l 采集网站
【场景描述】采集中国国际招标网招标数据。
【源网站介绍】中国国际招标网致力于为企业提供招标、采购、拟在建项目信息及网上招标采购等一系列商务服务。
【使用工具】前嗅ForeSpider数据采集系统
http://www.forenose.com/view/forespider/view/download.html
【入口网址】
http://chinabidding.mofcom.gov.cn/channel/business/bulletinList.shtml?s=
【采集内容】
采集字段:公告名、发布时间、正文内容、链接、公告类型、所属地区。
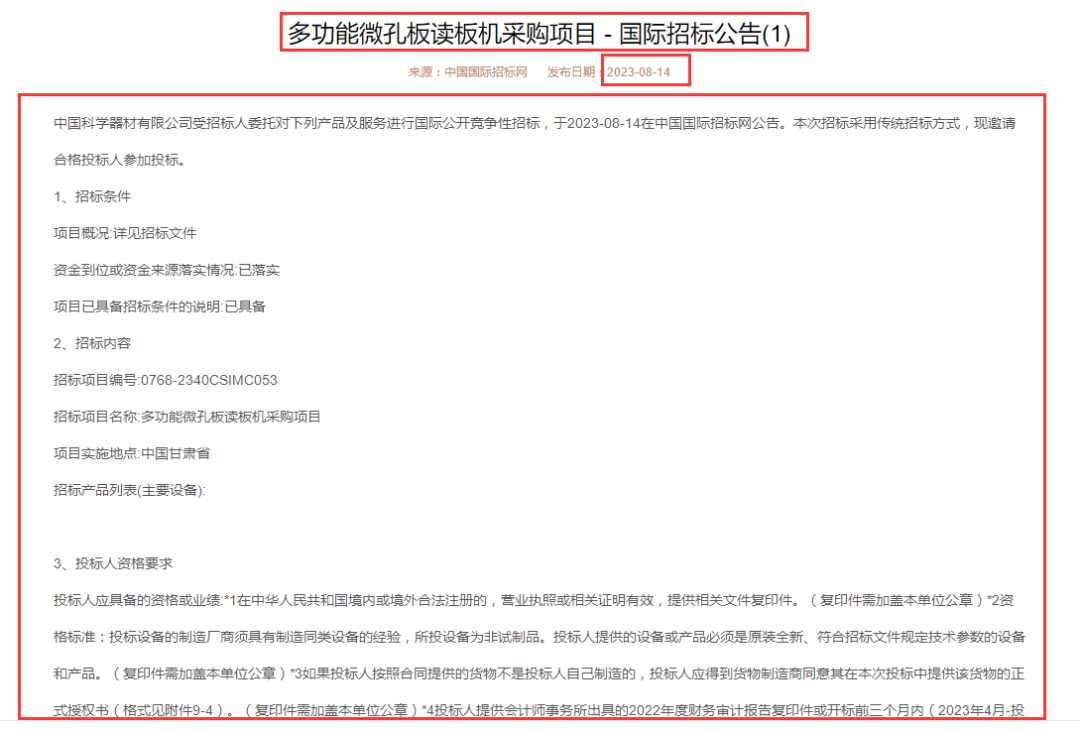
【采集效果】
如下图所示:

l 思路分析
配置思路概览:

l 配置步骤
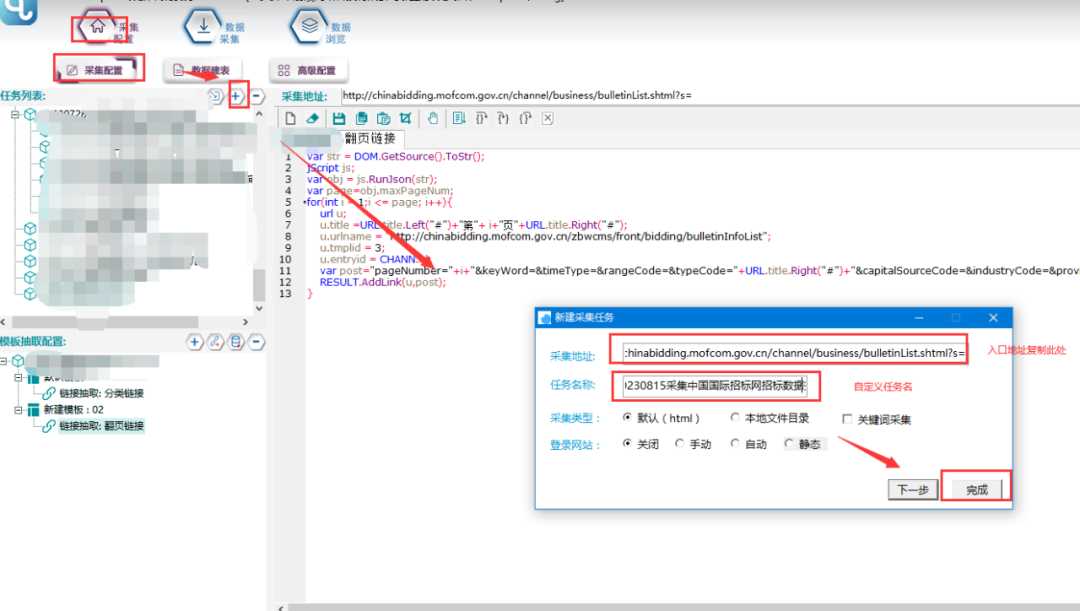
1.新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
2.获取分类链接
在浏览器中打开中国国际招标网,我们要采集所有招标公告、招标变更公告、评价结果公示和中标结果公告中的公告内容,所以第一步是获取以上分类的请求链接。
在浏览器中,分别搜索各类公告,发现页面链接没有变化,说明对应的数据在请求链接中。点击F12,打开开发者工具,选择Network,然后搜索任何一个分类比如“招标变更公告”,开发者工具中,出现该分类对应请求,如图所示:
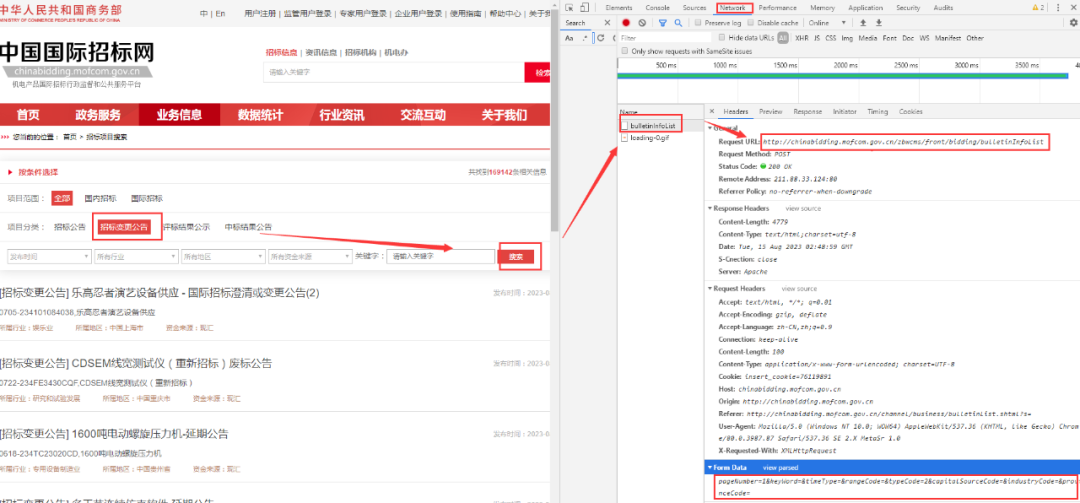
观察发现该请求是一个post请求,其通过post Form Data来传递信息。
该请求的链接为:http://chinabidding.mofcom.gov.cn/zbwcms/front/bidding/bulletinInfoList
该请求的Form Data为:pageNumber=1&keyWord=&timeType=&rangeCode=&typeCode=2&capitalSourceCode=&industryCode=&provinceCode=
同样的方法,观察其他分类对应的请求,发现“招标公告”请求链接为:http://chinabidding.mofcom.gov.cn/zbwcms/front/bidding/bulletinInfoList
该请求的Form Data为:
pageNumber=1&keyWord=&timeType=&rangeCode=&typeCode=1&capitalSourceCode=&industryCode=&provinceCode=
Post请求链接是不变的,其Form Data中的typeCode参数是变化的,观察发现各分类对应typeCode如下所示:
招标公告-1 招标变更公告-2 评标结果公告-3 中标结果公告-4
根据以上规律,在ForeSpider中用脚本拼写请求,具体如下所示:
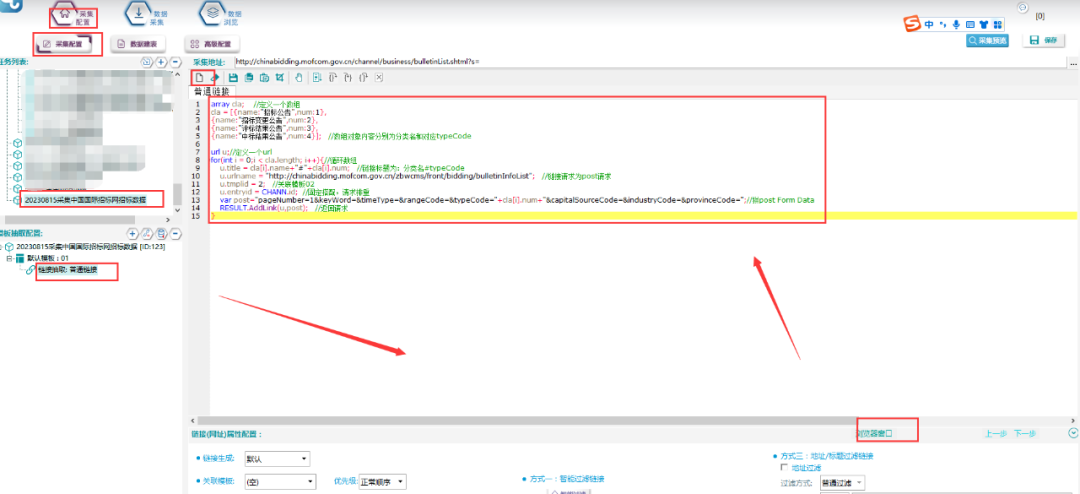
脚本文本如下所示:
