目录
- 一、Exercise
- 1.1、Exercise1: Filter and Join
- 1.2、Exercise2: Aggregates
- 1.3、Exercise 3:HeapFile Mutability
- 1.4、Exercise 4:Insertion and deletion
- 1.5、Exercise 5: Page eviction
- 二、总结
一、Exercise
1.1、Exercise1: Filter and Join
在Exercise1中要完成的是Filter与Join两个操作。
- Filter中实现的是返回满足过滤条件的元组,Predicate是其构造函数的一部分。
- Join中实现的是两个元素的自然联结,JoinPredicate是其构造函数的一部分。其中Join联结实现的方式是嵌套循环。
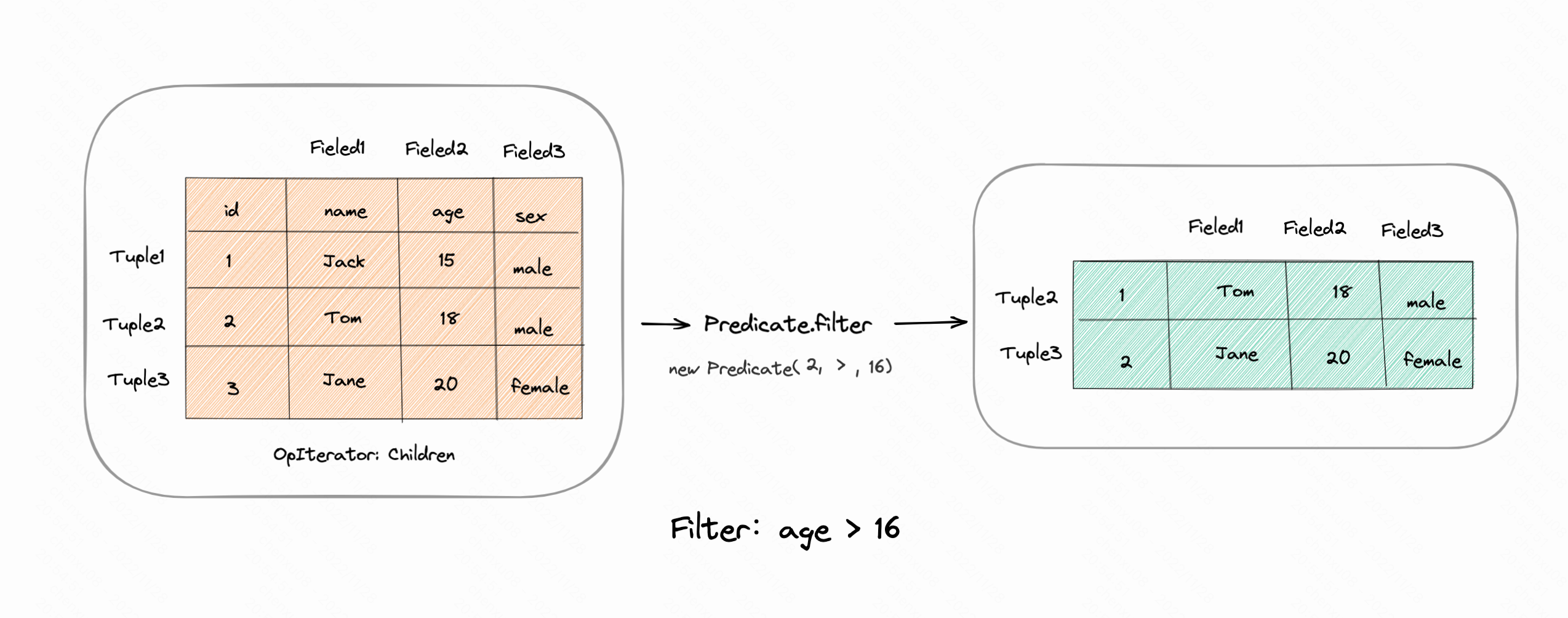
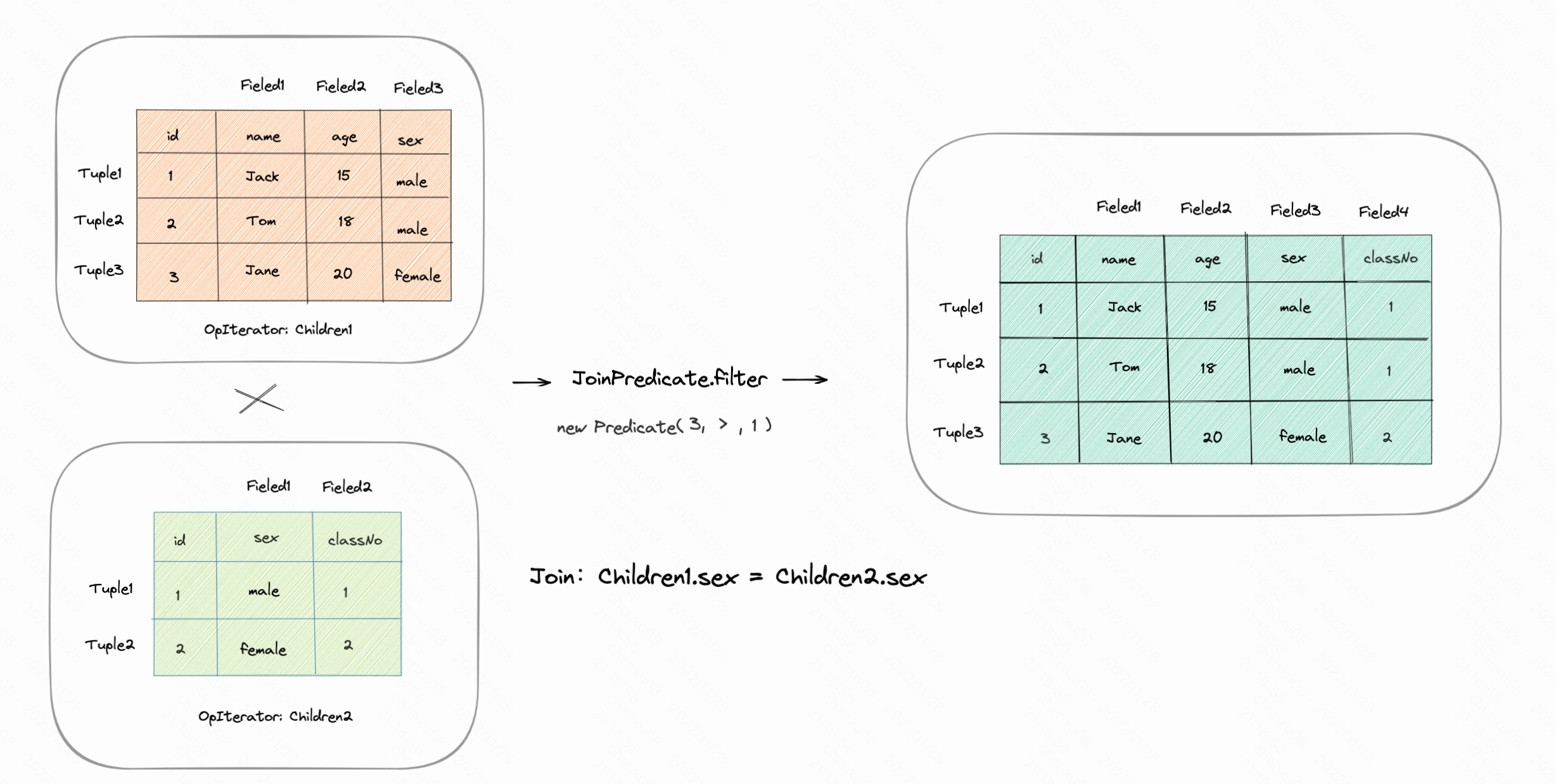
对于这两个操作都有对应的谓词辅助类Predicate、JoinPredicate。帮助去对比元组字段之间是否符合条件。笔者简单画个图:
- Filter: 过滤年龄大于16的元组。
- Join:对两个chidren中的sex字段进行自然连接。
- Predicate Class:
public class Predicate implements Serializable {
private static final long serialVersionUID = 1L;
/**
* field number of passed in tuples to compare against.
*/
private int fieldIndex;
/**
* operation to use for comparison
*/
private Op op;
/**
* field value to compare passed in tuples to
*/
private Field operand;
/**
* Constants used for return codes in Field.compare
*/
public enum Op implements Serializable {
EQUALS, GREATER_THAN, LESS_THAN, LESS_THAN_OR_EQ, GREATER_THAN_OR_EQ, LIKE, NOT_EQUALS;
/**
* Interface to access operations by integer value for command-line
* convenience.
*
* @param i a valid integer Op index
*/
public static Op getOp(int i) {
return values()[i];
}
public String toString() {
if (this == EQUALS)
return "=";
if (this == GREATER_THAN)
return ">";
if (this == LESS_THAN)
return "<";
if (this == LESS_THAN_OR_EQ)
return "<=";
if (this == GREATER_THAN_OR_EQ)
return ">=";
if (this == LIKE)
return "LIKE";
if (this == NOT_EQUALS)
return "<>";
throw new IllegalStateException("impossible to reach here");
}
}
/**
* Constructor.
*
* @param field field number of passed in tuples to compare against.
* @param op operation to use for comparison
* @param operand field value to compare passed in tuples to
*/
public Predicate(int field, Op op, Field operand) {
// some code goes here
this.fieldIndex = field;
this.op = op;
this.operand = operand;
}
/**
* @return the field number
*/
public int getFieldIndex() {
// some code goes here
return fieldIndex;
}
/**
* @return the operator
*/
public Op getOp() {
// some code goes here
return op;
}
/**
* @return the operand
*/
public Field getOperand() {
// some code goes here
return operand;
}
/**
* Compares the field number of t specified in the constructor to the
* operand field specified in the constructor using the operator specific in
* the constructor. The comparison can be made through Field's compare
* method.
