重生强化【Reincarnating RL】论文梳理
文章目录
- 重生强化【Reincarnating RL】论文梳理
- 前言:
- 文章链接:
- 作者团队介绍:
- 沈向洋老师的论文十问:
- 联系方式:
前言:
好久没写文章速读了,最近群友推荐了两篇非常有意思的文章,一个是重置强化,一个是重生强化,从两个不同的角度来让强化学的更快。
由于我最近也在做相关的工作,然后就仔细的看了这两篇文章。第一篇文章录了一个视频:【ResetNet-The Primacy Bias in Deep Reinforcement Learning论文解读和讨论-哔哩哔哩】 https://b23.tv/GJQ85N5
第二篇这周六晚上和群友讨论后,应该也会有一个视频。今天先梳理下思路。
首先这篇文章的openreview评分并不高,因为他的主要方法比较trivial,但是他的故事讲的非常棒,切入的点非常宏大,然后实现的效果比较明显,实验结果也很丰富。
另外,知乎曾经有一个强化的热门话题:为什么强化学习里很少有预训练模型(Pretrained Model)?。“在NLP和CV领域中都存在一些非常出名的预训练模型(例如BERT和ResNet),但好像没有太听说强化学习里有类似于这种的backbone呢?” 那么这篇文章就尝试让强化学习领域,能够构建类似的backbone,并且推崇这种预训练模型的范式。
基于此,他们只是在文中提供了一个例子,可以实现policy to value 的迁移(其实本质上是提供一个次优的policy,加上部分次优数据,去预训练一个白板强化(tabula-rasa RL),再利用行为克隆来做约束,帮助策略快速收敛,最后给行为克隆损失加一个衰减系数做“断奶”,让新的强化策略最终能超过原本的次优引导policy),这种方案在文中给的例子中效果不错。但是我个人感觉这种方案,可能对于AC结构的算法不是那么合适。
文章链接:
https://agarwl.github.io/reincarnating_rl
作者团队介绍:

谷歌大脑在蒙特利尔的研究院。看一作的talk,也是一个乐呵的人,有点意思。
沈向洋老师的论文十问:
Q1:论文试图解决什么问题?
A1:本文尝试正式定义好,强化学习领域,如何利用过去的训练结果。最好要突破网络结构的限制。
Q2:这是否是一个新的问题?
A2:这并不是新的问题,如何利用过去的训练结果,之前很多人都有过尝试。但是他们第一次正式的给出定义,并且提供了一个较为universal的方案,可以仅从次优策略和数据,实现到加速白板value-based RL的快速学习。
Q3:这篇文章要验证一个什么科学假设?
A3:提供一个强化预训练范式,至于重生强化,感觉更像噱头,但确实高大上了许多。
Q4:有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
A4:文中提到了五个:Rehearsal,JSRL,Offline RL Pretraining,Kickstarting,DQfD,但我感觉还有一个没提到,就是就是残差强化,因为在探索中利用guide-policy,JSRL属实不是一个好的方案,很明显会造成引导和学习策略的状态分布不匹配,而我上一篇工作RHER的自我引导探索策略采用的随机混合模式就不会有这样的问题。至于本文提到的重生强化,所提出的算法PVRL(policy(+data) to value RL),他们和上述五个方案的异同点在于,和offline RL一样,利用teacher policy的data做了离线预训练,后面的在线调优,和Kickstarting一样,都用了策略蒸馏损失,和他们不一样的在于,这篇工作对策略蒸馏损失加了一个衰减系数,作为“断奶”的操作。一共就三步,而且最后一个不同其实也就多了一个超参数。但人家是第一个正式定义大模型预训练范式,并且在很多任务中都验证好使,也算是一个solid work。
Q5:论文中提到的解决方案之关键是什么?
A5:我刚刚开始以为解决方案就是预训练加行为克隆损失。但细看文章的时候,它在文章开头前三页都没有说具体的方法,而是笼统的冠以“policy2value RL”,实现仅仅有一个sub-optimal policy,就能帮助一个新的value-based RL快速训练,根本不用管这个新的RL agent的网络结构和超参数,这个描述让我觉得太神奇了,我看完了甚至都不知道该如何实现。然后看到method的时候,才发现,其实就是一个policy distillation loss…甚至它还需要teacher agent的部分数据。用审稿人的话就是,不该称为PVRL,而是(Policy+Data to Value)RL.。那么它的关键技术就A4提到的三步,预训练,蒸馏,加衰减系数对teacher policy的“断奶”。
Q6:论文中的实验是如何设计的?
A6:实验设计范式和普通的强化完全不一样。
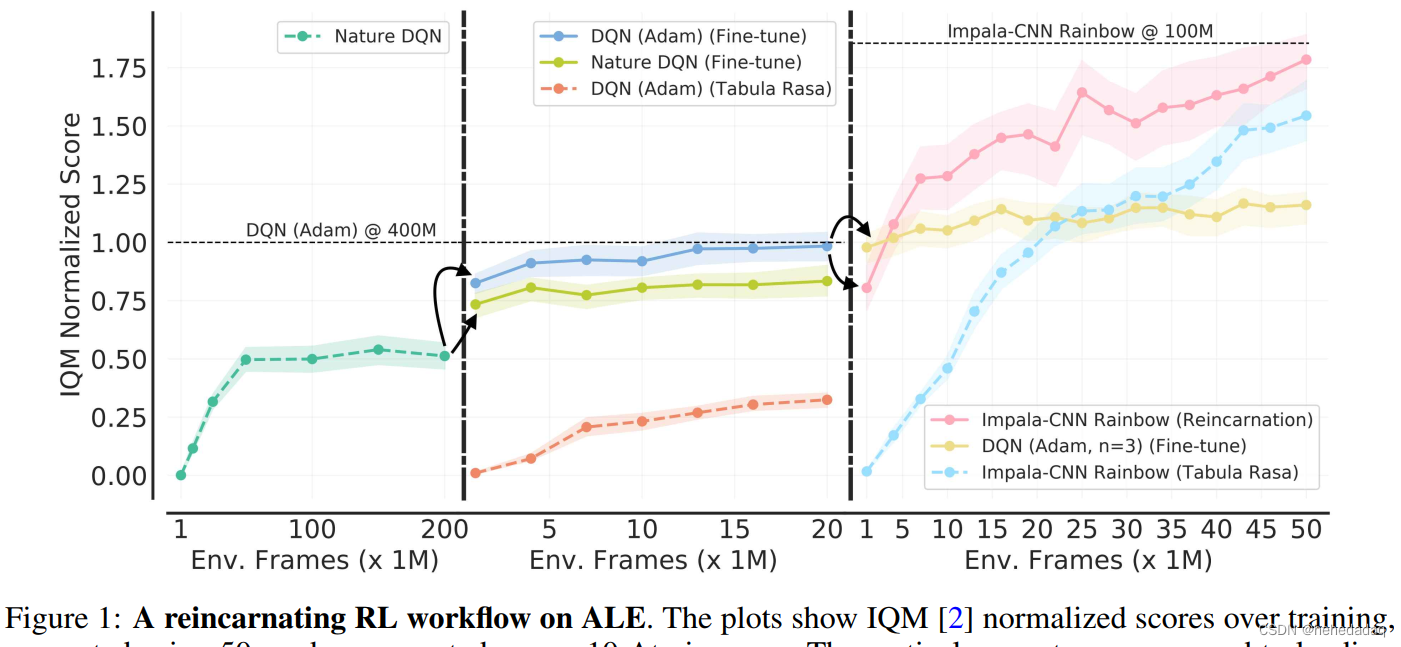
首先,横纵坐标就很不一样,横坐标根据不同的训练模式,分成了不同的panel(不同的部分?),纵坐标则做了一个norm,随机策略的性能为0,teacher policy的性能为1,应该是线性划分,用以突出teacher policy和student policy的性能差距。其次关于曲线,断续的纵线表示重生操作,左边是teacher policies的效果,或者是预训练的性能曲线,右边是student policy在线调优的性能曲线。title和legend表示不同的设置。
Q7:用于定量评估的数据集是什么?代码有没有开源?
A7:几个比较消耗资源的大任务,比如说雅塔丽游戏中的Arcade Learning Environment (ALE,街机游戏任务,离散动作,DQN系列) ;火柴人控制任务:humanoid:run (唯一的一个连续动作任务,用的TD3,没用预训练,非常诡异,我十分怀疑TD3预训练效果并不好使~);真实场景任务(其实也是仿真):Balloon Learning Environment (BLE,热气球飞行控制,也是离散动作,用的DQN系列) 。
不仅代码开源了(其实代码也没啥东西…),因为他们要力推强化的预训练backbone,他们还开源了不少谷歌的压箱底训练参数和数据。
Q8:论文中的实验及结果有没有很好地支持需要验证的科学假设?
A8:在他们展示的任务中,比较好的验证了他们的假设,即,通过预训练、蒸馏损失、衰减蒸馏系数,可以实现一个teacher policy+少量data,对一个全新的value-based RL网络的知识快速迁移。
Q9:这篇论文到底有什么贡献?
A9:贡献首先是正式的定义了重生强化(划掉,感觉本质上是强化学习预训练范式)。其次,提供了一个可能在离散动作比较好用的policy-to-value的迁移方案。最后,作为提倡者,他们开源了一些谷歌压箱底的训练模型和数据,对计算资源少的实验室和个人来说,无疑是一个利好。
Q10:下一步呢?有什么工作可以继续深入?
A10:下一步可以参考NLP和CV的操作,提出更好更universal的迁移方案,比如对于actor-critic结构的强化算法,如何才能快速的迁移,同时避免offline RL在AC结构中遇到的问题,比如OOD,比如offline2online过程中,性能甚至会下降的问题。
至于其他的内容,今天就到这儿了,感兴趣的同学可以自己去看看原文,或者等周六晚上7点,腾讯会议一起讨论一下。
联系方式:
ps: 欢迎做强化的同学加群一起学习:
深度强化学习-DRL:799378128
Mujoco建模:818977608
欢迎玩其他物理引擎的同学一起玩耍~
欢迎关注知乎帐号:未入门的炼丹学徒
CSDN帐号:https://blog.csdn.net/hehedadaq
我的两个GitHub仓库,欢迎star~
极简spinup+HER+PER代码实现:https://github.com/kaixindelele/DRLib
自我引导探索-接力式HER(据我所知的探索效率最高的HER变体):https://github.com/kaixindelele/RHER

![[附源码]Python计算机毕业设计房屋租赁管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/6b23f711803a4d329b203ea1e3dd263d.png)


![[附源码]计算机毕业设计的剧本杀管理系统Springboot程序](https://img-blog.csdnimg.cn/5a9bc17820474a93872947c9444d5a30.png)