摘要:本文作者阿里云 Hologres 高级研发工程师张高迪&阿里云 Flink 技术内容工程师张英男,本篇内容将为您介绍如何通过实时计算 Flink 版和实时数仓 Hologres 搭建实时数仓。
Tips:点击「阅读原文」免费领取 5000CU*小时 Flink 云资源
背景信息
随着社会数字化发展,企业对数据时效性的需求越来越强烈。除传统的面向海量数据加工场景设计的离线场景外,大量业务需要解决面向实时加工、实时存储、实时分析的实时场景问题。传统离线数仓搭建的方法论比较明确,通过定时调度实现数仓分层(ODS->DWD->DWS->ADS);但对于实时数仓的搭建,目前缺乏明确的方法体系。基于 Streaming Warehouse 理念,实现数仓分层之间实时数据的高效流动,可以解决实时数仓分层问题。
方案架构
实时计算 Flink 版是强大的流式计算引擎,支持对海量实时数据高效处理。Hologres 是一站式实时数仓,支持数据实时写入与更新,实时数据写入即可查。Hologres 与 Flink 深度集成,能够提供一体化的实时数仓联合解决方案。本文基于 Flink+Hologres 搭建实时数仓的方案架构如下:
1. Flink 将数据源写入 Hologres,形成 ODS 层。
2. Flink 订阅 ODS 层的 Binlog 进行加工,形成 DWD 层再次写入 Hologres。
3. Flink 订阅 DWD 层的 Binlog,通过计算形成 DWS 层,再次写入 Hologres。
4. 最后由 Hologres 对外提供应用查询。
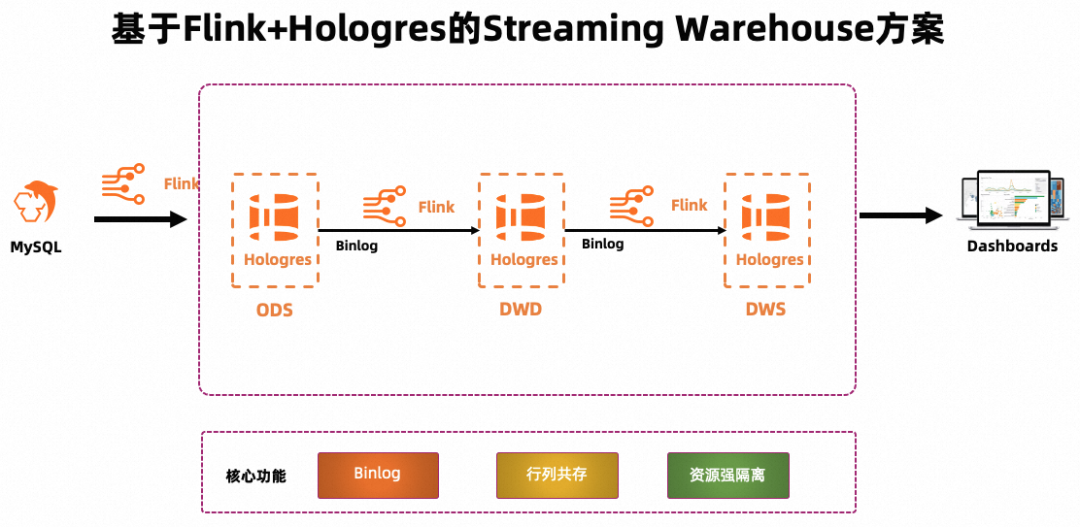
该方案有如下优势:
Hologres 的每一层数据都支持高效更新与修正、写入即可查,解决了传统实时数仓解决方案的中间层数据不易查、不易更新、不易修正的问题。
Hologres 的每一层数据都可单独对外提供服务,数据的高效复用,真正实现数仓分层复用的目标。
模型统一,架构简化。实时 ETL 链路的逻辑是基于 Flink SQL 实现的;ODS 层、DWD 层和 DWS 层的数据统一存储在 Hologres 中,可以降低架构复杂度,提高数据处理效率。
该方案依赖于 Hologres 的 3 个核心能力,详情如下表所示。
Hologres核心能力 | 详情 |
Binlog | Hologres提供Binlog能力,用于驱动Flink进行实时计算,以此作为流式计算的上游。Hologres的Binlog能力详情请参见订阅Hologres Binlog [1] 。 |
行列共存 | Hologres支持行列共存的存储格式。一张表同时存储行存数据和列存数据,并且两份数据强一致。该特性保证中间层表不仅可以作为Flink的源表,也可以作为Flink的维表进行主键点查与维表Join,还可以供其他应用(OLAP、线上服务等)查询。Hologres的行列共存能力详情请参见表存储格式:列存、行存、行列共存 [2] 。 |
资源强隔离 | Hologres实例的负载较高时,可能影响中间层的点查性能。Hologres支持通过主从实例读写分离部署(共享存储)[3] 或计算组实例架构 [4] 实现资源强隔离,从而保证Flink对Hologres Binlog的数据拉取不影响线上服务。 |
实践场景
本文以某个电商平台为例,通过搭建一套实时数仓,实现数据的实时加工清洗和对接上层应用数据查询,形成实时数据的分层和复用,支撑各个业务方的报表查询(交易大屏、行为数据分析、用户画像标签)以及个性化推荐等多个业务场景。
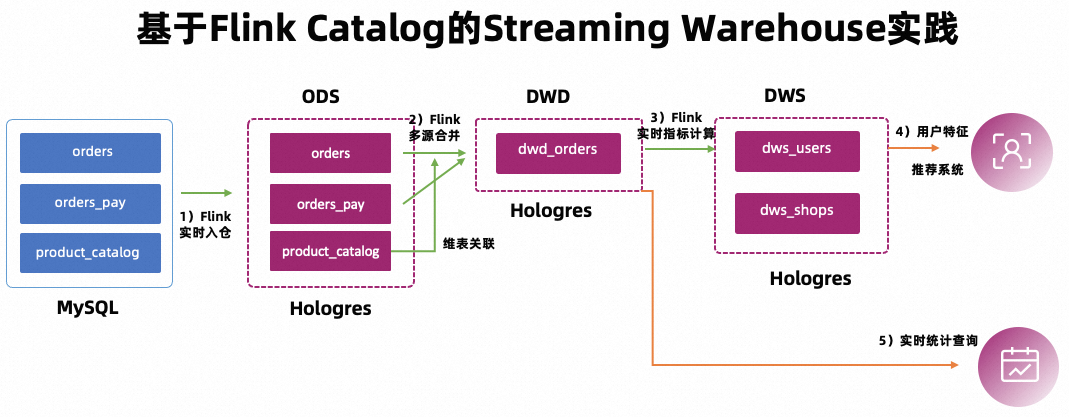
1. 构建 ODS 层:业务数据库实时入仓