* 传进来的是迭代器中的元素
* @param t The tuple to compare against
* @return true if the comparison is true, false otherwise.
*/
public boolean filter(Tuple t) {
// some code goes here
Field otherOperand = t.getField(fieldIndex);
return otherOperand.compare(op, operand);
}
/**
* Returns something useful, like "f = field_id op = op_string operand =
* operand_string"
*/
public String toString() {
// some code goes here
return String.format("f = %d op = %s operand = %s", fieldIndex,op.toString(),operand.toString());
}
}
- Filter Class:
/**
* Filter is an operator that implements a relational select.
*/
public class Filter extends Operator {
private static final long serialVersionUID = 1L;
private Predicate predicate;
private TupleDesc tupleDesc;
private OpIterator[] children;
/**
* Constructor accepts a predicate to apply and a child operator to read
* tuples to filter from.
*
* @param p The predicate to filter tuples with
* @param child The child operator
*/
public Filter(Predicate p, OpIterator child) {
// some code goes here
this.predicate = p;
this.children = new OpIterator[1];
this.children[0] = child;
this.tupleDesc = child.getTupleDesc();
}
public Predicate getPredicate() {
// some code goes here
return predicate;
}
public TupleDesc getTupleDesc() {
// some code goes here
return tupleDesc;
}
public void open() throws DbException, NoSuchElementException,
TransactionAbortedException {
// some code goes here
super.open();
children[0].open();
}
public void close() {
// some code goes here
super.close();
children[0].close();
}
public void rewind() throws DbException, TransactionAbortedException {
// some code goes here
children[0].rewind();
}
/**
* AbstractDbIterator.readNext implementation. Iterates over tuples from the
* child operator, applying the predicate to them and returning those that
* pass the predicate (i.e. for which the Predicate.filter() returns true.)
*
* @return The next tuple that passes the filter, or null if there are no
* more tuples
* @see Predicate#filter
*/
protected Tuple fetchNext() throws NoSuchElementException,
TransactionAbortedException, DbException {
// some code goes here
while (children[0].hasNext()) {
Tuple tuple = children[0].next();
if (predicate.filter(tuple)) {
return tuple;
}
}
return null;
}
@Override
public OpIterator[] getChildren() {
// some code goes here
return children;
}
@Override
public void setChildren(OpIterator[] children) {
// some code goes here
this.children = children;
}
}
- JoinPredicate Class:
public class JoinPredicate implements Serializable {
private static final long serialVersionUID = 1L;
/**
* The field index into the first tuple in the predicate
*/
private int fieldIndex1;
/**
* The field index into the second tuple in the predicate
*/
private int fieldIndex2;
private Predicate.Op op;
/**
* Constructor -- create a new predicate over two fields of two tuples.
*
* @param field1 The field index into the first tuple in the predicate
* @param field2 The field index into the second tuple in the predicate
* @param op The operation to apply (as defined in Predicate.Op); either
* Predicate.Op.GREATER_THAN, Predicate.Op.LESS_THAN,
* Predicate.Op.EQUAL, Predicate.Op.GREATER_THAN_OR_EQ, or
* Predicate.Op.LESS_THAN_OR_EQ
* @see Predicate
*/
public JoinPredicate(int field1, Predicate.Op op, int field2) {
// some code goes here
this.fieldIndex1 = field1;
this.fieldIndex2 = field2;
this.op = op;
}
/**
* Apply the predicate to the two specified tuples. The comparison can be
* made through Field's compare method.
*
* @return true if the tuples satisfy the predicate.
*/
public boolean filter(Tuple t1, Tuple t2) {
// some code goes here
if (t1 == null || t2 == null) {
return false;
}
Field field1 = t1.getField(fieldIndex1);
Field field2 = t2.getField(fieldIndex2);
return field1.compare(op, field2);
}
public int getField1() {
// some code goes here
return this.fieldIndex1;
}
public int getField2() {
// some code goes here
return this.fieldIndex2;
}
public Predicate.Op getOperator() {
// some code goes here
return op;
}
}
-
对于Join的自然连接:主要连接的操作实现其实就是二重循环。Children1中每个元组,与Children2中每个元组遍历对比,判断是否符合条件,符合条件则拼接,当遍历右边完成后再进行Children1.next。直至Children1也遍历完。
-
Join Class:
public class Join extends Operator {
private static final long serialVersionUID = 1L;
private JoinPredicate joinPredicate;
private TupleDesc tupleDesc;
private Tuple curJoinTuple;
/**
* children[0]:需要连接的做操作符
* children[1]:需要连接的右操作符
*/
private OpIterator[] children;
/**
* Constructor. Accepts two children to join and the predicate to join them
* on
*
* @param p The predicate to use to join the children
* @param child1 Iterator for the left(outer) relation to join
* @param child2 Iterator for the right(inner) relation to join
*/
public Join(JoinPredicate p, OpIterator child1, OpIterator child2) {
// some code goes here
this.joinPredicate = p;
this.children = new OpIterator[2];
this.children[0] = child1;
this.children[1] = child2;
this.tupleDesc = TupleDesc.merge(child1.getTupleDesc(),child2.getTupleDesc());
}
public JoinPredicate getJoinPredicate() {
// some code goes here
return joinPredicate;
}
/**
* @return the field name of join field1. Should be quantified by
* alias or table name.
*/
public String getJoinField1Name() {
// some code goes here
return children[0].getTupleDesc().getFieldName(joinPredicate.getField1());
}
/**
* @return the field name of join field2. Should be quantified by
* alias or table name.
*/
public String getJoinField2Name() {
// some code goes here
return children[1].getTupleDesc().getFieldName(joinPredicate.getField2());
}
/**
* @see TupleDesc#merge(TupleDesc, TupleDesc) for possible
* implementation logic.
*/
public TupleDesc getTupleDesc() {
// some code goes here
return tupleDesc;
}
public void open() throws DbException, NoSuchElementException,
TransactionAbortedException {
// some code goes here
super.open();
children[0].open();
children[1].open();
}
public void close() {
// some code goes here
super.close();
children[0].close();
children[1].close();
}
public void rewind() throws DbException, TransactionAbortedException {
// some code goes here
children[0].rewind();
children[1].rewind();
}
/**
* Returns the next tuple generated by the join, or null if there are no
* more tuples. Logically, this is the next tuple in r1 cross r2 that
* satisfies the join predicate. There are many possible implementations;
* the simplest is a nested loops join.
* <p>
* Note that the tuples returned from this particular implementation of Join
* are simply the concatenation of joining tuples from the left and right
* relation. Therefore, if an equality predicate is used there will be two
* copies of the join attribute in the results. (Removing such duplicate
* columns can be done with an additional projection operator if needed.)
* <p>
* For example, if one tuple is {1,2,3} and the other tuple is {1,5,6},
* joined on equality of the first column, then this returns {1,2,3,1,5,6}.
*
* @return The next matching tuple.
* @see JoinPredicate#filter
*/
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
while(children[0].hasNext() || curJoinTuple != null){
if(children[0].hasNext() && curJoinTuple == null){
curJoinTuple = children[0].next();
}
Tuple right;
while (children[1].hasNext()){
right = children[1].next();
if(joinPredicate.filter(curJoinTuple,right)){
int len1 = curJoinTuple.getTupleDesc().numFields();
int len2 = right.getTupleDesc().numFields();
Tuple tuple = new Tuple(getTupleDesc()); //tuple的recordID应该设置成什么?
for(int i=0; i<len1; i++){
tuple.setField(i,curJoinTuple.getField(i));
}
for(int i=0; i<len2; i++){
tuple.setField(i+len1,right.getField(i));
}
return tuple;
}
}
curJoinTuple = null;
children[1].rewind();
}
return null;
}
@Override
public OpIterator[] getChildren() {
// some code goes here
return this.children;
}
@Override
public void setChildren(OpIterator[] children) {
// some code goes here
this.children = children;
}
}
1.2、Exercise2: Aggregates
在Exercise2中要完成的就是SQL中的分组(GROUP BY)与聚合(aggregator)的操作。先简单复习下这两个的概念:
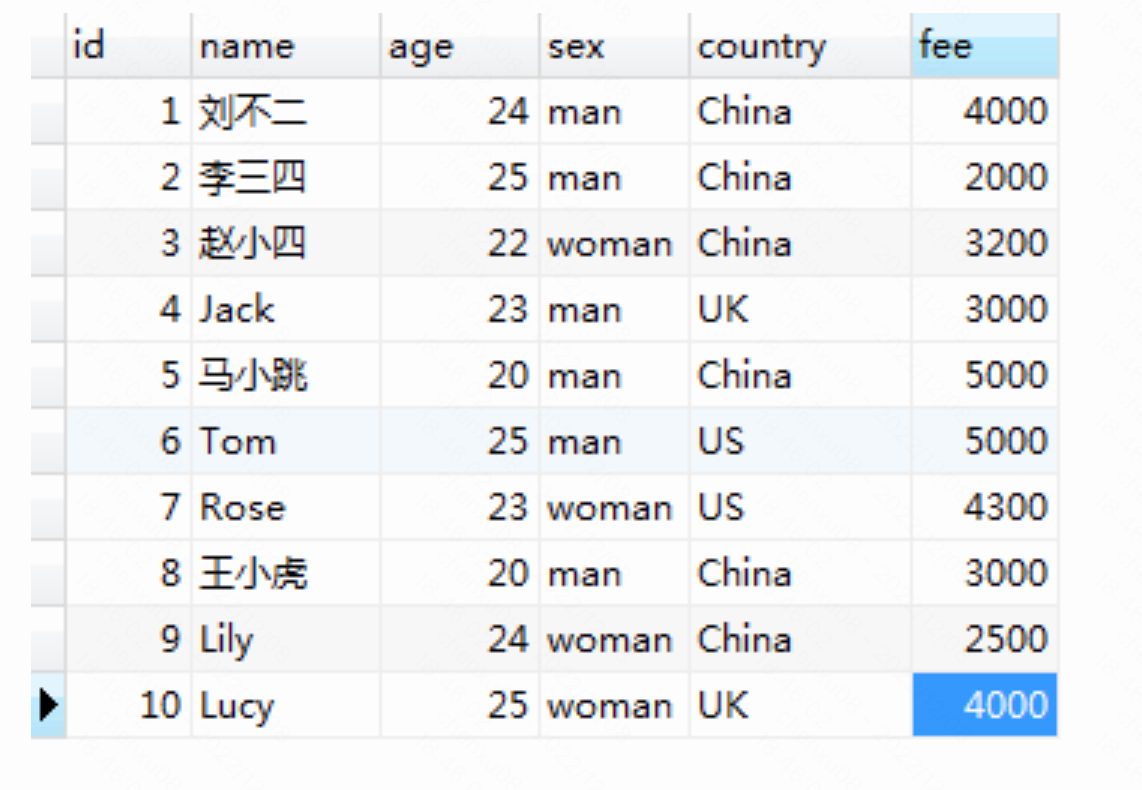
这是一张简单的会员信息的fee表,如果只是对fee进行SUM聚合操作,不进行分组的话则结果应为:
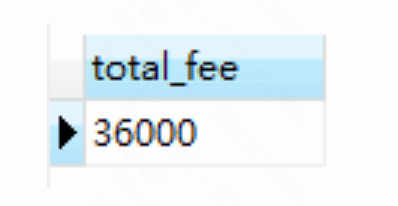
但是如果以城市进行分组进行计算的话(19700/7000/9300 则分别对应一个Field):
这就是简单的单列非分组的聚合与分组聚合的case。
本次的练习也不要求多重聚合与多重分组的实现(传参改为List,依次遍历对应值)。只需要实现分组/非分组下时聚合字段类型为int时的MAX、MIN、SUM、COUNT、AVG,或为String类型时下的COUNT操作。对于lab中的话,则是IntegerAggregator,StringAggregator 类各自实现自身数据类型的聚合操作,Aggregate来进行具体的调用。
- IntegerAggregator Class:
/**
* Knows how to compute some aggregate over a set of IntFields.
