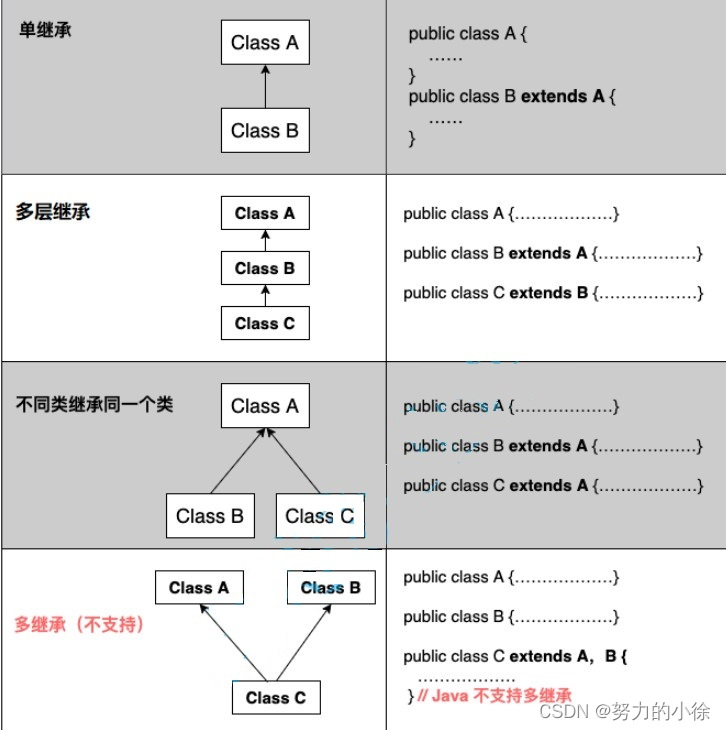
一、说明
变形金刚完全重建了自然语言处理(NLP)的格局。在变形金刚出现之前,由于循环神经网络(RNN),我们的翻译和语言分类很好——它们的语言理解能力有限,导致许多小错误,而且在大块文本上的连贯性几乎是不可能的。
自从在2017年的论文“注意力就是你所需要的一切”[1]中引入第一个转换器模型以来,NLP已经从RNN转向BERT和GPT等模型。这些新模型可以回答问题,写文章(也许是GPT-3写的),实现令人难以置信的直观语义搜索 - 等等。
有趣的是,对于许多任务,这些模型的后半部分与RNN中的相同 - 通常是输出模型预测的前馈神经网络。
这些层的输入发生了变化。变压器模型创建的密集嵌入的信息非常丰富,尽管使用相同的最终外层,我们仍获得了巨大的性能优势。
这些日益丰富的句子嵌入可用于快速比较各种用例的句子相似性。如:
在本文中,我们将探讨这些嵌入如何通过使用称为“句子转换器”的新型转换器来适应并应用于一系列语义相似性应用程序。
二、一些“背景知识”
在我们深入研究句子转换器之前,我们不妨先拼凑出为什么转换器嵌入如此丰富——以及普通转换器和句子转换器之间的区别在哪里。
变压器是先前RNN模型的间接后代。这些旧的循环模型通常由许多循环单元(如 LSTM 或 GRU)构建而成。
在机器翻译中,我们会找到编码器-解码器网络。第一个模型用于将原始语言编码为上下文向量,第二个模型用于将其解码为目标语言。
编码器-解码器架构,两个模型之间共享单个上下文向量,这充当了信息瓶颈,因为所有信息都必须通过这一点。

编码器-解码器架构,两个模型之间共享单个上下文向量,这充当了信息瓶颈,因为所有信息都必须通过这一点。
这里的问题是我们在两个模型之间造成了信息瓶颈。我们正在多个时间步长中创建大量信息,并试图通过单个连接来压缩所有信息。这限制了编码器-解码器的性能,因为编码器产生的大部分信息在到达解码器之前都会丢失。
注意力机制为瓶颈问题提供了解决方案。它为信息传递提供了另一条路线。尽管如此,它并没有压倒这个过程,因为它只将注意力集中在最相关的信息上。
通过将每个时间步的上下文向量传递到注意力机制(生成注释向量)中,可以消除信息瓶颈,并且可以在较长的序列中更好地保留信息。
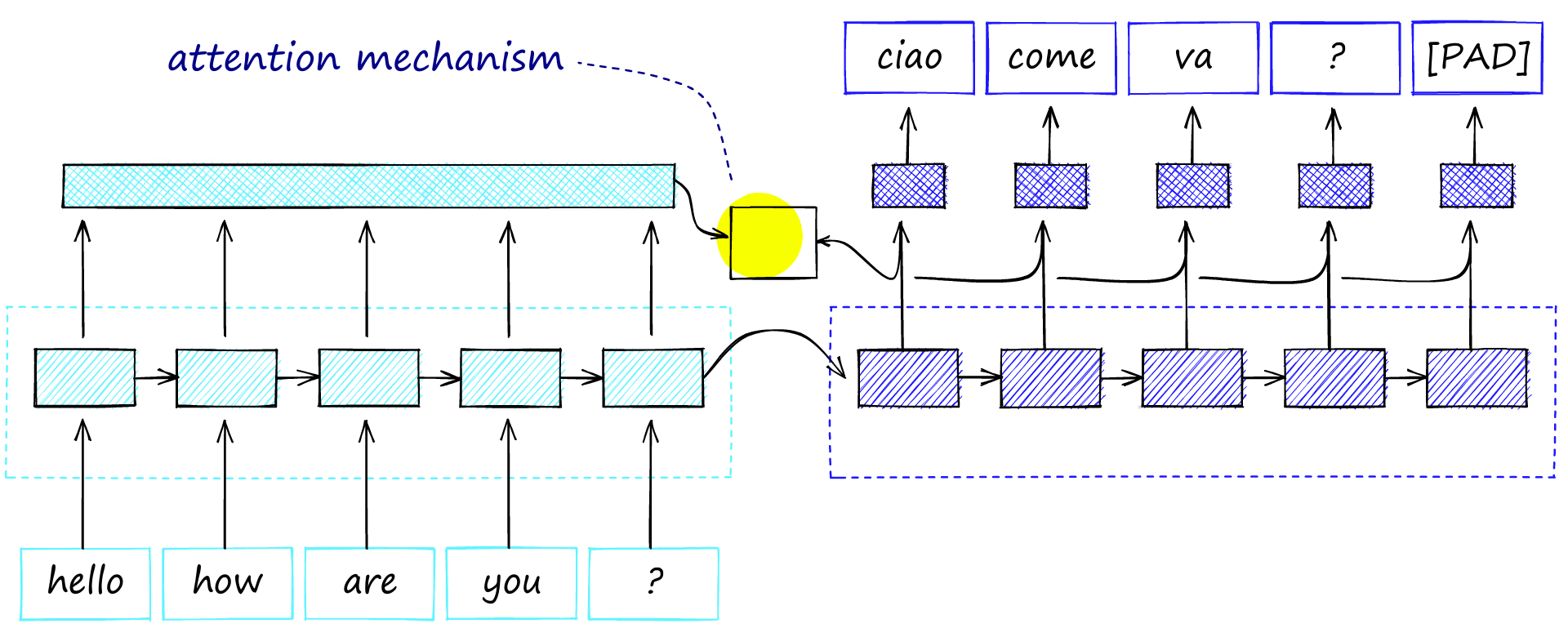
具有注意力机制的编码器-解码器。注意机制考虑了解码器中的所有编码器输出激活和每个时间步的激活,从而修改了解码器输出。
在解码过程中,模型一次解码一个单词/时间步长。为每个步骤计算单词和所有编码器注释之间的对齐方式(例如,相似性)。
