文心与飞桨,向我们展示了领先大模型的生产力。
大模型应用卷到了什么地步?几天前,我们看到的还是写文章、画图、回答数学问题,现在已经有人这么用了:

如果把一长段对话转发到别的群聊里,AI 可以自动生成总结。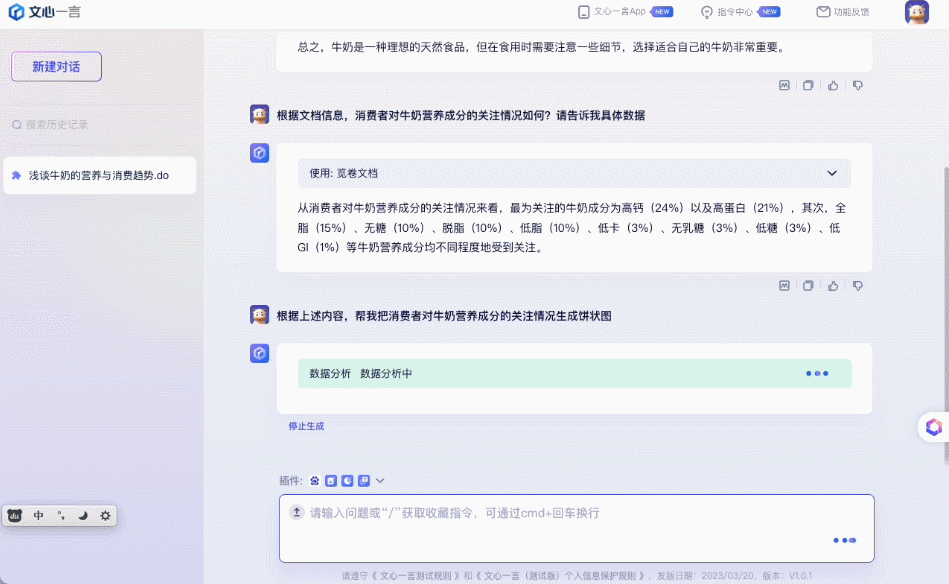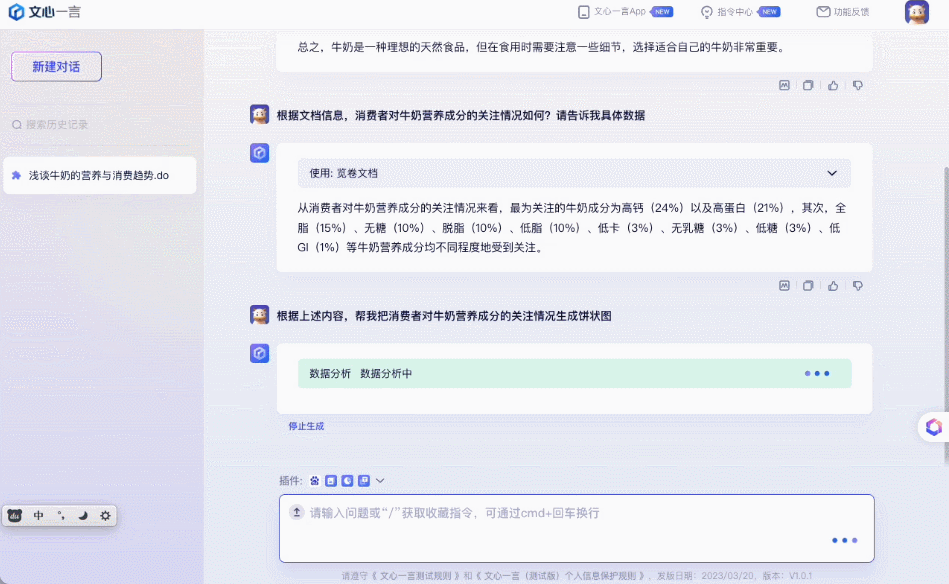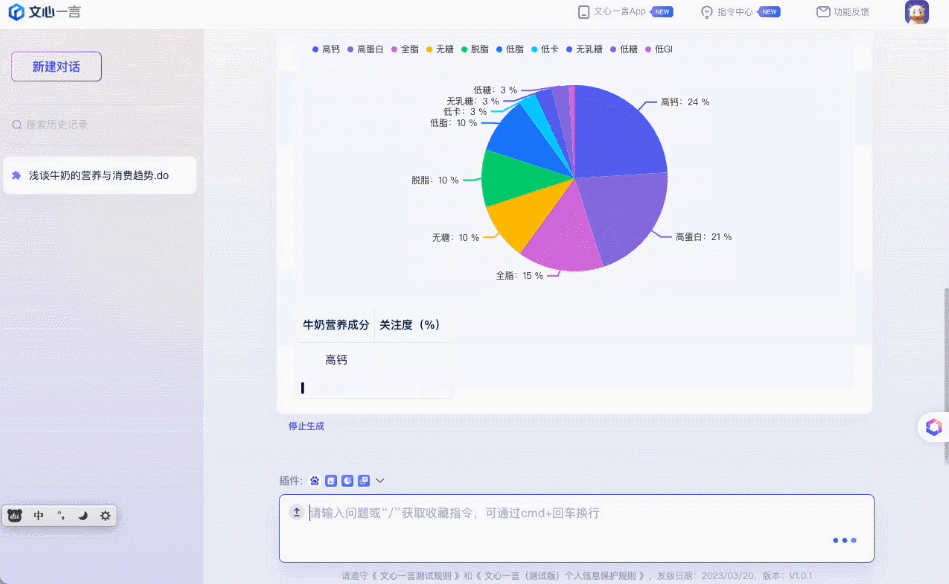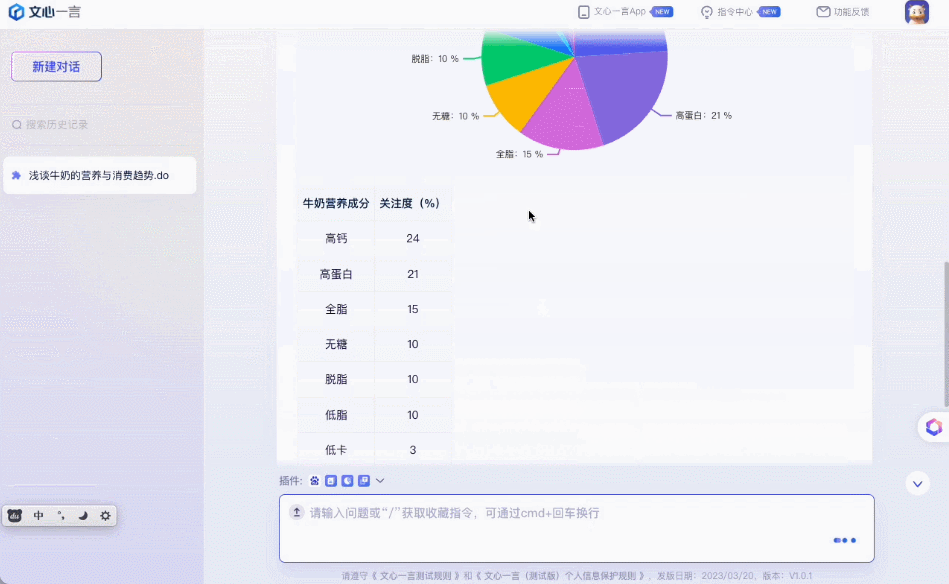 拿到数据后,直接进行有理有据还配图的分析。
拿到数据后,直接进行有理有据还配图的分析。
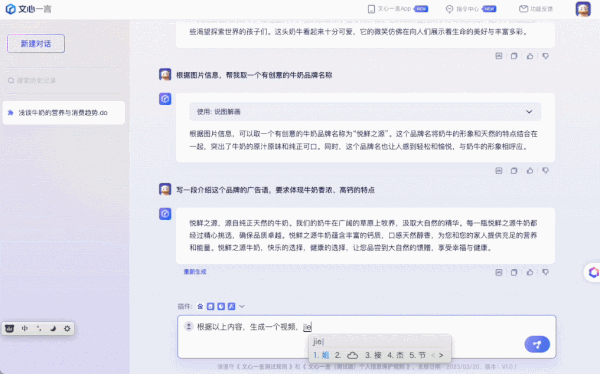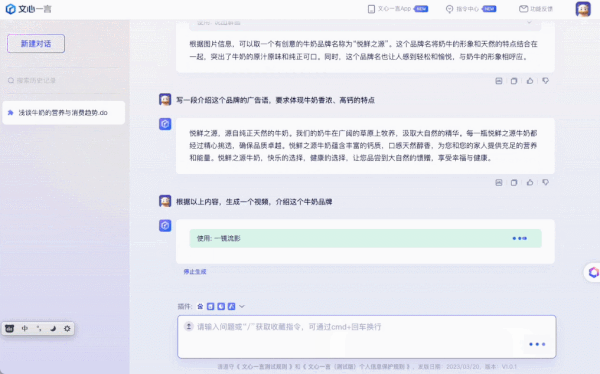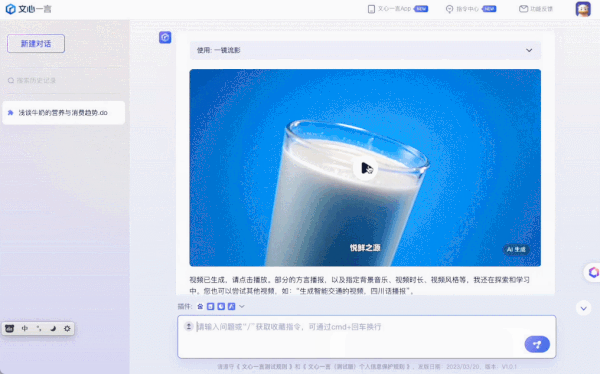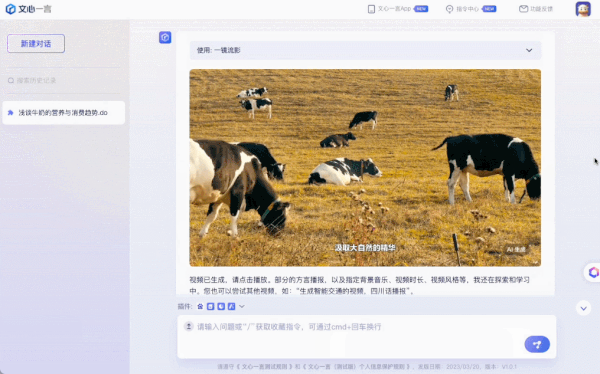 从市场分析、品牌构建、到输出视频广告,全部流程只需和 AI 进行简单对话就能完成。这是刚刚结束的 WAVE SUMMIT 大会上,百度展示的文心大模型、飞桨平台、AI 原生应用如流等一系列技术、产品及生态成果。
从市场分析、品牌构建、到输出视频广告,全部流程只需和 AI 进行简单对话就能完成。这是刚刚结束的 WAVE SUMMIT 大会上,百度展示的文心大模型、飞桨平台、AI 原生应用如流等一系列技术、产品及生态成果。
最近一段时间,大语言模型取得了令人震撼的技术突破。以大语言模型为代表的人工智能正在深入千行百业,加速产业升级和经济增长。百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰表示,大语言模型具备了理解、生成、逻辑、记忆等人工智能的核心基础能力,为通用人工智能带来曙光。
王海峰进一步表示,人工智能具有多种典型能力,理解、生成、逻辑、记忆是其中的核心基础能力,这四项能力越强,越接近通用人工智能。
 面对人工智能的这次重要变革,飞桨和文心大模型这两个百度核心技术拿出了一系列领先的发布。
面对人工智能的这次重要变革,飞桨和文心大模型这两个百度核心技术拿出了一系列领先的发布。
文心大模型:遥遥领先
