2023 AAAI
1 intro
1.1 背景
- 建模人类个体移动模式并生成接近真实的轨迹在许多应用中至关重要
- 1)生成轨迹方法能够为城市规划、流行病传播分析和交通管控等城市假设分析场景提供仿仿真数据支撑
- 2)生成轨迹方法也是目前促进轨迹数据开源共享与解决轨迹数据隐私问题的可行解决方案
- 在不泄漏移动轨迹数据中个人隐私的情况下实现轨迹数据的开源共享
- eg,某出行公司A拥有城市内的出租车轨迹数据,而某共享自行车公司 B 拥有同一城市内的共享单车轨迹数据。
- 如若两公司能够互相共享数据,那么二者能够更好地预测城市出行需求,从而改进相应的车辆调度服务。
- 但碍于轨迹数据的强隐私性,公司 A 与 B 无法互相共享数据。
- 此时,使用在数据效用上与真实轨迹相近的生成轨迹不仅可以完成数据共享改进各方服务,而且也可以避免用户隐私泄露。
- 因此,生成具有良好数据效用的轨迹数据非常重要
1.2 之前的工作
- 早期阶段,研究人员旨在构建基于模型的方法来模拟人类移动的规律性,例如时间周期性、空间连续性
- 这些方法假设人类移动可以用特定的移动模式来描述,因此可以用具有明确物理意义的有限参数来建模。
- 然而,事实上,人类移动行为表现出复杂的顺序转换规律,这些规律可能是时间依赖的、高阶的。
- ——>因此,尽管这些基于模型的方法具有设计上可解释的优点,但由于实现机制的简单性,它们的性能受到限制。
- 近些年使用神经网络生成范例(GAN、VAE)的无模型方法
- 放弃了特定人类移动模式的提取
- 直接构建神经网络来学习真实数据的分布,并从相同分布中生成轨迹
- 存在的问题
- 忽略了生成轨迹的连续性问题
- 不利用人类移动先验知识,难以有效地生成连续轨迹
- 现有方法的随机生成过程存在误差积累问题
- 现有生成过程中轨迹是根据生成器给出的概率随机生成的。
- 一旦生成器预测错误,该过程将在错误的前提下继续生成,从而降低了生成轨迹的质量
1.3 本文的思路
1.3.1 针对第一个挑战(忽略了生成轨迹的连续性问题)
算法笔记:A*算法_UQI-LIUWJ的博客-CSDN博客
- 提出了一种融合 A* 算法的城市个体移动模式感知的两阶段对抗生成网络