更高的对齐度导致解码器步骤输出上的编码器注释权重更大。意思是机制计算出要注意哪些编码器词。
![英语-法语编码器和解码器之间的注意,来源 [2]。](https://img-blog.csdnimg.cn/img_convert/eb8e73d2d74d5aca658de30148d0c2dd.png)
英语-法语编码器和解码器之间的注意,来源 [2]。
性能最好的RNN编码器-解码器都使用了这种注意力机制。
三、注意力就是你所需要的一切
2017年,发表了一篇题为《注意力就是你需要的一切》的论文。这标志着NLP的一个转折点。作者证明,我们可以删除RNN网络,并仅使用注意力机制获得卓越的性能 - 只需进行一些更改。
这种基于注意力的新模型被命名为“变压器”。从那时起,NLP生态系统已经完全从RNN转变为转换器,这要归功于它们非常优越的性能和令人难以置信的泛化能力。
第一个转换器通过使用三个关键组件消除了对 RNN 的需求:
-
-
语义文本相似性 (STS) — 句子对的比较。我们可能想要识别数据集中的模式,但这最常用于基准测试。
-
语义搜索 — 使用语义含义的信息检索 (IR)。给定一组句子,我们可以使用“查询”句子进行搜索并识别最相似的记录。允许对概念(而不是特定单词)执行搜索。
-
聚类 — 我们可以对句子进行聚类,这对于主题建模很有用。
位置编码取代了 NLP 中 RNN 的关键优势——考虑序列顺序的能力(它们是循环的)。它的工作原理是根据位置向每个输入嵌入添加一组不同的正弦波激活。
自我注意是指注意力机制应用于一个单词和其自身上下文(句子/段落)中的所有其他单词之间。这与普通注意力不同,普通注意力专门关注编码器和解码器之间的注意力。
多头注意力可以看作是几个平行的注意力机制一起工作。使用多个注意头可以表示几组关系(而不是一组)。
四、预训练模型
新的转换器模型比以前的RNN通用得多,以前的RNN通常是专门为每个用例构建的。
对于转换器模型,可以使用模型的相同“内核”,并简单地将最后几层交换为不同的用例(无需重新训练内核)。
这一新特性导致了NLP预训练模型的兴起。预训练的转换器模型在大量训练数据上进行训练——通常由谷歌或OpenAI等公司以高昂的成本进行训练,然后发布给公众免费使用。
这些预训练模型中使用最广泛的模型之一是BERT,或来自GoogleAI的T ransformers的Bidirectional Encoder R表示。
BERT催生了一大堆进一步的模型和推导,如distilBERT,RoBERTa和ALBERT,涵盖了分类,Q&A,POS标记等任务。