MySQL 有 orders(订单表),orders_pay(订单支付表),product_catalog(商品类别字典表)3 张业务表,这 3 张表通过Flink实时同步到 Hologres 中作为 ODS 层。

2. 构建 DWD 层:实时主题宽表
将订单表、商品类别字典表、订单支付表进行实时打宽,生成 DWD 层宽表。
3. 构建 DWS 层:实时指标计算
实时消费宽表的 binlog,事件驱动的聚合出相应的 DWS 层指标表。
前提条件
已购买独享通用型 Hologres 实例,详情请参见购买 Hologres [5] 。
购买实例后,需要创建 order_dw 数据库和用户(为用户赋予 admin 权限),推荐使用简单权限模型创建数据库,详情请参见简单权限模型的使用 [6] 和 DB 管理 [7] 。
说明:
- Hologres1.3 版本在创建完数据库后,需要执行 create extension hg_binlog 命令才能开启 binlog 扩展。
- Hologres2.0 之后版本默认开启 binlog 扩展,无需手动执行。
已开通 Flink 全托管,详情请参见开通 Flink 全托管 [8] 。
说明:Flink 全托管需要与 Hologres 实例处于相同 VPC 和相同可用区。
已准备 MySQL CDC 数据源,order_dw 数据库中的三张业务表的建表 DDL 以及插入的数据如下。
CREATE TABLE `orders` (
order_id bigint not null primary key,
user_id varchar(50) not null,
shop_id bigint not null,
product_id bigint not null,
buy_fee numeric(20,2) not null,
create_time timestamp not null,
update_time timestamp not null default now(),
state int not null
);
CREATE TABLE `orders_pay` (
pay_id bigint not null primary key,
order_id bigint not null,
pay_platform int not null,
create_time timestamp not null
);
CREATE TABLE `product_catalog` (
product_id bigint not null primary key,
catalog_name varchar(50) not null
);
-- 准备数据
INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee');
INSERT INTO orders VALUES
(100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1),
(100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1),
(100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1),
(100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1),
(100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1),
(100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1),
(100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1);
