523-353
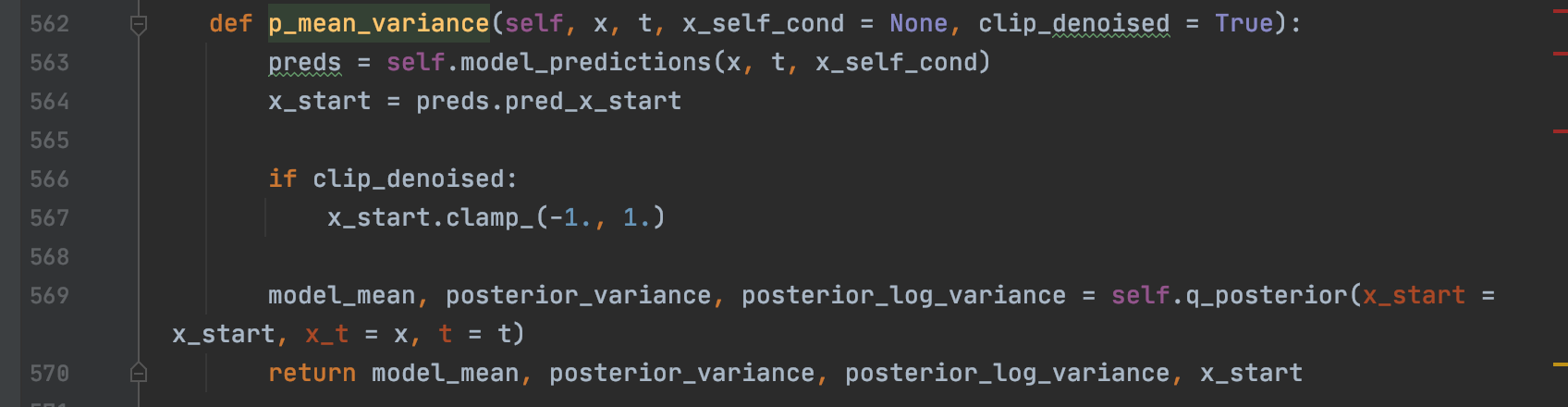

那么x_start到底是什么呢?我们还是再把开头的原理这张图搬过来,其实就是图中绿色框中的 ,其具体实现是在predict_start_from_noise这个函数,可以看到是和天蓝色框实现一一对应的

接着我们回到代码的q_posterior函数即523-353看,posterior_mean_coef1其实就是上面公式的黄色箭头,posterior_mean_coef2就是上面公式的灰色箭头,具体实现为,可以看到都是一一对应的:

最后看posterior_log_variance_clipped即论文的中 最后可以追踪到posterior_variance,可以看到和论文中的公式是一模一样的。

以上就是均值+方差的具体实现啦
-
小结
到此我们已经看完了扩散模型真正核心那部分代码的全部实现了,最后应该还有个Unet网络和一些train流程的代码,这个应该不难,感兴趣的小伙伴可以自行看看~
一些解读博客
https://www.bilibili.com/video/av601295714/?vd_source=247c686ab5fac4b46ead87ac455ab963
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/124641910
https://zhuanlan.zhihu.com/p/572770333
https://blog.csdn.net/sunningzhzh/article/details/125118688
总结
(1)扩散模型的原理不难(一点点加噪再一点点去噪),代码实现也不难,难的是数学推导即理论那部分,推导出了最后的结论性公式,代码直接对着写就可以啦。
(2)我们知道最终的文生图其实是根据文字生成图,也就是说在inference阶段其实是有条件地去噪的,怎么把这个“有条件”加进去是关键,甚至我们这里的文字可以替换成其他的外部信号,这部分逻辑大家可以看Unet网络,后面有时间再写写这块吧。
(3)大家可以把这块代码消化消化,可以不管细节,但是模块的大致逻辑要清楚,起码知道它是在求啥,然后往自己的场景套一套这套代码(扩散模型)试试效果。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布



![[附源码]Python计算机毕业设计飞羽羽毛球馆管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/a3b15daef2cb4ab881d9ee97f7ebbb57.png)