- 在 A* 假设中,个体移动行为由两个因素决定:
- 从起点道路到当前候选道路的已观察通行成本
- 从候选道路到目的地的预期通行成本
- 结合以上两种成本,A* 算法评估哪条候选道路是下一步搜索的最佳候选道路,然后启发式地生成最优连续轨迹
- 在 A* 假设中,个体移动行为由两个因素决定:
- ——>这篇论文的生成器由两部分组成:
- 基于注意力网络,学习观察到的通行成本
- 基于 GAT 的网络来估计预期通行成本
1.3.2 针对第二个挑战(不利用人类移动先验知识)
- 基于轨迹数据的时空特性构建了鉴别器网络
- 分别从时间序列相似性(序列奖励)和空间相似性(移动性偏航奖励)的角度来鉴别生成轨迹的真实性
- ——>以提高生成器的有效性
1.3.3 针对第三个挑战(误差积累问题)
- 提出了一个两阶段基于 A* 搜索的
- 第一阶段,依据路网结构构建区域,然后生成区域轨迹
- 第二阶段,在区域轨迹的指导下生成连续轨迹
1.4 贡献
- 首次使用 A* 算法与神经网络相结合以解决城市道路网络上连续轨迹生成问题
- 为了提高生成的有效性和效率,构建了一个结合了序列性奖励和移动偏航奖励的鉴别器,并提出了一个两阶段生成过程
- 在两个真实轨迹集上的相似性对比实验与两个案例研究证明了框架的有效性和鲁棒性
2 问题定义
2.1 连续轨迹
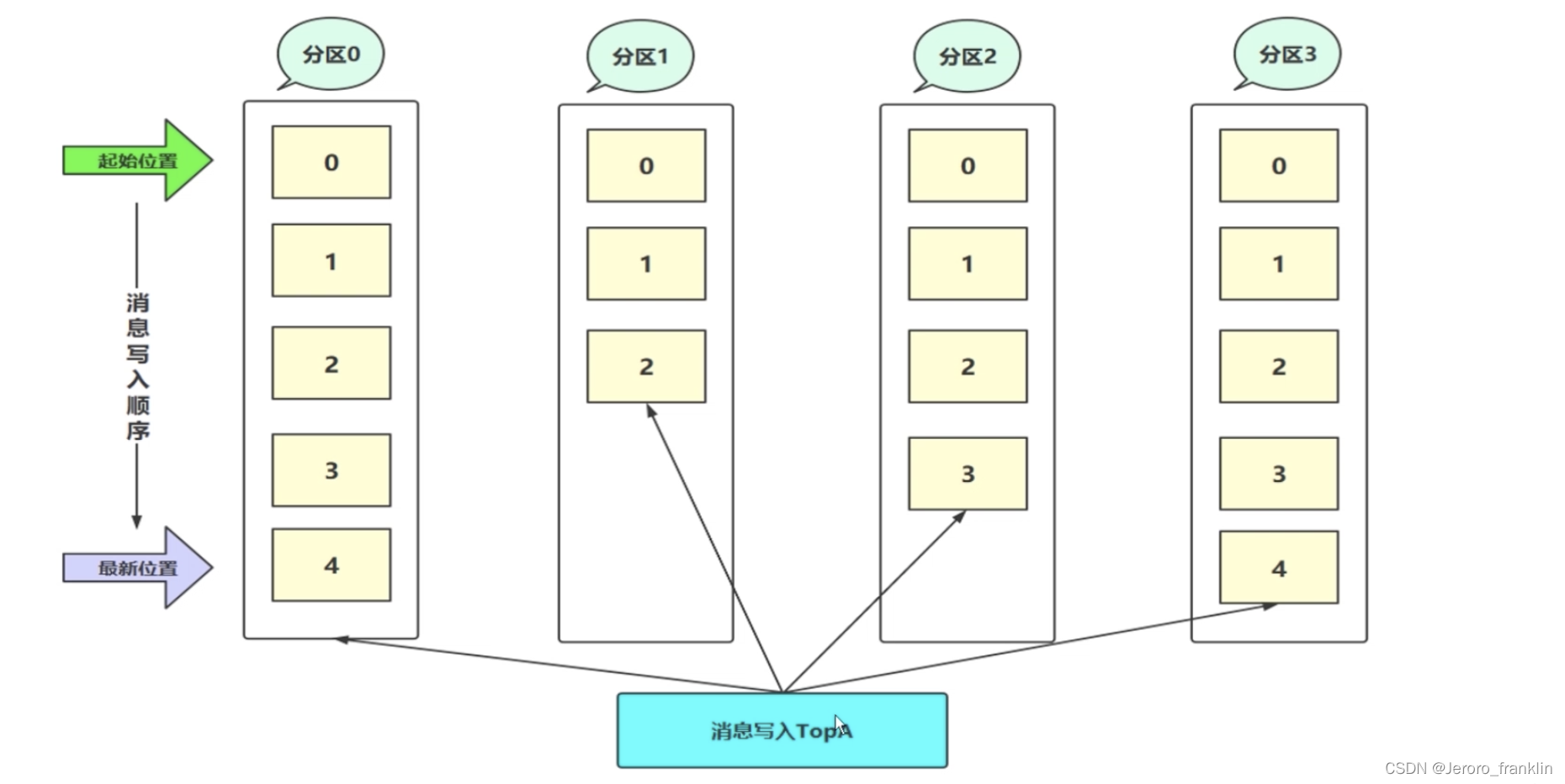
- 城市道路网络上的连续轨迹定义为按时间排序的序列
- 轨迹点xi由一个元组(li,ti)表示
- li——路段ID
- ti——轨迹点对应的时间信息
- 连续轨迹需要满足:相邻的轨迹点
在路网中是相邻路段
- 轨迹点xi由一个元组(li,ti)表示
2.2 连续轨迹生成问题
- 给定一个真实世界的移动轨迹数据集,给定起止点,生成一条或一组连续的移动轨迹
- 连续轨迹生成问题可以被建模为马尔可夫决策过程
- 状态——当前个体的移动状态
- 由当前部分轨迹
和目的地ld组成
- 由当前部分轨迹
- 个体动作a——要移动的下一个候选路段lj
- 个体移动策略
——个体在当前状态下决定下一步动作的条件概率
- 状态——当前个体的移动状态
- 生成器按照最大化个体移动策略的总概率来生成轨迹

