文章目录
- 前言
- fastai介绍
- 数据集介绍
- 一、环境准备
- 二、数据集处理
- 1.数据目录结构
- 2.导入依赖项
- 2.读入数据
- 3.模型构建
- 3.1 寻找合适的学习率
- 3.2 模型调优
- 4.模型保存与应用
- 总结
- 人工智能-图像识别 系列文章目录
前言
fastai介绍
fastai 是一个深度学习库,它为从业人员提供了高级组件,可以快速、轻松地在标准深度学习领域提供最先进的结果,并为研究人员提供了低级组件,可以混合和匹配以构建新的方法。以解耦抽象的方式表达了许多深度学习和数据处理技术的通用底层模式。
fastai 有两个主要的设计目标:易于使用、快速高效,同时具有很强的可破解性和可配置性。它建立在提供可组合构件的低级应用程序接口的层次结构之上。这样,如果用户想重写部分高级应用程序接口或添加特定行为以满足自己的需求,就不必学习如何使用最底层的应用程序接口。
数据集介绍
下载链接
Caltech101国内下载地址
Caltech101
Caltech101数据集内部有 101 个类别的物体图片。每个类别约有 40 至 800 张图片。大多数类别约有 50 张图片。每张图片的大小大约为 300 x 200 像素。并且作者还标注了这些图片中每个物体的轮廓,这些都包含在 "Annotations.tar "中。还有一个 MATLAB 脚本 "show_annotations.m "可以查看注释。
Collected in September 2003 by Fei-Fei Li, Marco Andreetto, and
Marc’Aurelio Ranzato。
一、环境准备
这里展示使用GPU进行训练的环境搭建,只用CPU也可以进行训练,只是训练时间比较慢。
首先安装Anaconda,通过conda安装我们需要的包
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
conda install -c nvidia fastai anaconda
详情可见第一篇文章。
二、数据集处理
1.数据目录结构
├───data_iamge
│ ├───101_ObjectCategories
│ │ ├───accordion
│ │ ├───airplanes
│ │ ├───anchor
│ │ ├───ant
│ │ ├───BACKGROUND_Google
│ │ ├───barrel
│ │ ├───bass
│ │ ├───beaver
│ │ ├───binocular
│ │ ├───bonsai
│ │ ├───brain
│ │ ├───brontosaurus
...
2.导入依赖项
from fastai import *
from fastai.vision.all import *
from fastai.metrics import error_rate
import os
#from keras.utils import plot_model
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
查看环境以及版本信息,cuda.is_available()判断是否可以用GPU。
print(torch.cuda.is_available())
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
True
2.0.1
11.8
8700
'''SEED Everything'''
def seed_everything(SEED=42):
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
torch.backends.cudnn.benchmark = True # keep True if all the input have same size.
SEED=42
seed_everything(SEED=SEED)
'''SEED Everything'''
2.读入数据
代码如下(示例):
path='./data_image/101_ObjectCategories/'
image_rsize=224
item_tfms = [Resize((image_rsize,image_rsize))]
data = ImageDataLoaders.from_folder(path, train = '.', valid_pct=0.2,
size=image_rsize,
item_tfms=item_tfms)
data.show_batch(figsize=(7,6))

