👏作者简介:大家好,我是爱敲代码的小王,CSDN博客博主,Python小白
📕系列专栏:python入门到实战、Python爬虫开发、Python办公自动化、Python数据分析、Python前后端开发
📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
🔥🔥🔥 python入门到实战专栏:从入门到实战
🔥🔥🔥 Python爬虫开发专栏:从入门到实战
🔥🔥🔥 Python办公自动化专栏:从入门到实战
🔥🔥🔥 Python数据分析专栏:从入门到实战
🔥🔥🔥 Python前后端开发专栏:从入门到实战
目录
内存管理机制
Python缓存机制
垃圾回收机制
分代回收机制
内存管理机制

Python是由C语言开发的,底层操作都是基于C语言实现,Python中创建每个对象,内部都会与C语言结构体维护一些值。
源码下载,https://www.python.org/
将压缩文件减压,可以看到有很多文件,主要关心两个(Include、 Objects) 在Include目录下object.h中可以查看创建对象的结构体。
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
PyTypeObject *ob_type;
} PyObject;typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;在创建对象时,每个对象至少内部4个值,PyObject结构体(上一个 对象、下一个对象、类型、引用个数)。
有多个元素组成的对象使用PyVarObject,里面由:PyObject结构体(上一个对象、下一个对象、类型、引用个数)+Ob_size(items=元素,元素个数)。
环状双向链表refchain
在python程序中创建的任何对象都会被放在refchain链表中。
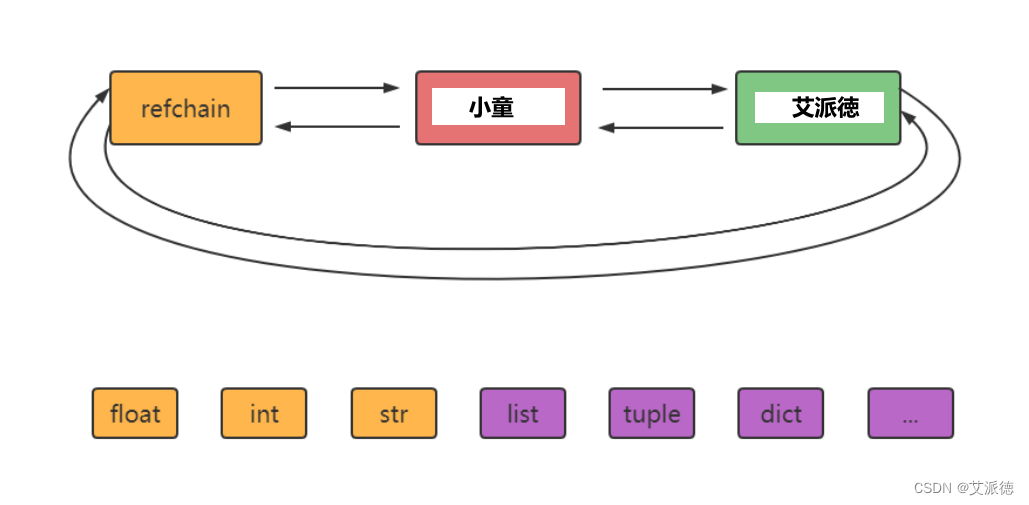
类型封装结构体
f = 3.14
'''
内部会创建:
1.开辟内存
2.初始化
ob_fval = 3.14 值
ob_type = float 类型
ob_refcnt = 1 引用数量
3.将对象加入到双向链表refchain中
_ob_next = refchain中的上一个对象
_ob_prev = refchain中的下一个对象
'''Python缓存机制

