前情提要
随着数据规模以及应用业务场景复杂度的不断增加,更大规模数据量的数据库应用场景出现,对于传统关系型数据库的优化能力要求也更高。
因为SQL是解释性语言,用户可以指定要什么,而无需关心如何达成目的。所以对于同样一条SQL,数据库可以有大量的执行计划返回同样的结果,而这些计划对应的时间可能产生数量级差异,因此优化器就显得尤为重要。
问题往往就出现在优化器无法给出最优的执行计划,而基数估计则是优化器的阿喀琉斯之踵。
“基数估计”的特殊情况
自SYSTEM-R诞生以来,基数估计的理论就开始逐渐的走向成熟。传统的基数估计基本思想是在不真正执行SQL语句的基础上,快速而准确的估算出各种算子(扫描、连接、聚集等)的选择率,进而为代价计算服务。
计算选择率则需要统计信息和选择率计算公式,直方图和MCV等统计信息技术应用而生,相应的针对不同的操作符、操作符组合、算子的选择率计算公式也随之出现。
高频值MCV信息
直方图信息
基于上述技术,大部分情况下基数估计与实际值基本一致,但是现实情况是复杂的,不可避免的会出现一些特殊情况:
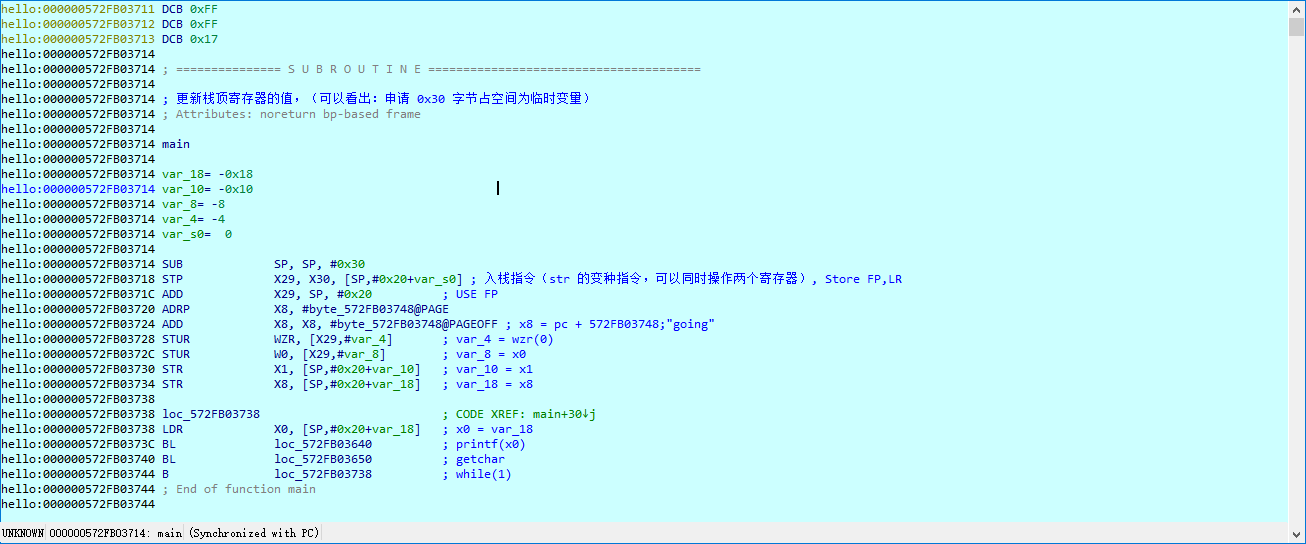
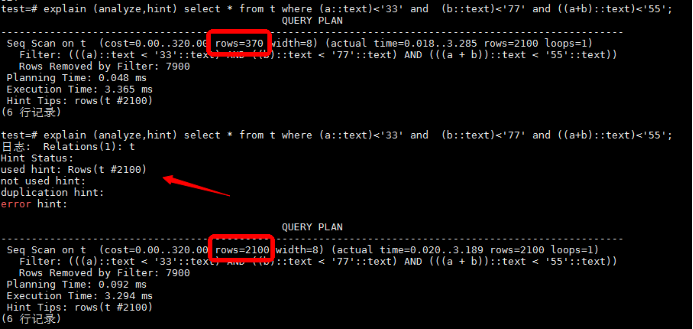
如该例中,T1、T2表做连接操作,其中T1表由于约束条件的复杂性,传统方案无法准确估算出准确基数内容,rows的估算值和实际值相差甚远,T1因rows估算值过大,作为外表进行nestloop连接。
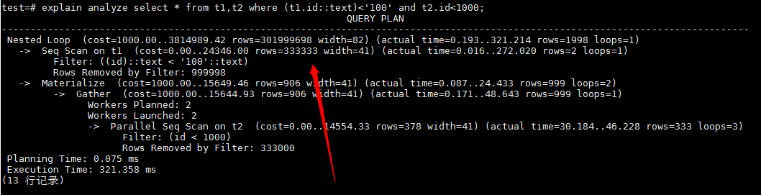
此时,T1的rows实际值是远低于T2的,按照nestloop连接原理,应当作为内表进行连接操作,但由于基数估计错误,使得计划选择错误。那么如何解决基数估计错误的相关问题呢?