array cla; //定义一个数组
cla = [{name:"招标公告",num:1},
{name:"招标变更公告",num:2},
{name:"评标结果公告",num:3},
{name:"中标结果公告",num:4}]; //数组对象内容分别为分类名和对应typeCode
url u;//定义一个url
for(int i = 0;i < cla.length; i++){//循环数组
u.title = cla[i].name+"#"+cla[i].num; //链接标题为:分类名#typeCode
u.urlname = "http://chinabidding.mofcom.gov.cn/zbwcms/front/bidding/bulletinInfoList"; //链接请求为post请求
u.tmplid = 2; //关联模板02
u.entryid = CHANN.id; //固定搭配,请求排重
var post="pageNumber=1&keyWord=&timeType=&rangeCode=&typeCode="+cla[i].num+"&capitalSourceCode=&industryCode=&provinceCode=";//拼post Form Data
RESULT.AddLink(u,post); //返回请求
} 3.获取翻页链接
用同样的方法观察不同分类招标公告在不同页面上的请求,发现其post请求链接没变,不同分类不同翻页的请求与其Form Data中的pageNumber参数、typeCode参数有关。
例如:pageNumber=2&keyWord=&timeType=&rangeCode=&typeCode=1&capitalSourceCode=&industryCode=&provinceCode= ,返回的是招标公告第二页的数据内容。
根据以上规律,在ForeSpider中新建模板02链接抽取模板,用脚本拼写请求,具体如下所示:
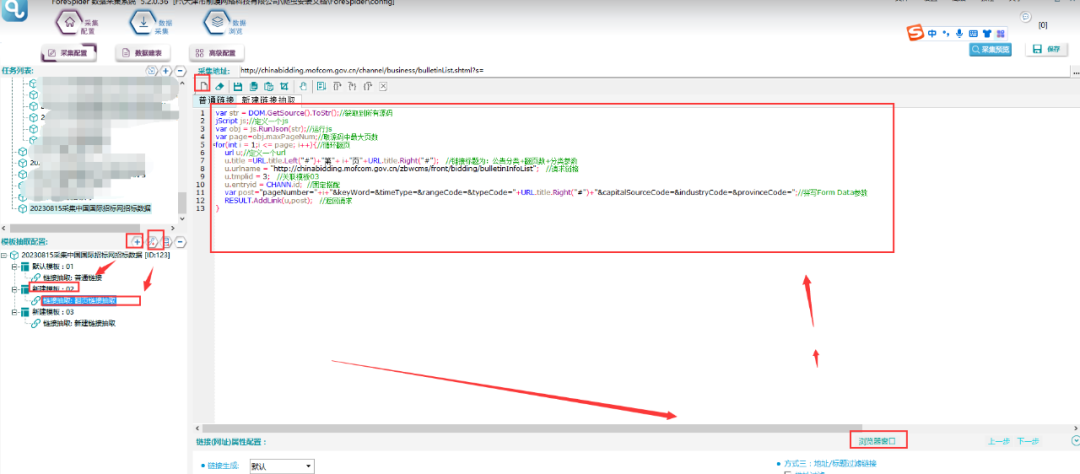
脚本文本如下所示:
var str = DOM.GetSource().ToStr();//获取到所有源码
jScript js;//定义一个js
var obj = js.RunJson(str);//运行js
var page=obj.maxPageNum;//取源码中最大页数
for(int i = 1;i <= 3; i++){//循环翻页
url u;//定义一个url
u.title =URL.title.Left("#")+"第"+ i+"页"+URL.title.Right("#"); //链接标题为:公告分类+翻页数+分类参数
u.urlname = "http://chinabidding.mofcom.gov.cn/zbwcms/front/bidding/bulletinInfoList"; //请求链接
u.tmplid = 3; //关联模板03
u.entryid = CHANN.id; //固定搭配