INSERT INTO orders_pay VALUES
(2001, 100001, 1, '2023-02-15 17:40:56'),
(2002, 100002, 1, '2023-02-15 17:40:56'),
(2003, 100003, 0, '2023-02-15 17:40:56'),
(2004, 100004, 0, '2023-02-15 17:40:56'),
(2005, 100005, 0, '2023-02-15 18:40:56'),
(2006, 100006, 0, '2023-02-15 18:40:56'),
(2007, 100007, 0, '2023-02-15 18:40:56');使用限制
仅实时计算引擎 VVR 6.0.7 及以上版本支持该实时数仓方案。
仅 1.3 及以上版本的 Hologres 支持该实时数仓方案。
构建实时数仓
管理元数据
1. 创建 Hologres Catalog。
在实时计算控制台 [9] 上,新建一个名为 test 的 SQL 作业,将如下代码拷贝到 test 作业的 SQL 编辑器上,修改目标参数取值后,选中代码片段后单击左侧代码行上的运行。
CREATE CATALOG dw WITH (
'type' = 'hologres',
'endpoint' = '<ENDPOINT>',
'username' = '<USERNAME>',
'password' = '<PASSWORD>',
'dbname' = 'order_dw',
'binlog' = 'true', -- 创建catalog时可以设置源表、维表和结果表支持的with参数,之后在使用此catalog下的表时会默认添加这些默认参数。
'sdkMode' = 'jdbc', -- 推荐使用jdbc模式。
'cdcmode' = 'true',
'connectionpoolname' = 'the_conn_pool',
'ignoredelete' = 'true', -- 宽表merge需要开启,防止回撤。
'partial-insert.enabled' = 'true', -- 宽表merge需要开启此参数,实现部分列更新。
'mutateType' = 'insertOrUpdate', -- 宽表merge需要开启此参数,实现部分列更新。
'table_property.binlog.level' = 'replica', --也可以在创建catalog时传入持久化的hologres表属性,之后创建表时,默认都开启binlog。
'table_property.binlog.ttl' = '259200'
);您需要修改以下参数取值为您实际 Hologres 服务信息。
参数 | 说明 | 备注 |
endpoint | Hologres的Endpoint地址。 | 详情请参见实例配置 [10] 。 |
username | 阿里云账号的AccessKey。 | 当前配置的AccessKey对应的用户需要能够访问所有的Hologres数据库,Hologres数据库权限请参见Hologres权限模型概述 [11] 。 |
password | 阿里云账号的AccessSecret。 |
说明:创建 Catalog 时可以设置默认的源表、维表和结果表的 WITH 参数,也可以设置创建 Hologres 物理表的默认属性,例如上方 table_property 开头的参数。详情请参见管理 Hologres Catalog [12] 和实时数仓 Hologres WITH 参数 [13] 。
2. 创建 MySQL Catalog
在实时计算控制台 [9] ,将如下代码拷贝到 test 作业的 SQL 编辑器上,修改目标参数取值后,选中代码片段后单击左侧代码行上的运行。
