文章目录
- 使用命令行参数初始化加载器
- 模型实例化
- 清空显存
- 加载模型调用链
- `loader.py`的`_load_model`方法
- `auto_factory.py`的`from_pretrained`方法
- `modeling_utils.py`的`from_pretrained`方法
- `hub.py`的`get_checkpoint_shard_files`方法
- `modeling_utils.py`的`_load_pretrained_mode`方法
- 回到`loader.py`的`_load_model`方法
使用命令行参数初始化加载器
loader.py
def __init__(self, params: dict = None):
"""
模型初始化
:param params:
"""
self.model = None
self.tokenizer = None
self.params = params or {}
self.model_name = params.get('model_name', False)
self.model_path = params.get('model_path', None)
self.no_remote_model = params.get('no_remote_model', False)
self.lora = params.get('lora', '')
self.use_ptuning_v2 = params.get('use_ptuning_v2', False)
self.lora_dir = params.get('lora_dir', '')
self.ptuning_dir = params.get('ptuning_dir', 'ptuning-v2')
self.load_in_8bit = params.get('load_in_8bit', False)
self.bf16 = params.get('bf16', False)
self.is_chatgmlcpp = "chatglm2-cpp" == self.model_name
模型实例化
shared.py
def loaderLLM(llm_model: str = None, no_remote_model: bool = False, use_ptuning_v2: bool = False) -> Any:
"""
init llm_model_ins LLM
:param llm_model: model_name
:param no_remote_model: remote in the model on loader checkpoint, if your load local model to add the ` --no-remote-model
:param use_ptuning_v2: Use p-tuning-v2 PrefixEncoder
:return:
"""
# 默认为chatglm2-6b-32k
pre_model_name = loaderCheckPoint.model_name
# model_config中chatglm2-6b-32k对应参数
llm_model_info = llm_model_dict[pre_model_name]
if no_remote_model:
loaderCheckPoint.no_remote_model = no_remote_model
if use_ptuning_v2:
loaderCheckPoint.use_ptuning_v2 = use_ptuning_v2
# 如果指定了参数,则使用参数的配置,默认为none
if llm_model:
llm_model_info = llm_model_dict[llm_model]
loaderCheckPoint.model_name = llm_model_info['name']
# 默认为THUDM/chatglm2-6b-32k
loaderCheckPoint.pretrained_model_name = llm_model_info['pretrained_model_name']
# 需手动指定路径
loaderCheckPoint.model_path = llm_model_info["local_model_path"]
# ChatGLMLLMChain
if 'FastChatOpenAILLM' in llm_model_info["provides"]:
loaderCheckPoint.unload_model()
else:
loaderCheckPoint.reload_model()
# 根据名称自动加载类:<class 'models.chatglm_llm.ChatGLMLLMChain'>
provides_class = getattr(sys.modules['models'], llm_model_info['provides'])
# 将类实例化为模型对象
modelInsLLM = provides_class(checkPoint=loaderCheckPoint)
if 'FastChatOpenAILLM' in llm_model_info["provides"]:
modelInsLLM.set_api_base_url(llm_model_info['api_base_url'])
modelInsLLM.call_model_name(llm_model_info['name'])
modelInsLLM.set_api_key(llm_model_info['api_key'])
return modelInsLLM
loader.py
def reload_model(self):
self.unload_model()
self.model_config = self._load_model_config()
if self.use_ptuning_v2:
try:
prefix_encoder_file = open(Path(f'{os.path.abspath(self.ptuning_dir)}/config.json'), 'r')
prefix_encoder_config = json.loads(prefix_encoder_file.read())
prefix_encoder_file.close()
self.model_config.pre_seq_len = prefix_encoder_config['pre_seq_len']
self.model_config.prefix_projection = prefix_encoder_config['prefix_projection']
except Exception as e:
print(e)
print("加载PrefixEncoder config.json失败")
self.model, self.tokenizer = self._load_model()
if self.lora:
self._add_lora_to_model([self.lora])
if self.use_ptuning_v2:
try:
prefix_state_dict = torch.load(Path(f'{os.path.abspath(self.ptuning_dir)}/pytorch_model.bin'))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
self.model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
self.model.transformer.prefix_encoder.float()
print("加载ptuning检查点成功!")