国内的 AI 领域中,百度一直走在技术的前沿,最早可以追溯到 2019 年 3 月发布的 ERNIE 1.0。今年 3 月,百度又率先揭幕了自研知识增强大语言模型「文心一言」,其经过数万亿数据、千亿知识的训练,并采用了有监督精调、人类反馈的强化学习和提示等技术,具备知识增强、检索增强和对话增强等技术优势。
文心大模型的最新版本是前不久发布的 3.5 版。百度集团副总裁、深度学习技术及应用国家工程研究中心副主任吴甜表示,文心一言熟练掌握的创作体裁超过 200 种,涵盖了几乎所有写作需求,内容丰富度是初期的 1.6 倍、思维链长度是初期的 2.1 倍,知识点覆盖是初期的 8.3 倍。

新版本中,文心大模型进一步在基础模型、知识增强、检索增强等核心技术上进行创新,实现了基础模型、精调技术、知识点增强、逻辑推理、插件机制等方面的改进。
其中在知识和检索增强基础上,文心大模型 3.5 提出「知识点增强技术」,让模型能够更好地利用精细的知识点来提升理解生成能力,提升了对世界知识的掌握和运用。
推理方面,通过大规模逻辑数据构建、逻辑知识建模、多粒度语义知识组合以及符号神经网络技术,文心大模型提升了逻辑推理、数学计算及代码生成等任务上的表现。
能给我们带来更明显感知的是插件。我们知道,在实际应用时大模型有时会面临数据有限,能力不够专精的问题。在 3.5 版本上,文心大模型新增了插件机制,已上线的官方插件有百度搜索、览卷文档、一镜流影、说图解画、E 言易图。其中:
-
百度搜索是默认插件,让文心一言具备了获得实时准确信息的能力。
-
览卷文档借助文档智能模型及搜索系统可实现对文档的格式、布局等信息的充分理解及定位,突破了大模型对文档长度理解的限制。现在我们能利用文心与文档进行「对话」,解决针对文档的摘要、问答及创作的需求。
-
一镜流影依托文心跨模态大模型,突破了不同模态之间语义对齐等技术难题,创新融合文本、视觉、语音、跨模态等一系列技术能力,用户仅需简单输入文字,即可在 1 分钟内获得完整视频。
-
说图解画接入文心跨模态大模型,实现了图片理解的能力,不仅可以让 AI「看图说话」、还可深入理解图片氛围和情感。用户上传上传图片即可满足随拍发文、电商配文等图片配文需求,也以帮你激发灵感。
-