3.模型构建
这里使用预训练模型resnet101,这是一个非常优秀的残差网络模型。
这些残差网络更容易优化,并且可以从显着增加的深度中获得准确性。
这些残差网络的集合在 ImageNet 测试集上实现了 3.57% 的误差。该结果在ILSVRC 1分类任务中获得第一名。
learn = cnn_learner(data, models.resnet101, model_dir='./model', path = Path("."))
3.1 寻找合适的学习率
learn.lr_find()
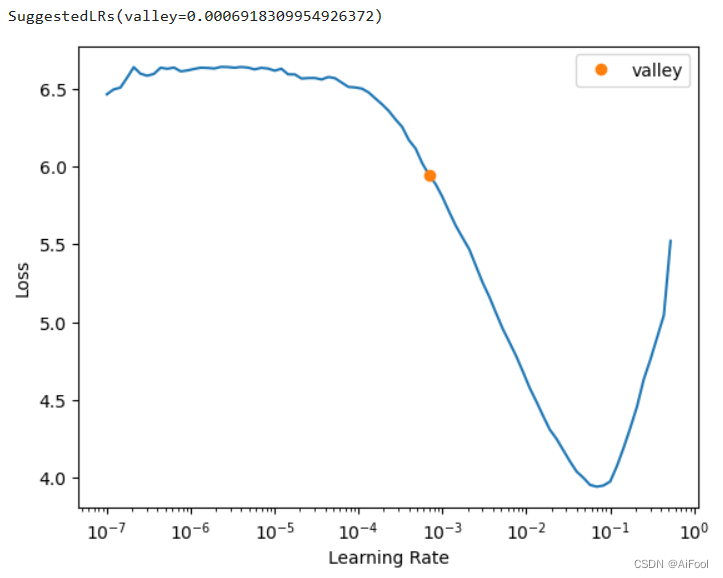
接下来使用fit_one_cycle方法用更小的学习率进一步训练。fit_one_cycle使用的是一种周期性学习率,从较小的学习率开始学习,缓慢提高至较高的学习率,然后再慢慢下降,周而复始,每个周期的长度略微缩短,在训练的最后部分,允许学习率比之前的最小值降得更低。这不仅可以加速训练,还有助于防止模型落入损失平面的陡峭区域,使模型更倾向于寻找更平坦的极小值,从而缓解过拟合现象。
lr1 = 1e-3
lr2 = 1e-1
epoch train_loss valid_loss time
0 1.417713 1.648756 00:45
1 3.097069 9.964518 00:43
2 5.385355 5.347832 00:44
3 4.194504 12.162844 00:44
4 2.985504 3.486863 00:43
5 2.152388 22.297184 00:43
6 1.295905 3.554162 00:43
7 0.630879 9.193820 00:43
8 0.361619 49.334236 00:43
9 0.255115 9.832499 00:43
3.2 模型调优
unfreeze
在fastai课程中使用的是预训练模型,模型卷积层的权重已经提前在ImageNet
上训练好了,在使用的时候一般只需要在预训练模型最后一层卷积层后添加自定义的全连接层即可。卷积层默认是freeze的,即在训练阶段进行反向传播时不会更新卷积层的权重,只会更新全连接层的权重。在训练几个epoch之后,全连接层的权重已经训练的差不多了,但accuracy还没有达到你的要求,这时你可以调用unfreeze然后再进行训练,这样在进行反向传播时便会更新卷积层的权重(一般不会对卷积层权重进行较大的更新,只会进行一点点的微调,越靠前的卷积层调整的幅度越小,所以有了differential
learning rate 这一想法)
precompute
当precompute=True时,会提前计算出每一个训练样本(不包括增强样本)在预训练模型最后一层卷积层的activation,
并将其缓存下来,之后在训练阶段进行前向传播的时候,直接将precompute 的activation 作为后面全连接层(FC
Layer)的输入,这样便省去前面卷积层进行前向传播的计算量,减少训练所需时间(这种优势在epoch比较大的时候能够显著0提高训练速度)。当precompute=False时,则不会提前计算训练样本的activation,每一个epoch都需要重新将训练样本+增强样本(前提是进行了增强操作)进行卷积层的前向传播,然后进行反向传播更新对应的权重。
learn.unfreeze()
learn.show_results()

从展示的部分训练结果可以看出,只有一张图被预测错误了,其他的都是正确的。
4.模型保存与应用
最后我们可以将模型保存下来,并且对验证集的图片的类别进行预测。
learn.export(Path("./model/export.pkl"))
from PIL import Image
img = Image.open(path+'ant/image_0001.jpg')
image_rsize=224
# Resize the image to 224x224
img_resized = img.resize((image_rsize,image_rsize))
pred, pred_idx, probs = learn.predict(img_resized)
im_t = cast(array(img_resized), TensorImage)
# Print the predicted label and probability
print(f"Predicted label: {pred}, probability: {probs[pred_idx]:.4f}")
img

总结
epoch train_loss valid_loss time
0 1.030772 979.477417 00:52
1 1.074642 86.289436 00:52
2 0.553576 0.457210 00:52
3 0.302997 0.546438 00:52
4 0.176070 0.596845 00:52
我们借助fastai训练了resnet101模型,对 101 个类别的图像数据集进行了分类。
使用基于pytorch的fastai库,使用resnet模型和有101个类别的Caltech101图像数据集,训练了一个高准确率的多分类的深度学习模型,能够对101个类别的图像大数据集进行准确的图像类别识别。
使用简洁高效的代码,借助GPU提升训练速度(也可以使用CPU训练,本项目会自动识别硬件),首先数据集进行预处理,然后对模型进行训练,并将模型保存为pkl格式,最后对测试集的图像的类别进行预测。
可见,使用fastai进行图像多分类是非常简便的,所使用的代码行数非常少却能达到很高的准确率,而且借助GPU训练速度非常快。
这里将全部的代码和图片数据集打包起来了,方便大家复现。
开箱即用,欢迎下载
使用fastai对Caltech101数据集进行图像多分类
人工智能-图像识别 系列文章目录
- 环境搭建: pytorch以及fastai安装,配置GPU训练环境 待更新。。。
- 使用fastai对Caltech101数据集进行图像多分类(50行以内的代码就可达到很高准确率)