传统“手动挡”方案
当遇到传统性能问题时,运维人员会根据问题原因进行手动调节,就基数估计错误的部分场景,金仓数据库也提供了诸多“手动挡”方案:
① 指数补偿 vs 复杂约束条件
传统数据库使用完全独立假设计算选择率,其计算公式如下:
基数估算值 = p0×p1×p2×…×原有数据量
但随着约束条件增多,或是约束条件之间关联性更强,其假设的基数估计偏差可能也会越大,金仓数据库采用指数补偿来弥补这一缺陷。但ROWS的估算内容与真实值还是有较大偏差。
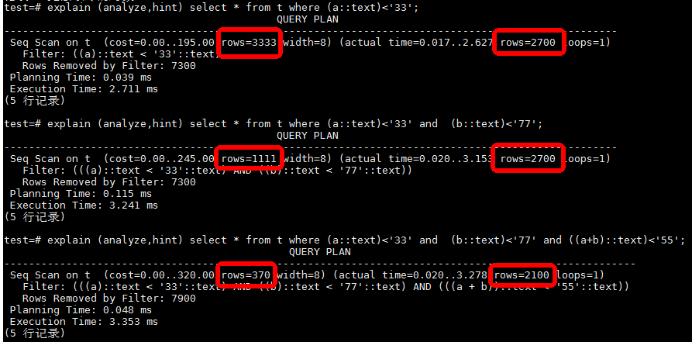 传统解决方案
传统解决方案
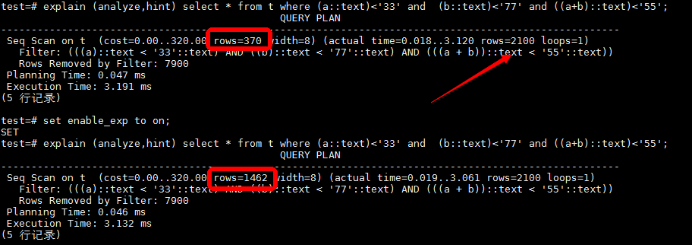 使用指数补偿
使用指数补偿
② 扩展统计信息 vs 函数依赖
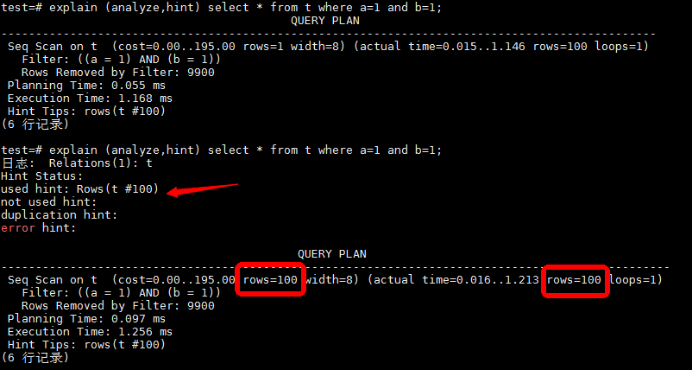
如出现函数依赖的统计信息内容,例如:当a等于1时,b也一定等于1,金仓数据库提供了扩展统计信息来进行优化。但扩展统计信息解决的基数估计内容非常有限。
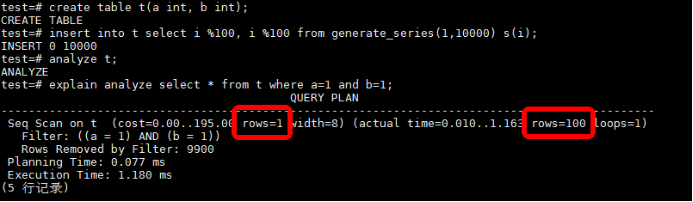 传统方案
传统方案
 使用扩展统计信息
使用扩展统计信息
③ “万金油”HINT
当出现基数估计不准,运维人员可锁定问题位置,直接使用ROWS HINT进行基数估计修正。如刚刚提到的两个示例,可用HINT直接修正:
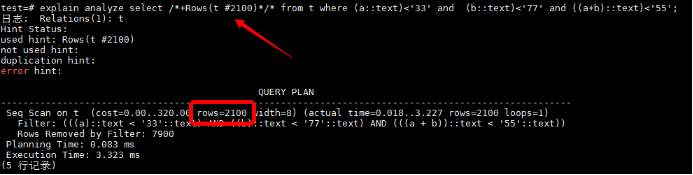
 HINT解决前两个问题
HINT解决前两个问题
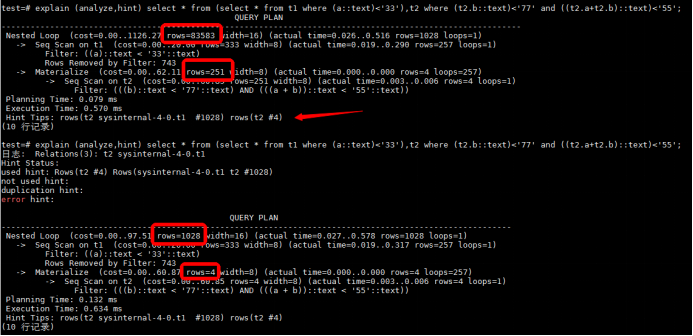
但当出现系统自命名的表信息,如连接表的基数估计修正,或是面对更加庞大的SQL集合,凭借运维人员独立筛选,效率极低。
 HINT处理系统自命名信息
HINT处理系统自命名信息
以上方案都可以解决一部分基数估计错误的场景,但在解决问题上,一方面对运维人员有较高的要求;另一方面,大部分方案的应用场景有限;传统数据库要想“破局”,必须探索其他办法修正基数估计错误的问题。
金仓“自动挡”方案
我们在传统“手动挡”方案中,提到了“万金油”HINT,其最大的作用就是修正单个SQL语句中,执行计划不准的问题,只是需要运维人员先做诊断,再对症下药。那为何不将“手动”变为“自动”?为ROWS类型HINT修正加一个触发器,自动扫描并更正基数估计错误的内容!

