第一步:将作者所给代码跑通。
下载代码,放置在本地文件夹。
报错问题一:
使用hugging face 中loaddataset函数报错。显示connect error。
修改如下:将数据集下载文件.py文件在本地,然后从.py文件中加载数据集。

解决方式参考:https://blog.csdn.net/weixin_49346755/article/details/125284869#:~:text=load_dataset%E5%87%BD%E6%95%B0%E4%BB%8EHugging%20Face%20Hub%E6%88%96%E8%80%85%E6%9C%AC%E5%9C%B0%E6%95%B0%E6%8D%AE%E9%9B%86%E6%96%87%E4%BB%B6%E4%B8%AD%E5%8A%A0%E8%BD%BD%E4%B8%80%E4%B8%AA%E6%95%B0%E6%8D%AE%E9%9B%86%E3%80%82,%E5%8F%AF%E4%BB%A5%E9%80%9A%E8%BF%87%20https%3A%2F%2Fhuggingface.co%2Fdatasets%20%E6%88%96%E8%80%85datasets.list_datasets%20%28%29%E5%87%BD%E6%95%B0%E6%9D%A5%E8%8E%B7%E5%8F%96%E6%89%80%E6%9C%89%E5%8F%AF%E7%94%A8%E7%9A%84%E6%95%B0%E6%8D%AE%E9%9B%86%E3%80%82
问题2:tensor数据类型报错。
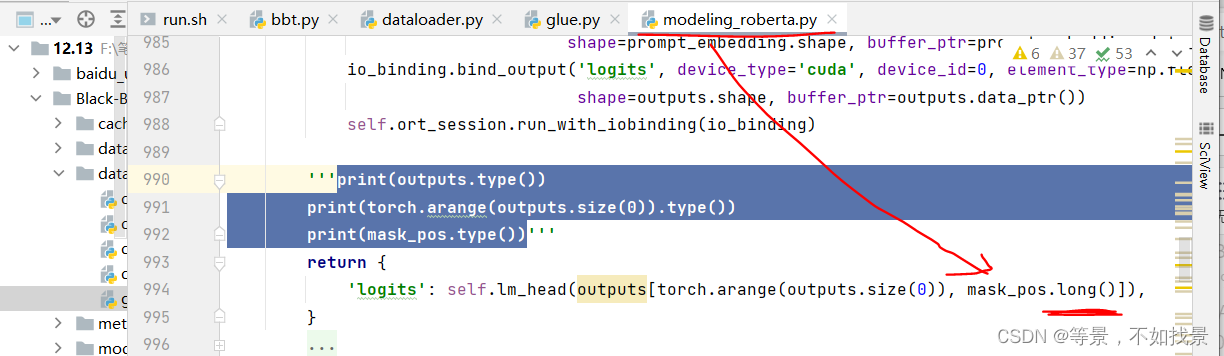
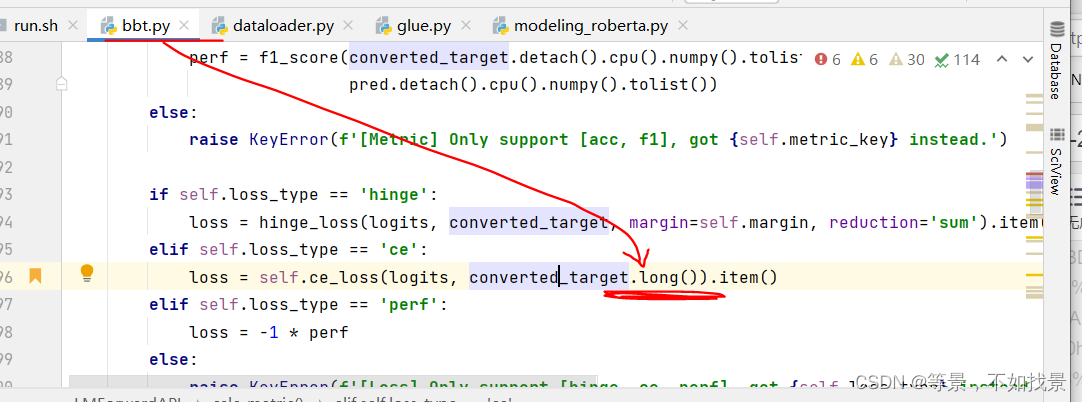
代码运行结果:
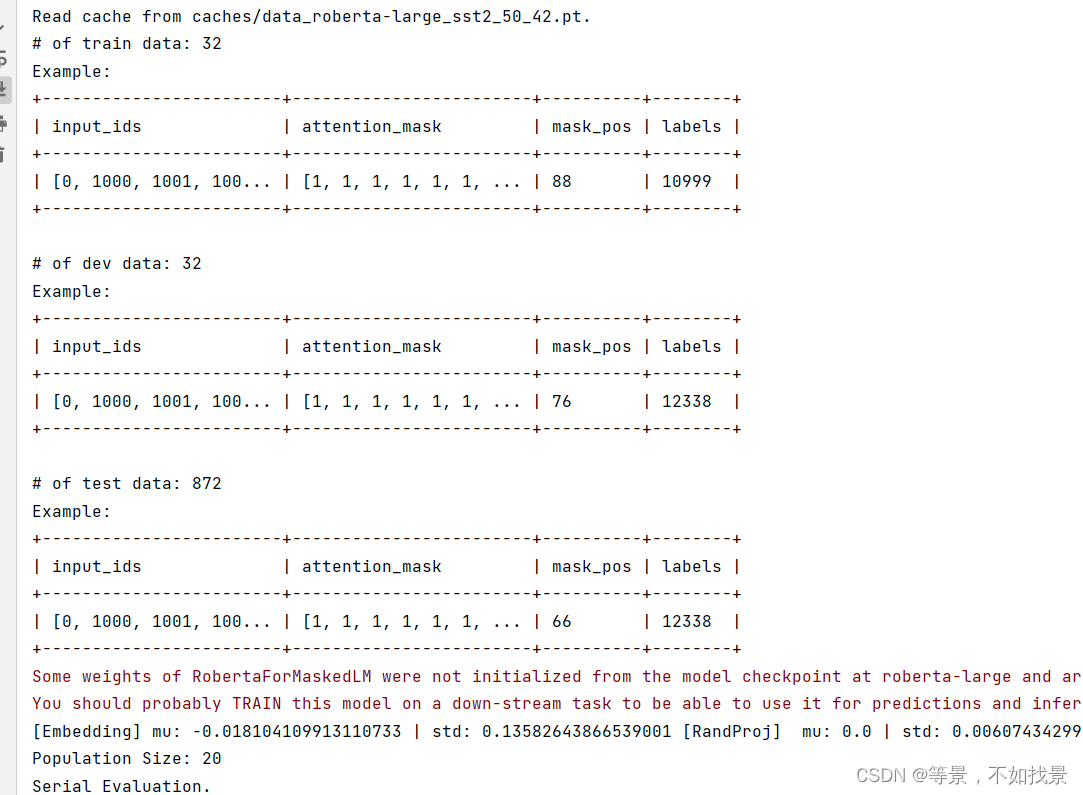
第二步,按照论文看代码框架
重点想看下PLM的API应该如何调用?
