性能分析常用方法
1. top
top指令默认用来监控cpu使用情况,根据cpu使用情况,分析整个系统运作情况(大多数系统cpu密集型)
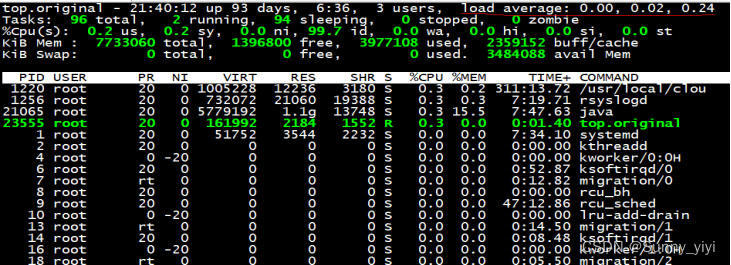
top指令查询的进程,将会根据cpu使用率大小进行排序,使用的比较多的排在前面,也可以按照内存进行排序,如果需要按照内存排序:按一下m键;
Load verage: 1分钟cpu平均使用率 5分钟cpu平均使用率 15分钟cpu平均使用率
单核cpu(1个核心cpu):
Load average < 1 , 表示cpu毫无压力,比较空闲,运行流畅
Load average= 1, 表示cpu刚刚被占满,没有可提供的cpu资源了
Load average>1,表示cpu满负荷运作,线程处于阻塞状态,等待cpu资源了
Load avergage > 5 , 表示cpu线程严重阻塞,如果时间一长,系统可能被打垮
4核cpu(4个核心cpu):
Load average < 4 , 表示cpu毫无压力,比较空闲,运行流畅
Load average= 4, 表示cpu刚刚被占满,没有可提供的cpu资源了
Load average>4,表示cpu满负荷运作,线程处于阻塞状态,等待cpu资源了
Load avergage > 20 , 表示cpu线程严重阻塞,如果时间一长,系统可能被打垮
2. free
free 排查线程内存问题重要指令,存在问题很多情况下也会使得cpu使用率飙高

3. df
df指令排查磁盘使用情况,有是时候服务出现问题,可能是磁盘不够了。
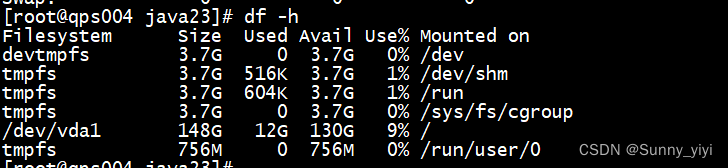
也可以使用du命令查询磁盘空间情况:
du命令: du -h –max-depth-1 find / -type d -size +50M
定时清理磁盘空间: ****** cat /dev/null > /usr/Catalina.out
4. dstat
dstat: 查看网络通畅情况
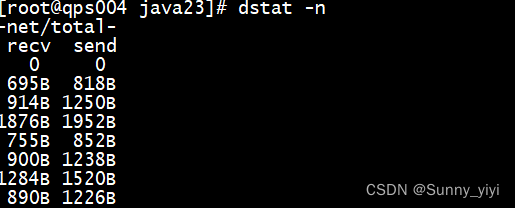
dstat: 查看网络通畅情况
netstat: 查询tcp连接情况
lsof : 查看tcp网络连接
查询网络连接: netstat -antp | grep ESTABLISHED lsof -I tcp
Tomcat调优
问题:项目在什么时间点介入调优??(开发之前,测试,线上运行时候)
答案:大多数情况下,项目上线后运行一段时间(持续用户流量,一切问题根源是量的积累,随着用户增多,随着数据量增大,并发的攀升,一段时间,系统出现了问题),此时就必须立马接入调优;
Tomcat配置
1) 空闲线程数(最低保活线程数)

2)最大线程数

3)最大连接数(提升连接数)

4)tomcat等待队列(提升队列)

开启20w个样本测试: 发现最大线程数为232个,有32个属于tomcat本身自带的线程,200个线程属于业务线程。
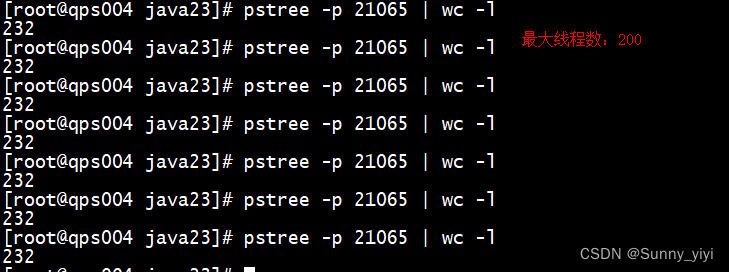
问题:tomcat最大线程数为200,是否意味着把线程数提升,服务性能是否一定会提升呢??