小整数对象池
一些整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间。
Python 对小整数的定义是 [-5, 257) 这些整数对象是提前建立好的,不会被垃圾回收。在一个 Python 的程序中,所有位于这个范围内的整数使用的都是同一个对象。在一个 Python 的程序中,无论这个整数处于LEGB(局部变量,闭包,全局,内建模块)中的哪个位置, 所有位于这个范围内的整数使用的都是同一个对象。
【示例】验证小整数池
In [8]: a = 100
In [9]: id(a)
Out[9]: 140705185112832
#删除变量a
In [10]: del a
In [11]: b = 100
In [12]: id(b)
Out[12]: 140705185112832大整数对象池
每一个大整数,均创建一个新的对象。
【示例】验证大整数池
In [13]: a = 257
In [14]: b = 257
In [15]: id(a)
Out[15]: 1747036560496
In [16]: id(b)
Out[16]: 1747036558352
In [17]: a is b
Out[17]: False
intern机制
每个单词(字符串),不夹杂空格或者其他符号,默认开启intern机制,共享内存,靠引用计数决定是否销毁。
【示例】intern机制
>>> a = 'helloworld'
>>> b = 'helloworld'
>>> a is b
>>> a = 'hello world'
>>> b = 'hello world'
>>> a is bfree_list机制
当一个对象的引用计数器为0时,按理说应该回收,但内存不会直接回收,而是将对象添加到free_list链表中缓存。以后再去创建对象 时,不再重新开辟内存,而是直接使用free_list。
以上的free_list的代表:float,list,tuple,dict。
>>> f1 = 3.14
>>> id(f1)
2078136427568
>>> del f1
>>> f2 = 9.998
>>> id(f2)
2078136427568f1 = 3.14,会创建float类型,并且加入refchain中。del f1 则减1, refchain移除,按理会进行销毁,但是实际中不会真正销毁,而是 会添加到free_list。以后创建f2=9.998等,只要是float类型,则不会重新开辟内存,会去free_list获取对象,对象内部进行初始化, 替换值3.14换成9.99,再放到refchain中。不是所有的都放入 free_list。例如存储100个缓存,则前面新创建的80个会放入 free_list。如果满了81之后则会销毁。
1、 float类型,维护的free_list链表最多可缓存100个float对象。
#ifndef PyFloat_MAXFREELIST//定义free_list的最大长度
#define PyFloat_MAXFREELIST 100
#endif2、 list类型,维护的free_list数组最多可缓存80个list对象。
#ifndef PyList_MAXFREELIST#define
PyList_MAXFREELIST 80
#endif
【示例】
>>> v1 = [11,22,33]
>>> id(v1)
2078137539904
>>> del v1
>>> v2 = ['a','b']
>>> id(v2)
2078137539904
3、 tuple类型,维护一个free_list数组且数组含量20,数组中元素 可以是链表且每个链表最多可以含钠2000个元组对象。元组的 free_list数据在存储数据时,是根据元组可容纳的个数为索引找 到free_list数组中对应的链表,并添加到链表中。

>>> t1 = (1,2,3)
>>> id(t1)
2078137564992
>>> del t1 #元组的数量是3,所以把这个对象缓存到
free_list[3]的链表中
>>> t2 = ('a','b','c')
#元组的数量也是3,不会重新开辟内存,而是去
free_list[3]对应的链表中拿到一个对象来使用
>>> id(t2)
2078137564992
>>> del t2
>>> t3 = (11,22,33,44)
>>> id(t3)
20781382194724、 dict类型,维护的free_list数组最多可缓存80个dict对象。
#ifndef PyDict_MAXFREELIST#define
PyDict_MAXFREELIST 80
#endif【示例】
>>> d1 = {'name':'zs'}
>>> id(d1)
2078137472640
>>> del d1
>>> d2 = {'age':30}
>>> id(d2)
2078137472640垃圾回收机制

Python 内部采用 引用计数法 ,为每个对象维护引用次数,并据此回收不再需要的垃圾对象。由于引用计数法存在重大缺陷,循环引 用时有内存泄露风险,因此 Python 还采用 标记清除法 来回收存在循环引用的垃圾对象。此外,为了提高垃圾回收( GC )效率,Python 还引入了 分代回收机制 。
引用计数法
Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。
引用计数 是计算机编程语言中的一种 内存管理技术 ,它将资源被引用的次数保存起来,当引用次数变为 0 时就将资源释放。它管理 的资源并不局限于内存,还可以是对象、磁盘空间等等。
Python 也使用引用计数这种方式来管理内存,每个 Python 对象都包含一个公共头部,头部中的 ob_refcnt 字段便用于维护对象被引用 次数。回忆对象模型部分内容,我们知道一个典型的 Python 对象结构如下:

当创建一个对象实例时,先在堆上为对象申请内存,对象的引用计数被初始化为 1 。以 Python 为例,我们创建一个 float 对象保存 6.66,并把它赋值到变量 f :
>>> f = 6.66
>>> f
6.66
由于此时只有变量 f 引用 float 对象,因此它的引用计数为 1 :

当我们把 pi 赋值给 f 后,float 对象的引用计数就变成了 2 ,因为现在有两个变量引用它:
>>> ff = f
>>> ff
6.66
我们新建一个 list 对象,并把 float 对象保存在里面。这样一来, float 对象有多了一个来自 list 对象的引用,因此它的引用计数又加 一,变成 3 了:
>>> l = [f]
>>> l
[6.66]
标准库 sys 模块中有一个函数 getrefcount 可以获取对象引用计数:
>>> import sys
>>> sys.getrefcount(pi)
4咦!引用计数不应该是 3 吗?为什么会是 4 呢?由于 float 对象被作为参数传给 getrefcount 函数,它在函数执行过程中作为函数的局部变量存在,创建了一个临时的引用,因此又多了一个引用:

随着 getrefcount 函数执行完毕并返回,它的栈帧对象将从调用链中解开并销毁,这时 float 对象的引用计数也跟着下降。因此,当一个 对象作为参数传个函数后,它的引用计数将加一;当函数返回,局部名字空间销毁后,对象引用计数又减一。
引用计数就这样随着引用关系的变动,不断变化着。当所有引用都消除后,引用计数就降为零,这时 Python 就可以安全地销毁对象, 回收内存了:
>>> del l
>>> del ff
>>> del f
引用计数增加
1、 对象被创建
2 、如果有新的对象使用该对象
3 、作为容器对象的一个元素
4、 被作为参数传递给函数
引用计数减少
1、 对象的引用被显示的销毁
2、 新对象不再使用该对象
3 、对象从列表中被移除,或者列表对象本身被销毁
4 、函数调用结束
引用计数机制的优点
1、简单
2、实时性:一旦没有引用,内存就直接释放了。
引用计数机制的缺点
1、维护引用计数消耗资源
2、循环引用的问题无法解决
a = [1,2]
b = [3,4]
a.append(b) #b的计数器2
b.append(a) #a的计数器2
del a
del b标记-清除
引用计数法能够解决大多数垃圾回收的问题,但是遇到两个对象相互引用的情况,del语句可以减少引用次数,但是引用计数不会归 0,对象也就不会被销毁,从而造成了内存泄漏问题。针对该情况, Python引入了标记-清除机制。
循环引用