*/
public class IntegerAggregator implements Aggregator {
private static final long serialVersionUID = 1L;
private static final Field NO_GROUP_FIELD = new StringField("NO_GROUP_FIELD",20);
/**
* 需要分组的字段的索引(从0开始
*/
private int groupByIndex;
/**
* 需要分组的字段类型
*/
private Type groupByType;
/**
* 需要聚合的字段的索引(从0开始
*/
private int aggregateIndex;
/**
* 需要聚合的操作
*/
private Op aggOp;
/**
* 分组计算Map: MAX,MIN,COUNT,SUM,理论上都只需要这一个calMap计算出来,如果是计算平均值,值则需要计算每个数出现的次数
*/
private Map<Field, GroupCalResult> groupCalMap;
private Map<Field,Tuple> resultMap;
/**
* for groupCalMap
*/
private static class GroupCalResult {
public static final Integer DEFAULT_COUNT = 0;
public static final Integer Deactivate_COUNT = -1;
public static final Integer DEFAULT_RES = 0;
public static final Integer Deactivate_RES = -1;
/**
* 当前分组计算的结果:SUM、AVG、MIN、MAX、SUM
*/
private Integer result;
/**
* 当前Field出现的频度
*/
private Integer count;
public GroupCalResult(int result,int count){
this.result = result;
this.count = count;
}
}
/**
* 聚合后Tuple的desc
* Each tuple in the result is a pair of the form (groupValue, aggregateValue), unless the value of the group by
* field was Aggregator.NO_GROUPING, in which case the result is a single tuple of the form (aggregateValue).
*/
private TupleDesc aggDesc;
/**
* Aggregate constructor
*
* @param gbField the 0-based index of the group-by field in the tuple, or
* NO_GROUPING if there is no grouping
* @param gbFieldType the type of the group by field (e.g., Type.INT_TYPE), or null
* if there is no grouping
* @param afield the 0-based index of the aggregate field in the tuple
* @param what the aggregation operator
*/
public IntegerAggregator(int gbField, Type gbFieldType, int afield, Op what) {
// some code goes here
this.groupByIndex = gbField;
this.groupByType = gbFieldType;
this.aggregateIndex = afield;
this.aggOp = what;
this.groupCalMap = new ConcurrentHashMap<>();
this.resultMap = new ConcurrentHashMap<>();
if (this.groupByIndex >= 0) {
// 有groupBy
this.aggDesc = new TupleDesc(new Type[]{this.groupByType,Type.INT_TYPE}, new String[]{"groupVal","aggregateVal"});
} else {
// 无groupBy
this.aggDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"aggregateVal"});
}
}
/**
* Merge a new tuple into the aggregate, grouping as indicated in the
* constructor
*
* @param tup the Tuple containing an aggregate field and a group-by field
*/
public void mergeTupleIntoGroup(Tuple tup) {
// some code goes here
Field groupByField = this.groupByIndex == NO_GROUPING ? NO_GROUP_FIELD : tup.getField(this.groupByIndex);
if(!NO_GROUP_FIELD.equals(groupByField) && groupByField.getType() != groupByType){
throw new IllegalArgumentException("Except groupType is: 「"+ this.groupByType + " 」,But given "+ groupByField.getType());
}
if(!(tup.getField(this.aggregateIndex) instanceof IntField)){
throw new IllegalArgumentException("Except aggType is: 「 IntField 」" + ",But given "+ tup.getField(this.aggregateIndex).getType());
}
IntField aggField = (IntField) tup.getField(this.aggregateIndex);
int curVal = aggField.getValue();
// 如果没有分组,则groupByIndex = -1 ,如果没有分组的情况直接为null的话那么concurrentHashMap就不适合 , 则需要赋默认值
// 不考虑并发的话,则直接用HashMap不需要默认值
// 1、store
switch (this.aggOp){
case MIN:
this.groupCalMap.put(groupByField,new GroupCalResult(Math.min(groupCalMap.getOrDefault(groupByField,
new GroupCalResult(Integer.MAX_VALUE,GroupCalResult.Deactivate_COUNT)).result,curVal),GroupCalResult.Deactivate_COUNT));
break;
case MAX:
this.groupCalMap.put(groupByField,new GroupCalResult(Math.max(groupCalMap.getOrDefault(groupByField,
new GroupCalResult(Integer.MIN_VALUE,GroupCalResult.Deactivate_COUNT)).result,curVal),GroupCalResult.Deactivate_COUNT));
break;
case SUM:
this.groupCalMap.put(groupByField,new GroupCalResult(groupCalMap.getOrDefault(groupByField,
new GroupCalResult(GroupCalResult.DEFAULT_RES,GroupCalResult.Deactivate_COUNT)).result+curVal, GroupCalResult.Deactivate_COUNT));
break;
case COUNT:
this.groupCalMap.put(groupByField,new GroupCalResult(GroupCalResult.Deactivate_RES, groupCalMap.getOrDefault(groupByField,
new GroupCalResult(GroupCalResult.Deactivate_RES,GroupCalResult.DEFAULT_COUNT)).count+1));
break;
case AVG:
GroupCalResult pre = this.groupCalMap.getOrDefault(groupByField, new GroupCalResult(GroupCalResult.DEFAULT_RES, GroupCalResult.DEFAULT_COUNT));
this.groupCalMap.put(groupByField,new GroupCalResult(pre.result+curVal,pre.count+1));
break;
// TODO:in lab7
case SC_AVG:
break;
// TODO:in lab7
case SUM_COUNT:
}
// 2、cal
Tuple curCalTuple = new Tuple(aggDesc);
int curCalRes = 0;
if(this.aggOp == Op.MIN || this.aggOp == Op.MAX || this.aggOp == Op.SUM){
curCalRes = this.groupCalMap.get(groupByField).result;
}else if(this.aggOp == Op.COUNT){
curCalRes = this.groupCalMap.get(groupByField).count;
}else if(this.aggOp == Op.AVG){
// 因为是IntField所以必然精度会有问题
curCalRes = this.groupCalMap.get(groupByField).result / this.groupCalMap.get(groupByField).count;
}
if (this.groupByIndex >= 0) {
// 有groupBy
curCalTuple.setField(0,groupByField);
curCalTuple.setField(1,new IntField(curCalRes));
} else {
// 无groupBy
curCalTuple.setField(0,new IntField(curCalRes));
}
// 3、update
resultMap.put(groupByField,curCalTuple);
}
/**
* Create a OpIterator over group aggregate results.
*
* @return a OpIterator whose tuples are the pair (groupVal, aggregateVal)
* if using group, or a single (aggregateVal) if no grouping. The
* aggregateVal is determined by the type of aggregate specified in
* the constructor.
*/
public OpIterator iterator() {
// some code goes here
return new IntAggTupIterator();
}
private class IntAggTupIterator implements OpIterator {
private boolean open = false;
private Iterator<Map.Entry<Field, Tuple>> iter;
@Override
public void open() throws DbException, TransactionAbortedException {
iter = resultMap.entrySet().iterator();
open = true;
}
@Override
public void close() {
open = false;
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException {
if (open && iter.hasNext()) {
return true;
} else {
return false;
}
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
return iter.next().getValue();
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
this.close();
this.open();
}
@Override
public TupleDesc getTupleDesc() {
return aggDesc;
}
}
}
-
Test result:
-
StringAggregator Class:
/**
* Knows how to compute some aggregate over a set of StringFields.