答案: 理论上,一定会提升,实际上看接口是否是耗时操作
Tomcat调优配置
server:
port: 9000
tomcat:
min-spare-threads: 10
max-connections: 10000
max-threads: 800
accept-count: 1000
uri-encoding: UTF-8
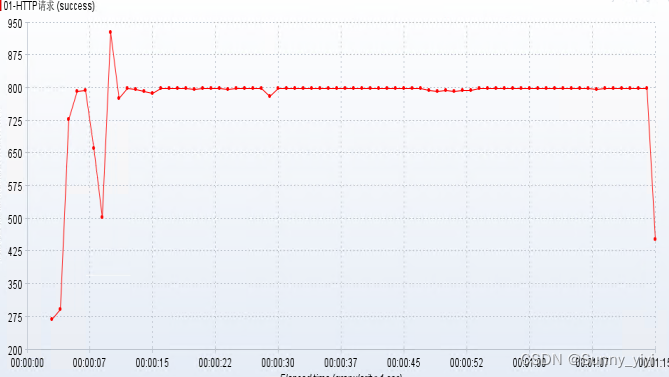
把优化后配置进行部署,观察得到的线程数量为800,确实对增大了线程数量:
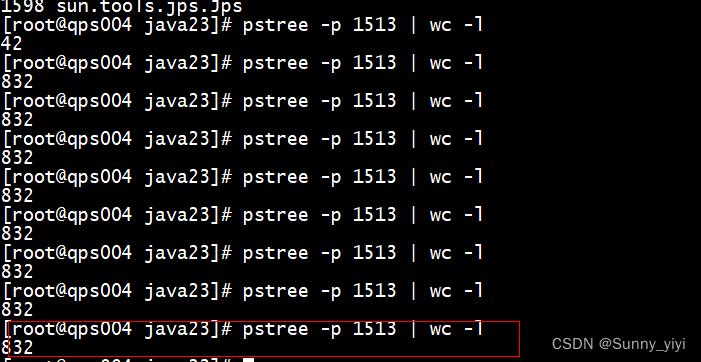
优化后的tps,经过tomcat调优后,发现tps吞吐能力提升了4倍。
JVM调优
Jvm调优本质: 对内存的调优(使用较少内存资源,获取最大的性能),及时释放内存空间垃圾对象;
典型参数
服务器:4cpus , 8GB ,目前来说jvm调优和cpu没有关系,跟内存有关系,因此jvm调优就是调内存:
1、-Xmx4000m 设置堆内存大小(一般情况下,设置物理内存一半即可-经验值设置-如果你想要更加精确的设置,根据程序在压力测试情况下反馈,做出合理的调试; 或是通过线上运行项目的反馈情况,进行合理的调试,不同项目,不同业务场景,调试的目标是不一样的)
2、-Xms4000m 设置堆内存初始化大小,必须和mx设置一致,防止内存抖动,从而损耗性能。
3、-Xmn2g 设置年轻代大小 (eden,s0,s1)
4、-Xss256k 设置线程堆栈大小,jdk1.5线程堆栈大小默认1MB, 相同内存空间,堆栈越小,操作系统就会创建更多的线程,从而提升性能
JVM在进行gc的时候,通过一些参数打印gc日志,记录gc详细过程情况,以便于分析gc参数设置是否合理,然后对gc参数做出及时更改调试;gc日志可以通过可视化的工具分析(gceasy.io)分析即可。
-XX:+PrintGCDetails : 打印gc详细信息
