服务器开发系列
文章目录
- 服务器开发系列
- 前言
- 一、原因分析与定位?
- 总结
前言
什么是Load?什么是Load Average?
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing),简单的说是进程队列的长度。
一、原因分析与定位?
1、查看load方法
查看负载的方法
w or uptime or procinfo or top
查看cpu个数
cat /proc/cpuinfo
Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。
一般是会根据15分钟那个load 平均值为首先。

2、如何判断系统是否已经Over Load?
对一般的系统来说,根据cpu数量去判断。如果平均负载始终在1.2一下,而你有2颗cup的机器。那么基本不会出现cpu不够用的情况。也就是Load平均要小于Cpu的数量,当Load值大于cpu个数时,这时候服务已经开始变“慢”了
3、对与Load误解:
a、系统load高一定是性能有问题。
真相:Load高也许是因为在进行cpu密集型的计算
b、系统Load高一定是CPU能力问题或数量不够。
真相:Load高只是代表需要运行的队列累计过多了。但队列中的任务实际可能是耗Cpu的,也可能是耗i/o等其他因素的。
c、系统长期Load高,首先增加CPU
真相:Load只是表象,不是实质。增加CPU个别情况下会临时看到Load下降,但治标不治本。
4、在Load average 高的情况下如何鉴别系统瓶颈
一般由三个方面导致:1、CPU不足,2、IO不足 ,3、内存不足
常用的解决办法如下:
1、查看系统负载cpu、内存等资源占用信息
通过top命令查看load、wait等指标判断系统状态
top

load:对计算机干活多少的度量
us:用户态使用的cpu时间比
sy:系统态使用的cpu时间比
id:空闲的cpu时间比
wa:cpu等待磁盘写入完成时间
通过free命令查看系统可用内存,swap内存 ,buff/cache等
free -h

buffer/cache 其实是作为服务器系统的文件数据缓存使用的,尤其是针对进程对文件存在 read/write 操作的时候,所以当你的服务进程在对文件进行读写的时候,Linux内核为了提高服务的读写速度,则将会把文件放在此处的 buffer/cache 中进行缓存使用,由于 Linux服务的特点便是任何事物都会以文件的形式进行存在,所以你会发现不管你是否对文件做了大规模的读写,机器的 buffer/cache 是一直都存在的,并且持续的增高不下。
可以发现内存不够充足,可以手动清理内存
1)清理pagecache(页面缓存)
echo 1 > /proc/sys/vm/drop_caches
或
sysctl -w vm.drop_caches=1
2)清理dentries(目录缓存)和inodes
echo 2 > /proc/sys/vm/drop_caches
或
sysctl -w vm.drop_caches=2
3)清理pagecache、dentries和inodes
echo 3 > /proc/sys/vm/drop_caches
或
sysctl -w vm.drop_caches=3
2、查看系统负载vmstat
vmstat
重点关注bi/bo(磁盘与内存之间),si/so(交换分区与内存之间),swpd,free id参数。