数据集、model、train、test。
1.数据集是SST2。
SST2 数据集是电影情感分类数据集,是二分类数据集。
在train和dev数据集中,表头包含了sentence,label两列。
代码
model选择的是Roberta-large
num_labels = 2
tokenizer = RobertaTokenizer.from_pretrained(model_name)
loss=hinge_loss
metrics 选择是 f1-score
1 数据加载
数据加载:两种方式(cat or add)
data_bundle=Dataloader()——>dataloader采用的是SST2Loader,
数据加载采用的 my_load 函数
fastnlp中Loader函数:https://fastnlp.readthedocs.io/zh/latest/fastNLP.io.loader.html?highlight=io#module-fastNLP.io.loader
Loader用于读取数据,并将内容读取到 DataSet 或者 DataBundle 中。所有的Loader都支持以下的 三个方法: init , _load , loads . 其中 init(…) 用于申明读取参数,以及说明该Loader支持的数据格式, 读取后 DataSet 中的 field ; _load(path) 方法传入文件路径读取单个文件,并返回 DataSet ; load(paths) 用于读取文件夹下的文件,并返回 DataBundle 类型的对象 , load()方法支持以下几种类型的参数:
hugging face的datasets数据库,用于加载数据集。
用到了load_dataset 和 map函数。
partial函数
>map函数和partial函数好像都是为了加快模型训练速度构造的一个函数。
data_bundle = DataLoader[task_name](tokenizer=tokenizer, n_prompt_tokens=0).my_load(splits)
数据加载
ds = DataSet()
ds.append(Instance(**example))
splits=[‘train’,‘dev’]
datasets = {name: self._load(name) for name in splits}
data_bundle = DataBundle(datasets=datasets)
2 构建小样本数据集
-
np.random.shuffle(all_indices)
打乱数据集顺序之后,按照k-shot的数量抽取得到的最终数据集。 -
dataset.set_input(‘index’)
dataset.set_target(“labels”)
生成train_data, dev_data ——construct_true_few_shot_data -
set_pad_val()函数,将padding_tokens填充???
通过 DataSet.set_input(‘words’, ‘chars’) , fastNLP将认为 words 和 chars 这两个field都是input,并将它们都放入迭代器 生成的第一个dict中; DataSet.set_target(‘labels’) , fastNLP将认为 labels 这个field是target,并将其放入到迭代器的第 二个dict中。如上例中所打印结果。分为input和target的原因是由于它们在被 Trainer 所使用时会有所差异, 详见 Trainer
官网
3 构建送入模型的数据集
train_data = {
‘input_ids’: torch.tensor(train_data[‘input_ids’].get(list(range(len(train_data))))),
‘attention_mask’: torch.tensor(train_data[‘attention_mask’].get(list(range(len(train_data))))),
‘mask_pos’: torch.tensor(train_data[‘mask_pos’].get(list(range(len(train_data))))),
‘labels’: torch.tensor(train_data[‘labels’].get(list(range(len(train_data))))),
}
dev_data = {
‘input_ids’: torch.tensor(dev_data[‘input_ids’].get(list(range(len(dev_data))))),
‘attention_mask’: torch.tensor(dev_data[‘attention_mask’].get(list(range(len(dev_data))))),
‘mask_pos’: torch.tensor(dev_data[‘mask_pos’].get(list(range(len(dev_data))))),
‘labels’: torch.tensor(dev_data[‘labels’].get(list(range(len(dev_data))))),
}
2 模型API接入
论文中从高维向量表征空间映射到低维向量表征空间,采用的add方式。
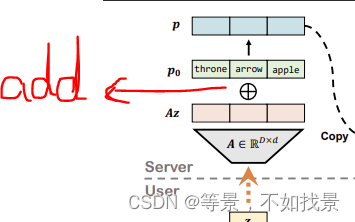
在代码中,提供了两种可选择的方式:cat和add.
if cat_or_add == 'cat':
self.model.set_concat_prompt(True)
if init_prompt_path is not None:
print('Initialize prompt embedding from {}'.format(init_prompt_path))
self.init_prompt = torch.load(init_prompt_path).weight.cpu().reshape(-1)
else:
print('Initial prompt embedding not found. Initialize to zero embedding.')
