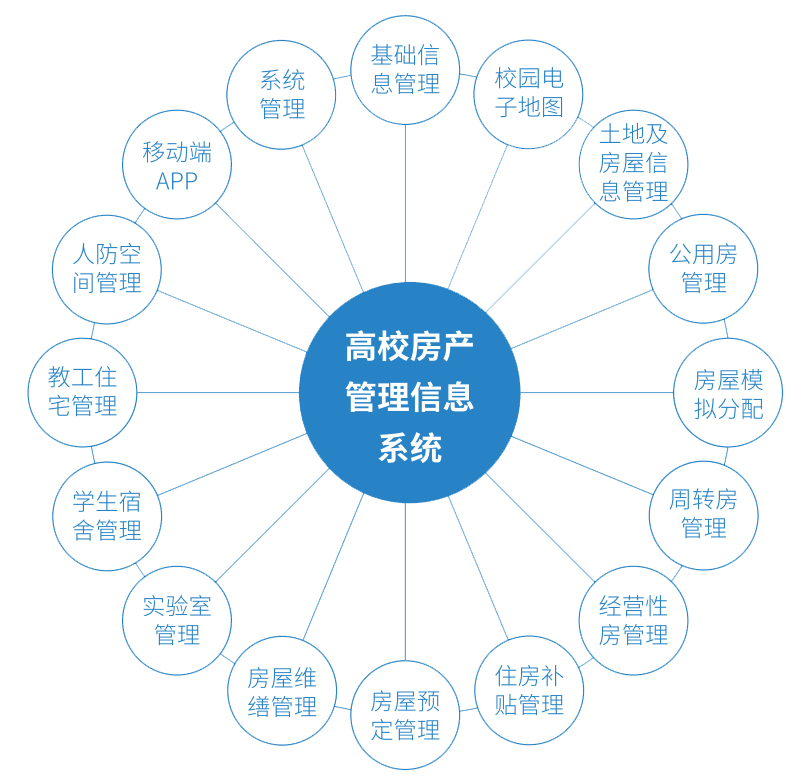
1、可利用的特征
1.1 用户行为特征
- 显性反馈行为:点赞、评分、评价等
- 隐形反馈行为:点击、浏览、播放、加入购物车等
1.2 用户关系数据
- 显性:关注、好友关系
- 隐形:点赞、共同观影
- 使用Graph Embedding生成用户和物品的Embedding
1.3 属性、标签类数据
推荐系统中另外一大类特征来源是属性、标签类数据,这里我把属性类数据(Attribute Data)和标签类数据(Label Data)归为一组进行讨论,是因为它们本质上都是直接描述用户或者物品的特征。属性和标签的主体可以是用户,也可以是物品
用户特征、物品特征,然后通过Multi-hot或GNN(Graph Neural Network),使特征数值化
1.4 内容类数据
内容类数据(Content Data)可以看作属性标签型特征的延伸,同样是描述物品或用户的数据,但相比标签类特征,内容类数据往往是大段的描述型文字、图片,甚至视频。
同样通过One-hot或者GNN变成Embedding
1.5 场景信息(上下文信息)
最后一大类是场景信息,或称为上下文信息(Context Information),它是描述推荐行为产生的场景的信息。最常用的上下文信息是“时间”和通过 GPS、IP 地址获得的“地点”信息。
2、特征数值化 – 传统方法
- 类别特征:one-hot、multi-hot
- 数值型特征:归一化、分桶
3、特征数值化 – Embedding技术
3.1 从word2vec到item2vec
从NLP中,对文字向量化的思想中得到启发,对物品向量化。以前简单总结了一下词向量技术:word2vec等词向量简述
Word2vec

思路:根据上下文实现对单词的Embedding,采用3层结构,图中hidden即是词的Embedding
方式有两种:
- CBOW:通过上下文预测单词,Input是目标词上下文的Multi-hot,连接全连接层到Hidden,再连接softmax到output,output是One-hot表示的目标词
- Skip-gram:与CBOW相反,Input是目标词,Output是上下文的Multi-hot
两个优化学习方法:
- 多层Softmax:由于样本不均衡,采用多层sigmoid的方式学习
- 负采样:上下文有2N个正样本,根据单词的出现频率,采样2N个负样本进行学习
item2vec
与Word2vec的原理完成一致,把用户的浏览、购买、观看序列,传入word2vec模型,就形成物品等Embedding
3.2 Graph Embedding
单纯的用item2vec没有考虑到结构信息,仅仅考虑到了序列的前后关联。
- DeepWalk:将item的前后连成图,在图上随机游走采样,形成序列,在传入item2vec
- Node2vec:DeepWalk采用完全随机游走的采样方式,没有考虑到图的同质性和结构性,Node2vec采用带有权重的随机游走方式,兼顾到了这两方面的:
- 同质性: 倾向于向远处游走,考虑图的全貌,加大DFS的权重
- 结构性:倾向于在附近游走,考虑图的附近结构,加大BFS的权重
Graph Embedding应用
Graph Embedding的应用有三种形式:
- 直接应用:利用相似的item embedding推荐物品
- 预训练:预训练物品的Embedding,传入模型作为土整
- 端到端:把物品的Embedding训练加入到模型中
![[附源码]Python计算机毕业设计SSM基于web的托育园管理系统(程序+LW)](https://img-blog.csdnimg.cn/39287ac0fcf748f7b16e47eabfeff7db.png)