引用计数这种管理内存的方式虽然很简单,但是有一个比较大的瑕疵,即它不能很好的解决循环引用问题。如上图所示:对象 A 和对 象 B,相互引用了对方作为自己的成员变量,只有当自己销毁时, 才会将成员变量的引用计数减 1。因为对象 A 的销毁依赖于对象 B 销毁,而对象 B 的销毁与依赖于对象 A 的销毁,这样就造成了我们 称之为循环引用(Reference Cycle)的问题,这两个对象即使在外界已经没有任何指针能够访问到它们了,它们也无法被释放。
class People:
pass
class Cat:
pass
#创建People的实例对象
p = People()
#创建Dog的实例对象
c = Cat()
#People的宠物属性指向Cat
p.pet = c
#Cat的主人属性指向People
c.master = p
#删除p和c对象
del p
del c上述实例中,对象p中的属性引用c,而对象c中属性同时来引用p, 从而造成仅仅删除p和c对象,也无法释放其内存空间,因为他们依然在被引用。深入解释就是,循环引用后,p和c被引用个数为2, 删除p和c对象后,两者被引用个数变为1,并不是0,而python只有 在检查到一个对象的被引用个数为0时,才会自动释放其内存,所以 这里无法释放p和c的内存空间。
主动思路一般分为两步:垃圾识别 和 垃圾回收 。垃圾对象被识别出来后,回收就只是自然而然的工作了,因此垃圾识别是解决问题的关键。那么,有什么办法可以将垃圾对象识别出来呢?我们来考察一个一般化例子:
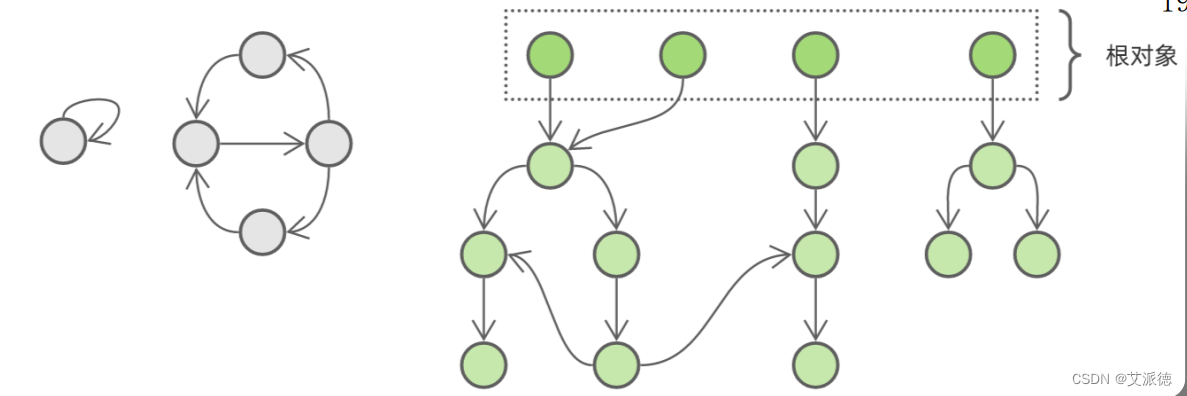
这是一个对象引用关系图,其中灰色部分是需要回收但由于循环引用而无法回收的垃圾对象,绿色部分是被程序引用而不能回收的活跃对象。如果我们能够将活跃对象逐个遍历并标记,那么最后没有被标记的对象就是垃圾对象。
遍历活跃对象,第一步需要找出 根对象 ( root object )集合。所谓根对象,就是指被全局引用或者在栈中引用的对象,这部对象是不能被删除的。因此,我们将这部分对象标记为绿色,作为活跃对象遍历的起点。

根对象本身是 可达的 ( reachable ),不能删除;被根对象引用的对象也是可达的,同样不能删除;以此类推。我们从一个根对象出发,沿着引用关系遍历,遍历到的所有对象都是可达的,不能删除。

这样一来,当我们遍历完所有根对象,活跃对象也就全部找出来了:
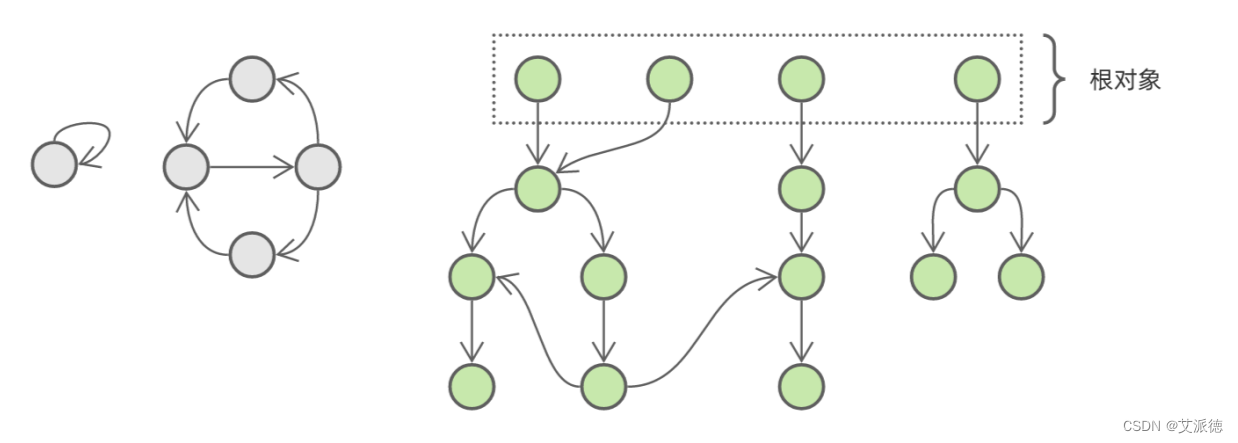
而没有被标色的对象就是 不可达 ( unreachable )的垃圾对象,可以被安全回收。循环引用的致命缺陷完美解决了!