procs
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比
system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量(swap)。
so 由内存交换区进入内存数量(swap)。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
补充知识交换分区swap:
物理内存就是系统硬件提供的内存大小,是真正的内存。相对于物理内存,在 Linux 下还有一个虚拟内存的概念,虚拟内存是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存。用作虚拟内存的磁盘空间被称为交换空间(又称 swap 空间)。
作为物理内存的扩展,Linux 会在物理内存不足时,使用交换分区的虚拟内存,更详细地说,就是内核会将暂时不用的内存块信息写到交换空间,这样一来,物理内存得到了释放,这块内存就可以用于其他目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
Linux 的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
3、查看磁盘负载iostat
iostat -x 1 10
可以通过 iostat 命令还查看磁盘性能。其中的 svctm 一项,反应了磁盘的负载情况,如果该项大于 15ms,并且 util% 接近 100%,那就说明,磁盘现在是整个系统性能的瓶颈了。
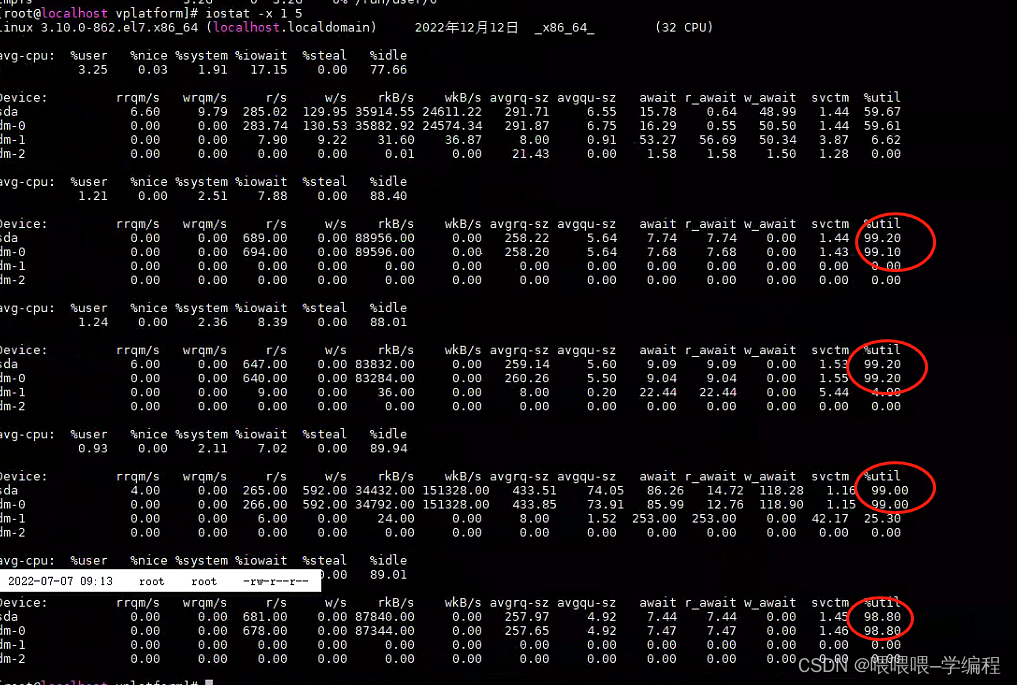
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。idle小于70%,IO压力就较大了,一般读取速度有较多的wait.
可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
await: await的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O队列太长,应用得到的响应时间变慢,
4、查看各核 CPU使用情况
mpstat是一种实时系统监控工具。mpstat命令会输出CPU的一些统计信息 这些信息存放在/proc/stat文件中。
mpstat能查看所有CPU的平均信息,还能查看指定CPU的信息
mpstat -P ALL 1 3
-P ALL表示所有CPU
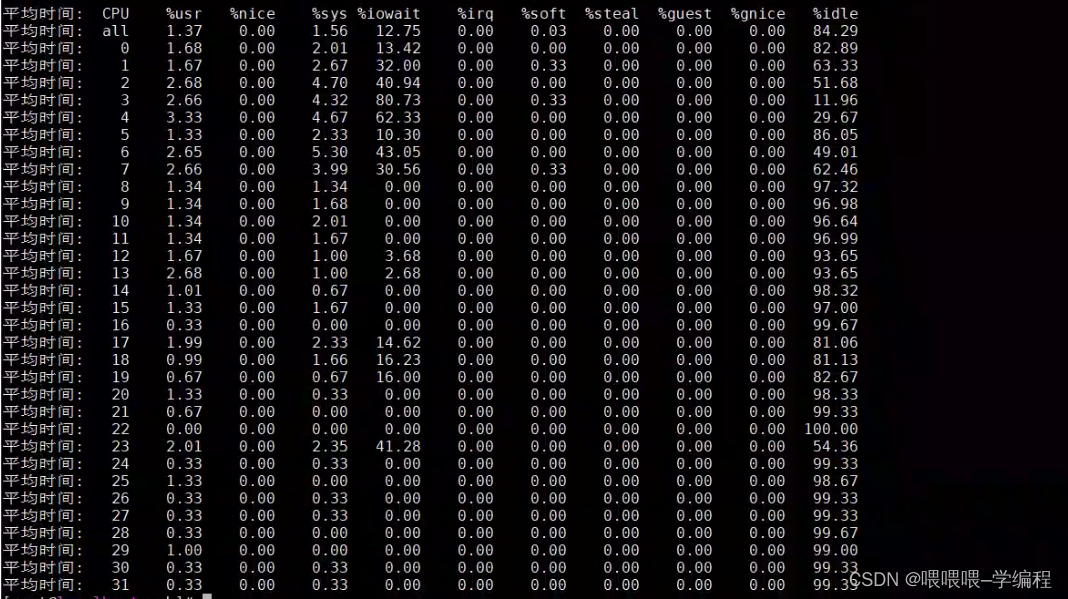
%usr: 用户进程消耗的CPU时间百分比。
%nice: 改变过优先级的进程占用的CPU时间百分比。
%sys: 系统(内核)进程消耗的CPU时间百分比。
%iowait: I0等待所占用的CPU时间百分比。
%irq: 硬中断占用的CPU时间百分比。
%soft: 软中断占用的CPU时间百分比。
%steal: 虚拟机强制CPU等待的时间百分比。
%guest: 虚拟机占用CPU时间的百分比。
%idle: CPU处在空闲状态的时间百分比。
总结
到这里有关于查看CPU性能参数(mpstat, iostat, sar、vmstat)等命令就演示完毕了!!
希望对你有所帮助