except Exception as e:
print(e)
print("加载PrefixEncoder模型参数失败")
# llama-cpp模型(至少vicuna-13b)的eval方法就是自身,其没有eval方法
if not self.is_llamacpp and not self.is_chatgmlcpp:
self.model = self.model.eval()
清空显存
在加载模型前先清空显存
loader.py
def unload_model(self):
del self.model
del self.tokenizer
self.model = self.tokenizer = None
self.clear_torch_cache()
def clear_torch_cache(self):
# 垃圾回收, 避免内存泄漏和优化内存使用
gc.collect()
if self.llm_device.lower() != "cpu":
# 检测系统是否支持MPS,这是是Apple在Mac设备上用于GPU加速的框架
if torch.has_mps:
try:
from torch.mps import empty_cache
empty_cache()
except Exception as e:
print(e)
print(
"如果您使用的是 macOS 建议将 pytorch 版本升级至 2.0.0 或更高版本,以支持及时清理 torch 产生的内存占用。")
elif torch.has_cuda:
device_id = "0" if torch.cuda.is_available() and (":" not in self.llm_device) else None
CUDA_DEVICE = f"{self.llm_device}:{device_id}" if device_id else self.llm_device
with torch.cuda.device(CUDA_DEVICE):
# 释放GPU显存缓存中的任何未使用的内存。
# PyTorch在GPU上申请和释放内存时,部分内存会保留在缓存中重复利用,
# empty_cache()可以释放这些缓存memory。
torch.cuda.empty_cache()
# 用于CUDA IPC内存共享的垃圾回收。
# 在多进程GPU训练中,进程间会共享部分内存,
# ipc_collect()可以显式收集共享内存垃圾。
torch.cuda.ipc_collect()
else:
print("未检测到 cuda 或 mps,暂不支持清理显存")
加载模型调用链
loader.py的_load_model方法
model = LoaderClass.from_pretrained(checkpoint,
config=self.model_config,
torch_dtype=torch.bfloat16 if self.bf16 else torch.float16,
trust_remote_code=True).half()
auto_factory.py的from_pretrained方法
包路径:site-packages/transformers/models/auto/auto_factory.py
作用:将配置对象的类与模型类或对象建立关联,以便根据配置来获取相应的模型类或对象。这通常用于管理不同配置下的模型选择和实例化。例如,根据不同的配置选择不同的模型架构或模型参数。
cls.register(config.__class__, model_class, exist_ok=True)
modeling_utils.py的from_pretrained方法
包路径:site-packages/transformers/modeling_utils.py
作用:因为没有显式指定模型路径,所以只能通过缓存方式下载和加载。
resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
# Since we set _raise_exceptions_for_missing_entries=False, we don't get an exception but a None
# result when internet is up, the repo and revision exist, but the file does not.
if resolved_archive_file is None and filename == _add_variant(SAFE_WEIGHTS_NAME, variant):
# Maybe the checkpoint is sharded, we try to grab the index name in this case.
resolved_archive_file = cached_file(
pretrained_model_name_or_path,
_add_variant(SAFE_WEIGHTS_INDEX_NAME, variant),
**cached_file_kwargs,
)
...
# We'll need to download and cache each checkpoint shard if the checkpoint is sharded.
if is_sharded:
# rsolved_archive_file becomes a list of files that point to the different checkpoint shards in this case.
resolved_archive_file, sharded_metadata = get_checkpoint_shard_files(
pretrained_model_name_or_path,
resolved_archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
use_auth_token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=commit_hash,
)
hub.py的get_checkpoint_shard_files方法
包路径:site-packages/transformers/utils/hub.py
作用:第一次启动项目时下载模型到本地缓存。
for shard_filename in tqdm(shard_filenames, desc="Downloading shards", disable=not show_progress_bar):
try:
# Load from URL
cached_filename = cached_file(
pretrained_model_name_or_path,
shard_filename,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=_commit_hash,
)
modeling_utils.py的_load_pretrained_mode方法
包路径:site-packages/transformers/modeling_utils.py
作用:遍历权重文件分片,逐一加载这些分片,但会跳过那些只包含磁盘上载权重的分片文件,显示加载的进度条,也就是下面这个东西,但此时模型权重还没有加载到显存中

if len(resolved_archive_file) > 1:
resolved_archive_file = logging.tqdm(resolved_archive_file, desc="Loading checkpoint shards")
for shard_file in resolved_archive_file:
# Skip the load for shards that only contain disk-offloaded weights when using safetensors for the offload.
if shard_file in disk_only_shard_files:
continue
state_dict = load_state_dict(shard_file)
回到loader.py的_load_model方法
这里主要是为了把模型加载到显存,可以使用多卡加载方式
else:
# 基于如下方式作为默认的多卡加载方案针对新模型基本不会失败
# 在chatglm2-6b,bloom-3b,blooz-7b1上进行了测试,GPU负载也相对均衡
from accelerate.utils import get_balanced_memory
max_memory = get_balanced_memory(model,
dtype=torch.int8 if self.load_in_8bit else None,
low_zero=False,
no_split_module_classes=model._no_split_modules)
self.device_map = infer_auto_device_map(model,
dtype=torch.float16 if not self.load_in_8bit else torch.int8,
max_memory=max_memory,
no_split_module_classes=model._no_split_modules)
model = dispatch_model(model, device_map=self.device_map)
-
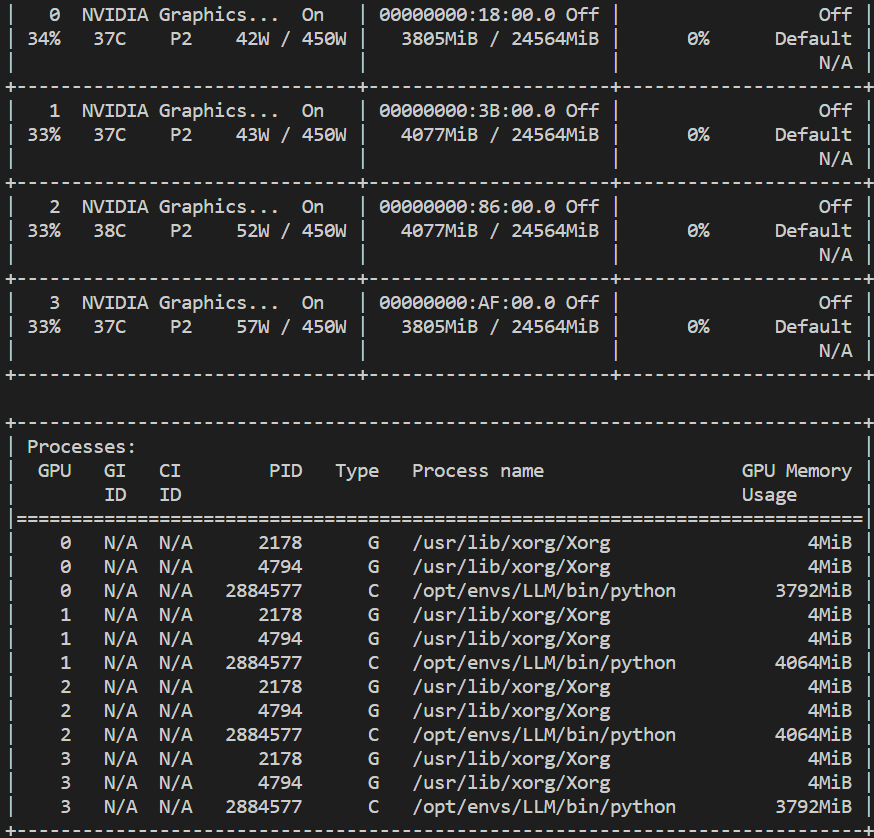
未执行上述代码之前,显存占用为0
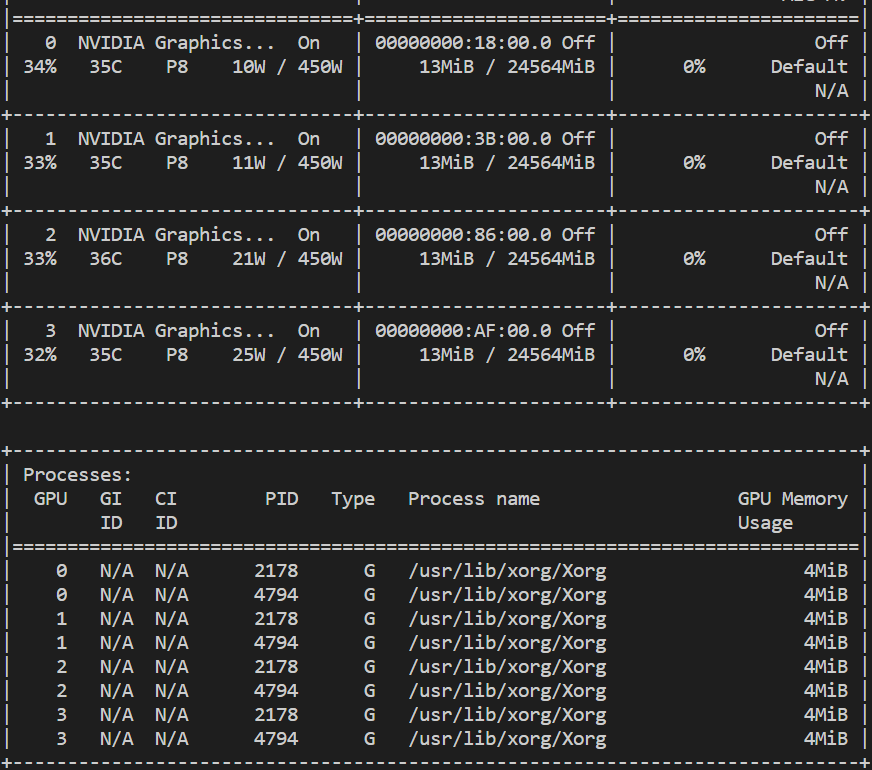
-
执行max_memory = get_balanced_memory(…):在这一部分代码中,通过调用 get_balanced_memory 函数来获取一个适当的内存分配方案,执行完后每个卡都会产生少量的显存占用

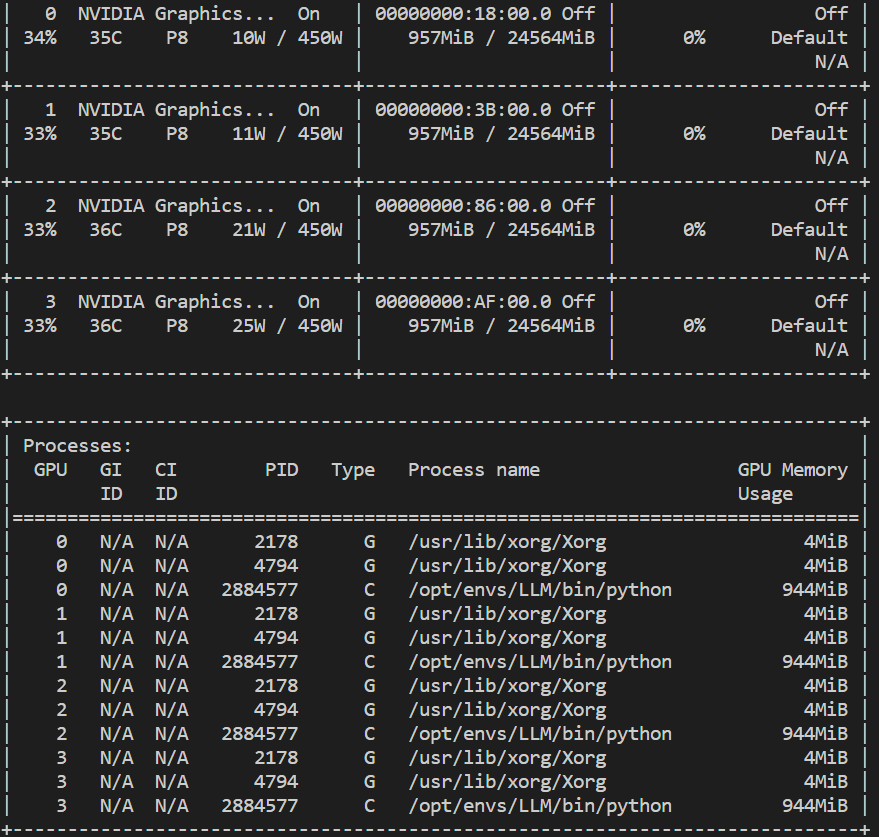
- 执行self.device_map = infer_auto_device_map(…):根据模型、数据类型、内存分配等信息来推断设备映射,将模型的不同部分分配到不同的设备上进行计算。
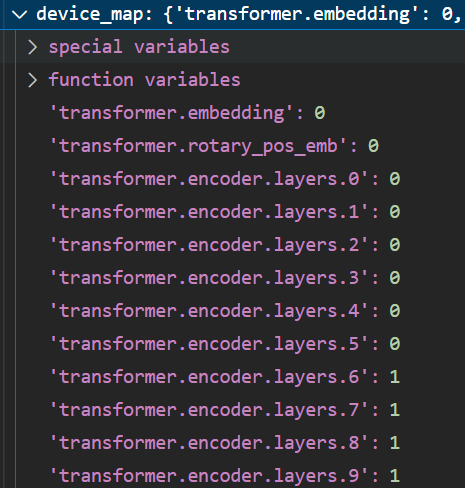
- 执行model = dispatch_model(model, device_map=self.device_map):根据生成的设备映射 将模型的不同部分分配到不同的设备上进行计算。这样,模型就可以利用多个GPU并行计算,以提高计算性能,模型权重被全部加载到显存。