*/
public class StringAggregator implements Aggregator {
private static final long serialVersionUID = 1L;
private static final Field NO_GROUP_FIELD = new StringField("NO_GROUP_FIELD",20);
/**
* 需要分组的字段的索引(从0开始
*/
private int groupByIndex;
/**
* 需要分组的字段类型
*/
private Type groupByType;
/**
* 需要聚合的字段的索引(从0开始
*/
private int aggregateIndex;
private TupleDesc aggDesc;
/**
* 分组计算Map只需要计算count
*/
private Map<Field, Integer> groupCalMap;
private Map<Field,Tuple> resultMap;
/**
* Aggregate constructor
*
* @param gbField the 0-based index of the group-by field in the tuple, or NO_GROUPING if there is no grouping
* @param gbFieldType the type of the group by field (e.g., Type.INT_TYPE), or null if there is no grouping
* @param afield the 0-based index of the aggregate field in the tuple
* @param what aggregation operator to use -- only supports COUNT
* @throws IllegalArgumentException if what != COUNT
*/
public StringAggregator(int gbField, Type gbFieldType, int afield, Op what) {
// some code goes here
if(what != Op.COUNT){
throw new IllegalArgumentException("The Op Type != COUNT");
}
this.groupByIndex = gbField;
this.groupByType = gbFieldType;
this.aggregateIndex = afield;
this.groupCalMap = new ConcurrentHashMap<>();
this.resultMap = new ConcurrentHashMap<>();
if (this.groupByIndex >= 0) {
// 有groupBy
this.aggDesc = new TupleDesc(new Type[]{this.groupByType,Type.INT_TYPE}, new String[]{"groupVal","aggregateVal"});
} else {
// 无groupBy
this.aggDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"aggregateVal"});
}
}
/**
* Merge a new tuple into the aggregate, grouping as indicated in the constructor
*
* @param tup the Tuple containing an aggregate field and a group-by field
*/
public void mergeTupleIntoGroup(Tuple tup) {
// some code goes here
Field groupByField = this.groupByIndex == NO_GROUPING ? NO_GROUP_FIELD : tup.getField(this.groupByIndex);
if(!NO_GROUP_FIELD.equals(groupByField) && groupByField.getType() != groupByType){
throw new IllegalArgumentException("Except groupType is: "+ this.groupByType + ",But given "+ groupByField.getType());
}
if(!(tup.getField(this.aggregateIndex) instanceof StringField)){
throw new IllegalArgumentException("Except aggType is: 「 StringField 」" + ",But given "+ tup.getField(this.aggregateIndex).getType());
}
this.groupCalMap.put(groupByField,this.groupCalMap.getOrDefault(groupByField,0)+1);
Tuple curCalTuple = new Tuple(aggDesc);
if (this.groupByIndex >= 0) {
// 有groupBy
curCalTuple.setField(0,groupByField);
curCalTuple.setField(1,new IntField(this.groupCalMap.get(groupByField)));
} else {
// 无groupBy
curCalTuple.setField(0,new IntField(this.groupCalMap.get(groupByField)));
}
resultMap.put(groupByField,curCalTuple);
}
/**
* Create a OpIterator over group aggregate results.
*
* @return a OpIterator whose tuples are the pair (groupVal,
* aggregateVal) if using group, or a single (aggregateVal) if no
* grouping. The aggregateVal is determined by the type of
* aggregate specified in the constructor.
*/
public OpIterator iterator() {
// some code goes here
return new StringAggTupIterator();
}
private class StringAggTupIterator implements OpIterator {
private boolean open = false;
private Iterator<Map.Entry<Field, Tuple>> iter;
@Override
public void open() throws DbException, TransactionAbortedException {
iter = resultMap.entrySet().iterator();
open = true;
}
@Override
public void close() {
open = false;
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException {
if (open && iter.hasNext()) {
return true;
} else {
return false;
}
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
return iter.next().getValue();
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
this.close();
this.open();
}
@Override
public TupleDesc getTupleDesc() {
return aggDesc;
}
}
}
-
Test result:
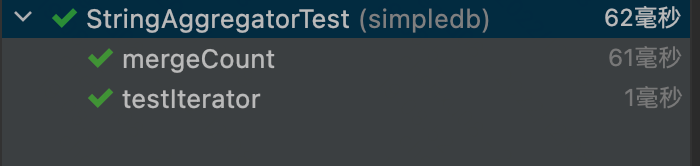
-
Aggregate Class:
public class Aggregate extends Operator {
private static final long serialVersionUID = 1L;
private OpIterator[] children;
private int aggFieldIndex;
private int groupByIndex;
private Aggregator.Op aggOp;
private TupleDesc tupleDesc;
private Aggregator aggregator;
/**
* 存放aggregator处理后的结果
*/
private OpIterator opIterator;
/**
* Constructor.
* <p>
* Implementation hint: depending on the type of afield, you will want to
* construct an {@link IntegerAggregator} or {@link StringAggregator} to help
* you with your implementation of readNext().
*
* @param child The OpIterator that is feeding us tuples.
* @param afield The column over which we are computing an aggregate.
* @param gfield The column over which we are grouping the result, or -1 if
* there is no grouping
* @param aop The aggregation operator to use
*/
public Aggregate(OpIterator child, int afield, int gfield, Aggregator.Op aop) {
// some code goes here
this.children = new OpIterator[]{child};
this.aggFieldIndex = afield;
this.groupByIndex = gfield;
this.aggOp = aop;
this.tupleDesc = child.getTupleDesc();
if( this.tupleDesc.getFieldType(afield)== Type.INT_TYPE) {
this.aggregator = new IntegerAggregator(gfield, this.tupleDesc.getFieldType(afield), afield, this.aggOp);
} else {
this.aggregator = new StringAggregator(gfield, this.tupleDesc.getFieldType(afield), afield, this.aggOp);
}
}
/**
* @return If this aggregate is accompanied by a groupby, return the groupby
* field index in the <b>INPUT</b> tuples. If not, return
* {@link Aggregator#NO_GROUPING}
*/
public int groupField() {
// some code goes here
return this.groupByIndex;
}
/**
* @return If this aggregate is accompanied by a group by, return the name
* of the groupby field in the <b>OUTPUT</b> tuples. If not, return
* null;
*/
public String groupFieldName() {
// some code goes here
return this.tupleDesc.getFieldName(groupByIndex);
}
/**
* @return the aggregate field
*/
public int aggregateField() {
// some code goes here
return this.aggFieldIndex;
}
/**
* @return return the name of the aggregate field in the <b>OUTPUT</b>
* tuples
*/
public String aggregateFieldName() {
// some code goes here
return this.tupleDesc.getFieldName(aggFieldIndex);
}
/**
* @return return the aggregate operator
*/
public Aggregator.Op aggregateOp() {
// some code goes here
return this.aggOp;
}
public static String nameOfAggregatorOp(Aggregator.Op aop) {
return aop.toString();
}
public void open() throws NoSuchElementException, DbException,
TransactionAbortedException {
// some code goes here
super.open();
this.children[0].open();
while (children[0].hasNext()) {
Tuple nextTuple = children[0].next();
aggregator.mergeTupleIntoGroup(nextTuple);
}
this.opIterator = aggregator.iterator();
this.opIterator.open();
}
/**
* Returns the next tuple. If there is a group by field, then the first
* field is the field by which we are grouping, and the second field is the
* result of computing the aggregate. If there is no group by field, then
* the result tuple should contain one field representing the result of the
* aggregate. Should return null if there are no more tuples.
*/
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
if (this.opIterator.hasNext()) {
return this.opIterator.next();
} else {
return null;
}
}
public void rewind() throws DbException, TransactionAbortedException {
// some code goes here
this.children[0].rewind();
this.opIterator.rewind();
}
/**
* Returns the TupleDesc of this Aggregate. If there is no group by field,
* this will have one field - the aggregate column. If there is a group by
* field, the first field will be the group by field, and the second will be
* the aggregate value column.
* <p>
* The name of an aggregate column should be informative. For example:
* "aggName(aop) (child_td.getFieldName(afield))" where aop and afield are
* given in the constructor, and child_td is the TupleDesc of the child
* iterator.
*/
public TupleDesc getTupleDesc() {
// some code goes here
return this.tupleDesc;
}
public void close() {
// some code goes here
this.children[0].close();
this.opIterator.close();
}
@Override
public OpIterator[] getChildren() {
// some code goes here
return this.children;
}
@Override
public void setChildren(OpIterator[] children) {
// some code goes here
this.children = children;
}
}
-Test Result:
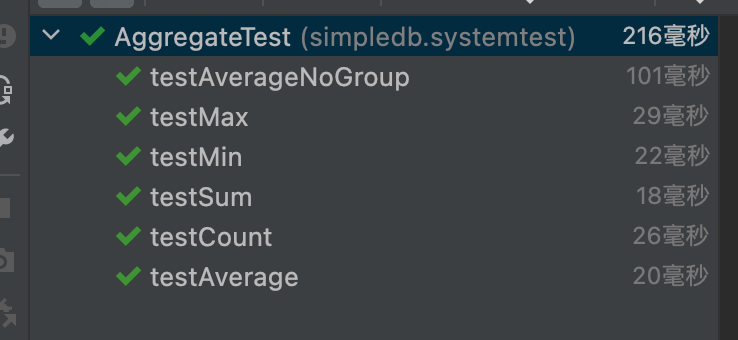
1.3、Exercise 3:HeapFile Mutability
在Exercise3中主要是在HeapPage、HeapFile、BufferPool中实现deleteTuple、insertTuple的功能。对于这些要注意的tip,笔者认为主要有以下几点:
- deleteTuple、insertTuple都应注意最终修改的应是HeapPage中header,修改slot的占用情况。
- 对于修改后的页,应及时记录变更为脏页。
- 元组获取所在表的方式:t.getRecordId().getPageId().getTableId()
- 元组获取所在页的方式:Database.getBufferPool().getPage(tid,t.getRecordId().getPageId(),Permissions.READ_WRITE);
而getPage则是通过:1、BufferPool直接KV获取;2、无缓存则通过DbFile计算偏移量获得。
以上有些忘了可以看笔者上一篇文章:
6.830 lab1实验思路
- HeapFile Class:
package simpledb.storage.dbfile;
import simpledb.common.Database;
import simpledb.common.DbException;
import simpledb.common.Debug;
import simpledb.common.Permissions;
import simpledb.storage.*;
import simpledb.storage.iterator.DbFileIterator;
import simpledb.transaction.TransactionAbortedException;
import simpledb.transaction.TransactionId;
import java.io.*;
import java.util.*;
/**
* HeapFile is an implementation of a DbFile that stores a collection of tuples
* in no particular order. Tuples are stored on pages, each of which is a fixed
* size, and the file is simply a collection of those pages. HeapFile works
* closely with HeapPage. The format of HeapPages is described in the HeapPage
* constructor.