五、句子相似性的BERT
到目前为止,一切顺利,但是这些转换器模型在构建句子向量时存在一个问题:转换器使用单词或令牌级嵌入,而不是句子级嵌入。
在句子转换器之前,使用BERT计算准确句子相似性的方法是使用交叉编码器结构。这意味着我们将两个句子传递给BERT,在BERT的顶部添加一个分类头 - 并使用它来输出相似性分数。
BERT交叉编码器架构由使用句子A和B的BERT模型组成。两者以相同的顺序处理,由 [SEP] 令牌分隔。所有这些都后跟一个前馈 NN 分类器,该分类器输出相似性分数。
![BERT交叉编码器架构由使用句子A和B的BERT模型组成。两者以相同的顺序处理,由 [SEP] 令牌分隔。所有这些都后跟一个前馈 NN 分类器,该分类器输出相似性分数。](https://img-blog.csdnimg.cn/img_convert/d47e79c48b3413d277aba60f48eeec67.png)
BERT交叉编码器架构由使用句子A和B的BERT模型组成。两者以相同的顺序处理,由 [SEP] 令牌分隔。所有这些都后跟一个前馈 NN 分类器,该分类器输出相似性分数。
交叉编码器网络确实会产生非常准确的相似性分数(优于 SBERT),但它不可扩展。如果我们想通过一个 100K 的小型句子数据集执行相似性搜索,我们需要完成 100K 次交叉编码器推理计算。
为了对句子进行聚类,我们需要比较100K数据集中的所有句子,从而产生不到500M的比较 - 这根本不现实。
理想情况下,我们需要预先计算可以存储的句子向量,然后在需要时使用。如果这些向量表示是好的,我们需要做的就是计算每个向量之间的余弦相似性。
使用原始 BERT(和其他转换器),我们可以通过平均 BERT 输出的所有标记嵌入的值来构建句子嵌入(如果我们输入 512 个标记,则输出 512 个嵌入)。或者,我们可以使用第一个 [CLS] 令牌(特定于 BERT 的令牌,其输出嵌入用于分类任务)的输出。
使用这两种方法之一为我们提供了可以更快地存储和比较的句子嵌入,将搜索时间从 65 小时缩短到大约 5 秒(见下文)。但是,准确性并不好,并且比使用平均GloVe嵌入(2014年开发)更差。
Nils Reimers 和 Iryna Gurevych 在 2019 年设计了这种缺乏具有合理延迟的准确模型的解决方案,引入了句子 BERT (SBERT) 和句子转换器库。
对于所有常见的语义文本相似性(STS)任务,SBERT的性能优于以前的最先进的(SOTA)模型 - 稍后会详细介绍这些任务 - 除了单个数据集(SICK-R)。