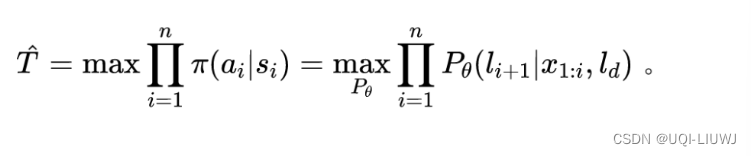
3 模型
3.1 整体模型

3.2 生成器
3.2.1 生成器的A*思想
- 在 A* 假设中,个体移动行为由两个因素决定:
- 从起点道路到当前候选道路lj的当前已通行成本(g)
- 从候选道路lj到目的地的未来通行成本(h)
- 结合以上两种成本,A* 算法评估哪条候选道路是下一步搜索的最佳候选道路,然后启发式地生成最优连续轨迹
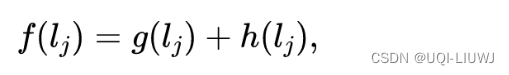
- 使用朴素 A* 算法生成轨迹有以下两个缺陷
- 在朴素 A* 算法中,g 和 h 函数是根据路段之间的球面距离计算的
- ——》学习多样化的人类个体移动模式变得困难
- 球面距离不能准确估算未来通行成本
- eg,主干道 & 支路
- 在朴素 A* 算法中,g 和 h 函数是根据路段之间的球面距离计算的
- ——>使用神经网络拟合 g 和 h 函数以建模个体移动模式,从而预测个体移动策略
注:这篇论文只是采用A*算法这个思路,并不是使用A*算法来找下一个路段,找下一条路段还是用概率P来找的

3.2.2 拟合A* 算法思路中的g函数(已通行成本)

3.2.3 拟合A*算法思路中的h函数(未来通行成本)
论文笔记 Graph Attention Networks_UQI-LIUWJ的博客-CSDN博客
- 使用图注意力网络从道路网络中提取相对位置信息,并计算两个路段之间的球形距离
- 基于以上信息,最终使用多层感知器网络来估计未来通行成本 h

