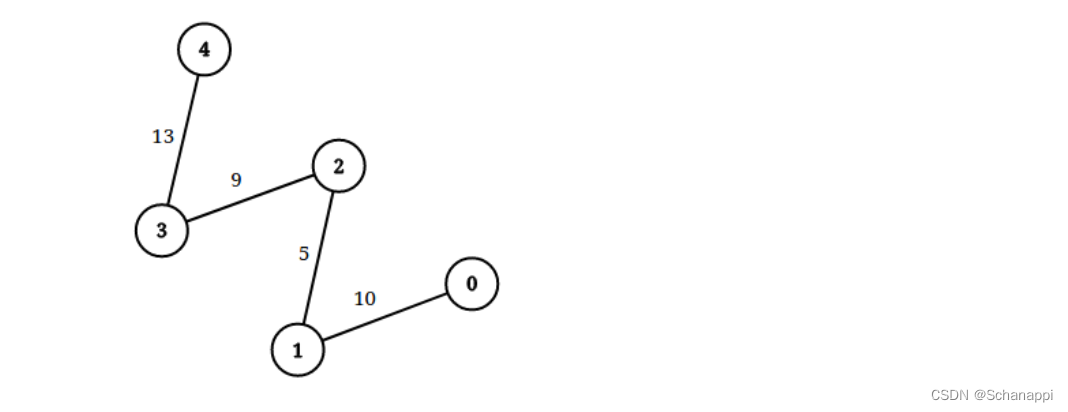
在 OpenMLDB 第 8 期 Meetup 中,OpenMLDB PMC 陈迪豪以出租车行车时间预测问题为例,使用 OpenMLDB 基于阿里云 MaxCompute 的 Serverless 服务搭建机器学习应用,从数据引入开始,实现了端到端的机器学习应用全流程构建。
云服务作为快速整合、高效计算的服务模式,极大推动着大数据的分析处理和 AI应用的升级和进化。为更好的应对数据挑战,加速AI落地,OpenMLDB 将其高性能的离线和在线特征计算引擎与阿里云 MaxCompute 的海量数据计算能力进行生态整合,满足云上开发者的 AI 应用构建需求。
OpenMLDB 与 MaxCompute 的生态整合将会于12月中旬发布的v0.7.0版本中发布,欢迎大家关注。
OpenMLDB 简介
OpenMLDB 是一个开源机器学习数据库,致力于闭环解决 AI 工程化落地的数据治理难题,为企业提供全栈的低门槛特征数据计算和管理平台。OpenMLDB 包含 Feature Store 的全部功能,并且提供更为完整的 FeatureOps 全栈方案。除了提供特征存储功能,还具有基于 SQL 的低门槛数据库开发体验、面向特征计算优化的 OpenMLDB Spark 发行版、针对实时特征计算优化的索引结构、特征上线服务、企业级运维和管理等功能,让特征工程开发回归于本质——专注于高质量的特征计算脚本开发。
MaxCompute 简介
MaxCompute 是适用于数据分析场景的企业级 SaaS (Software as a Service) 模式云数据仓库,以Serverless 架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使用户可以经济并高效地分析处理海量数据。MaxCompute 还深度融合了阿里云的一系列产品如:DataWorks、机器学习 PAI、Quick BI,使得其云上生态平滑高效。
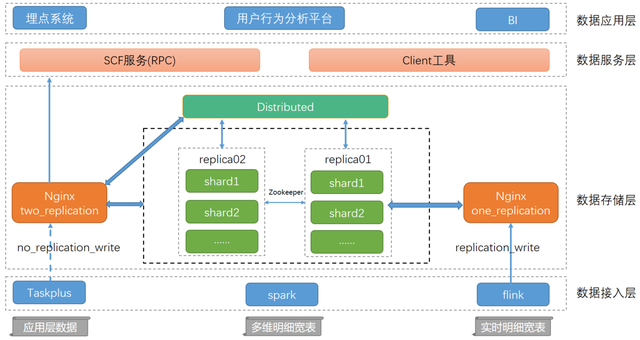
演示流程图
下图为应用搭建流程图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wpX9TyDT-1671011242332)(null)]
- 离线部分: 将原始数据集导入到阿里云 OSS,再通过阿里云 DataWorks 将数据格式转换成 MaxCompute 表,然后使用 OpenMLDB 的离线引擎来对数据做特征抽取得到样本数据,再将样本数据传入 MaxCompute,然后可以使用阿里云 PAI(机器学习平台)做模型训练,或者使用开源机器学习框架如 Tensorflow、Pytorch、LightGBM 等做模型训练得到机器学习模型(本演示使用开源模型训练工具 LightGBM)。
- 在线部分: 使用 OpenMLDB 的在线引擎对原始在线数据做实时特征计算,结合离线训练好的模型进行在线预测或推理,实现机器学习场景端到端的应用。整个过程是硬实时的,可以在 20ms 以内完成。
为了保证离线在线特征一致性,离线的特征抽取使用 OpenMLDB 离线计算引擎,而运行的后端服务为阿里云的 MaxCompute 云服务。
演示视频
【https://www.zhihu.com/zvideo/1583837565811060737】
详细流程
根据陈迪豪 meetup 上的演示,其详细流程分为六个步骤:
- 环境准备:开通阿里云账户,下载 MaxCompute 包、OpenMLDB 包