*
* @author Sam Madden
* @see HeapPage#HeapPage
*/
public class HeapFile implements DbFile {
/**
* f the file that stores the on-disk backing store for this heap file.
*/
private final File f;
/**
* 文件描述(consist of records)
*/
private final TupleDesc td;
/**
* 写在内部类的原因是:DbFileIterator is the iterator interface that all SimpleDB Dbfile should
*/
private static final class HeapFileIterator implements DbFileIterator {
private final HeapFile heapFile;
private final TransactionId tid;
/**
* 存储了堆文件迭代器
*/
private Iterator<Tuple> tupleIterator;
private int index;
public HeapFileIterator(HeapFile file,TransactionId tid){
this.heapFile = file;
this.tid = tid;
}
@Override
public void open() throws DbException, TransactionAbortedException {
index = 0;
tupleIterator = getTupleIterator(index);
}
private Iterator<Tuple> getTupleIterator(int pageNumber) throws TransactionAbortedException, DbException{
if(pageNumber >= 0 && pageNumber < heapFile.numPages()){
HeapPageId pid = new HeapPageId(heapFile.getId(),pageNumber);
HeapPage page = (HeapPage)Database.getBufferPool().getPage(tid, pid, Permissions.READ_ONLY);
return page.iterator();
}else{
throw new DbException(String.format("heapFile %d does not exist in page[%d]!", pageNumber,heapFile.getId()));
}
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException {
// TODO Auto-generated method stub
if(tupleIterator == null){
return false;
}
while(!tupleIterator.hasNext()){
index++;
if(index < heapFile.numPages()){
tupleIterator = getTupleIterator(index);
}else{
return false;
}
}
return true;
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
if(tupleIterator == null || !tupleIterator.hasNext()){
throw new NoSuchElementException();
}
return tupleIterator.next();
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
close();
open();
}
@Override
public void close() {
tupleIterator = null;
}
}
/**
* Constructs a heap file backed by the specified file.
*
* @param f the file that stores the on-disk backing store for this heap
* file.
*/
public HeapFile(File f, TupleDesc td) {
// some code goes here
this.f = f;
this.td = td;
}
/**
* Returns the File backing this HeapFile on disk.
*
* @return the File backing this HeapFile on disk.
*/
public File getFile() {
// some code goes here
return f;
}
/**
* Returns an ID uniquely identifying this HeapFile. Implementation note:
* you will need to generate this tableid somewhere to ensure that each
* HeapFile has a "unique id," and that you always return the same value for
* a particular HeapFile. We suggest hashing the absolute file name of the
* file underlying the heapfile, i.e. f.getAbsoluteFile().hashCode().
*
* @return an ID uniquely identifying this HeapFile.
*/
public int getId() {
// some code goes here
return f.getAbsoluteFile().hashCode();
}
/**
* Returns the TupleDesc of the table stored in this DbFile.
*
* @return TupleDesc of this DbFile.
*/
public TupleDesc getTupleDesc() {
// some code goes here
return this.td;
}
// see DbFile.java for javadocs
public Page readPage(PageId pid) {
// some code goes here
int tableId = pid.getTableId();
int pgNo = pid.getPageNumber();
int offset = pgNo * BufferPool.getPageSize();
RandomAccessFile randomAccessFile = null;
try{
randomAccessFile = new RandomAccessFile(f,"r");
// 起码有pgNo页那么大小就应该大于pgNo
if((long) (pgNo + 1) *BufferPool.getPageSize() > randomAccessFile.length()){
randomAccessFile.close();
throw new IllegalArgumentException(String.format("table %d page %d is invalid", tableId, pgNo));
}
byte[] bytes = new byte[BufferPool.getPageSize()];
// 移动偏移量到文件开头,并计算是否change
randomAccessFile.seek(offset);
int read = randomAccessFile.read(bytes,0,BufferPool.getPageSize());
// Do not load the entire table into memory on the open() call
// -- this will cause an out of memory error for very large tables.
if(read != BufferPool.getPageSize()){
throw new IllegalArgumentException(String.format("table %d page %d read %d bytes not equal to BufferPool.getPageSize() ", tableId, pgNo, read));
}
HeapPageId id = new HeapPageId(pid.getTableId(),pid.getPageNumber());
return new HeapPage(id,bytes);
}catch (IOException e){
e.printStackTrace();
}finally {
try{
if(randomAccessFile != null){
randomAccessFile.close();
}
}catch (Exception e){
e.printStackTrace();
}
}
throw new IllegalArgumentException(String.format("table %d page %d is invalid", tableId, pgNo));
}
// see DbFile.java for javadocs
public void writePage(Page page) throws IOException {
// some code goes here
// not necessary for lab1
PageId pageId = page.getId();
int pageNo = pageId.getPageNumber();
int offset = pageNo * BufferPool.getPageSize();
byte[] pageData = page.getPageData();
RandomAccessFile file = new RandomAccessFile(this.f, "rw");
file.seek(offset);
file.write(pageData);
file.close();
page.markDirty(false, null);
}
/**
* Returns the number of pages in this HeapFile,not page index;
*/
public int numPages() {
// some code goes here
// 通过文件长度算出所在bufferPool所需的页数(Math.floor是向下取整)
return (int) Math.floor(getFile().length() * 1.0 / BufferPool.getPageSize());
}
// see DbFile.java for javadocs
public List<Page> insertTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
ArrayList<Page> pageList= new ArrayList<Page>();
for(int i=0;i<numPages();++i){
// took care of getting new page
HeapPage p = (HeapPage) Database.getBufferPool().getPage(tid,
new HeapPageId(this.getId(),i),Permissions.READ_WRITE);
if(p.getNumUnusedSlots() == 0)
continue;
p.insertTuple(t);
pageList.add(p);
return pageList;
}
// 如果现有的页都没有空闲的slot,则新起一页
BufferedOutputStream bw = new BufferedOutputStream(new FileOutputStream(f,true));
byte[] emptyData = HeapPage.createEmptyPageData();
bw.write(emptyData);
bw.close();
// 加载进BufferPool
HeapPage p = (HeapPage) Database.getBufferPool().getPage(tid,
new HeapPageId(getId(),numPages()-1),Permissions.READ_WRITE);
p.insertTuple(t);
pageList.add(p);
return pageList;
}
// see DbFile.java for javadocs
public List<Page> deleteTuple(TransactionId tid, Tuple t) throws DbException,
TransactionAbortedException {
// some code goes here
// not necessary for lab1
HeapPage page = (HeapPage) Database.getBufferPool().getPage(tid,
t.getRecordId().getPageId(),Permissions.READ_WRITE);
page.deleteTuple(t);
return Collections.singletonList(page);
}
// see DbFile.java for javadocs
/**
* HeapFile与Heap为一一对应的关系,所以其实是获取BufferPool中对应页的元组迭代器
*/
public DbFileIterator iterator(TransactionId tid) {
//some code goes here
return new HeapFileIterator(this,tid);
}
}
- 测试结果:
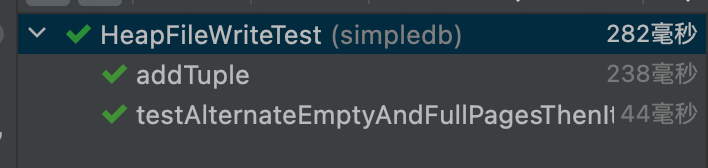
HeapPage Class:
package simpledb.storage;
import simpledb.common.Catalog;
import simpledb.common.Database;
import simpledb.common.DbException;
import simpledb.storage.dbfile.HeapFile;
import simpledb.transaction.TransactionId;
import java.io.*;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.NoSuchElementException;
/**
* Each instance of HeapPage stores data for one page of HeapFiles and
* implements the Page interface that is used by BufferPool.
*
* @see HeapFile
* @see BufferPool
*/
public class HeapPage implements Page {
final HeapPageId pid;
final TupleDesc td;
/**
* the lowest bit of the first byte represents whether or not the first slot in the page is in use.
* The second lowest bit of the first byte represents whether or not the second slot in the page is in use
*/
final byte[] header;
final Tuple[] tuples;
/**
* Each page in a HeapFile is arranged as a set of slots, each of which can hold one tuple (tuples for a given table
* in SimpleDB are all of the same size)
*/
final int numSlots;
byte[] oldData;
private final Byte oldDataLock = (byte) 0;
/**
* 事务的量大可转队列
*/
private TransactionId dirtyTid;
/**
* if the page is dirty
*/
private boolean dirtyFlag;
/**
* Create a HeapPage from a set of bytes of data read from disk.
* The format of a HeapPage is a set of header bytes indicating
* the slots of the page that are in use, some number of tuple slots.
* Specifically, the number of tuples is equal to: <p>
* floor((BufferPool.getPageSize()*8) / (tuple size * 8 + 1))
* <p> where tuple size is the size of tuples in this
* database table, which can be determined via {@link Catalog#getTupleDesc}.