E言易图则实现了将文字需求转化为可视化图表的需求。仅需简单的数据图表需求,或输入待生成图标的数据内容,即可生成可交互图表,协助用户完成数据分析、洞察及图表信息的交互演示。据了解,E 言易图已支持7类图表的生成,包括数据图、饼状图、折线图、雷达图、漏斗图、思维导图、散点图。
在现场,吴甜演示了文心一言应用插件的方式,在和 AI 对话的过程中,现在你已可以让大模型进行总结长文内容,图表展示数据,读取图像、生成文案,甚至还能合成带语音的视频。文心一言只花了 5 分钟,就完成了从行业调研、品牌分析选择到生成宣传视频,这样一个完整场景的工作。
插件进一步扩展了大模型的能力边界,对于文心大模型生态也至关重要。百度表示,文心一言还将上线更多优质官方和第三方插件,同时逐步开放插件生态,帮助开发者基于文心大模型打造 AI 原生应用。
为实现这一目标,百度依托于「文心一言」的核心技术,提供了插件开发工具集,可以支持信息服务类、工具类、以及基于大语言模型创新类等多类型的插件开发。开发完成后,还可以通过插件接入平台和应用层生态进行紧密结合。

插件能力正式启动邀测:yiyan.baidu.com/developer
与此同时,飞桨 AI Studio(星河社区)最新升级,正式推出星河大模型社区,在星河大模型社区,开发者可以获得一体化大模型开发体验。目前,星河大模型社区已积累超 300 个大模型创意应用,社区还提供了丰富的功能方便开发者进行交流。
会上,百度还最新发布了文心大模型「星河」共创计划,将以丰富的大模型资源、多层次的产业生态资源,携手广大开发者和生态伙伴们,激活数据资源价值,共建大模型插件,广泛创新 AI 应用。
飞桨开源框架 v2.5,拥抱大模型
文心大模型之所以能颠覆生产力,除了因为 AI 算法层面创新,也离不开深度学习框架的优化。
百度在人工智能领域是为数不多有全栈布局的公司,能力覆盖从芯片到应用。在框架层面上,飞桨深度学习平台向上支撑大模型生产,提高模型部署效率和灵活性,向下则适配各类硬件,提高硬件适配效率和降低成本。
今天的 WAVE SUMMIT 上,飞桨开源框架正式发布 2.5 版,完成了全面的架构升级,同时在大模型训练、推理和多硬件适配方面带来了新的功能。
其中的重点,就是与文心大模型做了联合优化。
通过飞桨深度学习框架在大模型训练、推理、硬件适配等方面的一系列新技术,文心大模型的训练推理效率得到了大幅提升。现场给出一组数字:通过协同优化,文心大模型 3.5 的训练速度是优化前的 3 倍,推理速度更是快了 30 多倍。