- 离线数据引入:使用 OSS、DataWorks、MaxCompute 导入离线数据
- 特征抽取计算:编写 OpenMLDB SQL 提交到 MaxCompute
- 离线模型训练:导入离线样本数据并进行机器学习模型训练
- 特征抽取 SQL 脚本上线:将第 3 步中用于特征抽取的 SQL 脚本部署上线,以提供在线的特征抽取
- 在线模型预测:基于 OpenMLDB 在线服务与机器学习模型实现 E2E 预测
步骤详解
- 环境准备:开通阿里云账户,下载 MaxCompute 包、OpenMLDB 包
- 开通阿里云账户可参考阿里云官方文档 https://help.aliyun.com/document_detail/58226.html,下图展示开通 MaxCompute 服务后可查看的项目详情。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jbf2T8AI-1671011239356)(null)] - 下载 MaxCompute 包可参考阿里云官方关于搭建本地环境的文档:https://help.aliyun.com/document_detail/118144.html
- OpenMLDB 包下载可参考官方的快速上手文档:https://openmldb.ai/docs/zh/main/quickstart/openmldb_quickstart.html
快速了解如何使用阿里云服务以及 OpenMLDB 的部署流程后,后面会详细介绍将两者整合的完整流程。
- 离线数据引入:使用 OSS、DataWorks、MaxCompute 导入离线数据
- 利用 OSS 的命令行工具在阿里云 OSS 桶内创建目录
openmldb_maxcompute_demo2,然后上传本地样本数据taxi_tour_table_train_simple.csv至该目录,数据格式为 .csv 或 .parquet 均可。本地测试数据可在 OpenMLDB 快速上手的 Docker 镜像中找到,详细使用文档可参考 https://openmldb.ai/docs/zh/main/quickstart/openmldb_quickstart.html 。ossutil 工具也可以在阿里云官方文档中下载 https://help.aliyun.com/document_detail/120075.html 。
./ossutil mkdir oss://tobe-bucket/openmldb_maxcompute_demo2/
./ossutil cp ./taxi-trip/data/taxi_tour_table_train_simple.csv oss://tobe-bucket/openmldb_maxcompute_demo2/
- 数据转换为 MaxCompute 表的格式,再引入到 MaxCompute。需要使用阿里云 DataWorks 工具,创建一个 demo 流程,拉取一个离线同步的算子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lz2sU0gE-1671011240515)(null)]
点击算子即可进行数据格式的转换,在数据来源列,设置样本数据的 OSS 数据源、文本类型和文本路径,在数据去向列设置数据源为 MaxCompute:
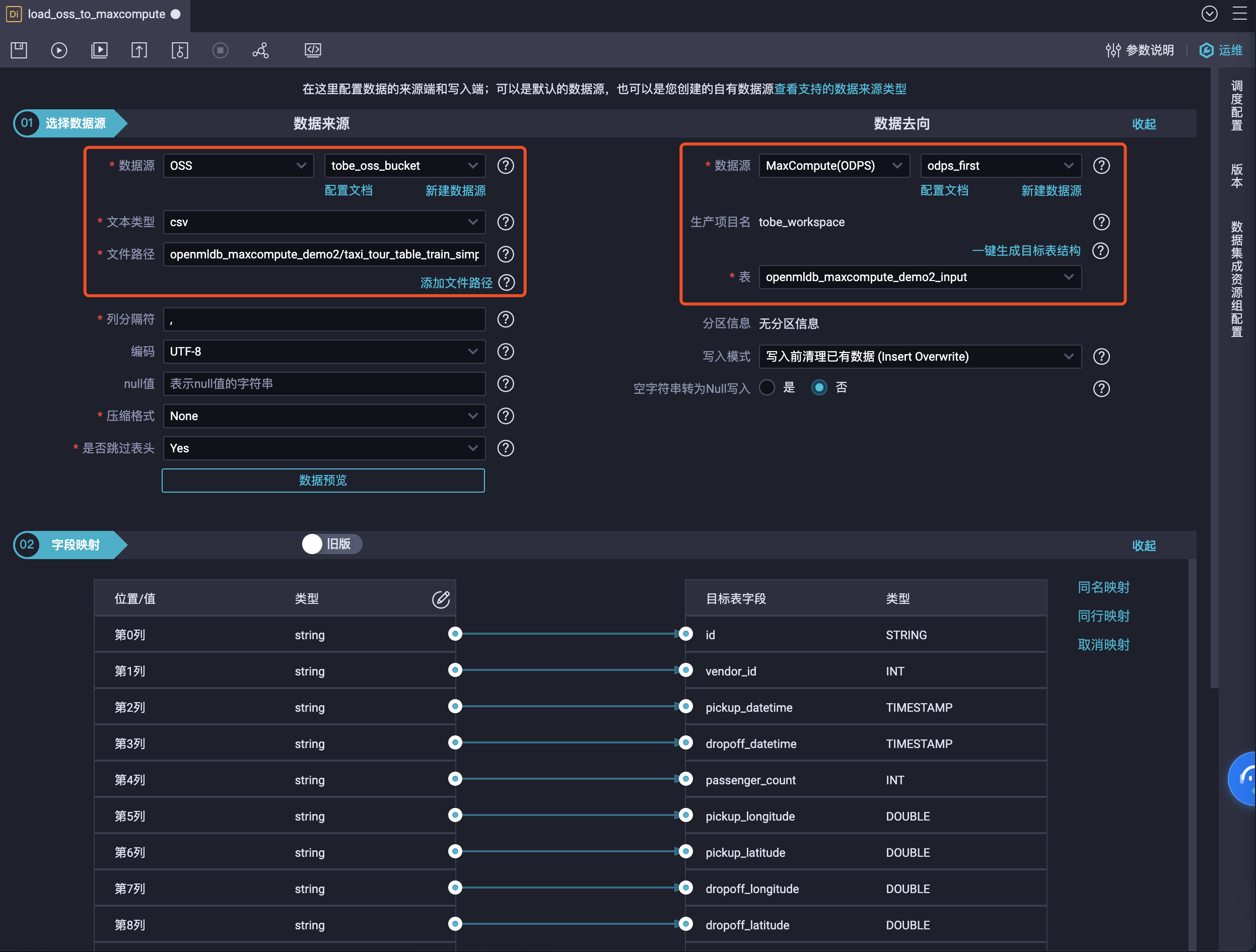
单击一键生成目标表结构,手动更改自动生成的 schema 为下方代码块中的内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FRwXXfnw-1671011239135)(null)]