CREATE CATALOG mysqlcatalog WITH(
'type' = 'mysql',
'hostname' = '<hostname>',
'port' = '<port>',
'username' = '<username>',
'password' = '<password>',
'default-database' = 'order_dw'
);您需要修改以下参数取值为您实际 MySQL 服务信息。
参数 | 说明 |
hostname | MySQL数据库的IP地址或者Hostname。 |
port | MySQL数据库服务的端口号,默认值为3306。 |
username | MySQL数据库服务的用户名。 |
password | MySQL数据库服务的密码。 |
构建 ODS 层:业务数据库实时入仓
基于 Catalog 的 CREATE DATABASE AS(CDAS)语句 [14]功能,可以一次性把 ODS 层建出来。ODS 层一般不直接做 OLAP 或 SERVING(KV 点查),主要作为流式作业的事件驱动,开启 binlog 即可满足需求。
1. 创建 CDAS 同步作业 ODS。
a. 在实时计算控制台 [9]上,新建名为 ODS 的 SQL 流作业,并将如下代码拷贝到 SQL 编辑器。
CREATE DATABASE IF NOT EXISTS dw.order_dw -- 创建catalog时设置了table_property.binlog.level参数,因此通过CDAS创建的所有表都开启了binlog。
AS DATABASE mysqlcatalog.order_dw INCLUDING all tables -- 可以根据需要选择上游数据库需要入仓的表。
/*+ OPTIONS('server-id'='8001-8004') */ ; -- 指定mysql-cdc源表。b. 单击右上方的部署,进行作业部署。
c. 单击左侧导航栏的作业运维,单击刚刚部署的 ODS 作业操作列的启动,启动作业。
2. 查看 MySQL 同步到 Hologres 的 3 张表数据。
在 HoloWeb 开发页面连接 Hologres 实例并登录目标数据库后,在 SQL 编辑器上执行如下命令。
---查orders中的数据。
SELECT * FROM orders;
---查orders_pay中的数据。
SELECT * FROM orders_pay;
---查product_catalog中的数据。
SELECT * FROM product_catalog;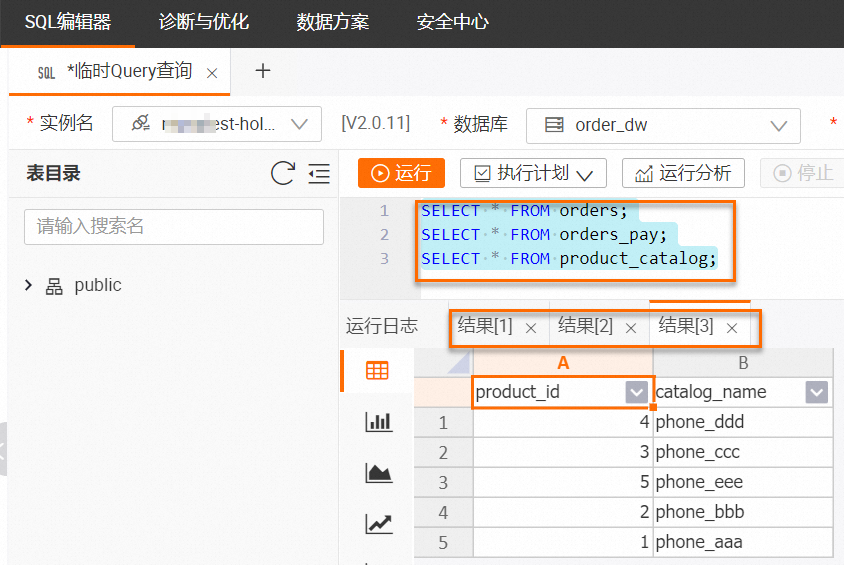
构建 DWD 层:实时主题宽表
1. 通过 Flink Catalog 功能在 Hologres 中建 DWD 层的宽表 dwd_orders。
在实时计算控制台 [9]上,将如下代码拷贝到 test 作业的 SQL 编辑器后,选中目标片段后单击左侧代码行上的运行。
-- 宽表字段要nullable,因为不同的流写入到同一张结果表,每一列都可能出现null的情况。
CREATE TABLE dw.order_dw.dwd_orders (
order_id bigint not null primary key,
order_user_id string,
order_shop_id bigint,
order_product_id bigint,
order_product_catalog_name string,
order_fee numeric(20,2),
order_create_time timestamp,
order_update_time timestamp,
order_state int,