var post="pageNumber="+i+"&keyWord=&timeType=&rangeCode=&typeCode="+URL.title.Right("#")+"&capitalSourceCode=&industryCode=&provinceCode=";//拼写Form Data参数
RESULT.AddLink(u,post); //返回请求
} 采集预览观察生成的链接,是否与网页中对应的翻页链接和Form Data一致,如果一致则继续配置下一步。
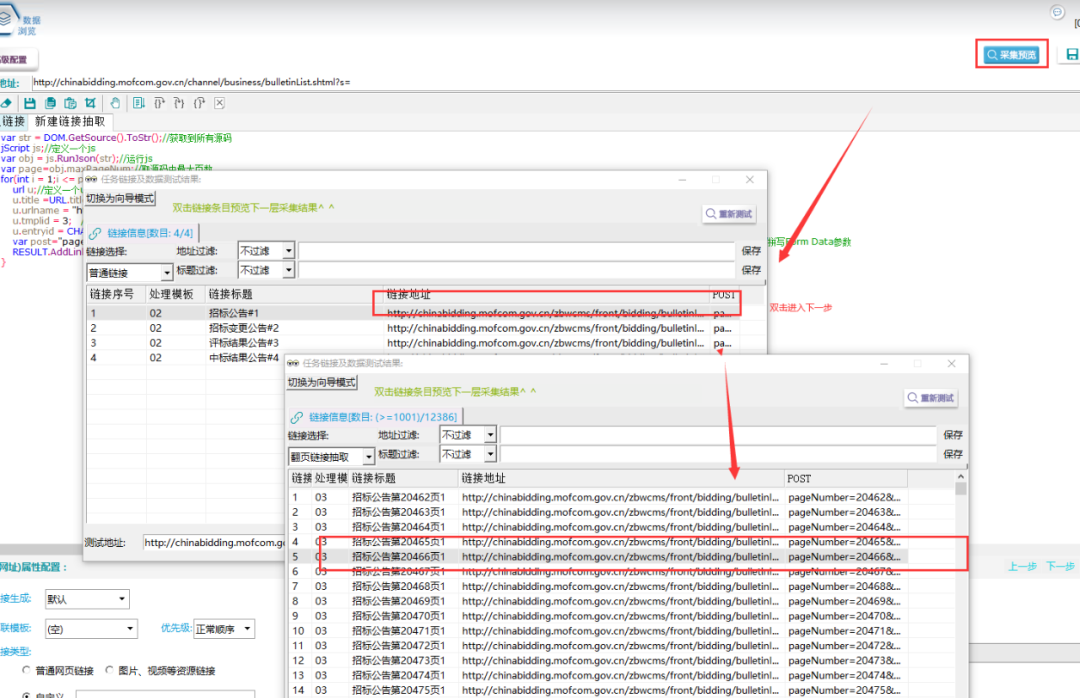
4.获取招投标公告列表链接
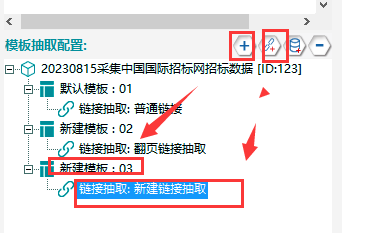
①新建模板03,在其下新建一个链接抽取模板,具体操作如下所示:
②在浏览器上观察翻页请求链接返回的源码中的公告数据内容,如下所示:
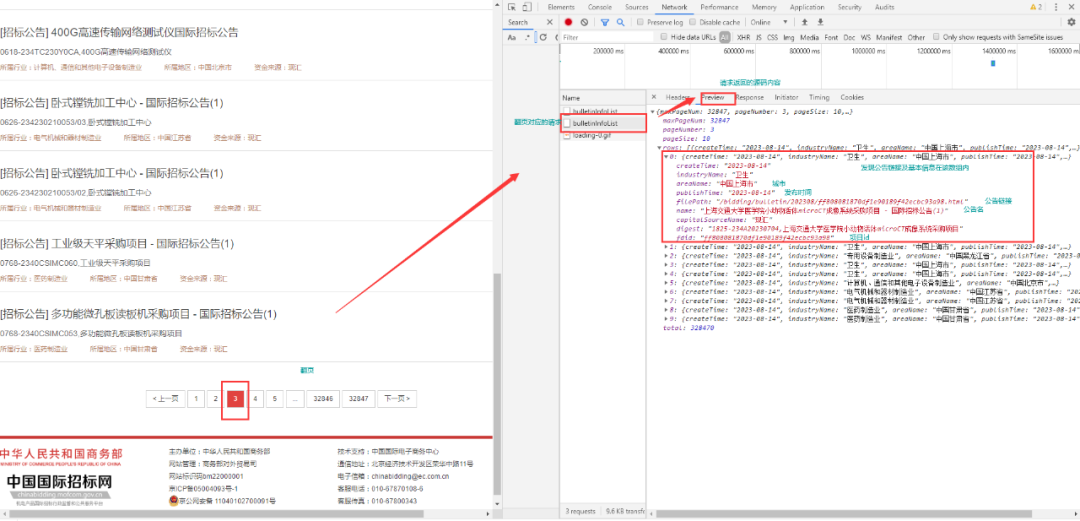
根据数据结构,在ForeSpider中,用脚本抽取列表链接数据,具体如下所示:
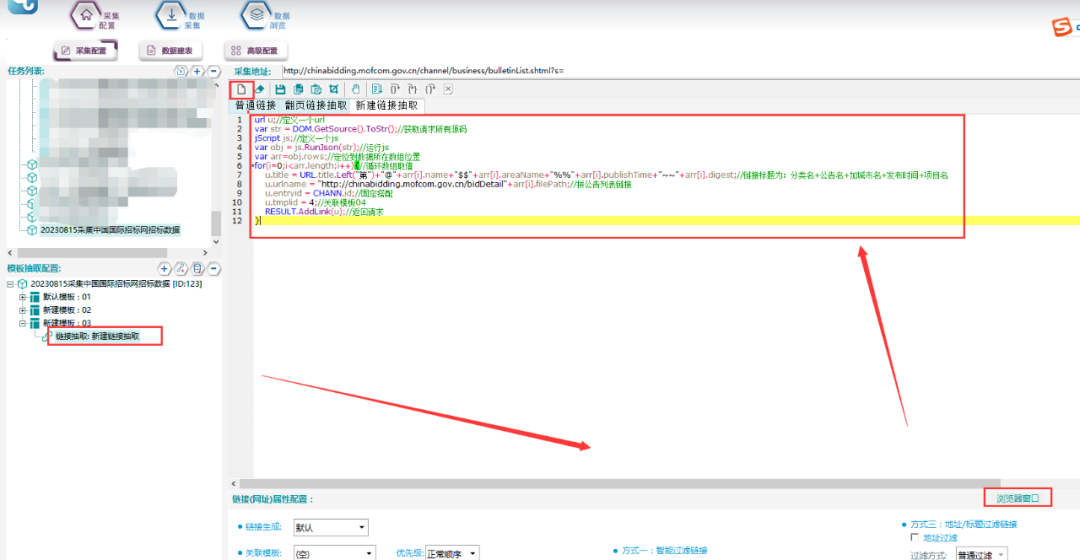
脚本文本如下所示:
var str = DOM.GetSource().ToStr();//获取到所有源码
jScript js;//定义一个js
var obj = js.RunJson(str);//运行js
var page=obj.maxPageNum;//取源码中最大页数