* The number of 8-bit header words is equal to:
* <p>
* ceiling(no. tuple slots / 8)
* <p>
*
* @see Database#getCatalog
* @see Catalog#getTupleDesc
* @see BufferPool#getPageSize()
*/
public HeapPage(HeapPageId id, byte[] data) throws IOException {
this.pid = id;
this.td = Database.getCatalog().getTupleDesc(id.getTableId());
this.numSlots = getNumTuples();
DataInputStream dis = new DataInputStream(new ByteArrayInputStream(data));
// allocate and read the header slots of this page
header = new byte[getHeaderSize()];
for (int i = 0; i < header.length; i++)
header[i] = dis.readByte();
tuples = new Tuple[numSlots];
try {
// allocate and read the actual records of this page
for (int i = 0; i < tuples.length; i++)
tuples[i] = readNextTuple(dis, i);
} catch (NoSuchElementException e) {
e.printStackTrace();
}
dis.close();
setBeforeImage();
}
/**
* Retrieve the number of tuples on this page.
*
* @return the number of tuples on this page
*/
private int getNumTuples() {
// some code goes here
return (BufferPool.getPageSize() * 8) / (td.getSize() * 8 +1);
}
/**
* Computes the number of bytes in the header of a page in a HeapFile with each tuple occupying tupleSize bytes
*
* @return the number of bytes in the header of a page in a HeapFile with each tuple occupying tupleSize bytes
*/
private int getHeaderSize() {
// some code goes here
// 向上取整
return (int) Math.ceil((double) getNumTuples() / 8);
}
/**
* Return a view of this page before it was modified
* -- used by recovery
*/
public HeapPage getBeforeImage() {
try {
byte[] oldDataRef = null;
synchronized (oldDataLock) {
oldDataRef = oldData;
}
return new HeapPage(pid, oldDataRef);
} catch (IOException e) {
e.printStackTrace();
//should never happen -- we parsed it OK before!
System.exit(1);
}
return null;
}
public void setBeforeImage() {
synchronized (oldDataLock) {
oldData = getPageData().clone();
}
}
/**
* @return the PageId associated with this page.
*/
public HeapPageId getId() {
// some code goes here
return this.pid;
}
/**
* Suck up tuples from the source file.
*/
private Tuple readNextTuple(DataInputStream dis, int slotId) throws NoSuchElementException {
// if associated bit is not set, read forward to the next tuple, and
// return null.
if (!isSlotUsed(slotId)) {
for (int i = 0; i < td.getSize(); i++) {
try {
dis.readByte();
} catch (IOException e) {
System.out.println("slotId:"+slotId+" is empty;");
throw new NoSuchElementException("error reading empty tuple");
}
}
return null;
}
// read fields in the tuple
Tuple t = new Tuple(td);
RecordId rid = new RecordId(pid, slotId);
t.setRecordId(rid);
try {
for (int j = 0; j < td.numFields(); j++) {
Field f = td.getFieldType(j).parse(dis);
t.setField(j, f);
}
} catch (java.text.ParseException e) {
e.printStackTrace();
throw new NoSuchElementException("parsing error!");
}
return t;
}
/**
* Generates a byte array representing the contents of this page.
* Used to serialize this page to disk.
* <p>
* The invariant here is that it should be possible to pass the byte
* array generated by getPageData to the HeapPage constructor and
* have it produce an identical HeapPage object.
*
* @return A byte array correspond to the bytes of this page.
* @see #HeapPage
*/
public byte[] getPageData() {
int len = BufferPool.getPageSize();
ByteArrayOutputStream baos = new ByteArrayOutputStream(len);
DataOutputStream dos = new DataOutputStream(baos);
// create the header of the page
for (byte b : header) {
try {
dos.writeByte(b);
} catch (IOException e) {
// this really shouldn't happen
e.printStackTrace();
}
}
// create the tuples
for (int i = 0; i < tuples.length; i++) {
// empty slot
if (!isSlotUsed(i)) {
for (int j = 0; j < td.getSize(); j++) {
try {
dos.writeByte(0);
} catch (IOException e) {
e.printStackTrace();
}
}
continue;
}
// non-empty slot
for (int j = 0; j < td.numFields(); j++) {
Field f = tuples[i].getField(j);
try {
f.serialize(dos);
} catch (IOException e) {
e.printStackTrace();
}
}
}
// padding
int zerolen = BufferPool.getPageSize() - (header.length + td.getSize() * tuples.length); //- numSlots * td.getSize();
byte[] zeroes = new byte[zerolen];
try {
dos.write(zeroes, 0, zerolen);
} catch (IOException e) {
e.printStackTrace();
}
try {
dos.flush();
} catch (IOException e) {
e.printStackTrace();
}
return baos.toByteArray();
}
/**
* Static method to generate a byte array corresponding to an empty
* HeapPage.
* Used to add new, empty pages to the file. Passing the results of
* this method to the HeapPage constructor will create a HeapPage with
* no valid tuples in it.
*
* @return The returned ByteArray.
*/
public static byte[] createEmptyPageData() {
int len = BufferPool.getPageSize();
return new byte[len]; //all 0
}
/**
* Delete the specified tuple from the page; the corresponding header bit should be updated to reflect
* that it is no longer stored on any page.
*
* @param t The tuple to delete
* @throws DbException if this tuple is not on this page, or tuple slot is
* already empty.
*/
public void deleteTuple(Tuple t) throws DbException {
// some code goes here
// not necessary for lab1
int tid = t.getRecordId().getTupleNumber();
boolean flag = false;
for (int i = 0; i < tuples.length; i++) {
if (t.equals(tuples[i])){
if(!isSlotUsed(i))
throw new DbException("The tuple slot is already empty !!!");
markSlotUsed(i,false);
tuples[tid] = null;
flag = true;
}
}
if(!flag)
throw new DbException("Tuple does not exist !!!");
}
/**
* Adds the specified tuple to the page; the tuple should be updated to reflect
* that it is now stored on this page.
*
* @param t The tuple to add.
* @throws DbException if the page is full (no empty slots) or tupledesc
* is mismatch.
*/
public void insertTuple(Tuple t) throws DbException {
// some code goes here
// not necessary for lab1
// mismatch : int,int,String的表插入了一条 String,String,String
if(getNumUnusedSlots() == 0 || !t.getTupleDesc().equals(td)){
throw new DbException("the page is full (no empty slots) or tupleDesc is mismatch.");
}
for(int i=0;i<numSlots;++i){
if(!isSlotUsed(i)){
markSlotUsed(i,true);
t.setRecordId(new RecordId(pid,i));
tuples[i] = t;
break;
}
}
}
/**
* Marks this page as dirty/not dirty and record that transaction
* that did the dirtying
*/
public void markDirty(boolean dirty, TransactionId tid) {
// some code goes here
// not necessary for lab1
this.dirtyFlag = dirty;
this.dirtyTid = tid;
}
/**
* Returns the tid of the transaction that last dirtied this page, or null if the page is not dirty
*/
public TransactionId isDirty() {
// some code goes here
// Not necessary for lab1
return this.dirtyFlag ? this.dirtyTid : null ;
}
/**
* Returns the number of unused (i.e., empty) slots on this page.
* 计算未使用的slot:计算header数组中bit为0
*/
public int getNumUnusedSlots() {
// some code goes here
int cnt = 0;
for(int i=0;i<numSlots;++i){
if(!isSlotUsed(i)){
++cnt;
}
}
return cnt;
}
/**
* Returns true if associated slot on this page is filled.
* i 为tuples的 index
*/
public boolean isSlotUsed(int i) {
// some code goes here
// 计算在header中的位置
int iTh = i / 8;
// 计算具体在bitmap中的位置
int bitTh = i % 8;
int onBit = (header[iTh] >> bitTh) & 1;
return onBit == 1;
}
/**
* Abstraction to fill or clear a slot on this page.
*/
private void markSlotUsed(int i, boolean value) {
// some code goes here
// not necessary for lab1
int iTh = i / 8;
// 计算具体在bitmap中的位置
int bitTh = i % 8;
int onBit = (header[iTh] >> bitTh) & 1;
// 需要改变的情况
if(onBit == 0 && value){
header[iTh] += (1 << bitTh);
}else if(onBit == 1 && !value){
header[iTh] -= (1 << bitTh);
}
}
/**
* @return an iterator over all tuples on this page (calling remove on this iterator throws an UnsupportedOperationException)
* (note that this iterator shouldn't return tuples in empty slots!)
*/
public Iterator<Tuple> iterator() {
// some code goes here
List<Tuple> tupleList = new ArrayList<>();
// 判断是否在empty slots
for(int i = 0; i < numSlots ;i++){
if(isSlotUsed(i)) tupleList.add(tuples[i]);
}
return tupleList.iterator();
}
}
测试结果:

- 关于BufferPool实现统一放到Exercise 5。
1.4、Exercise 4:Insertion and deletion
- Now that you have written all of the HeapFile machinery to add and remove tuples, you will implement the Insert and Delete operators.
此Exercise则完成的是操作符中的插入与删除,相当于上层的调用。
注意的tips:
-
插入与删除调用的是BufferPool中的:BufferPool.insertTuple()与BufferPool.deleteTuple()
-
应该加入个标识符判断结果是否已经读取,否则迭代器会一直迭代。
-
都不需要检查是否已经插入/删除。
-
Insert class:
/**
* Inserts tuples read from the child operator into the tableId specified in the
* constructor
*/
public class Insert extends Operator {
private static final long serialVersionUID = 1L;
private TransactionId tid;
private OpIterator[] children;
private int tableId;
private TupleDesc tupleDesc;
/**
* 需要将插入的结果储存下来,否则外部会一直调用fetchNext
* 具体参阅InsertTest validateInsert
*/
private Tuple insertRes;
/**
* Constructor.
*
* @param t The transaction running the insert.
* @param child The child operator from which to read tuples to be inserted.
