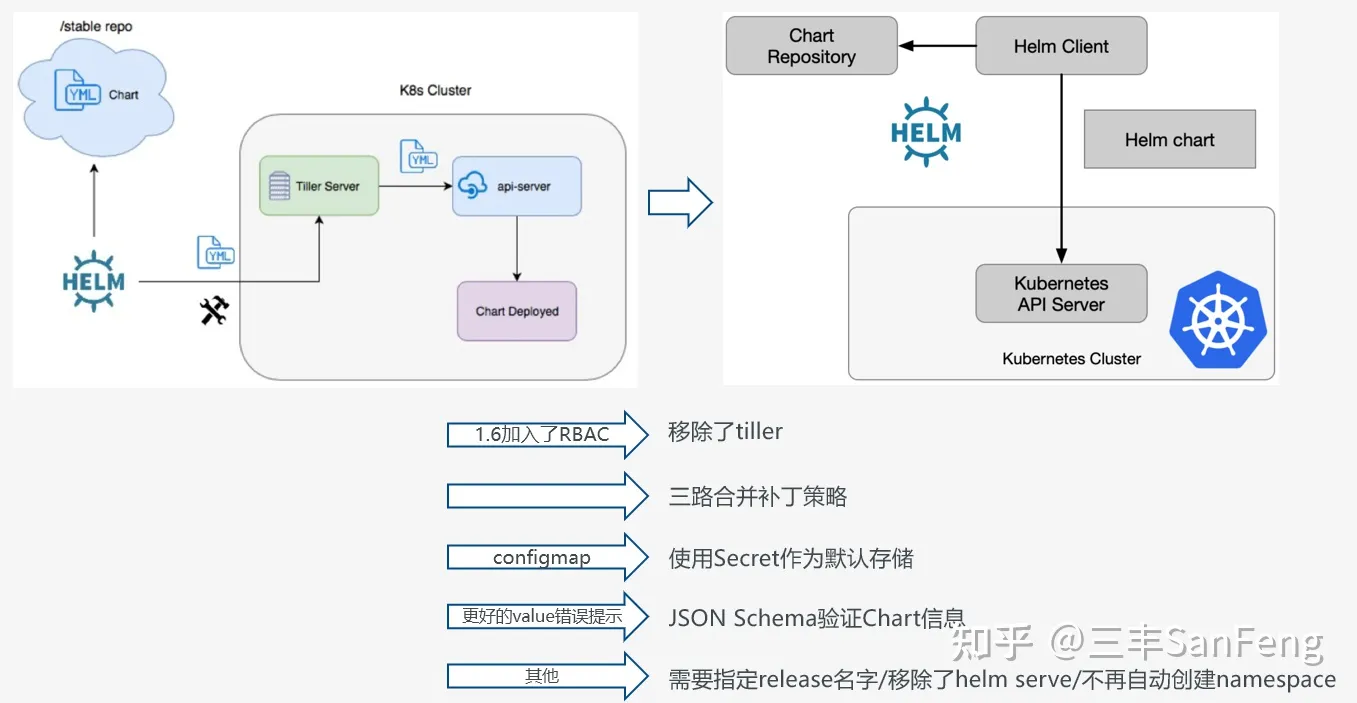
人脸识别是指程序对输入的人脸图像进行判断,并识别出其对应的人的过程。人脸识别程 序像我们人类一样,“看到”一张人脸后就能够分辨出这个人是家人、朋友还是明星。
当然,要实现人脸识别,首先要判断当前图像内是否出现了人脸,也即人脸检测。只有检 测到图像中出现了人脸,才能根据人脸判断这个人到底是谁。
人脸检测
当我们预测的是离散值时,进行的是“分类”。例如,预测一个孩子能否成为一名优秀的运动员,其实就是看他是被划分为“好苗子”还是“普通孩子”的分类。对于只涉及两个类别的“二分类”任务,我们通常将其中一个类称为“正类”(正样本),另一个类称为“负类”(反类、负样本)。
例如,在人脸检测中,主要任务是构造能够区分包含人脸实例和不包含人脸实例的分类器。这些实例被称为“正类”(包含人脸图像)和“负类”(不包含人脸图像)。
本节介绍分类器的基本构造方法,以及如何调用OpenCV中训练好的分类器实现人脸检测。
基本原理
OpenCV 提供了三种不同的训练好的级联分类器,下面简单介绍其中涉及的一些概念。
- 级联分类器
通常情况下,分类器需要对多个图像特征进行识别。例如,识别一个动物到底是狗(正类)还是其他动物(负类),我们可能需要根据多个条件进行判断,这样比较下来是非常烦琐的。
但是,如果首先就比较它们有几条腿:
- 有“四条腿”的动物被判断为“可能为狗”,并对此范围内的对象继续进行分析和判断。
- 没有“四条腿”的动物直接被否决,即不可能为狗。
这样,仅仅比较腿的数目,根据这个特征就能排除样本集中大量的负类(例如鸡、鸭、鹅等不是狗的其他动物实例)。级联分类器就是基于这种思路,将多个简单的分类器按照一定的顺序级联而成的。
级联分类器的基本原理如图 23-1 所示。
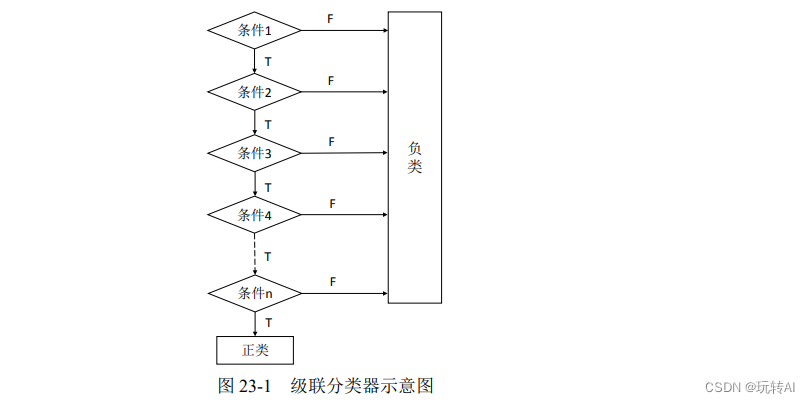
级联分类器的优势是,在开始阶段仅进行非常简单的判断,就能够排除明显不符合要求的实例。在开始阶段被排除的负类,不再参与后续分类,这样能极大地提高后面分类的速度。这有点像我们经常收到的骗子短信,大多数人通常一眼就能识别出这些短信是骗人的,也不可能上当受骗。骗子们随机大量发送大多数人明显不会上当受骗的短信,这种做法虽然看起来非常蠢,但总还是会有人上当。这些短信,在最开始的阶段经过简单的筛选过滤就能够将完全不可能上当的人排除在外。不回复短信的人,是不可能上当的;而回复短信的人,才是目标人群。
这样,骗子轻易地就识别并找到了目标人群,能够更专注地“服务”于他们的“最终目标人群”(不断地进行短信互动),从而有效地避免了与“非目标人群”(不回复短信的人群)发生进一