-XX:+PrintGCTimeStamps : 打印gc时间信息
-XX:+PrintGCDateStamp: 打印gc日期信息
-XX:+PrintHeapAtGC : 打印gc堆内存信息
Jvm参数设置,添加到启动脚本即可:
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.addition-location=application.yaml > jshop.log 2>&1 &
压力测试,观察gc日志,反馈gc情况:
压测后,把gc.log文件下载下来传到gceasy.io网站进行分析
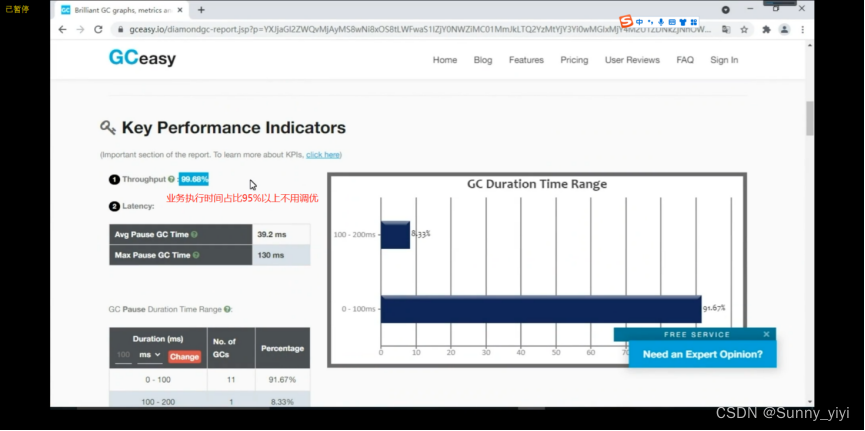
gc的次数,时间
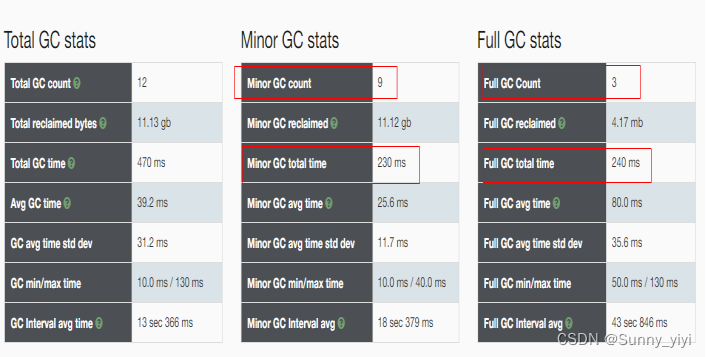
调试参数
当前服务器配置:8GB, 在大内存服务器下,产生对象很难快速把内存占满,触发gc, 因此对于大内存服务器来说,原则上来说不需要太多的调优,但是对于高并发,高可用的项目来说,jvm调优还是有必要的;因为防止频繁的gc(minor gc , fullgc 都会使得程序stw , 卡顿)
试验1: 把内存调小,产生频繁的gc , stw 卡顿时间将会延长
把内存调小,发现程序卡顿时间变长,变成了560+200=760ms;
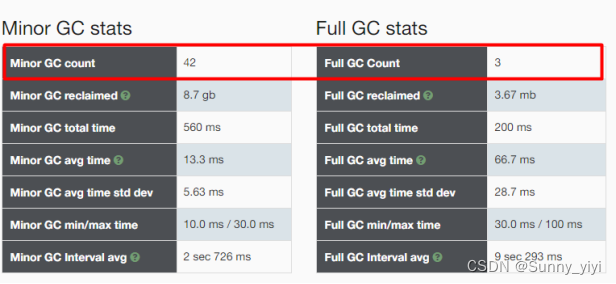
小结:
1) 频繁young gc , 必然会导致老年代空间对象变多,甚至会频繁fullgc ,oom
2) 当生命周期比较短暂的对象比较多的话,建议把年轻代空间设置大一些,当老年代空间对象比较多,建议把老年代空间设置大一些。
试验2: 把内存空间调大,不会产生频繁的gc,因此程序运行速度变快,也就是说程序的性能提升了。
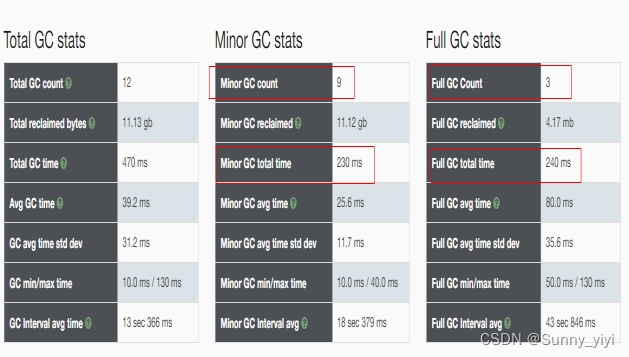
思考:为什么会发生fullgc 问题,按照垃圾回收理论(old区域被装满了才会触发fullgc)?