CREATE TABLE IF NOT EXISTS openmldb_maxcompute_demo2_input(id string, vendor_id int, pickup_datetime timestamp, dropoff_datetime timestamp, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
建表完成后,表名会自动更新为openmldb_maxcompute_demo2_input,页面下方会显示源数据和目标数据源之间字段的映射。
最后进行数据集成资源组配置,若使用 MaxCompute 比较多,可以将方案设置成独享数据集成资源组,本文档作演示目的,将其设置为调试资源组>公共资源组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KNrbF51u-1671011235382)(https://openmldb.ai/wordpress/wp-content/uploads/2022/12/image-1670831867256.png)]
再保存方案:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CbIeoP0t-1671011243865)(null)]
然后运行方案:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1nhhvYOb-1671011244251)(null)]
最后进入阿里云 MaxCompute 工作台,可以看到创建好的表记录:
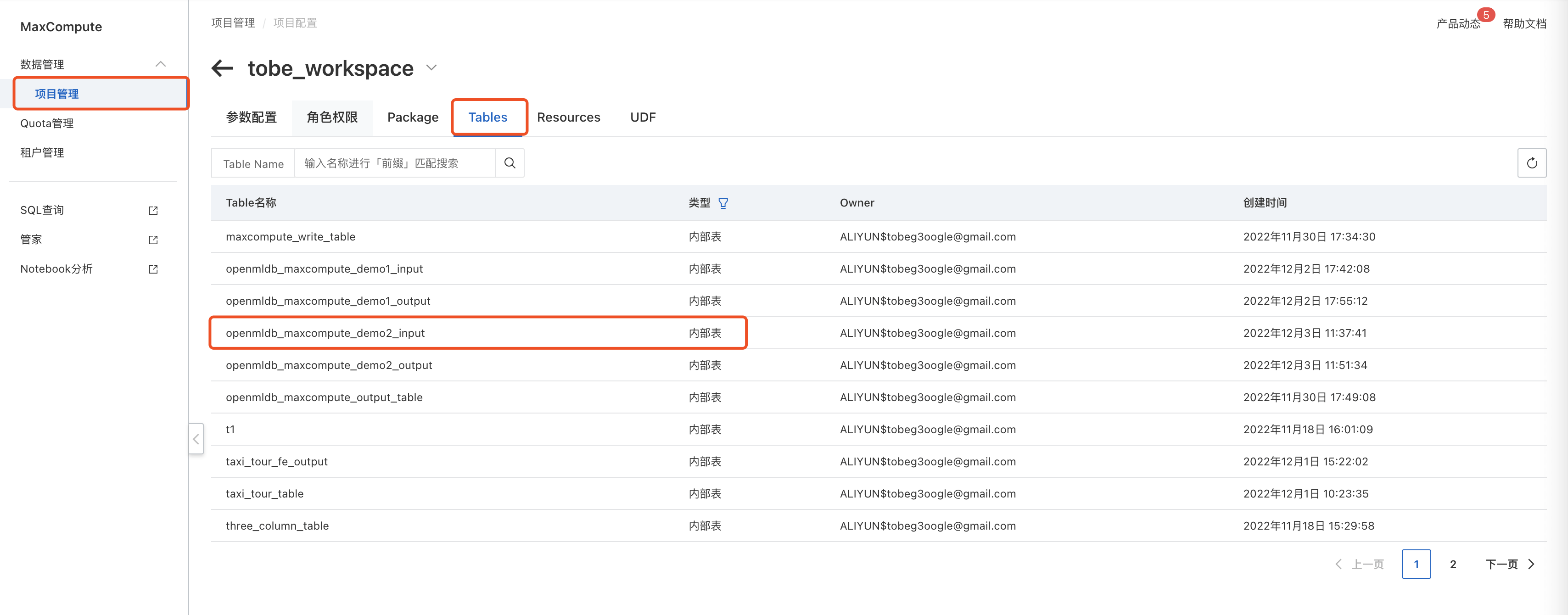
至此,离线数据顺利引入 MaxCompute。
选中表之后,基于阿里云的云上生态,可以选择 MaxCompute 集成的功能来对数据进行预览或预处理等,例如单击 SQL 查询可以调用 DataWorks 平台:

3. 特征抽取计算:编写 OpenMLDB SQL 提交到 MaxCompute
- 需要提前配置好 MaxCompute 的运行环境,同样参考阿里云 MaxCompute 官方文档 https://help.aliyun.com/document_detail/118144.html。下载对应的 Spark 包后,需要修改 spark-defaults.conf 配置文件,填写个人申请的 MaxCompute 项目名以及 AKSK 等认证信息,然后在命令行配置好环境变量,将 SPARK_HOME 指向 MaxCompute Spark 包地址。
export SPARK_HOME=/Users/tobe/code/code_examples/maxcompute_examples/spark-3.1.1-odps0.33.0/
export PATH=$SPARK_HOME/bin:$PATH
- 使用 OpenMLDB Java SDK 实现一个 Spark 应用,并且使用 OpenMLDB 离线引擎进行 SQL 计算。核心代码如下,首先通过配置 MaxCompute catalog 来读写 MaxCompute 的表数据,然后使用 OpenmldbSession 的
sql()接口进行离线任务的计算,最后将结果也导出为 MaxCompute 表。
val spark = SparkSession
.builder()
.appName("OpenmldbExportMaxcomputeTable")