步的接触而“浪费”时间和精力。
OpenCV 提供了用于训练级联分类器的工具,也提供了训练好的用于人脸定位的级联分类器,都可以作为现成的资源使用。
- Haar级联分类器
OpenCV 提供了已经训练好的 Haar 级联分类器用于人脸定位。Haar 级联分类器的实现,经过了以下漫长的历史:
-
首先,有学者提出了使用 Haar 特征用于人脸检测,但是此时 Haar 特征的运算量超级大,这个方案并不实用。
-
接下来,有学者提出了简化 Haar 特征的方法,让使用 Haar 特征检测人脸的运算变得简单易行,同时提出了使用级联分类器提高分类效率。
-
后来,又有学者提出用于改进 Haar 的类 Haar 方案,为人脸定义了更多特征,进一步提高了人脸检测的效率。
下面用一个简单的例子来叙述上述方案。假设有两幅 4×4 大小的图像,如图 23-2 所示。
针对这两幅图像,我们可以通过简单的计算来判断它们在左右关系这个维度是否具有相关性。
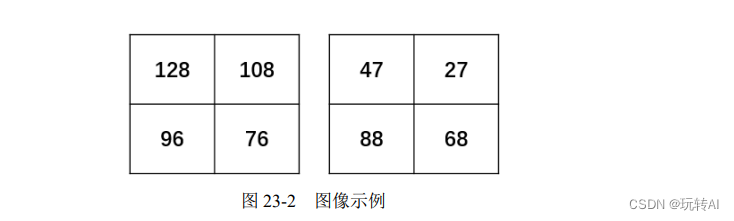
’用两幅图像左侧像素值之和减去右侧像素值之和:
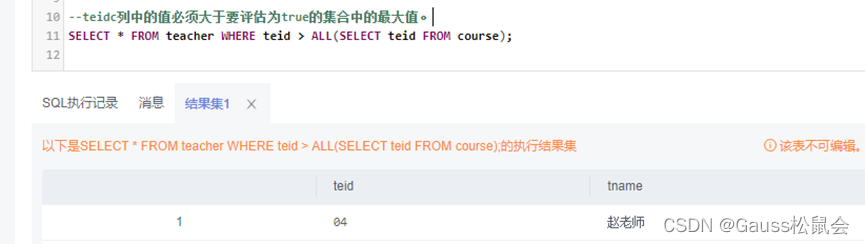
- 针对左图,sum(左侧像素) - sum(右侧像素) = (128+96) - (108+76) = 40
- 针对右图,sum(左侧像素) - sum(右侧像素) = (47+88) - (27+68) = 40
这两幅图像中,“左侧像素值之和”减去“右侧像素值之和”都是 40。所以,可以认为在“左侧像素值之和”减去“右侧像素值之和”这个角度,这两幅图像具有一定的相关性。
进一步扩展,我们可以从更多的角度考虑图像的特征。学者 Papageorgiou 等人提出了如图23-3 所示的 Haar 特征,这些特征包含垂直特征、水平特征和对角特征。他们利用这些特征分
别实现了行人检测(Pedestrian Detection Using Wavelet Templates)和人脸检测(A GeneralFramework For Object Detection)。

Haar 特征反映的是图像的灰度变化,它将像素划分为模块后求差值。Haar 特征用黑白两种矩形框组合成特征模板,在特征模板内,用白色矩形像素块的像素和减去黑色矩形像素块的像素和来表示该模板的特征。
经过上述处理后,人脸部的一些特征就可以使用矩形框的差值简单地表示了。比如,眼睛的颜色比脸颊的颜色要深,鼻梁两侧的颜色比鼻梁的颜色深,唇部的颜色比唇部周围的颜色深。