* @param tableId The table in which to insert tuples.
* @throws DbException if TupleDesc of child differs from table into which we are to
* insert.
*/
public Insert(TransactionId t, OpIterator child, int tableId)
throws DbException {
// some code goes here
this.tid = t;
this.children = new OpIterator[]{child};
this.tableId = tableId;
this.tupleDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"insertNums"});
}
public TupleDesc getTupleDesc() {
// some code goes here
return this.tupleDesc;
}
public void open() throws DbException, TransactionAbortedException {
// some code goes here
super.open();
children[0].open();
this.insertRes = null;
}
public void close() {
// some code goes here
super.close();
children[0].close();
}
public void rewind() throws DbException, TransactionAbortedException {
// some code goes here
this.close();
this.open();
}
/**
* Inserts tuples read from child into the tableId specified by the
* constructor. It returns a one field tuple containing the number of
* inserted records. Inserts should be passed through BufferPool. An
* instances of BufferPool is available via Database.getBufferPool(). Note
* that insert DOES NOT need check to see if a particular tuple is a
* duplicate before inserting it.
*
* @return A 1-field tuple containing the number of inserted records, or
* null if called more than once.
* @see Database#getBufferPool
* @see BufferPool#insertTuple
*/
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
// 已经计算插入过了,所以直接返回null,防止迭代器一直迭代下去
if(insertRes != null){
return null;
}
int insert = 0 ;
while(children[0].hasNext()){
try {
Database.getBufferPool().insertTuple(tid,this.tableId,children[0].next());
insert++;
}catch (IOException e){
System.out.println("Insert Tuples into DataBase is Failed !!!");
e.printStackTrace();
}
}
insertRes = new Tuple(this.tupleDesc);
insertRes.setField(0,new IntField(insert));
return insertRes;
}
@Override
public OpIterator[] getChildren() {
// some code goes here
return this.children;
}
@Override
public void setChildren(OpIterator[] children) {
// some code goes here
this.children = children;
}
}
- Test class:
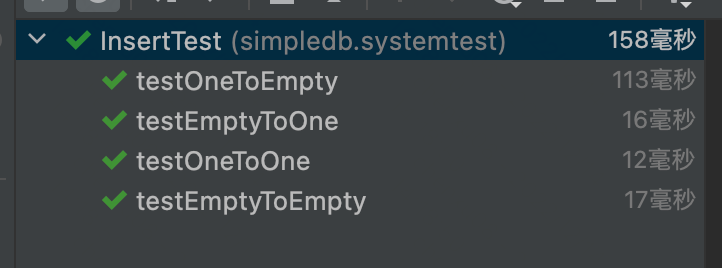
- Delete Class:
import simpledb.common.Database;
import simpledb.common.DbException;
import simpledb.common.Type;
import simpledb.storage.BufferPool;
import simpledb.storage.IntField;
import simpledb.storage.Tuple;
import simpledb.storage.TupleDesc;
import simpledb.transaction.TransactionAbortedException;
import simpledb.transaction.TransactionId;
import java.io.IOException;
/**
* The delete operator. Delete reads tuples from its child operator and removes
* them from the table they belong to.
*/
public class Delete extends Operator {
private static final long serialVersionUID = 1L;
private TransactionId tid;
private OpIterator[] children;
private TupleDesc tupleDesc;
private Tuple deleteRes;
/**
* Constructor specifying the transaction that this delete belongs to as
* well as the child to read from.
*
* @param t The transaction this delete runs in
* @param child The child operator from which to read tuples for deletion
*/
public Delete(TransactionId t, OpIterator child) {
// some code goes here
this.tid = t;
this.children = new OpIterator[]{child};
this.tupleDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"deleteNums"});
}
public TupleDesc getTupleDesc() {
// some code goes here
return this.tupleDesc;
}
public void open() throws DbException, TransactionAbortedException {
// some code goes here
super.open();
children[0].open();
this.deleteRes = null;
}
public void close() {
// some code goes here
super.close();
children[0].close();
this.deleteRes = null;
}
public void rewind() throws DbException, TransactionAbortedException {
// some code goes here
close();
open();
}
/**
* Deletes tuples as they are read from the child operator. Deletes are
* processed via the buffer pool (which can be accessed via the
* Database.getBufferPool() method.
*
* @return A 1-field tuple containing the number of deleted records.
* @see Database#getBufferPool
* @see BufferPool#deleteTuple
*/
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
if(deleteRes != null){
return null;
}
int delete = 0 ;
while(children[0].hasNext()){
try {
Database.getBufferPool().deleteTuple(tid,children[0].next());
delete++;
}catch (IOException e){
System.out.println("Delete Tuples into DataBase is Failed !!!");
e.printStackTrace();
}
}
deleteRes = new Tuple(this.tupleDesc);
deleteRes.setField(0,new IntField(delete));
return deleteRes;
}
@Override
public OpIterator[] getChildren() {
// some code goes here
return this.children;
}
@Override
public void setChildren(OpIterator[] children) {
// some code goes here
this.children = children;
}
}
- 测试结果:
1.5、Exercise 5: Page eviction
之前的Exercise完成了BufferPool的Insert与Delete操作。此次的Exercise则完成的是页的置换。而eviction policy由自己选择,我选用的是LRU的置换策略,并用自己写的LRU的数据结构替换了之前的map。其实置换策略有很多种方式,且是缓存的一个重点,笔者可以简单聊一下:
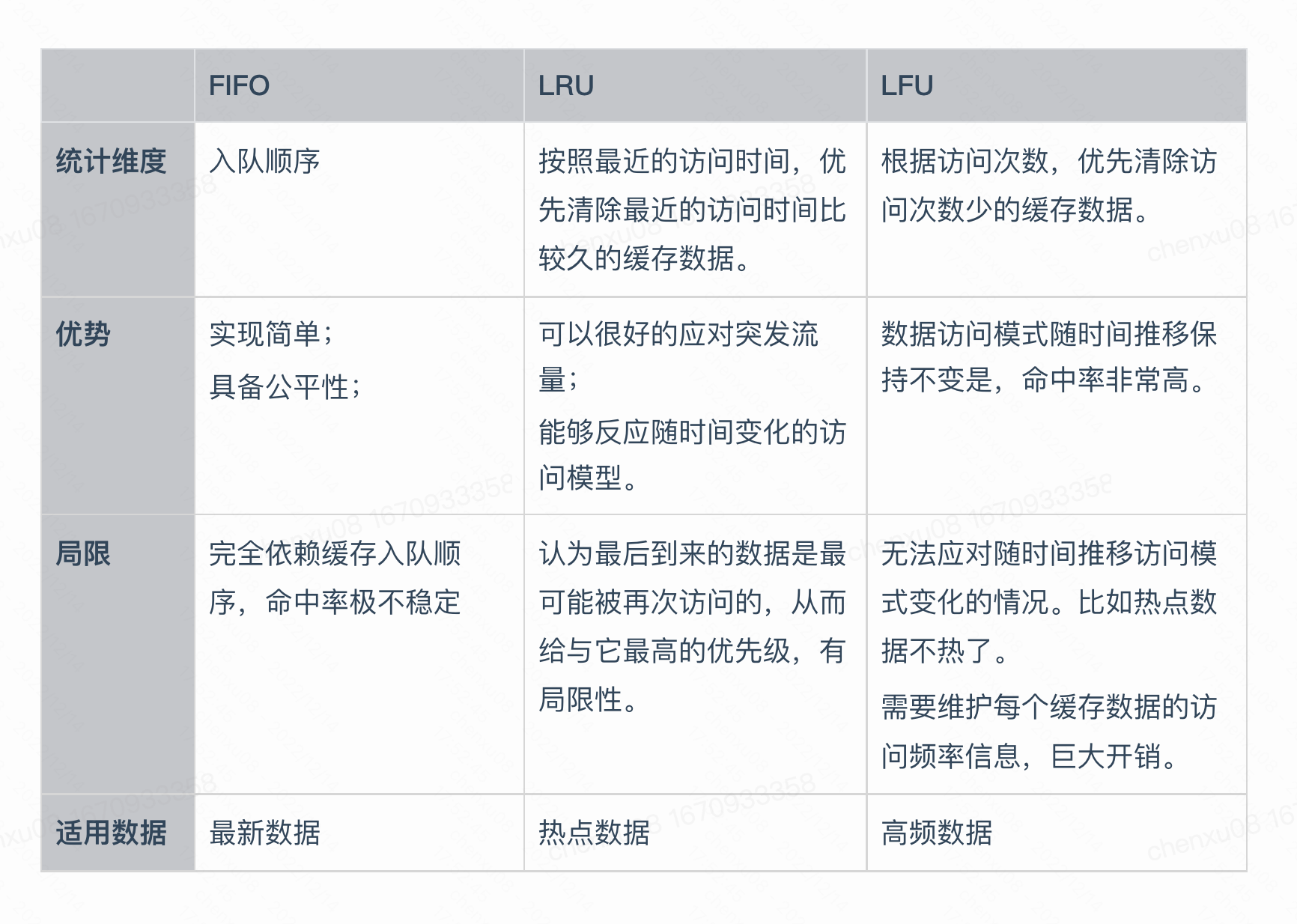
除此之外还有W-TinyLRU:综合了LRU,LFU,本质则用了Count-Min Sketch 算法,利用多个数组的下标储存hash,节省了储存key的开销,并且利用多个哈希函数,分别取值然后存进不同数组,最后取值取最少的那一个(最准确,因为最少的一定是哈希冲突最少的)。然后每条数据加入Sketch时维护一个计数,当总的计数达到窗口上限时,则把每条记录的计数除以2,以此达到时间衰减的效果。而Caffeine则是用这种方式实现,其他的本地缓存则还有:HashMap/ConcurrentHashMap,GuavaCache,Ehcache等。笔者这里则是简单的用LRU的实现,再简单点,其实也可以直接迭代,找到个脏页就置换。
- BufferPool Class:
/**
* BufferPool manages the reading and writing of pages into memory from
* disk. Access methods call into it to retrieve pages, and it fetches
* pages from the appropriate location.