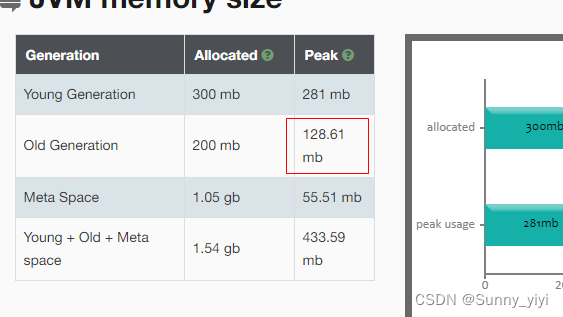
因此根据fullgc触发条件:
1、metaspace 元数据空间发生扩容,就会发生fullgc, 且每扩容一次,发生一次fullgc , 如果需要存储的数据超过maxMetaspace, 发生OOM
2、old memory 内存被占满了,发生fullgc,甚至发生oom;
1) 通过gc日志观察metaspace是否发生扩容
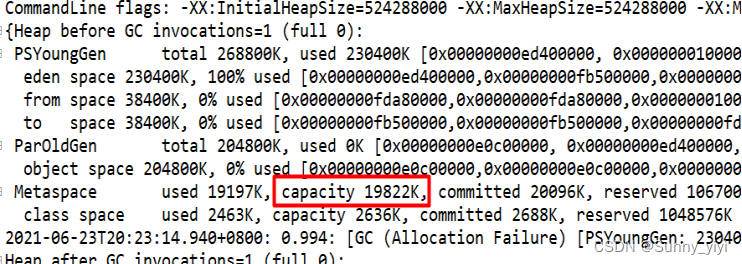
通过日志可以发现:元数据库初始化大小19822k
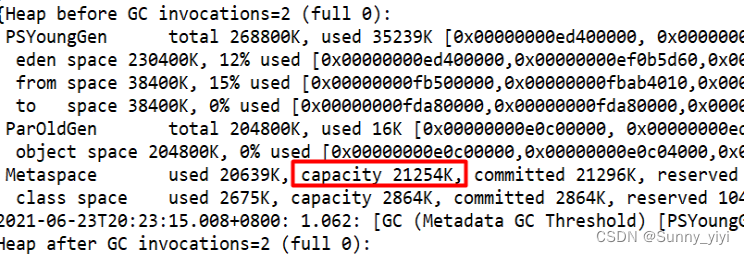
通过gc日志的观察,发现metaspace元数据空间发生了扩容;从19822k –> 21254k (第一次扩容,发生第一次fullgc)
2) 通过命令查询metaspace元数据空间初始化大小
查询命令: java -XX:+PrintFlagsFinal -version | grep MetaspaceSize

发现fullgc的原因后,就去把metaspace元数据空间的大小设置大一些,让其扩容不要发生了:


年轻代,老年代大小比例:改如何去设置?