关于 Harr 特征中的矩形框,有如下 3 个变量。
- 矩形位置:矩形框要逐像素地划过(遍历)整个图像获取每个位置的差值。
- 矩形大小:矩形的大小可以根据需要做任意调整。
- 矩形类型:包含垂直、水平、对角等不同类型。
上述 3 个变量保证了能够细致全面地获取图像的特征信息。但是,变量的个数越多,特征的数量也会越多。
例如,仅一个 24×24 大小的检测窗口内的特征数量就接近 20 万个。由于计算量过大,该方案并不实用,除非有人提出能够简化特征的方案。
后来,Viola 和 Jones 两位学者在论文 Rapid Object Detection Using A Boosted Cascade OfSimple Features 和 Robust Real-time Face Detection 中提出了使用积分图像快速计算 Haar 特征的方法。他们提出通过构造“积分图(Integral Image)”,让 Haar 特征能够通过查表法和有限次简单运算快速获取,极大地减少了运算量。同时,在这两篇文章中,他们提出了通过构造级联分类器让不符合条件的背景图像(负样本)被快速地抛弃,从而能够将算力运用在可能包含人脸的对象上。
为了进一步提高效率,Lienhart 和 Maydt 两位学者,在论文 An Extended Set Of Haar-LikeFeatures For Rapid Object Detection 中提出对 Haar 特征库进行扩展。他们将 Haar 特征进一步划分为如图 23-4 所示的 4 类:
- 4 个边特征。
- 8 个线特征。
- 2 个中心点特征。
- 1 个对角特征。
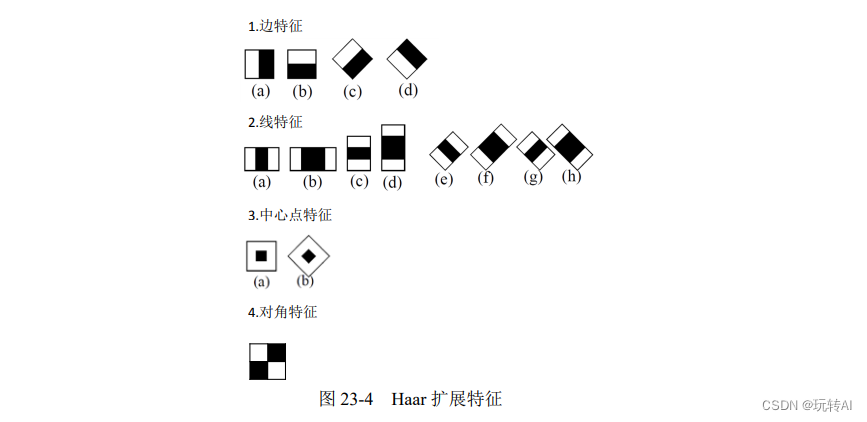
Lienhart 和 Maydt 两位学者认为在实际使用中,对角特征(见图 23-4 底部)和线特征中的“e”和“g”(见图 23-4 的第 2 行,(e)图和(g)图)是相近的,因此通常情况下无须重复计算。
同时,该论文还给出了计算 Haar 特征数的方法、快速计算方法,以及级联分类器的构造方法等内容。
OpenCV 在上述研究的基础上,实现了将 Haar 级联分类器用于人脸部特征的定位。我们可以直接调用 OpenCV 自带的 Haar 级联特征分类器来实现人脸定位。
级联分类器的使用
在 OpenCV
1.边特征
2.线特征
3.中心点特征
4.对角特征中,有一些训练好的级联分类器供用户使用。这些分类器可以用来检测人脸、脸部特征(眼睛、