* <p>
* The BufferPool is also responsible for locking; when a transaction fetches
* a page, BufferPool checks that the transaction has the appropriate
* locks to read/write the page.
*
* @Threadsafe, all fields are final
*/
public class BufferPool {
/**
* Default number of pages passed to the constructor. This is used by
* other classes. BufferPool should use the numPages argument to the
* constructor instead.
*/
public static final int DEFAULT_PAGES = 50;
/**
* Bytes per page, including header.
*/
private static final int DEFAULT_PAGE_SIZE = 4096;
private static int pageSize = DEFAULT_PAGE_SIZE;
private final int numPages;
private LRUCache lruCache;
/**
* Creates a BufferPool that caches up to numPages pages.
*
* @param numPages maximum number of pages in this buffer pool.
*/
public BufferPool(int numPages) {
// some code goes here
this.numPages = numPages;
this.lruCache = new LRUCache(numPages);
}
public static int getPageSize() {
return pageSize;
}
// THIS FUNCTION SHOULD ONLY BE USED FOR TESTING!!
public static void setPageSize(int pageSize) {
BufferPool.pageSize = pageSize;
}
// THIS FUNCTION SHOULD ONLY BE USED FOR TESTING!!
public static void resetPageSize() {
BufferPool.pageSize = DEFAULT_PAGE_SIZE;
}
/**
* Retrieve the specified page with the associated permissions.
* Will acquire a lock and may block if that lock is held by another
* transaction.
* <p>
* The retrieved page should be looked up in the buffer pool. If it
* is present, it should be returned. If it is not present, it should
* be added to the buffer pool and returned. If there is insufficient
* space in the buffer pool, a page should be evicted and the new page
* should be added in its place.
*
* @param tid the ID of the transaction requesting the page
* @param pid the ID of the requested page
* @param perm the requested permissions on the page
*/
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
// some code goes here
// TODO 事务..
// bufferPool应直接放在直接内存
if (lruCache.get(pid) == null) {
DbFile file = Database.getCatalog().getDatabaseFile(pid.getTableId());
Page page = file.readPage(pid);
lruCache.put(pid, page);
}
return lruCache.get(pid);
}
/**
* Releases the lock on a page.
* Calling this is very risky, and may result in wrong behavior. Think hard
* about who needs to call this and why, and why they can run the risk of
* calling it.
*
* @param tid the ID of the transaction requesting the unlock
* @param pid the ID of the page to unlock
*/
public void unsafeReleasePage(TransactionId tid, PageId pid) {
// TODO: some code goes here
// not necessary for lab1|lab2
}
/**
* Release all locks associated with a given transaction.
*
* @param tid the ID of the transaction requesting the unlock
*/
public void transactionComplete(TransactionId tid) {
// TODO: some code goes here
// not necessary for lab1|lab2
}
/**
* Return true if the specified transaction has a lock on the specified page
*/
public boolean holdsLock(TransactionId tid, PageId p) {
// TODO: some code goes here
// not necessary for lab1|lab2
return false;
}
/**
* Commit or abort a given transaction; release all locks associated to
* the transaction.
*
* @param tid the ID of the transaction requesting the unlock
* @param commit a flag indicating whether we should commit or abort
*/
public void transactionComplete(TransactionId tid, boolean commit) {
// TODO: some code goes here
// not necessary for lab1|lab2
}
/**
* Add a tuple to the specified table on behalf of transaction tid. Will
* acquire a write lock on the page the tuple is added to and any other
* pages that are updated (Lock acquisition is not needed for lab2).
* May block if the lock(s) cannot be acquired.
* <p>
* Marks any pages that were dirtied by the operation as dirty by calling
* their markDirty bit, and adds versions of any pages that have
* been dirtied to the cache (replacing any existing versions of those pages) so
* that future requests see up-to-date pages.
*
* @param tid the transaction adding the tuple
* @param tableId the table to add the tuple to
* @param t the tuple to add
*/
public void insertTuple(TransactionId tid, int tableId, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
DbFile f = Database.getCatalog().getDatabaseFile(tableId);
updateBufferPool(f.insertTuple(tid, t), tid);
}
/**
* Remove the specified tuple from the buffer pool.
* Will acquire a write lock on the page the tuple is removed from and any
* other pages that are updated. May block if the lock(s) cannot be acquired.
* <p>
* Marks any pages that were dirtied by the operation as dirty by calling
* their markDirty bit, and adds versions of any pages that have
* been dirtied to the cache (replacing any existing versions of those pages) so
* that future requests see up-to-date pages.
*
* @param tid the transaction deleting the tuple.
* @param t the tuple to delete
*/
public void deleteTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
DbFile updateFile = Database.getCatalog().getDatabaseFile(t.getRecordId().getPageId().getTableId());
List<Page> updatePages = updateFile.deleteTuple(tid, t);
updateBufferPool(updatePages, tid);
}
/**
* update:delete ; add
*
* @param updatePages 需要变为脏页的页列表
* @param tid the transaction to updating.
*/
public void updateBufferPool(List<Page> updatePages, TransactionId tid) {
for (Page page : updatePages) {
page.markDirty(true, tid);
// update bufferPool
lruCache.put(page.getId(), page);
}
}
/**
* Flush all dirty pages to disk.
* NB: Be careful using this routine -- it writes dirty data to disk so will
* break simpledb if running in NO STEAL mode.
*/
public synchronized void flushAllPages() throws IOException {
// some code goes here
// not necessary for lab1
for (Map.Entry<PageId, LRUCache.Node> group : lruCache.getEntrySet()) {
Page page = group.getValue().val;
if (page.isDirty() != null) {
this.flushPage(group.getKey());
}
}
}
/**
* Remove the specific page id from the buffer pool.
* Needed by the recovery manager to ensure that the
* buffer pool doesn't keep a rolled back page in its
* cache.
* <p>
* Also used by B+ tree files to ensure that deleted pages
* are removed from the cache so they can be reused safely
*/
public synchronized void removePage(PageId pid) {
// some code goes here
// not necessary for lab1
if(pid != null){
lruCache.removeByKey(pid);
}
}
/**
* Flushes a certain page to disk
*
* @param pid an ID indicating the page to flush
*/
private synchronized void flushPage(PageId pid) throws IOException {
// some code goes here
// not necessary for lab1
Page target = lruCache.get(pid);
if(target == null){
return;
}
TransactionId tid = target.isDirty();
if (tid != null) {
Page before = target.getBeforeImage();
Database.getLogFile().logWrite(tid, before,target);
Database.getCatalog().getDatabaseFile(pid.getTableId()).writePage(target);
}
}
/**
* Write all pages of the specified transaction to disk.
*/
public synchronized void flushPages(TransactionId tid) throws IOException {
// some code goes here
// not necessary for lab1|lab2
for (Map.Entry<PageId, LRUCache.Node> group : this.lruCache.getEntrySet()) {
PageId pid = group.getKey();
Page flushPage = group.getValue().val;
TransactionId flushPageDirty = flushPage.isDirty();
Page before = flushPage.getBeforeImage();
// 涉及到事务就应该setBeforeImage
flushPage.setBeforeImage();
if (flushPageDirty != null && flushPageDirty.equals(tid)) {
Database.getLogFile().logWrite(tid, before, flushPage);
Database.getCatalog().getDatabaseFile(pid.getTableId()).writePage(flushPage);
}
}
}
/**
* Discards a page from the buffer pool.
* Flushes the page to disk to ensure dirty pages are updated on disk.
* 直接在LRU中实现
*/
private synchronized void evictPage() {
// some code goes here
// not necessary for lab1
}
private static class LRUCache {
int cap,size;
ConcurrentHashMap<PageId,Node> map ;
Node head = new Node(null ,null);
Node tail = new Node(null ,null);
public LRUCache(int capacity) {
this.cap = capacity;
map = new ConcurrentHashMap<>();
head.next = tail;
tail.pre = head;
size = 0;
}
public synchronized Page get(PageId key) {
if(map.containsKey(key)){
remove(map.get(key));
moveToHead(map.get(key));
return map.get(key).val ;
}else{
return null;
}
}
public synchronized void put(PageId key, Page value) {
Node newNode = new Node(key, value);
if(map.containsKey(key)){
remove(map.get(key));
}else{
size++;
if(size > cap){
Node removeNode = tail.pre;
// 丢弃不是脏页的页
while (removeNode.val.isDirty() != null && removeNode != head){
removeNode = removeNode.pre;
}
if(removeNode != head && removeNode != tail){
map.remove(tail.pre.key);
remove(tail.pre);
size--;
}
}
}
moveToHead(newNode);
map.put(key,newNode);
}
public synchronized void remove(Node node){
Node pre = node.pre;
Node next = node.next;
pre.next = next;
next.pre = pre;
}
public synchronized void removeByKey(PageId key){
Node node = map.get(key);
remove(node);
}
public synchronized void moveToHead(Node node){
Node next = head.next;
head.next = node;
node.pre = head;
node.next = next;
next.pre = node;
}
public synchronized int getSize(){
return this.size;
}
private static class Node{
PageId key;
Page val;
Node pre;
Node next;
public Node(PageId key ,Page val){
this.key = key;
this.val = val;
}
}
public Set<Map.Entry<PageId, Node>> getEntrySet(){
return map.entrySet();
}
}
}
- 测试结果:

二、总结
总的来说lab2对于深入理解操作符,包括页的置换来说还是挺有帮助的。但是建议还是多画画图,才能理解各种数据结构之间的关系。后面大概还要实习几个月,还是希望能抽空尽早写完orz…如有不足,欢迎指正~