.config("spark.sql.defaultCatalog","odps")
.config("spark.sql.catalog.odps", "org.apache.spark.sql.execution.datasources.v2.odps.OdpsTableCatalog")
.config("spark.sql.sources.partitionOverwriteMode", "dynamic")
.config("spark.sql.extensions", "org.apache.spark.sql.execution.datasources.v2.odps.extension.OdpsExtensions")
.config("spark.sql.catalogImplementation","hive")
.getOrCreate()
val sess = new OpenmldbSession(spark)
val inputTableName = "taxi_tour_table"
sess.registerTable("t1", spark.table(inputTableName))
val sql =
"""
|SELECT trip_duration, passenger_count,
|sum(pickup_latitude) OVER w AS vendor_sum_pl,
|max(pickup_latitude) OVER w AS vendor_max_pl,
|min(pickup_latitude) OVER w AS vendor_min_pl,
|avg(pickup_latitude) OVER w AS vendor_avg_pl,
|sum(pickup_latitude) OVER w2 AS pc_sum_pl,
|max(pickup_latitude) OVER w2 AS pc_max_pl,
|min(pickup_latitude) OVER w2 AS pc_min_pl,
|avg(pickup_latitude) OVER w2 AS pc_avg_pl,
|count(vendor_id) OVER w2 AS pc_cnt,
|count(vendor_id) OVER w AS vendor_cnt
|FROM t1
|WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW),
|w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW)
|""".stripMargin
// Run OpenMLDB offline execution
val outputDf = sess.sql(sql).getSparkDf()
完整 Scala 代码和可编译的 Maven 可在 Github 中找到:https://github.com/tobegit3hub/OpenmldbDemo/blob/main/openmldb_maxcompute_spark3/src/main/scala/com/aliyun/odps/spark/examples/openmldb/demo/OpenmldbMaxcomputeTaxiDemo.scala
3. 使用标准的 spark-submit 命令提交任务即可,因为前面已经配置好 SPARK_HOME 环境变量和 spark-defaults.conf 配置文件,因此任务会自动提交到 MaxCompute 计算集群中运行。