这就是垃圾回收中常用的 标记清除法 。
【示例】标记清除法
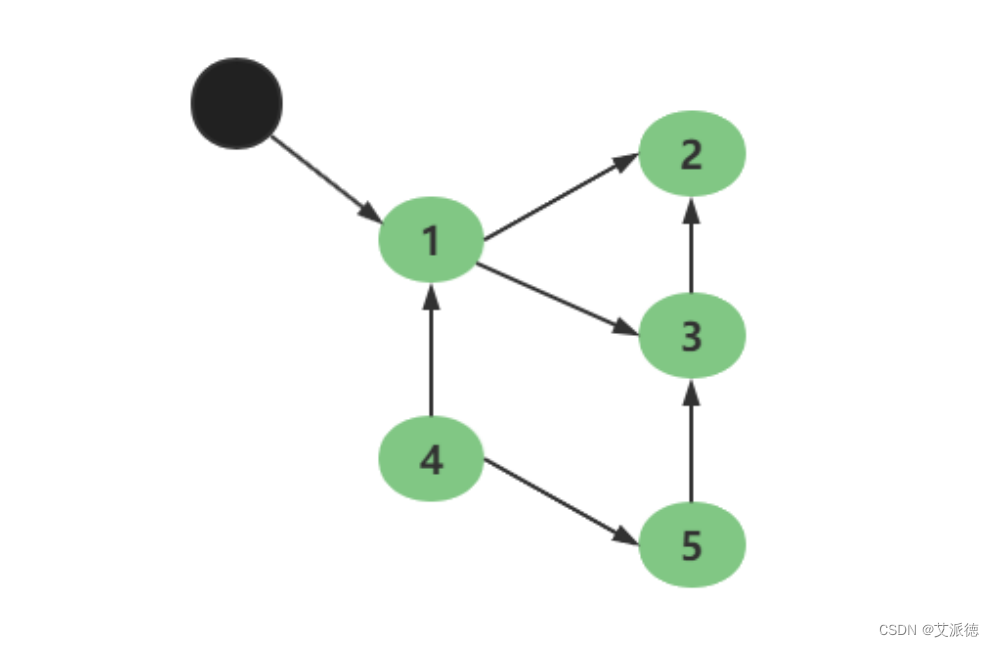
上图中小黑点(变量)表示根节点,从根节点出发,每个对象都有引用和被引用的情况,如果该对象找不到根节点,那么就会被清除,如图1,2,3都有被小黑点(变量)引用,4,5没有变量引用,所以 4,5就会被清除。
分代回收机制
Python 程序启动后,内部可能会创建大量对象。如果每次执行标记清除法时,都需要遍历所有对象,多半会影响程序性能。为此, Python引入分代回收机制——将对象分为若干“代”( generation ), 每次只处理某个代中的对象,因此 GC 卡顿时间更短。
考察对象的生命周期,可以发现一个显著特征:一个对象存活的时间越长,它下一刻被释放的概率就越低。我们应该也有这样的亲身体会:经常在程序中创建一些临时对象,用完即刻释放;而定义为 全局变量的对象则极少释放。
因此,根据对象存活时间,对它们进行划分就是一个不错的选择。 对象存活时间越长,它们被释放的概率越低,可以适当降低回收频率;相反,对象存活时间越短,它们被释放的概率越高,可以适当提高回收频率。
| 对象存活时间 | 释放概率 | 回收频率 |
| 长 | 低 | 低 |
| 短 | 高 | 高 |