JVM堆内存大小 = 年轻代内存空间 + 老年代内存空间
调整年轻代大小,或者是调整老年代大小都会对整个gc都会有影响(会影响gc性能:年轻代内存空间设置小了,频繁触发minor gc , gc时间变快–balance),因此堆内存空间大小比例调试也非常重要的;
Sun(官方推荐设置):
3(young): 8(堆内存空间) 强调: 此设置是推荐设置,不代表最终设置,具体设置还需要根据你的代码业务场景来进行设置;
举个栗子:
当你的代码局部对象非常多,非常适合在年轻代第一次就全部回收,这样业务场景,应该强调把年轻代空间设置大一些,尽量让对象在年轻代被回收
当你老年代对象较多时候,且发送频繁的fullgc , 建议把老年代空间调大一些,方式fullgc的发生。
推荐设置:
官方推荐设置: eden:s0:s1=8:1:1
设置方式: -XX:SurvivorRatio = 8

GC经典组合
吞吐量优先
并行垃圾回收器组合: Parallel Scavenge + Parallel Old , JDK8默认的垃圾回收器,ps+po充分利用多核心cpu资源,在多个cpu上同时执行gc; 因此把这样垃圾回收器叫做吞吐量优先组合;
显式配置(默认不用配)吞吐量优先垃圾回收器组合:
nohup java -Xmx4000m -Xms4000m -Xmn2g -XX:SurvivorRatio=8 -XX:+UseParallelGC -XX:+UseParallelOldGC -Xss256k -XX:MetaspaceSize=200m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.addition-location=application.yaml > jshop.log 2>&1 &
响应时间优先
响应时间优先的垃圾回收器组合:ParNew + CMS (业务线程,gc线程交叉执行,降低业务线程停顿时间,从而降低业务卡顿)
nohup java -Xmx4000m -Xms4000m -Xmn2g -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -Xss256k -XX:MetaspaceSize=200m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.addition-location=application.yaml > jshop.log 2>&1 &
G1
G1 垃圾回收器: 一个在逻辑上分代的垃圾回收器,使用方式非常简单,高效: -XX:+UseG1GC
连接池调优
druid:
#配置初始化大小、最小、最大
initial-size: 1
min-idle: 5
max-active: 10
max-wait: 1200
time-between-eviction-runs-millis: 600000
# 配置一个连接在池中最大空闲时间,单位是毫秒
min-evictable-idle-time-millis: 300000
# 设置从连接池获取连接时是否检查连接有效性,true时,每次都检查;false时,不检查
test-on-borrow: true
#设置往连接池归还连接时是否检查连接有效性,true时,每次都检查;false时,不检查
test-on-return: true
# 设置从连接池获取连接时是否检查连接有效性,true时,如果连接空闲时间超过minEvictableIdleTimeMillis进行检查,否则不检查;false时,不检查
test-while-idle: true
# 检验连接是否有效的查询语句。如果数据库Driver支持ping()方法,则优先使用ping()方法进行检查,否则使用validationQuery查询进行检查。(Oracle jdbc Driver目前不支持ping方法)
validation-query: select 1 from dual
keep-alive: true
remove-abandoned: true
remove-abandoned-timeout: 80
log-abandoned: true
#打开PSCache,并且指定每个连接上PSCache的大小,Oracle等支持游标的数据库,打开此开关,会以数量级提升性能,具体查阅PSCache相关资料
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
# 配置间隔多久启动一次DestroyThread,对连接池内的连接才进行一次检测,单位是毫秒。
#检测时:
#1.如果连接空闲并且超过minIdle以外的连接,如果空闲时间超过minEvictableIdleTimeMillis设置的值则直接物理关闭。
#2.在minIdle以内的不处理。
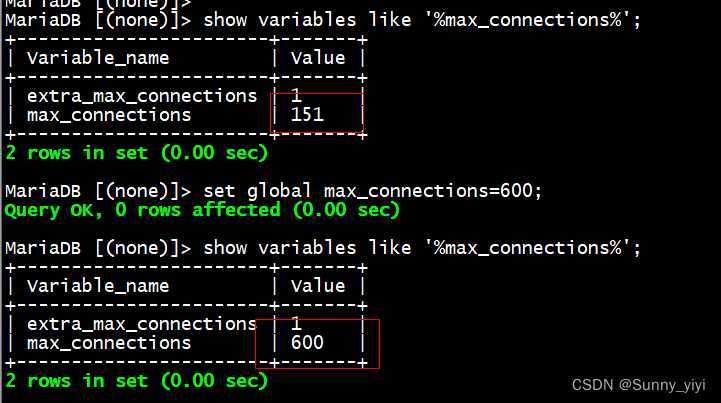
问题1:max-active最大连接数设置多少合适?