pay_id bigint,
pay_platform int comment 'platform 0: phone, 1: pc', -- catalog建表可以设置注释。
pay_create_time timestamp
);
-- 支持通过catalog修改Hologres物理表属性。
ALTER TABLE dw.order_dw.dwd_orders SET (
'table_property.binlog.ttl' = '604800' --修改binlog的超时时间为一周。
);2. 实现实时消费 ODS 层 orders、orders_pay 表的 binlog。
在实时计算控制台 [9]上,新建名为 DWD 的 SQL 作业,并将如下代码拷贝到 SQL 编辑器后,部署并启动作业。通过如下 SQL 作业,orders 表会与 product_catalog 表进行维表关联,将最终结果写入 dwd_orders 表中,实现数据的实时打宽。
BEGIN STATEMENT SET;
INSERT INTO dw.order_dw.dwd_orders
(
order_id,
order_user_id,
order_shop_id,
order_product_id,
order_fee,
order_create_time,
order_update_time,
order_state,
order_product_catalog_name
) SELECT o.*, dim.catalog_name
FROM dw.order_dw.orders as o
LEFT JOIN dw.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim
ON o.product_id = dim.product_id;
INSERT INTO dw.order_dw.dwd_orders
(pay_id, order_id, pay_platform, pay_create_time)
SELECT * FROM dw.order_dw.orders_pay;
END;3. 查看宽表 dwd_orders 数据。
在 HoloWeb 开发页面连接 Hologres 实例并登录目标数据库后,在 SQL 编辑器上执行如下命令。
SELECT * FROM dwd_orders;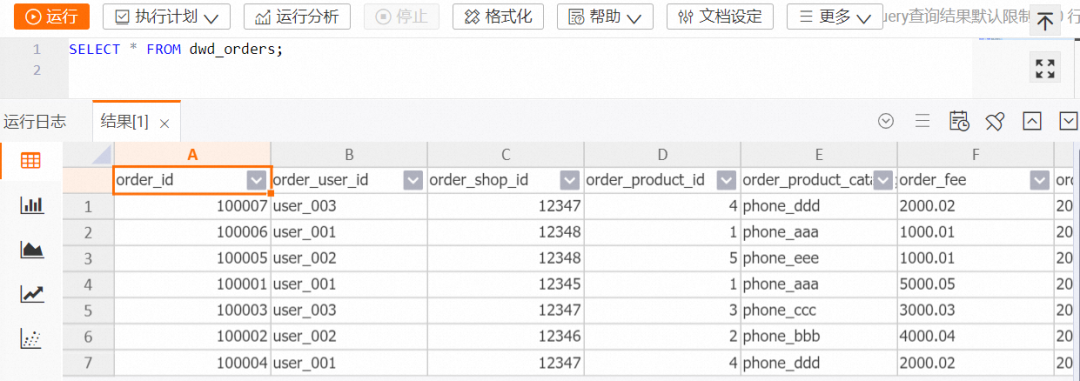
构建 DWS 层:实时指标计算
1. 通过 Flink Catalog 功能,在 Hologres 中创建 dws 层的聚合 dws_users 以及 dws_shops。
在实时计算控制台 [9]上,将如下代码拷贝到 test 作业的 SQL 编辑器,选中目标片段后单击左侧代码行上的运行。
-- 用户维度聚合指标表。
CREATE TABLE dw.order_dw.dws_users (
user_id string not null,
ds string not null,
paied_buy_fee_sum numeric(20,2) not null, -- 当日完成支付的总金额。
primary key(user_id,ds) NOT ENFORCED
);
-- 商户维度聚合指标表。
CREATE TABLE dw.order_dw.dws_shops (
shop_id bigint not null,
ds string not null,
paied_buy_fee_sum numeric(20,2) not null, -- 当日完成支付总金额。
primary key(shop_id,ds) NOT ENFORCED