值得庆幸的是,为了可扩展性,SBERT 生成句子嵌入 - 因此我们不需要为每个句子对比较执行完整的推理计算。
Reimers和Gurevych展示了2019年的速度大幅增长。使用 BERT 从 10K 个句子中找到最相似的句子对需要 65 个小时。使用 SBERT,嵌入在 ~5 秒内创建,与余弦相似性在 ~0.01 秒内进行比较。
自 SBERT 论文以来,已经使用类似的概念构建了更多的句子转换器模型,这些概念用于训练原始 SBERT。他们都接受过许多相似和不同的句子对的训练。
使用损失函数(如 softmax 损失、多重负排名损失或 MSE 保证金损失),这些模型经过优化,可为相似句子生成相似的嵌入,否则产生不同的嵌入。
现在,您已经了解了句子转换器背后的一些上下文,它们来自何处,以及为什么需要它们。让我们深入了解它们是如何工作的。
[3] SBERT论文涵盖了本节中的许多陈述,技术和数字。
六、句子转换器
我们解释了与BERT句子相似性的交叉编码器架构。SBERT类似,但放弃了最终的分类头,一次处理一个句子。然后,SBERT在最终输出层上使用平均池化来生成句子嵌入。
与BERT不同,SBERT使用暹罗架构对句子对进行微调。我们可以将其视为具有两个并行的相同BERT,它们共享完全相同的网络权重。
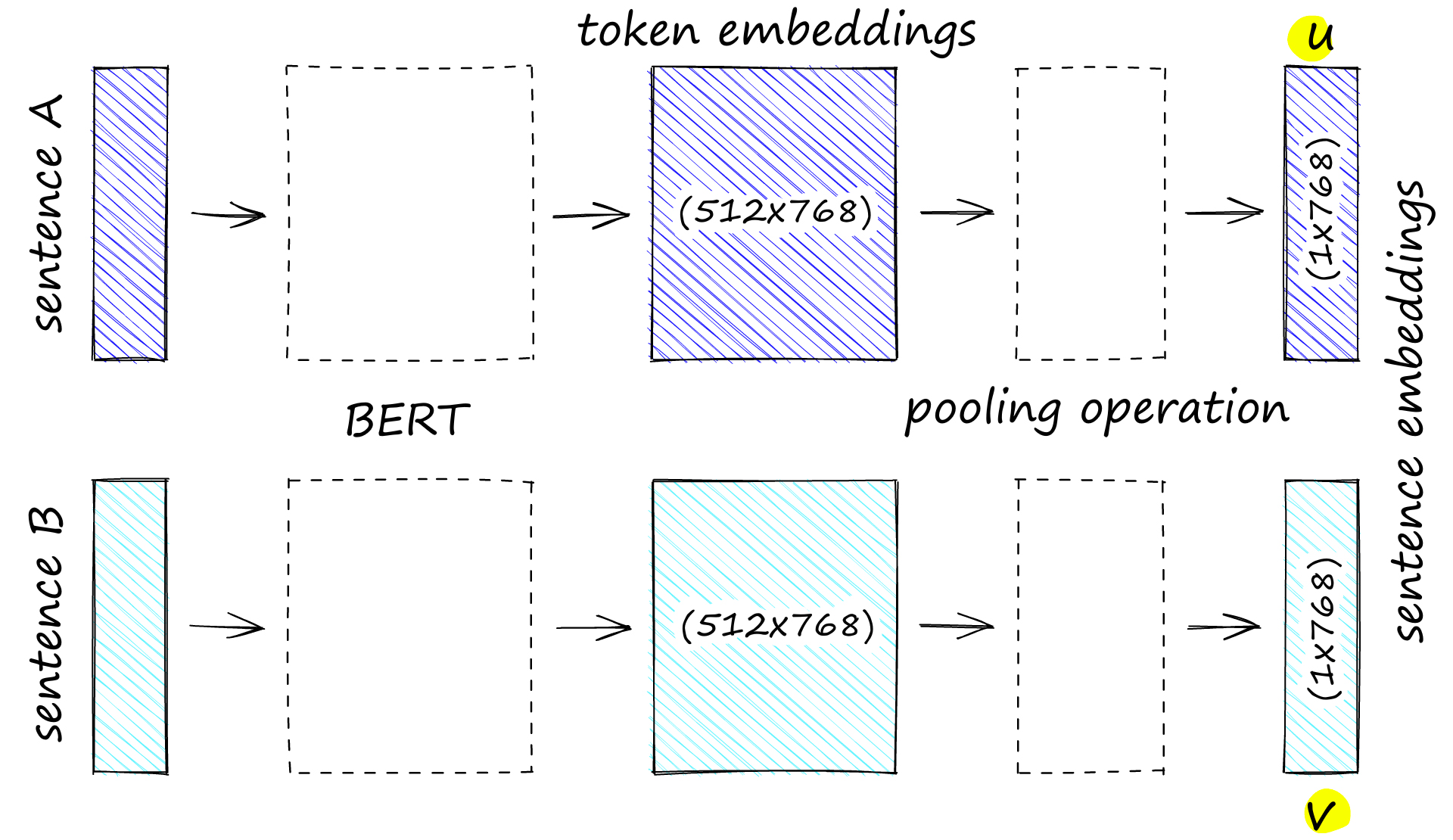
应用于句子对句子 A 和句子 B 的 SBERT 模型。请注意,BERT 模型输出令牌嵌入(由 512 768 维向量组成)。然后,我们使用池化函数将该数据压缩到单个 768 维句子向量中。
实际上,我们使用的是单个BERT模型。但是,由于我们在训练期间成对处理句子 A,然后是句子 B,因此更容易将其视为两个权重相同的模型。
七、暹罗伯特预培训
训练句子转换器有不同的方法。我们将描述原始 SBERT 中最突出的原始过程,该过程优化了软最大损耗。请注意,这是一个高级说明,我们将在另一篇文章中保存深入演练。
softmax-loss 方法使用了在斯坦福自然语言推理 (SNLI) 和多流派 NLI (MNLI) 语料库上微调的“暹罗”架构。
SNLI 包含 570K 个句子对,MNLI 包含 430K。两个语料库中的对都包括一个前提和一个假设。每对分配有以下三个标签之一:
-
-
位置编码
-
自我关注
-
多头注意力
鉴于这些数据,我们将句子A(假设前提)输入到暹罗BERT A中,句子B(假设)输入到暹罗BERT B中。