压力测试:max-active:10 , TPS = 20000
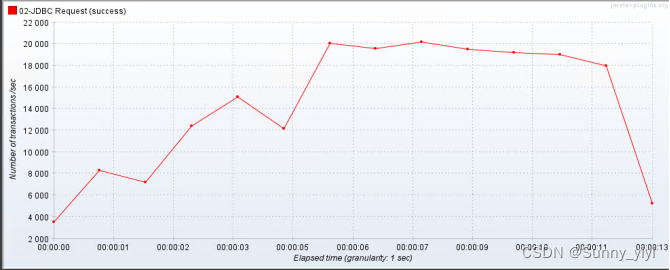
max-active:15 ,TPS = 16000 TPS , 发现连接越多,tps会下降;
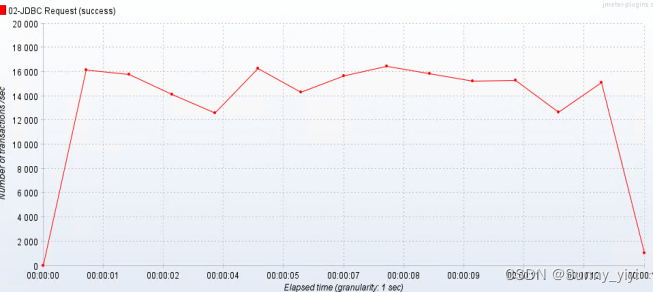
max-active:20 , tps = 14000 tps
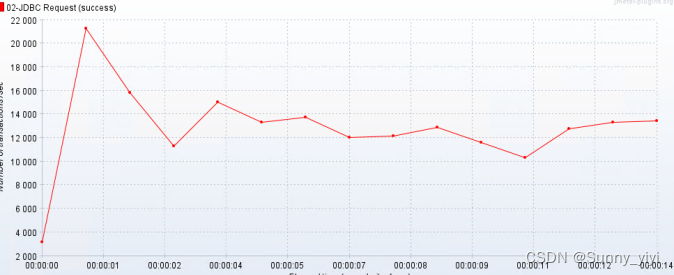
思考:经过测试,发现随着连接数变多,发现数查询据库性能越来越低;这是什么原因呢??
1、数据库连接连接数不够吗?
压力测试: 观察,是否和连接数有关系?
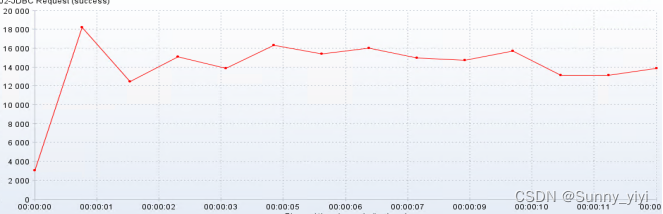
经过测试,发现数据库查询性能和连接数目前来说没有什么关系!性能其实和客户端设置有关系,当然归根结底是因为数据库的问题;
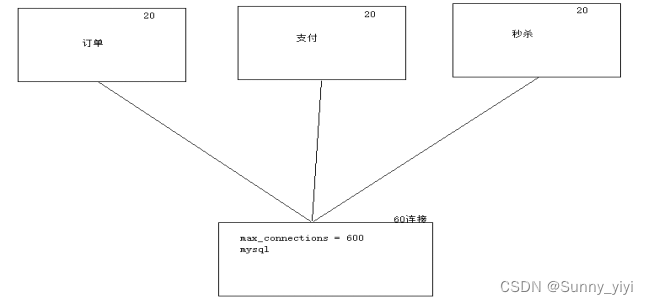
连接数越多,抢占cpu资源(上下文切换的开销比较耗时,因此降低业务处理性能)
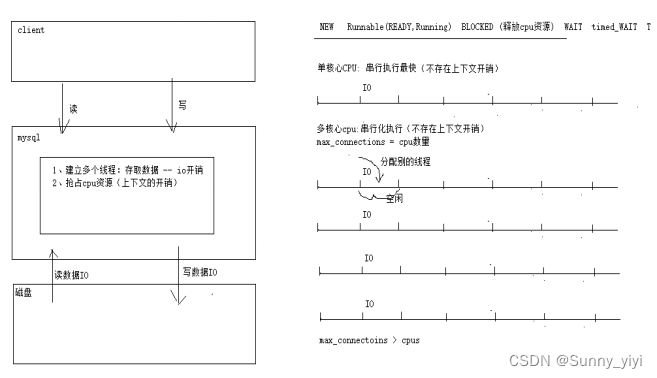
连接池中,io最耗时的,查询的时候,cpu指令执行结束后,然后线程存取数据(io操作:磁盘非常耗时)
最大连接数计算公式 = (cpu核心数 X 2)+ 磁盘数量 = 10
问题2:max-wait设置多少合适呢?