其中在大模型训练方面,飞桨与文心在硬件集群上进行协同优化,提升了有效训练时间占比,芯片层面上进行了芯片、存储、网络协同优化,提升训练吞吐速度。

而在软件上,飞桨与模型算法协同优化提高了模型收敛的效率。特别是在大模型训练中,优化的收敛效率和稳定性大幅度减少了训练时间,达到了事半功倍的效果。
很多科技公司都在对大模型的训练进行优化,而在推理上,我们面临着更大、更严峻的挑战。李彦宏曾表示:「当别人刚刚开始思考如何进行训练的时候,我们已经在推理上冲出了很远。」
在大模型推理方面,飞桨从模型压缩、推理引擎、服务部署三个关键环节,开展了全方位的协同优化。
 除了采取了自适应 Shift-SmoothQuant 压缩算法、结合场景的混合量化推理方案、动态插入批处理技术等,飞桨还持续结合算子融合加速、变长输入处理加速等方法,让文心大模型推理速度达到优化前的 30 多倍。
除了采取了自适应 Shift-SmoothQuant 压缩算法、结合场景的混合量化推理方案、动态插入批处理技术等,飞桨还持续结合算子融合加速、变长输入处理加速等方法,让文心大模型推理速度达到优化前的 30 多倍。
为了更好的支撑大模型生产与应用,飞桨的大模型套件打通了整个流程,围绕大模型开发、训练、精调、压缩、推理、部署的六个阶段全流程进行了升级,降低了大模型开发和应用成本。
飞桨框架对于算大模型的优化,也离不开软硬件协同能力的不断提升。飞桨为文心大模型在各类硬件上的部署提供了统一方案,还推动建设了软硬件适配的国家标准。
此前,由中国电子技术标准化研究院牵头,百度、曙光、飞腾、浪潮一起联合起草了国家标准《人工智能 深度学习框架多硬件平台适配技术规范》。基于该标准,飞桨与 30 多家硬件厂商开展软硬协同深度优化,大大提升了软硬件适配的效率。

在此之上,文心大模型与英伟达、寒武纪、华为等 12 家硬件伙伴开展了适配,覆盖了云和端侧多种硬件类型。目前已有 25 家硬件伙伴共建 AI Studio 硬件生态专区,为 AI Studio 大模型社区引入多元生态算力,支持开发者基于 AI Studio 的大模型开发及多样应用体验。
在基础层面上,飞桨也完成了重要升级。通过建设基础算子体系和组合算子机制,飞桨将神经网络编译器 CINN 更好地与主框架融合打通,借助其通用编译优化能力,实现了更加通用的性能优化。往上看,基础框架的自动微分也更加完善,实现了动静统一的高阶自动微分开发接口,可以更低成本实现高阶自动微分能力。