暹罗 BERT 输出我们的合并句子嵌入。SBERT论文中有三种不同合并方法的结果。这些是平均值、最大值和 [CLS] 池化。平均池方法在NLI和STSb数据集中表现最佳。
现在有两个句子嵌入。我们将嵌入称为 A u,将嵌入称为 B v。下一步是连接 u 和 v。同样,测试了几种串联方法,但性能最高的是(u,v,|u-v|)操作:
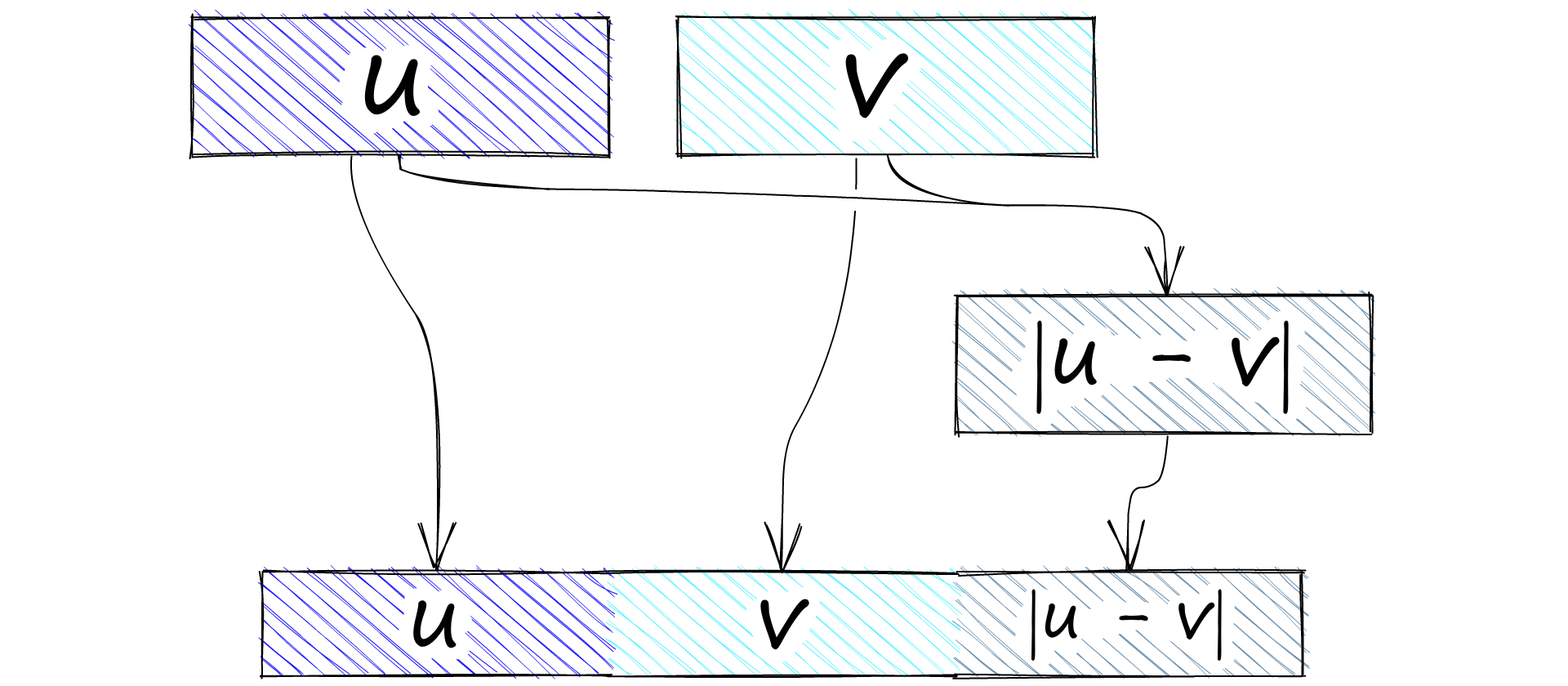
我们将嵌入 u、v 和 |u - v| 连接起来。
|u-v|计算是为了给我们两个向量之间的元素差异。除了最初的两个嵌入(u 和 v)之外,它们都被馈送到具有三个输出的前馈神经网络 (FFNN) 中。
这三个输出与我们的 NLI 相似性标签 0、1 和 2 一致。我们需要根据 FFNN 计算 softmax,这是在交叉熵损失函数内完成的。softmax和标签用于优化这种“softmax-loss”。
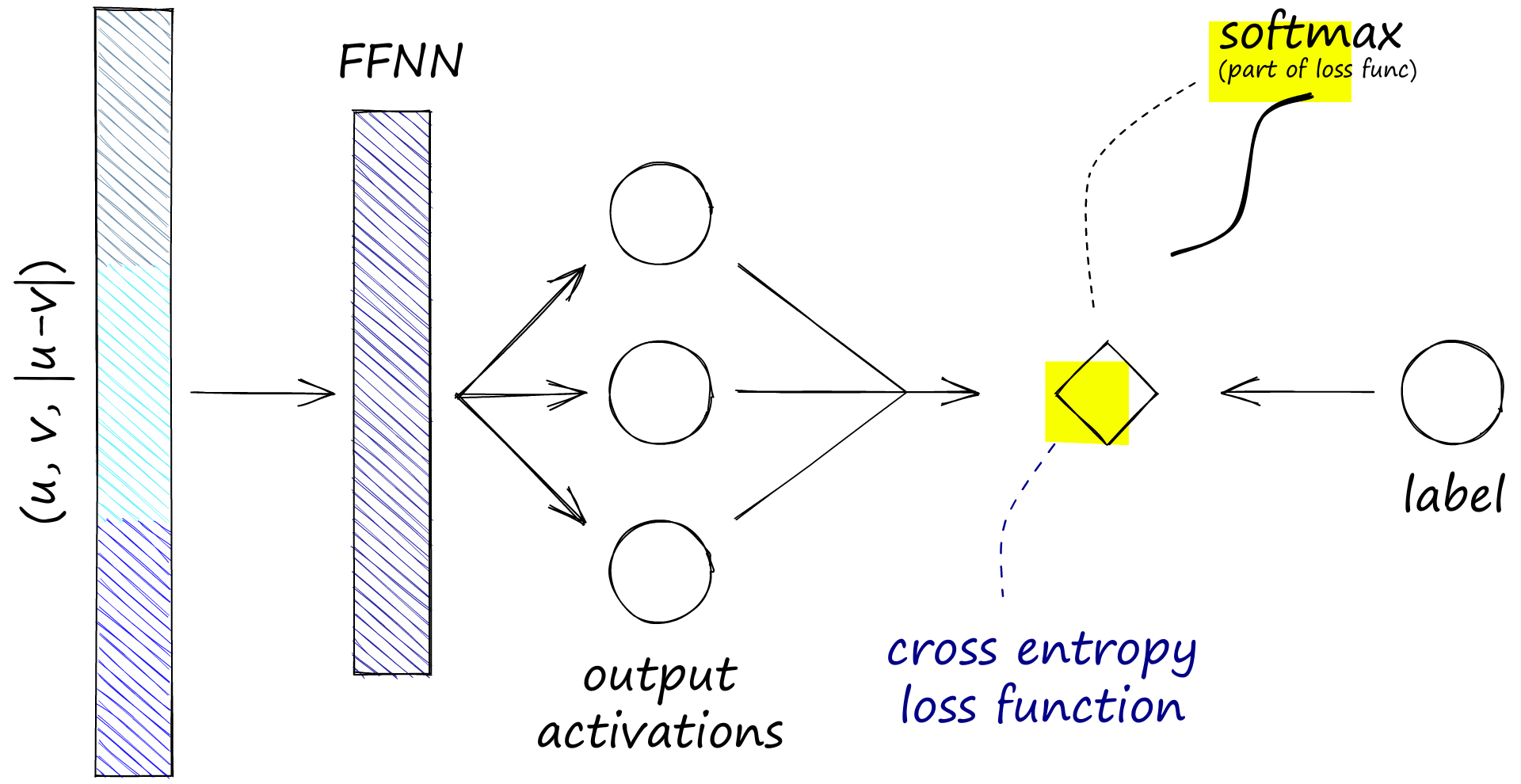
这些操作是在训练两个句子嵌入 u 和 v 期间执行的。请注意,softmax-loss 是指交叉熵损失(默认情况下包含一个 softmax 函数)。
这些操作是在训练两个句子嵌入 u 和 v 期间执行的。请注意,softmax-loss 是指交叉熵损失(默认情况下包含一个 softmax 函数)。
这导致相似句子(标签 0)的合并句子嵌入变得更加相似,而不同句子(标签 2)的嵌入变得不那么相似。
请记住,我们使用的是连体BERT,而不是双BERT。这意味着我们不使用两个独立的BERT模型,而是使用一个处理句子A后跟句子B的BERT。
这意味着当我们优化模型权重时,它们被推向一个方向,允许模型输出更多相似的向量,我们看到一个蕴涵标签,而更多的不同向量,我们看到矛盾标签。
我们正在制定一个分步指南,使用上述SNLI和MNLI语料库使用softmax-loss和多重负排名-loss方法训练暹罗BERT模型。您可以在我们发布文章后立即收到电子邮件,请单击此处(表格位于页面底部)。
这种训练方法有效的事实并不是特别直观,事实上,Reimers将其描述为巧合地产生了良好的句子嵌入[5]。
自原始文件以来,在这一领域做了进一步的工作。已经构建了更多的模型,例如在1B +样本上训练的最新MPNet和RoBERTa模型(产生更好的性能)。我们将在以后的文章中探讨其中的一些,以及它们使用的卓越训练方法。
现在,让我们看看如何初始化和使用其中一些句子转换器模型。
八、句子转换器入门
开始使用句子转换器的最快和最简单的方法是通过 SBERT 创建者创建的句子转换器库。我们可以用 pip 安装它。