for(int i = 1;i <= 3; i++){//循环翻页
url u;//定义一个url
u.title =URL.title.Left("#")+"第"+ i+"页"+URL.title.Right("#"); //链接标题为:公告分类+翻页数+分类参数
u.urlname = "http://chinabidding.mofcom.gov.cn/zbwcms/front/bidding/bulletinInfoList"; //请求链接
u.tmplid = 4; //关联模板03
u.entryid = CHANN.id; //固定搭配
var post="pageNumber="+i+"&keyWord=&timeType=&rangeCode=&typeCode="+URL.title.Right("#")+"&capitalSourceCode=&industryCode=&provinceCode=";//拼写Form Data参数
RESULT.AddLink(u,post); //返回请求
} 5.抽取招投标公告数据
①新建模板04,在其下新建一个数据抽取模板,用来抽取招投标公告数据。
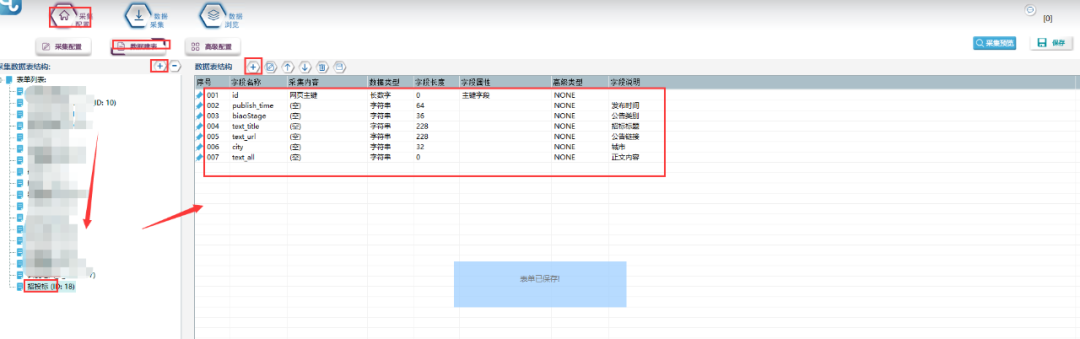
②在数据建表模块,新建一个数据表,字段如下所示:
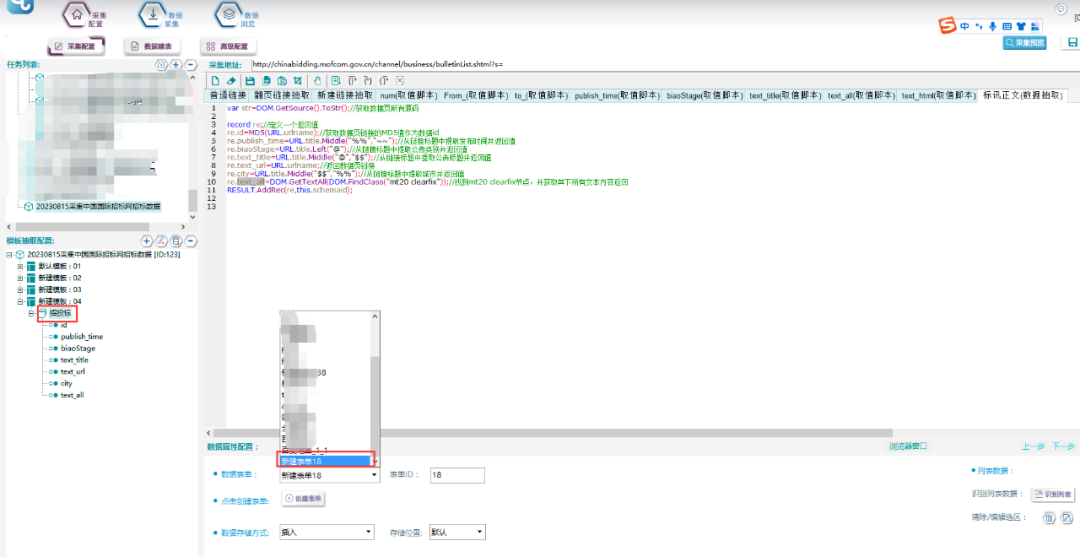
③关联数据表
在数据抽取处关联新建的数据表。