3.3 鉴别器

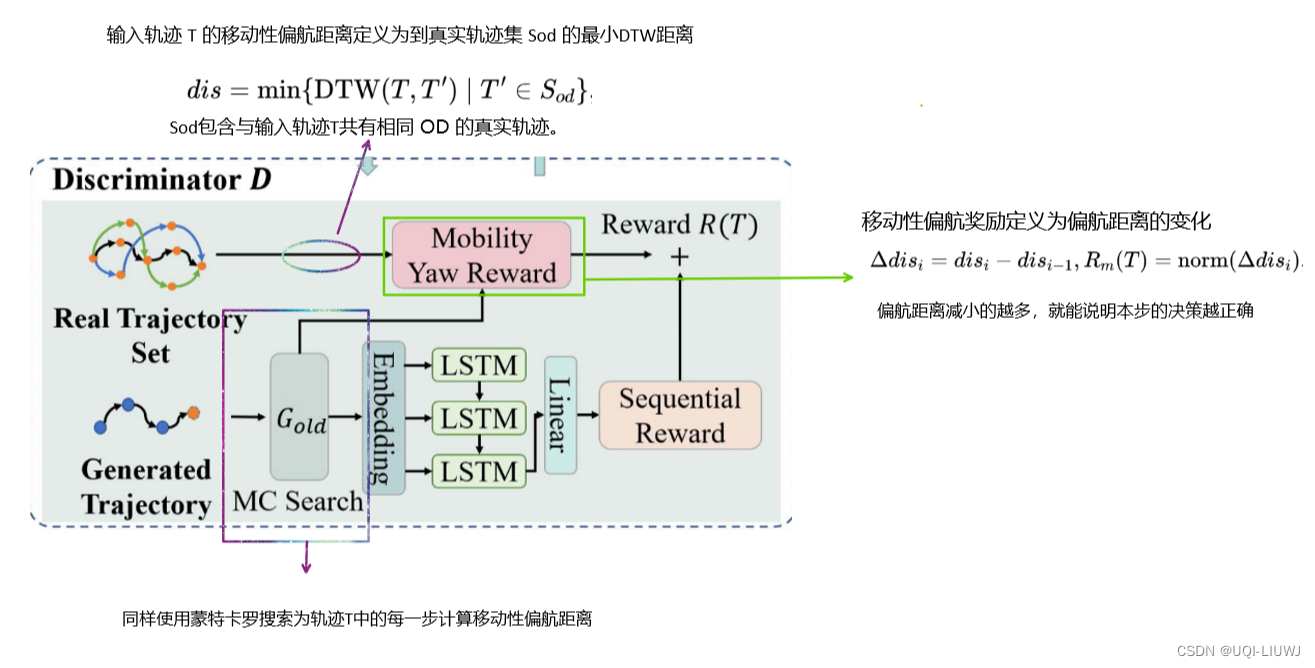
3.3.1 序列性奖励

3.3.2 移动性偏航奖励
3.4 训练生成器(REINFORCE算法)
强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客
强化学习,所以使用梯度上升

3.5 两阶段生成过程
- 现有方法的随机生成过程存在误差累积的问题
- 即在该过程中,轨迹是根据生成器给出的概率随机生成
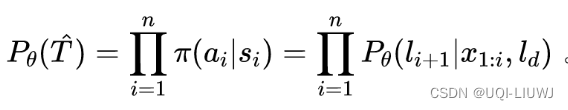
- 然而,一旦生成器预测错误,随机生成过程会在错误的前提状态下继续生成
- 当生成长轨迹时,生成器出错的概率随着生成器做出的预测数量的增加而增加
- ——>生成轨迹难以到达目的地,同时降低生成轨迹的质量
- 论文采用了两阶段生成过程
- 第一阶段生成区域轨迹
- 第二阶段,在区域轨迹的前提下生成区域内的道路级别轨迹,从而完成连续轨迹生成
4 实验
4.1 数据集


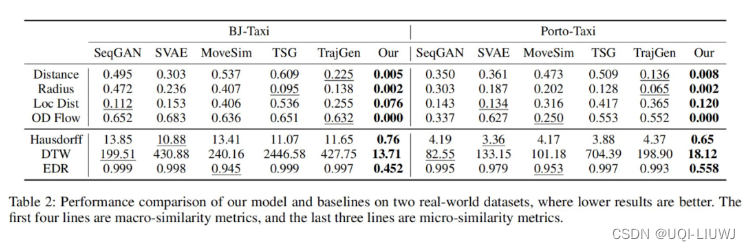
4.2 比较结果
5 可能可以改进的点
不同的人有不同的通行习惯,这边只考虑的比较general的mobility pattern。如何融入personalized mobility pattern,是一个考虑方向