鼻子)、人类和其他物体。这些级联分类器以 XML 文件的形式存放在 OpenCV 源文件的 data 目录下,加载不同级联分类器的 XML 文件就可以实现对不同对象的检测。
下载地址
https://github.com/opencv/opencv/tree/4.x/data/haarcascades
OpenCV 自带的级联分类器存储在 OpenCV 根文件夹的 data 文件夹下。该文件夹包含三个子文件夹:haarcascades、hogcascades、lbpcascades,里面分别存储的是 Harr 级联分类器、HOG级联分类器、LBP 级联分类器。
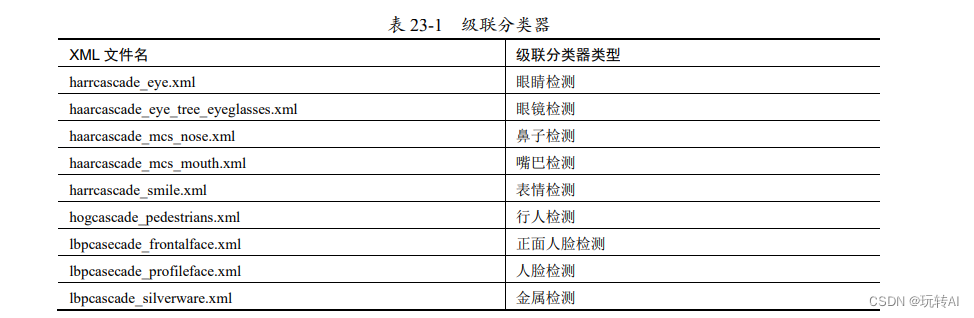
其中,Harr 级联分类器多达 20 多种(随着版本更新还会继续增加),提供了对多种对象的检测功能。部分级联分类器如表 23-1 所示。
加载级联分类器的语法格式为:
<CascadeClassifier object> = cv2.CascadeClassifier( filename )
式中,filename 是分类器的路径和名称。
下面的代码是一个调用实例:
faceCascade =
cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
使用级联分类器时需要注意:如果你是通过在anaconda中使用pip的方式安装的OpenCV,则无法直接获取级联分类器的 XML 文件。可以通过以下两种方式获取需要的级联分类器 XML
文件:
- 安装 OpenCV 后,在其安装目录下的 data 文件夹内查找 XML 文件。
- 直接在网络上找到相应 XML 文件,下载并使用。
同样,如果使用 opencv_createsamples.exe 和 opencv_traincascade.exe,也需要采用上述方式获取 XML 文件。
cv2.CascadeClassifier.detectMultiScale() 函数介绍
在 OpenCV 中,人脸检测使用的是 cv2.CascadeClassifier.detectMultiScale()函数,它可以检
测出图片中所有的人脸。该函数由分类器对象调用,其语法格式为:
objects = cv2.CascadeClassifier.detectMultiScale( image[,
scaleFactor[, minNeighbors[, flags[, minSize[, maxSize]]]]] )
式中各个参数及返回值的含义为:
- image:待检测图像,通常为灰度图像。
- scaleFactor:表示在前后两次相继的扫描中,搜索窗口的缩放比例。