 马艳军表示,使用飞桨编译器,可以获得相比其他业内主流框架更好的性能。
马艳军表示,使用飞桨编译器,可以获得相比其他业内主流框架更好的性能。
基于飞桨框架的能力升级,特别是高阶自动微分能力,飞桨开源平台已发布赛桨 PaddleScience、螺旋桨 PaddleHelix、量桨 Paddle Quantum 等开源 AI for Science 工具,支持复杂外形障碍物绕流、结构应力应变分析、材料分子模拟等丰富领域算例,广泛支持 AI + 计算流体力学、生物计算、量子计算等前沿方向的科研和产业应用。
 经由基础框架的两大升级,飞桨全新的训练架构已初步成型,不仅保持了动静统一、一行代码动转静训练部署的优势,而且通过编译器技术进一步降低了模型性能优化的边际成本。
经由基础框架的两大升级,飞桨全新的训练架构已初步成型,不仅保持了动静统一、一行代码动转静训练部署的优势,而且通过编译器技术进一步降低了模型性能优化的边际成本。
在解决了大模型开发和部署过程中的各类问题之后,飞桨平台现在做到了让 AI 模型的研发门槛更低、效果更好、流程更加标准化。
颠覆生产力
大会上,百度展现了大语言模型与智能工作的结合,重塑了人们工作的范式。
文心一言的能力已通过智能工作平台「如流」应用在百度内部的工作流程中。现场,百度集团副总裁、百度集团首席信息官李莹重磅发布如流「超级助理」。

它可以解决你工作中的大部分问题。在大会上,百度进行了一番演示。
文档处理是生产力工作的刚需,在大量文档中寻找和跳转经常会耗费很多时间。大模型出现后,你只需要给超级助理发出指令,它就可以立即找出相关文档。如果你需要了解新的知识,大模型可以生成详细的回答,如果你点击其中附带的参考链接发现是英文论文,也可以让大模型生成中文的摘要。

据说,现在百度的很多员工都在用如流超级助理,AI 在很多小细节上可以成倍的提升效率。
说到提升效率,在科技公司里,如何能更好的写代码是很重要的事,李莹现场演示了基于文心大模型的编码工具 Comate X 智能编程助手,它目前支持 30 多种语言和 10 多种 IDE,甚至包括一些非常小众的语言,像汽车硬件的语言。