说干就干!金仓数据库推出了“自适应基数估计”,在执行过程中收集更多统计信息,让静态决策变为动态决策,根据运行时的真实信息调整执行计划,Plan 由真实的数据本身在运行时决定,不同的数据会拥有不同的执行策略。
“自适应基数估计”,主要包含两大功能:
给出HINT建议
当使用explain (analyze,hint)时,倘若出现基数估计错误时,会自动给出HINT建议,当用户将自适应基数估计特性关闭后,可使用这些HINT建议控制SQL语句使用优化后的执行计划。
自动修正错误的执行计划
第一次执行SQL语句,优化器使用缺省的基数估计算法来估计基数。当该语句执行完成后,会使用实际的返回行数和基数估计值进行比较,将基数估计不准确的运算节点的基数值进行修正,来保证第二次执行相同的SQL语句时,基数估计准确。
那么我们来回看传统数据库解决的方案问题,当开启基数估计自适应时,都自动定位到了基数估计不准的位置,并予以修正。
① 自适应基数估计 vs 复杂约束条件
② 自适应基数估计 vs函数依赖
③ 自适应基数估计 vs HINT修正困难问题
应用自适应基数估计后,数据库将自动检测并使用真实值,使得估算差距较大的rows及时得到更正,从而使得选择率计算准确,计划选择更精准,分析更快速,该方案可以高效解决所有基数估计错误的场景。
快来看看实际案例的情况吧~
当前,金仓数据库内核中已添加了基数估计内容的自适应基数估计功能,并于近期在某行业核心应用的性能优化上,取得显著效果。面对系统中多条SQL的优化问题,自适应基数估计功能快速定位并自行修正了因统计信息不准造成的执行计划选择问题。
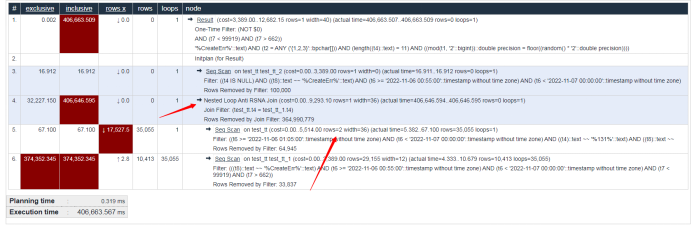
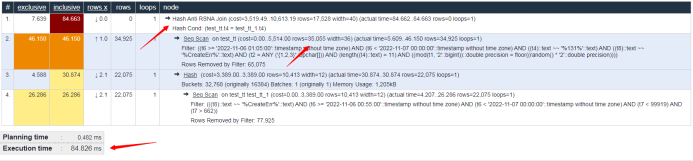
其中较为明显的用例如上(其数据及表信息内容已脱敏):因多函数条件造成的估算不准问题,当基数估计修改后,计划选择由NestLoop更正为HashJoin,效率提升4000多倍!
1
END
1
传统数据库在面对统计信息缺失或者不准的问题,能做的只有使统计信息变准、不断优化算法,但面对众多业务场景下SQL种类复杂的情况,难以实现真正的“准”。而自适应基数估计在信息收集的准确性、及时性基础上,自动对基数估计错误内容进行检测,并提供相应的解决方案,提升数据处理的效率,有效缩短运维响应的时间,帮助企业把关注点从数据库和平台层转回,更多关注到业务和应用。
当然,该功能的内容、应用场景还有待拓宽,未来金仓会结合前沿理论,通过各类实际案例的应用实践,在自感知、自诊断、自建议、自优化等方面,不断增强与完善,使数据库更智能,为运维人员及用户提供更好的使用体验,为实现数据库“全自动”不断前进!
 供稿:产品研发中心
供稿:产品研发中心
编辑:王堇
审核:日尧