self.init_prompt = torch.zeros(n_prompt_tokens * self.config.hidden_size)
print('Shape of initial prompt embedding: {}'.format(self.init_prompt.shape))
映射矩阵A是通过线性变化实现的。函数表征形式为:
linear = torch.nn.Linear(intrinsic_dim, n_prompt_tokens * self.config.hidden_size, bias=False)
其中,intrinsic_dim=500,n_prompt_tokens=50
project方式采用“正态分布”——normal。
embedding = self.model.roberta.get_input_embeddings().weight.clone().cpu()
mu_hat = np.mean(embedding.reshape(-1).detach().cpu().numpy())
std_hat = np.std(embedding.reshape(-1).detach().cpu().numpy())
mu = 0.0
std = alpha * std_hat / (np.sqrt(intrinsic_dim) * sigma)
**model **
model = RobertaForMaskedLM.from_pretrained(
model_name,
config=self.config,
n_prompt_tokens=n_prompt_tokens,
inference_framework=inference_framework,
onnx_model_path=onnx_model_path,
)
evaluation process:train
for k, v in train_data.items():
train_data[k] = v.to(device)
with torch.no_grad():
if model_name in ['t5-small', 't5-base', 't5-large', 't5-3b']:
logits = self.model(
input_ids=train_data['input_ids'],
attention_mask=train_data['attention_mask'],
decoder_input_ids=train_data['decoder_input_ids'],
decoder_attention_mask=train_data['decoder_attention_mask'],
)['logits']
elif model_name in ['gpt2', 'gpt2-medium', 'gpt2-large', 'gpt2-xl']:
logits = self.model(
input_ids=train_data['input_ids'],
attention_mask=train_data['attention_mask'],
)['logits']
else:
logits = self.model(
input_ids=train_data['input_ids'],
attention_mask=train_data['attention_mask'],
mask_pos=train_data['mask_pos'],
)['logits']
evaluation process:dev
if dev_perf > self.best_dev_perf:
self.best_dev_perf = dev_perf
# fitlog.add_best_metric(self.best_dev_perf, name='dev_acc')
self.best_prompt = copy.deepcopy(tmp_prompt)
3 Evaluation
对于sst2任务,采用SST2Metric评估方式。
采用的是fastnlp的BaseMetric框架。
损失函数:
- nn.CrossEntropyLoss(reduction=‘sum’)
- hinge_loss(pred, hinge_target, self.margin, reduction=‘sum’).item()
hinge_loss = self.hinge / len(self._target)
ce_loss = self.ce_loss / len(self._target)
CMA 评测:es = cma.CMAEvolutionStrategy(intrinsic_dim * [0], sigma, inopts=cma_opts)
4 总结
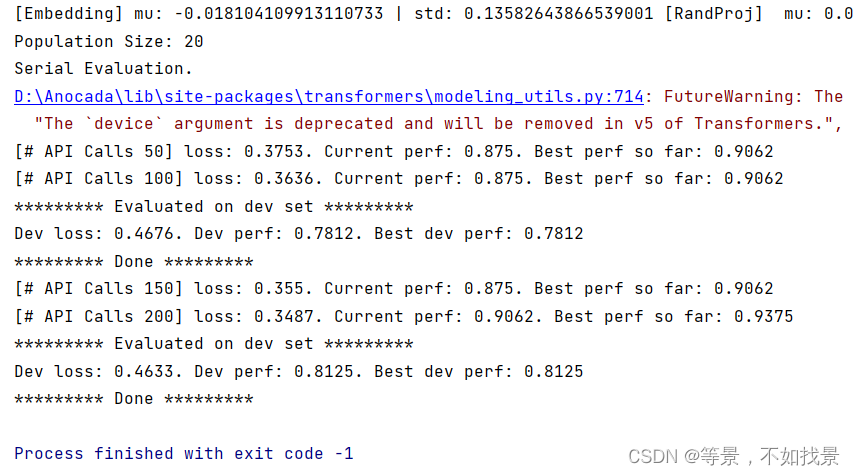
模型效果可以越来越好,是cma evalaution在起作用??
整个valid过程中,当新的valid score的评测分值超过上一次的valid score时,模型才会保留prompt。
整个建模中,API并不是以http形式出现,是以大模型参数形式出现的。
模型代码中主要用到了fastnlp库。