max-wait : 从连接池中获取连接超时等待时间,单位ms,这个参数和连接超时有关系的:
获取连接超时直接原因:
1、连接池未初始化(初始化耗时)
2、连接池使用的时候,连接已经被释放
3、连接正在使用中,需要重建建立连接
4、连接已耗尽,需要等待归还后才能获取连接
设置多少超时时间比较合适。防止连接长时间阻塞,因此需要设置合理的max-wait 的值:
# 推荐设置
1、内网模式下(网络状态非常好): 800ms
2、外网模式下(网络抖动不可避免):max-wait >=1200ms ,TCP建立连接时间耗时1s;
防止死连接
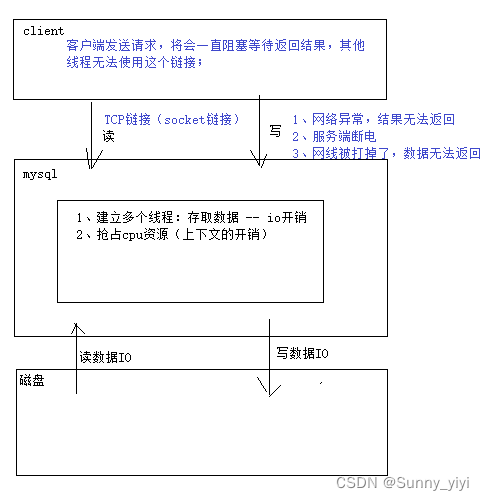
给这个链接设置一个过期时间(等待返回结果超时,如果在规定时间内无法获取结果,释放连接)
connectionTimeout = 3000 # 单位是ms, 连接超时
socketTimeout = 1200 # 单位是ms, 连接建立后,如果在1200ms获取不到数据,连接就自动释放;
分布式部署
为了进一步提高项目吞吐能力,对项目进行水平扩容(服务集群部署),把项目部署2个服务节点,在请求接入层使用openresty(nginx)来实现负载均衡;
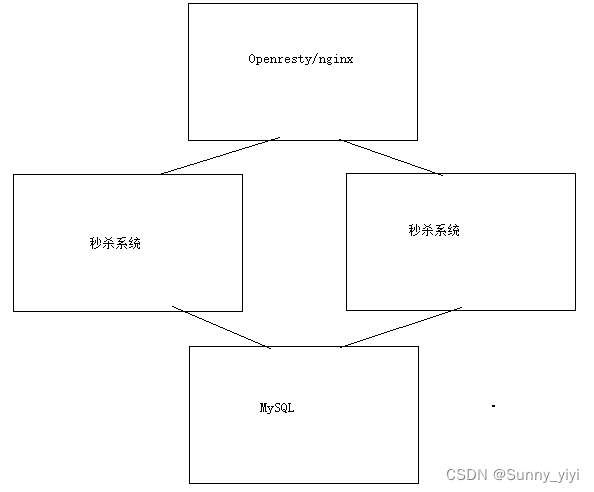
nginx.conf配置

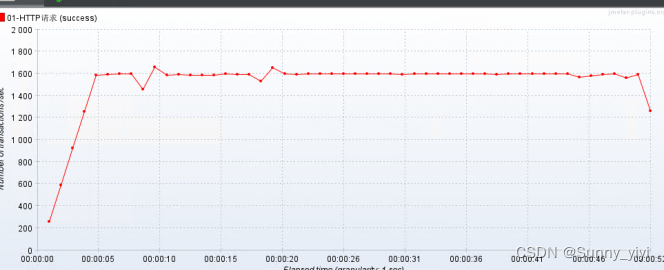
根据刚才我们测试,发现性能瓶颈不在数据库,因此数据库测试tps=40000, 项目测试tps=800,因此性能瓶颈不在数据库,而在项目,因此提升系统吞吐能力,必然需要把服务进行水平扩容;
预测:性能瓶颈不在数据库,也不在接入层Openresty,那么项目进行水平扩容后,tps = 800 X 2 = 1600 TPS

![[附源码]Python计算机毕业设计房屋租赁管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/6b23f711803a4d329b203ea1e3dd263d.png)


![[附源码]计算机毕业设计的剧本杀管理系统Springboot程序](https://img-blog.csdnimg.cn/5a9bc17820474a93872947c9444d5a30.png)