!pip install sentence-transformers我们将从原始的SBERT模型bert-base-nli-mean-tokens开始。首先,我们下载并初始化模型。
在[1]中:
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens') model输出[1]:
SentenceTransformer( (0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel (1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False}) )我们在这里可以看到的输出是 SentenceTransformer 对象,它包含三个组件:
-
-
0 — 蕴涵,例如前提暗示假设。
-
1 — 中性,前提和假设都可以为真,但它们不一定相关。
-
2 — 矛盾,前提和假设相互矛盾。
一旦我们有了模型,就可以使用 encode 方法快速完成构建句子嵌入。
在[2]中:
sentences = [ "the fifty mannequin heads floating in the pool kind of freaked them out", "she swore she just saw her sushi move", "he embraced his new life as an eggplant", "my dentist tells me that chewing bricks is very bad for your teeth", "the dental specialist recommended an immediate stop to flossing with construction materials" ] embeddings = model.encode(sentences) embeddings.shape输出[2]:
(5, 768)我们现在有了句子嵌入,可以用来快速比较文章开头介绍的用例的句子相似性;STS、语义搜索和聚类分析。
我们可以将一个快速的 STS 示例放在一起,只使用余弦相似函数和 Numpy。
在[3]中:
import numpy as np from sentence_transformers.util import cos_sim sim = np.zeros((len(sentences), len(sentences))) for i in range(len(sentences)): sim[i:,i] = cos_sim(embeddings[i], embeddings[i:]) sim输出[3]:
array([[1.00000024, 0. , 0. , 0. , 0. ], [0.40914285, 1. , 0. , 0. , 0. ], [0.10909 , 0.4454796 , 1. , 0. , 0. ], [0.50074852, 0.30693918, 0.20791623, 0.99999958, 0. ], [0.29936209, 0.38607228, 0.28499269, 0.63849503, 1.0000006 ]])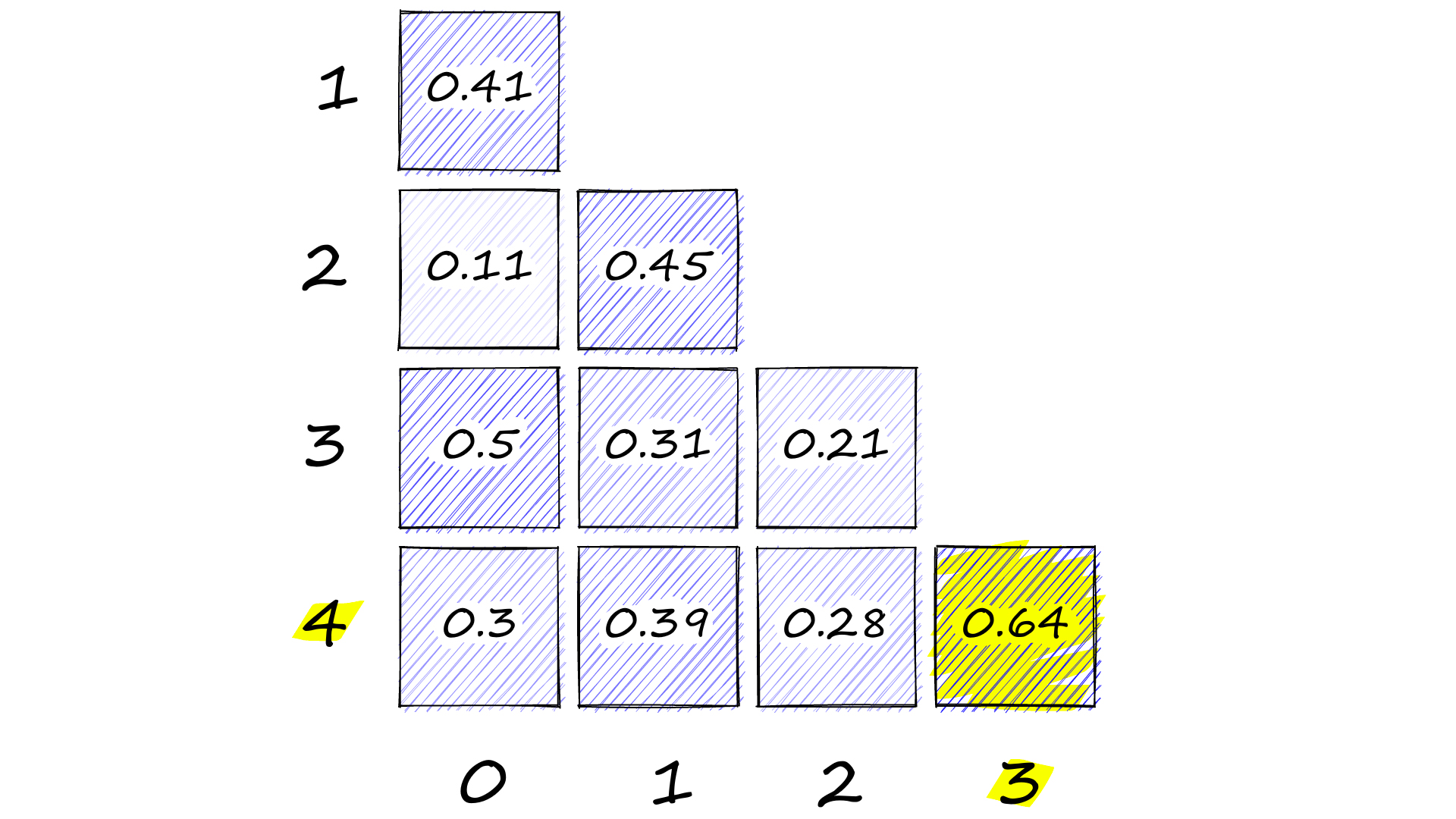
Heatmap showing cosine similarity values between all sentence-pairs.
Here we have calculated the cosine similarity between every combination of our five sentence embeddings. Which are:
Index Sentence 0 the fifty mannequin heads floating in the pool kind of freaked them out 1 she swore she just saw her sushi move 2 he embraced his new life as an eggplant 3 我的牙医告诉我,咀嚼砖头对你的牙齿非常有害 4 牙科专家建议立即停止使用建筑材料使用牙线 索引句子0漂浮在游泳池中的五十个人体模特头有点吓坏了他们1她发誓她刚刚看到她的寿司移动2他接受了茄子的新生活3我的牙医告诉我,咀嚼砖头对你的牙齿非常有害4牙科专家建议立即停止使用建筑材料使用牙线
我们可以在右下角看到最高的相似性得分,为 0.64。正如我们所希望的,这是针对第 4 句和第 3 句,它们都描述了使用建筑材料的不良牙科实践。
九、其他句子转换器
尽管我们从 SBERT 模型中返回了良好的结果,但此后已经建立了更多的句子转换器模型。其中许多我们可以在句子转换器库中找到。
这些较新的型号可以显着优于原始的SBERT。事实上,SBERT 不再在 SBERT.net 型号页面上列为可用型号。