以代码生成为例,Comate 可根据自然语言的描述,生成对应的代码片段,也支持在代码编辑区内根据注释自动生成代码实现。在代码测试能力方面,Comate 可对选定代码生成单元测试用例,极大减少工程师编写单测用例的时间,提升代码质量。
开发基于 AI 原生的应用,不仅需要代码工具,还需要有开发套件。百度提出了 Comate Stack,其中包括三个工具:评测平台 iEValue、AI 应用开发平台 IPlayground 和数据集托管平台 iDateSet。
使用这套体系,开发一个休假政策插件,只需要两个步骤,规则也不用你输入,直接给 AI 喂文档就可以了。

现在,大模型能力已成为百度员工的 AI 助手,Comate 帮助 80% 百度工程师提升了编程效率,颠覆了程序开发的模式。而这种革命性的生产力,已经吸引到超过 100 家合作伙伴的兴趣。
面向全场景、覆盖多行业
文心大模型的应用实践,在国内覆盖了最大的产业规模。
这段时间,大模型发展的进程以天为计,论文技术层出不穷,应用也不断更新,百度在这场竞争里始终保持在前列 —— 不断更新版本的文心已应用到搜索、信息流、网盘、智能音箱等产品中,面向更多普通用户开放,面向企业的落地成果也非常可观。
文心大模型建立了一套完整的大模型体系,其中基础大模型包含 NLP(自然语言理解)、CV(计算机视觉)、跨模态大模型,任务大模型包含对话、搜索、信息抽取、生物计算等典型任务。
目前,文心大模型已拥有中国最大的产业落地规模,超过 15 万家企业申请了文心一言内测,其中超过 300 家生态伙伴在 400 多个具体场景取得了测试成效,覆盖办公提效、知识管理、智能客服、智能营销等领域。百度也联合国家电网、浦发银行、泰康、吉利等企业共同发布了 11 个行业大模型。
去年王海峰指出,深度学习平台加上大模型会贯通从硬件到场景应用的 AI 全产业链,进一步加速智能化升级。如今,百度的大模型 AI 技术栈已实现全面布局,深度学习加大模型技术让 AI 真正进入了工业大生产阶段。
与此同时,飞桨也公布了最新的生态数据:整个平台已汇聚 800 万开发者,服务了 22 万家企事业单位,基于飞桨创建的模型已有 80 万个。

人们都说这段时间 ChatGPT 引发的大模型浪潮带来了生产力变革,在大模型技术不断演进的同时,AI 的新能力终究还是要落地在各行业的实践中。
而百度在这个过程中,已经走在了前面。
文章来源:机器之心公众号
作者:泽南