);2. 实时消费 DWD 层的宽表 dw.order_dw.dwd_orders,在 Flink 中做聚合计算,最终写入 Hologres 中的 DWS 表。
在实时计算控制台 [9]上,新建名为 DWS 的 SQL 流作业,并将如下代码拷贝到 SQL 编辑器,部署并启动作业。
BEGIN STATEMENT SET;
INSERT INTO dw.order_dw.dws_users
SELECT
order_user_id,
DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds,
SUM (order_fee)
FROM dw.order_dw.dwd_orders c
WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 订单流和支付流数据都已写入宽表。
GROUP BY order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd');
INSERT INTO dw.order_dw.dws_shops
SELECT
order_shop_id,
DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds,
SUM (order_fee)
FROM dw.order_dw.dwd_orders c
WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 订单流和支付流数据都已写入宽表。
GROUP BY order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd');
END;3. 查看 DWS 层的聚合结果,其结果会根据上游数据的变更实时更新。
在 HoloWeb 开发页面连接 Hologres 实例并登录目标数据库后,在 SQL 编辑器上执行如下命令。
查询 dws_users 表结果。
SELECT * FROM dws_users;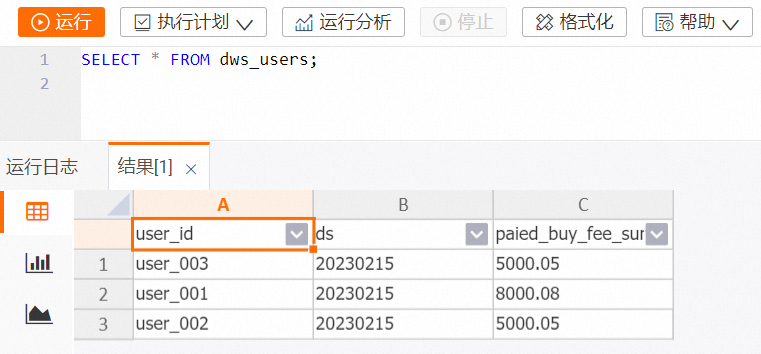
查询 dws_shops 表结果。
SELECT * FROM dws_shops;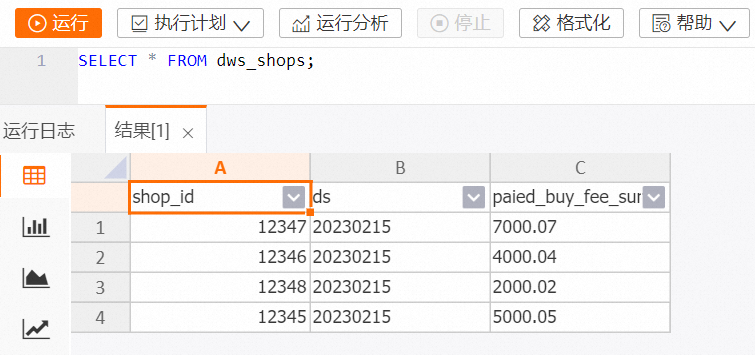
数据探查
如果对中间结果需要即系(Ad-hoc)性质的业务数据探查,或者对最终计算结果进行数据正确性排查,此方案的每一层数据都实现了持久化,可以便捷的探查中间过程。
流模式探查
a. 新建并启动数据探查流作业。
在实时计算控制台 [9]上,新建名为 Data-exploration 的 SQL 流作业,并将如下代码拷贝到 SQL 编辑器后,部署并启动作业。
-- 流模式探查,打印到print可以看到数据的变化情况。
CREATE TEMPORARY TABLE print_sink(
order_id bigint not null primary key,
order_user_id string,
order_shop_id bigint,
order_product_id bigint,
order_product_catalog_name string,
order_fee numeric(20,2),
order_create_time timestamp,
order_update_time timestamp,
order_state int,
pay_id bigint,
pay_platform int,
pay_create_time timestamp
) WITH (
'connector' = 'print'
);
INSERT INTO print_sink SELECT *