spark-submit --master yarn --deploy-mode cluster --class com.aliyun.odps.spark.examples.openmldb.demo.OpenmldbMaxcomputeTaxiDemo ./target/spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar
最后,可以得到一个特征抽取计算结果的 MaxCompute 表,可以在阿里云 MaxCompute 控制台>Tables 里面获取到。
4. 离线模型训练:导入离线样本数据并进行机器学习模型训练
- 导出样本数据。从 MaxCompute 导出数据到阿里云 OSS,再从 OSS 下载到本地。同样使用阿里云 DataWorks 服务,相关配置如下。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S5Uod87m-1671011244313)(null)] - 离线模型训练。在普通命令行下,执行 train.py(在 OpenMLDB 快速上手文档中 Docker 镜像的/
work/taxi-trip目录中),使用开源模型训练工具 LightGBM 基于上一步生成的离线特征表进行模型训练,训练结果存放在/tmp/model.txt中。
python3 train.py /tmp/feature_data /tmp/model.txt
- 特征抽取 SQL 脚本上线:将第 3 步中用于特征抽取的 SQL 脚本部署上线,以提供在线的特征抽取
- 使用 OpenMLDB 最新的一键部署工具(将在 OpenMLDB 0.6.8 版本中发布,详情请参考官方文档 https://openmldb.ai/docs/zh/main/ ),在阿里云的两台虚拟机上部署 OpenMLDB 集群版。需要提前下载好 OpenMLDB Spark。
./sbin/deploy-all.sh
- 部署完成后启动集群:
./sbin/start-all.sh
- 启动后,连接 OpenMLDB 集群检查集群状态:
./openmldb_cli.sh
show components
- 保证集群成功创建以后,可以创建表:
CREATE DATABASE demo_db;
USE demo_db;
CREATE TABLE t1(id string, vendor_id int, pickup_datetime timestamp, dropoff_datetime timestamp, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
SET @@execute_mode='online';
再使用 OpenMLDB SQL DEPLOY 语法,部署上线 SQL 脚本(可以执行SHOW DEPLOYMENT 语句查看部署详情):
DEPLOY demo SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
avg(pickup_latitude) OVER w AS vendor_avg_pl,
sum(pickup_latitude) OVER w2 AS pc_sum_pl,
max(pickup_latitude) OVER w2 AS pc_max_pl,
min(pickup_latitude) OVER w2 AS pc_min_pl,
avg(pickup_latitude) OVER w2 AS pc_avg_pl,
count(vendor_id) OVER w2 AS pc_cnt,