- minNeighbors:表示构成检测目标的相邻矩形的最小个数。默认情况下,该值为 3,意味着有 3 个以上的检测标记存在时,才认为人脸存在。如果希望提高检测的准确率,可以将该值设置得更大,但同时可能会让一些人脸无法被检测到。
- flags:该参数通常被省略。在使用低版本 OpenCV(OpenCV 1.X 版本)时,它可能会被设置为 CV_HAAR_DO_CANNY_PRUNING,表示使用 Canny 边缘检测器来拒绝一些区域。
- minSize:目标的最小尺寸,小于这个尺寸的目标将被忽略。
- maxSize:目标的最大尺寸,大于这个尺寸的目标将被忽略。
- objects:返回值,目标对象的矩形框向量组。
示例:使用函数 cv2.CascadeClassifier.detectMultiScale()检测一幅图像内的人脸
原图:

import cv2
# 读取待检测的图像
image = cv2.imread('face\\face3.jpg')
# 获取 XML 文件,加载人脸检测器
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 色彩转换,转换为灰度图像
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
# 调用函数 detectMultiScale
faces = faceCascade.detectMultiScale(
gray,
scaleFactor = 1.15,
minNeighbors = 5,
minSize = (5,5)
)
print(faces)
# 打印输出的测试结果
print("发现{0}个人脸!".format(len(faces)))
# 逐个标注人脸
for(x,y,w,h) in faces:
cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2) #矩形标注
# 显示结果
cv2.imshow("dect",image)
# 保存检测结果
cv2.imwrite("re.jpg",image)
cv2.waitKey(0)
运行结果:
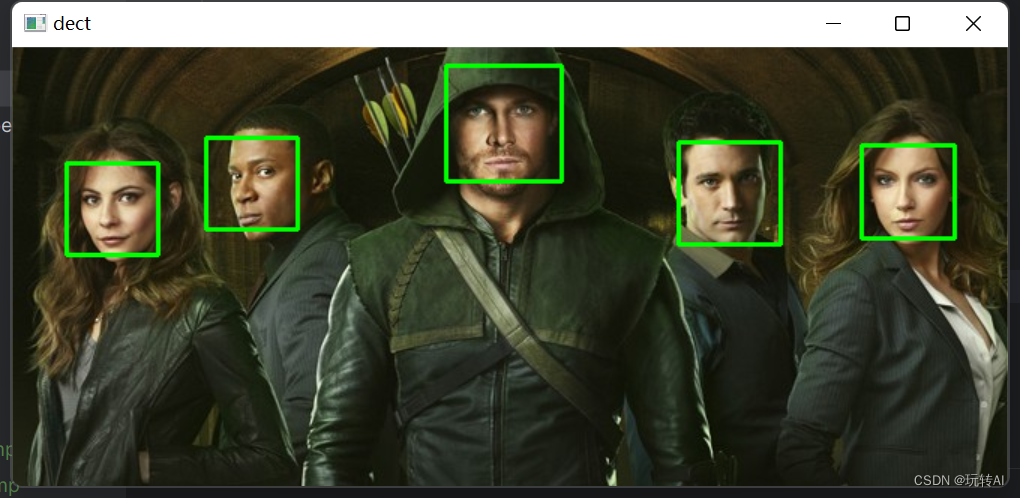
同时,在控制台会显示检测到的人脸的具体位置信息及个数,具体结果如下:
[[129 59 61 61]
[ 35 76 62 62]
[565 65 61 61]
[443 62 71 71]
[290 13 77 77]]
发现 5 个人脸!