FROM dw.order_dw.dwd_orders /*+ OPTIONS('startTime'='2023-02-15 12:00:00') */ --这里的startTime是binlog生成的时间
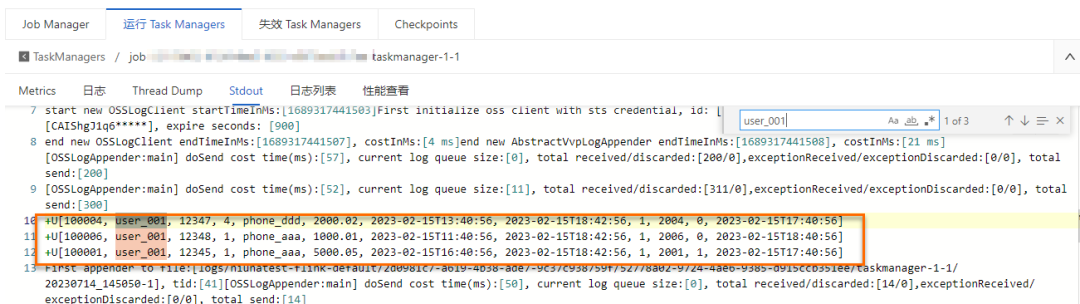
WHERE order_user_id = 'user_001';b. 查看数据探查结果。
在作业运维详情页面,单击目标作业名称,在作业探查页签下左侧运行日志页签,单击运行 Task Managers 页签下的 Path, ID。在 Stdout 页面搜索 user_001 相关的日志信息。
批模式探查
在实时计算控制台 [9]上,创建 SQL 流作业,并将如下代码拷贝到 SQL 编辑器后,单击调试。详情请参见作业调试 [15]。
批模式探查是获取当前时刻的终态数据,在 Flink 作业开发界面调试结果如下图所示。
SELECT *
FROM dw.order_dw.dwd_orders /*+ OPTIONS('binlog'='false') */
WHERE order_user_id = 'user_001' and order_create_time > '2023-02-15 12:00:00'; --批量模式支持filter下推,提升批作业执行效率。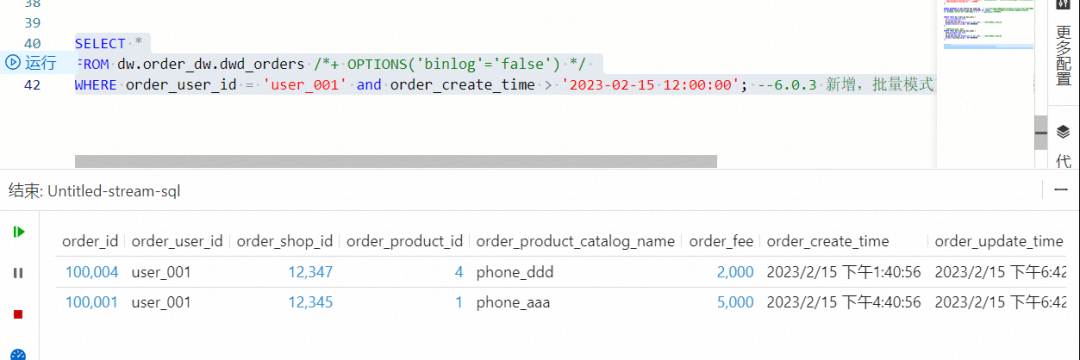
使用实时数仓
上一小节展示了通过 Flink Catalog,可以仅在 Flink 侧搭建一个基于 Flink 和 Hologres的Streaming Warehouse 实时分层数仓。本节则展示数仓搭建完成之后的一些简单应用场景。
Key-Value 服务
根据主键查询 DWS 层的聚合指标表,支持百万级 RPS。
在 HoloWeb 开发页面查询指定用户指定日期的消费额的代码示例如下。
-- holo sql
SELECT * FROM dws_users WHERE user_id ='user_001' AND ds = '20230215';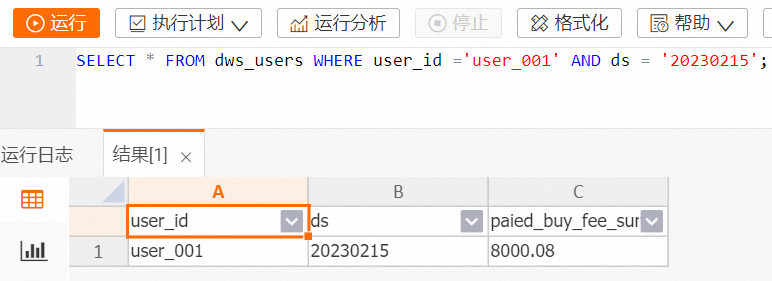
明细查询
对 DWD 层宽表进行 OLAP 分析。
在 HoloWeb 开发页面查询某个客户 23 年 2 月特定支付平台支付的订单明细的代码示例如下。
-- holo sql
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time LIMIT 100;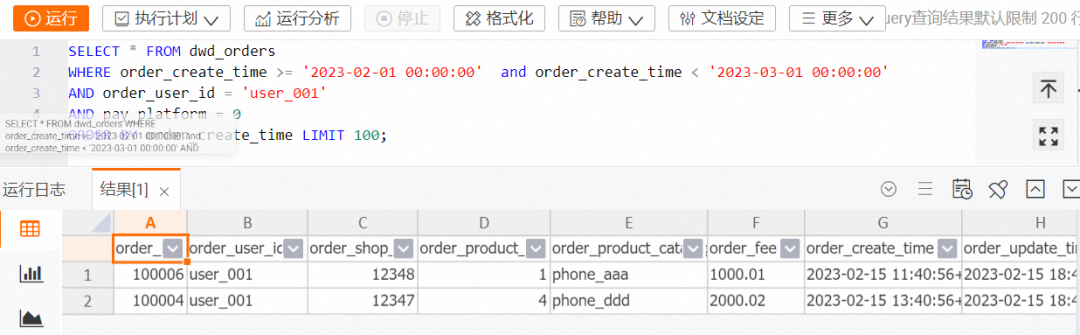
实时报表
基于 DWD 层宽表数据展示实时报表,支持秒级响应。
在 HoloWeb 开发页面查询 23 年 2 月内每个品类的订单总量和订单总金额的代码示例如下。
-- holo sql
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD'),
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
1, 2
ORDER BY
1, 2;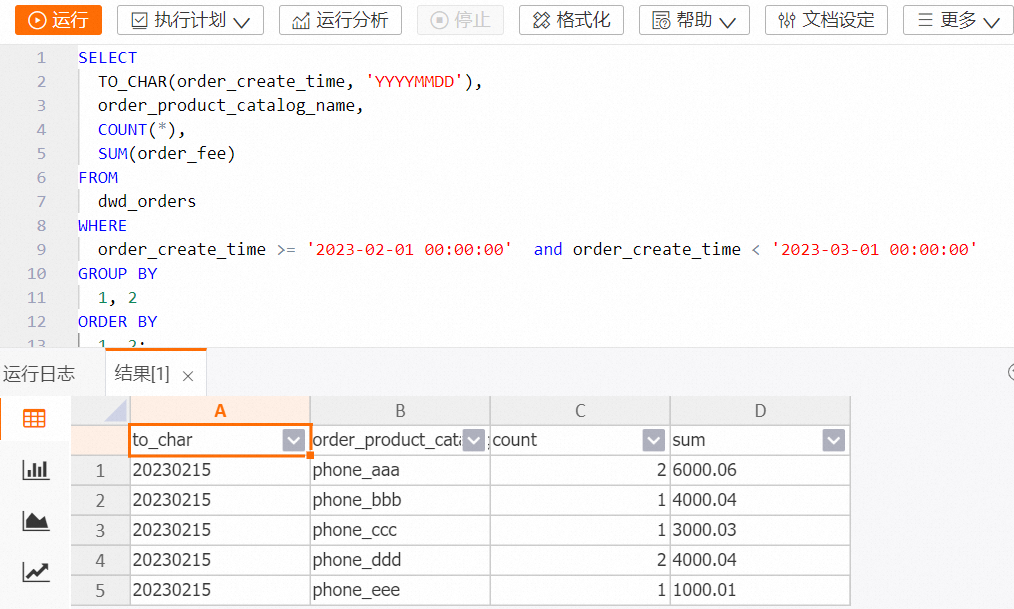
参考
[1] 订阅 Hologres Binlog:
https://help.aliyun.com/zh/hologres/user-guide/subscribe-to-hologres-binary-logs
[2] 表存储格式:列存、行存、行列共存:
https://help.aliyun.com/zh/hologres/user-guide/storage-models-of-tables
[3] 主从实例读写分离部署(共享存储):