④字段publish_time、biaoStage、text_title、text_url、city在上一层均已获取到并通过链接标题传递到本层,所以可直接使用脚本从链接标题中获取。
字段text_all需在数据页源码中获取,在浏览器中打开任意一个公告数据页,点击F12,查找到正文数据在源码中对应的位置,如下图所示:
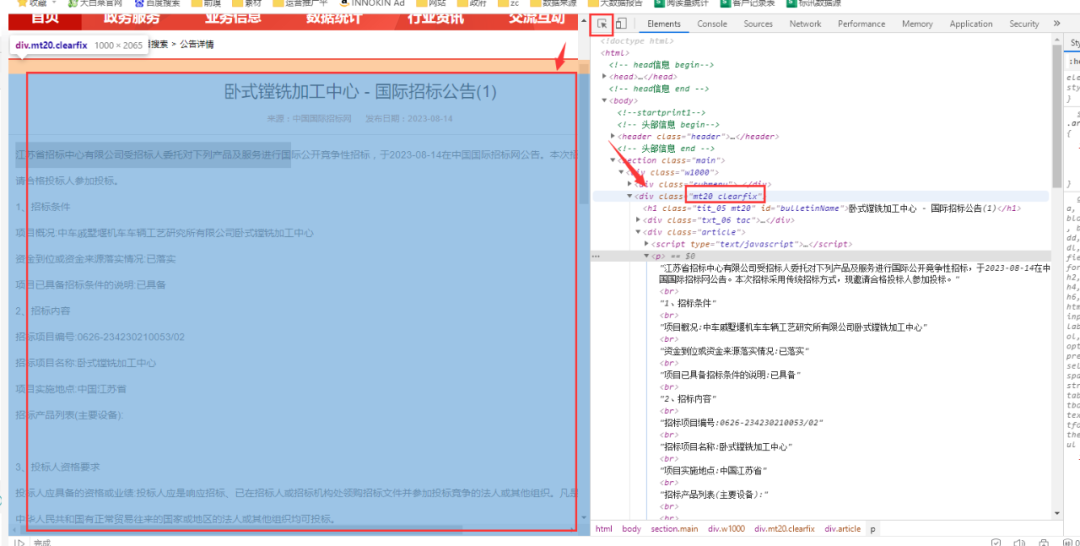
我们发现正文内容在class为mt20 clearfix的节点下,所以用脚本取该节点文本即可。数据抽取脚本如下所示:
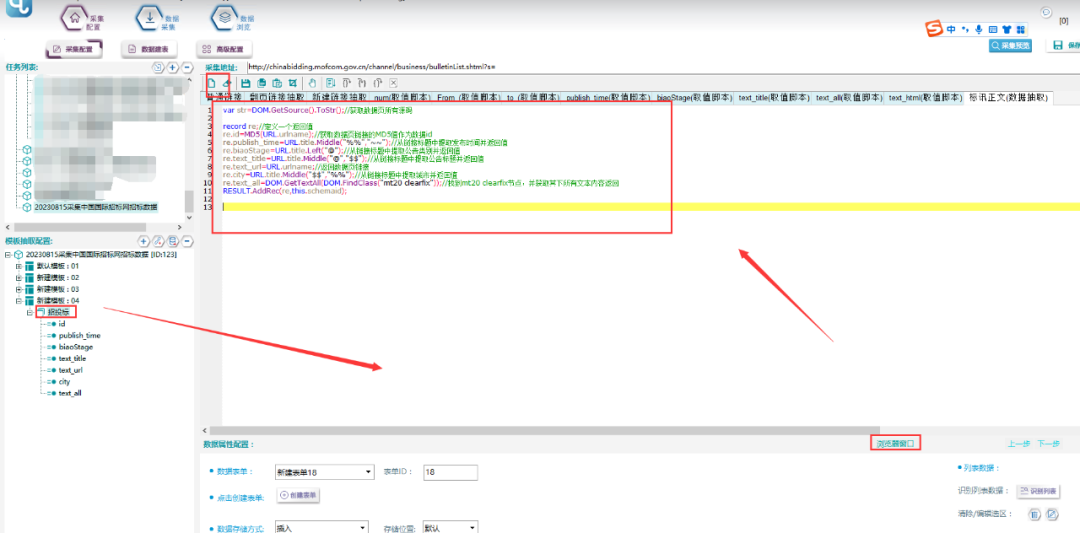
脚本文本如下所示:
var str=DOM.GetSource().ToStr();//获取数据页所有源码
record re;//定义一个返回值
re.id=MD5(URL.urlname);//获取数据页链接的MD5值作为数据id
re.publish_time=URL.title.Middle("%%","~~");//从链接标题中提取发布时间并返回值
re.biaoStage=URL.title.Left("@");//从链接标题中提取公告类别并返回值
re.text_title=URL.title.Middle("@","$$");//从链接标题中提取公告标题并返回值
re.text_url=URL.urlname;//返回数据页链接
re.city=URL.title.Middle("$$","%%");//从链接标题中提取城市并返回值