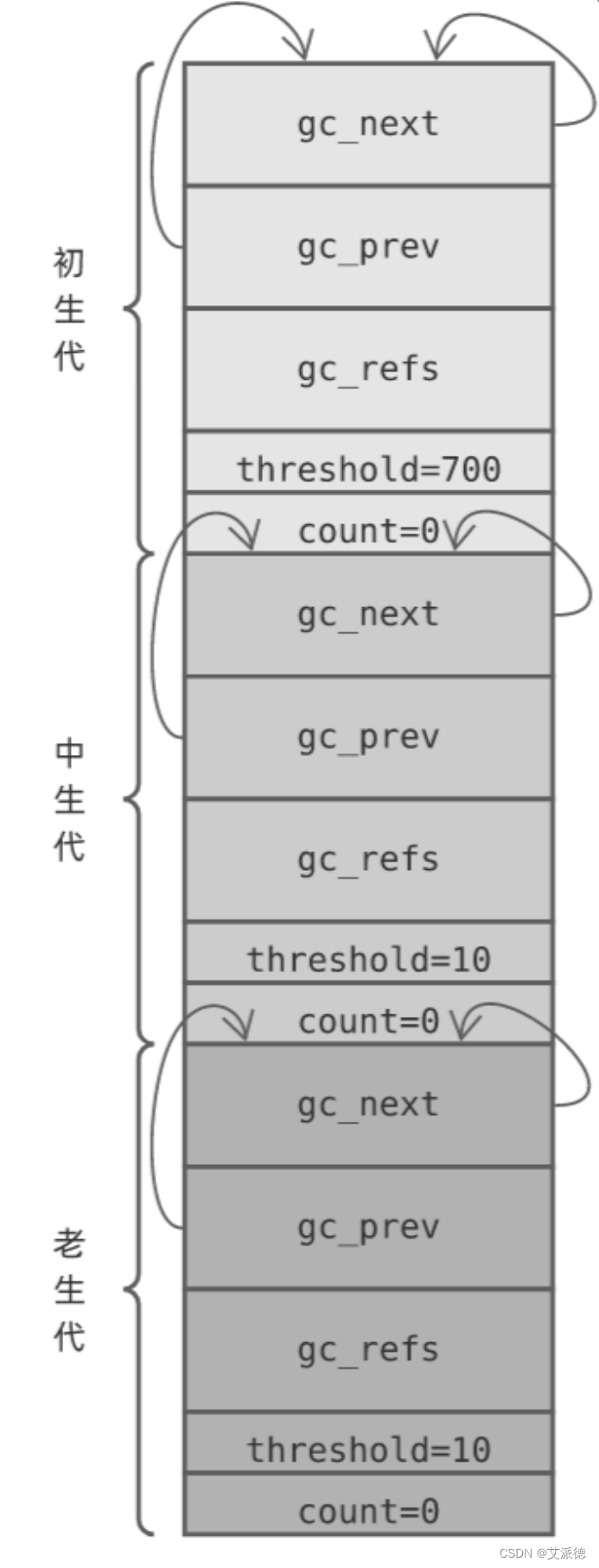
Python 内部根据对象存活时间,将对象分为 3 代(见 Include/internal/mem.h ):
#define NUM_GENERATIONS 3随着时间的推进,程序冗余对象逐渐增多,达到一定阈值,系统进行回收。
这 3 个代分别称为:初生代、中生代 以及 老生代。当这 3 个代初始化完毕后,对应的 gc_generation 数组大概是这样的:
import gc
#python 中内置模块gc触发
print(gc.get_threshold()) #查看gc默认值
#输出(700, 10, 10)
第一代链表:
当第一代达到700,就开始检测哪些对象引用计数变成0了,把不是0的放到第二代链表里,此时第一代链表就是空了,当再次达到700 时,就再检测一遍。
第二代链表:
当第二代链表达到10,就检测一次。
第三代链表:
第三代链表检测10之后,第三代链表检测一次。
import gc
#返回一个元组,分别获取这三代当前计数
gc.get_count()
#返回一个元组,分别获取这三代当前的收集阈值
gc.get_threshold()
#设置阈值
gc.set_threshold()
#关闭gc垃圾回收机制
gc.disable()