count(vendor_id) OVER w AS vendor_cnt
FROM t1
WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW),
w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW);
- 在线模型预测:基于 OpenMLDB 在线服务与机器学习模型实现 E2E 预测
- 准备在线数据。首先,切换到在线执行模式。接着在在线模式下,导入样例数据
/work/taxi-trip/data/taxi_tour_table_train_simple.csv作为在线数据,用于在线特征计算。以下命令均在 OpenMLDB CLI 下执行。
> USE demo_db;
> SET @@execute_mode='online';
> LOAD DATA INFILE 'file:///work/taxi-trip/data/taxi_tour_table_train_simple.csv' INTO TABLE t1 options(format='csv', header=true, mode='append');
- 启动预估服务。如果尚未退出 OpenMLDB CLI,请使用 quit 命令退出 OpenMLDB CLI。在普通命令行下启动预估服务:
./start_predict_server.sh 127.0.0.1:9080 /tmp/model.txt
- 发送预估请求。在普通命令行下执行内置的
predict.py脚本。该脚本发送一行请求数据到预估服务,接收返回的预估结果,并打印出来。
# Run inference with a HTTP requestpython3 predict.py
----------------ins---------------[[ 2. 40.774097 40.774097 40.774097 40.774097 40.774097 40.774097 40.774097 40.774097 1. 1. ]]---------------predict trip_duration -------------844.0261882914319 s
写在最后
希望本文能够帮大家快速了解如何使用 OpenMLDB 和 Maxcompute 联合实现一个完整的机器学习应用,跑通从数据导入到特征工程到机器学习模型训练、应用的全流程。
OpenMLDB的上下游生态在不断完善当中,后续也将整合更多生态工具,吸引更多开发者的同时降低开发者的使用门槛,敬请期待。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OkkgVGMM-1671011244563)(null)]
若你想进一步了解 OpenMLDB 或者参与社区技术交流,可以通过以下渠道获得相关信息和互动~
Github: https://github.com/4paradigm/OpenMLDB
官网:https://openmldb.ai
Email: contact@openmldb.ai
OpenMLDB 微信交流群:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xzfUb7Q0-1671011245353)(null)]



![[附源码]Python计算机毕业设计SSM基于java语言的在线电子书阅读系统(程序+LW)](https://img-blog.csdnimg.cn/73ace95176004ed3882abe699ae5af4b.png)