https://help.aliyun.com/zh/hologres/user-guide/configure-multi-instance-high-availability-deployment
[4] 计算组实例架构:
https://help.aliyun.com/zh/hologres/user-guide/architecture-of-virtual-warehouses
[5] 购买 Hologres:
https://help.aliyun.com/zh/hologres/getting-started/purchase-a-hologres-instance
[6] 简单权限模型的使用:
https://help.aliyun.com/zh/hologres/user-guide/use-the-spm
[7] DB 管理:
https://help.aliyun.com/zh/hologres/user-guide/manage-databases
[8] 开通 Flink 全托管:
https://help.aliyun.com/zh/flink/getting-started/activate-fully-managed-flink
[9] 实时计算控制台:
https://realtime-compute.console.aliyun.com/regions/cn-shanghai#/region/cn-hangzhou/resource/all/dashboard/serverless/asi
[10] 实例配置:
https://help.aliyun.com/zh/hologres/user-guide/instance-configurations?spm=a2c4g.11186623.0.0.7d706105cYpaCU
[11] Hologres 权限模型概述:
https://help.aliyun.com/zh/hologres/user-guide/overview#concept-2021277
[12] 管理 Hologres Catalog:
https://help.aliyun.com/zh/flink/user-guide/manage-hologres-catalogs
[13] 实时数仓 Hologres WITH 参数:
https://help.aliyun.com/zh/flink/developer-reference/hologres-connector
[14] CREATE DATABASE AS(CDAS)语句:
https://help.aliyun.com/zh/flink/developer-reference/create-database-as-statement?spm=a2c4g.11186623.0.0.7d706105cYpaCU
[15] 作业调试:
https://help.aliyun.com/zh/flink/user-guide/debug-a-deployment
8/26 活动预告
活动时间:8 月 26 日 13:00
活动地点:北京阿里中心·望京 A 座
线下报名地址:https://developer.aliyun.com/trainingcamp/4bb294cf64b04a2a8b3f8b153e188e9f
线上直播观看地址:https://gdcop.h5.xeknow.com/sl/1l4Sye
活动详情:专家老师带教!现场答疑!阿里云实时计算 Flink 版线下训练营北京站来啦!
▼ 「8/26 活动预告」扫下方图片预约线上直播 ▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源
点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源