re.text_all=DOM.GetTextAll(DOM.FindClass("mt20 clearfix"));//找到mt20 clearfix节点,并获取其下所有文本内容返回
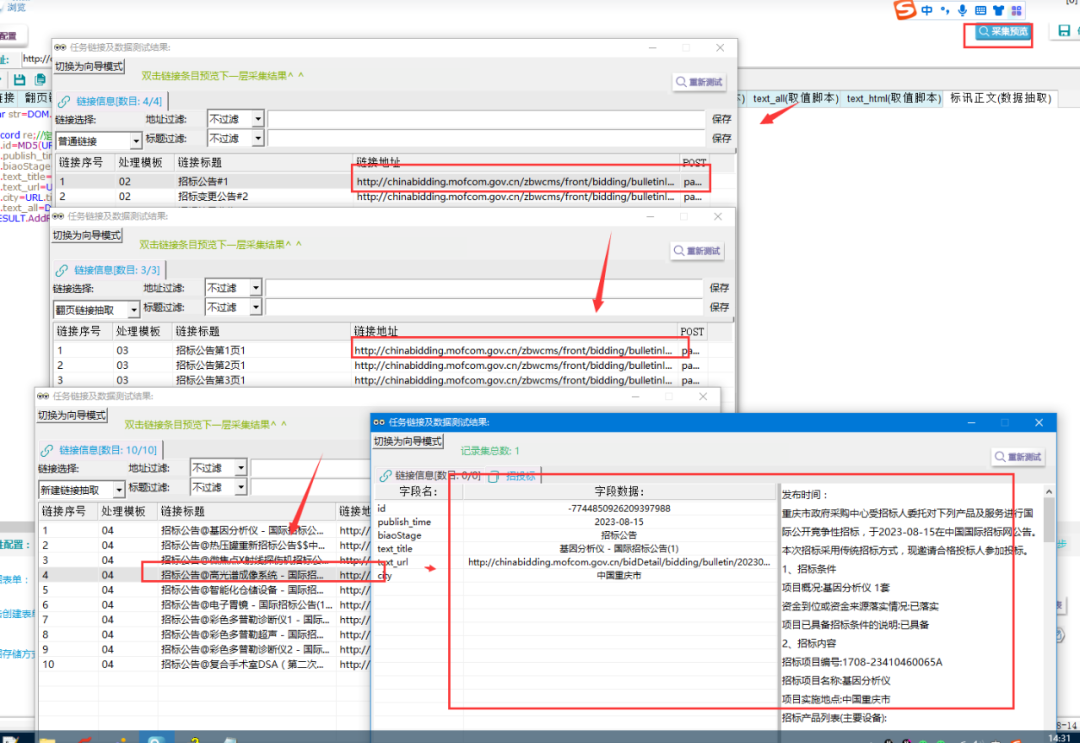
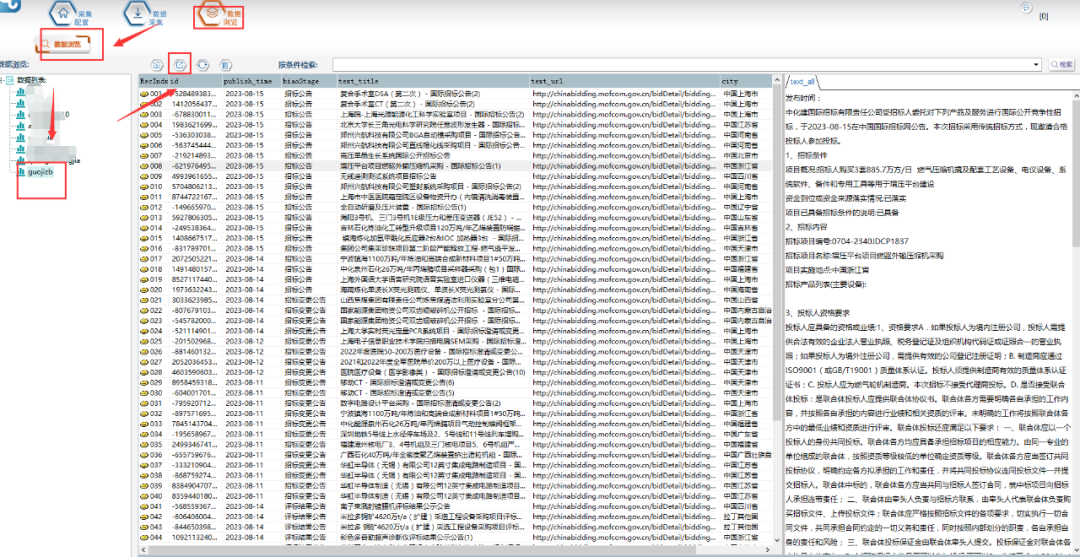
RESULT.AddRec(re,this.schemaid);⑤采集预览,如下图所示,各类招标数据已被采集出来了,说明模板配置完成。
|采集步骤
模板配置完,采集预览没有问题,可以进行数据采集。
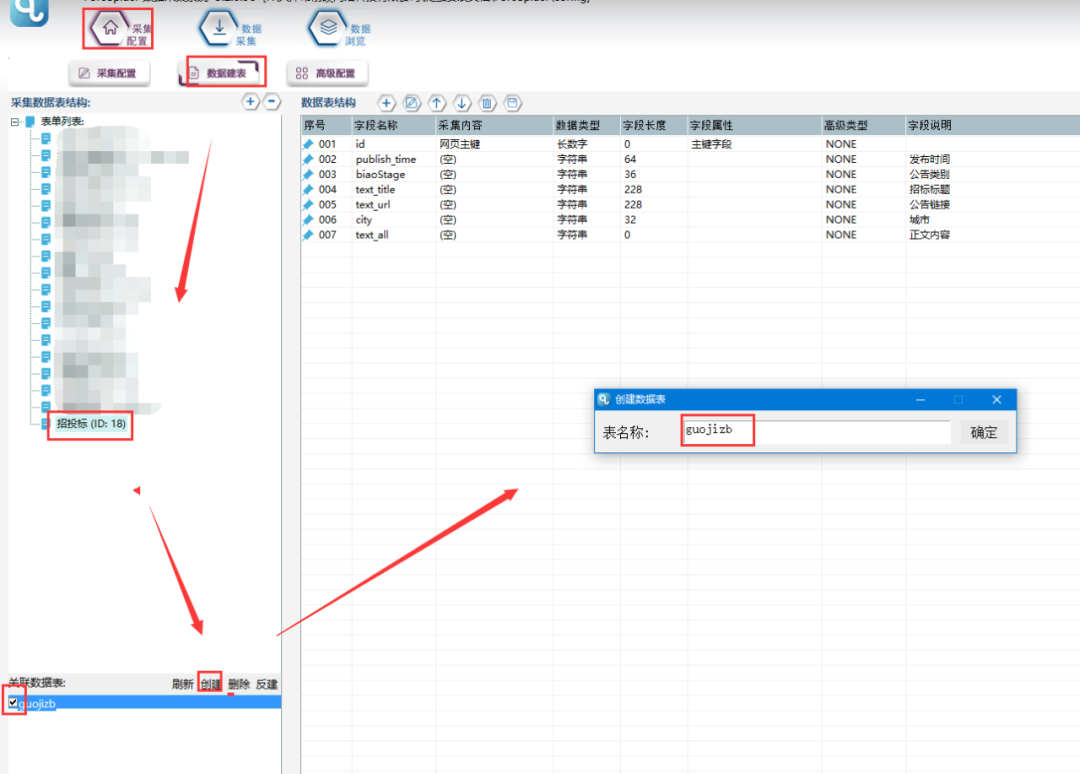
1.建立数据表单
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【guojizb】(注意命名不能用数字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。
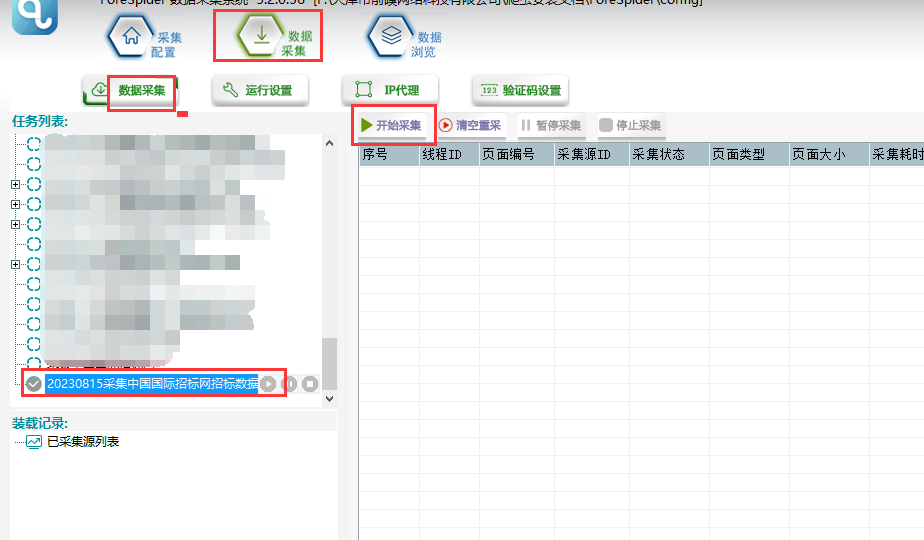
2.开始采集
选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
3.导出数据
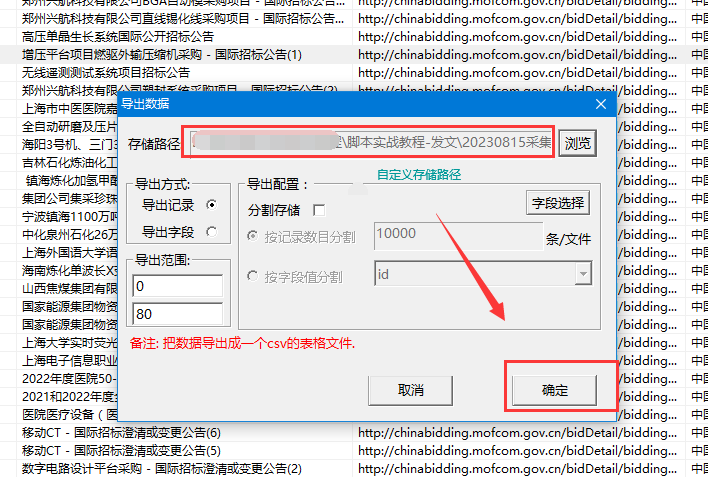
采集结束后,可以在【数据浏览】中,选择数据表查看采集数据,并导出数据。
4.导出的文件
本教程仅供教学使用,严禁用于商业用途!