型 平均性能 速度 大小 (MB) all-mpnet-base-v2 63.30 2800 418 全罗伯塔-大-V1 53.05 800 1355 全-迷你LM-L12-v1 59.80 7500 118 我们将在以后的文章中更详细地介绍其中一些后续模型。现在,让我们比较性能最高的一个,并运行我们的 STS 任务。
在[1]中:
# !pip install sentence-transformers from sentence_transformers import SentenceTransformer mpnet = SentenceTransformer('all-mpnet-base-v2') mpnet输出[1]:
SentenceTransformer( (0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel (1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False}) (2): Normalize() )这里我们有 all-mpnet-base-v2 的 SentenceTransformer 模型。这些组件与bert-base-nli-mean-tokens模型非常相似,但有一些小的区别:
-
-
转换器本身,在这里我们可以看到 128 个令牌的最大序列长度以及是否将任何输入小写(在这种情况下,模型没有)。我们还可以看到模型类 BertModel。
-
池化操作,这里我们可以看到我们正在生成一个 768 维的句子嵌入。我们使用平均池化方法执行此操作。
让我们比较一下 all-mpnet-base-v2 和 SBERT 的 STS 结果。
在[6]中:
embeddings = mpnet.encode(sentences) sim = np.zeros((len(sentences), len(sentences))) for i in range(len(sentences)): sim[i:,i] = cos_sim(embeddings[i], embeddings[i:]) sim输出[6]:
array([[ 1.00000048, 0. , 0. , 0. , 0. ], [ 0.26406282, 1.00000012, 0. , 0. , 0. ], [ 0.16503485, 0.16126671, 1.00000036, 0. , 0. ], [ 0.04334451, 0.04615867, 0.0567013 , 1.00000036, 0. ], [ 0.05398509, 0.06101188, -0.01122264, 0.51847214, 0.99999952]])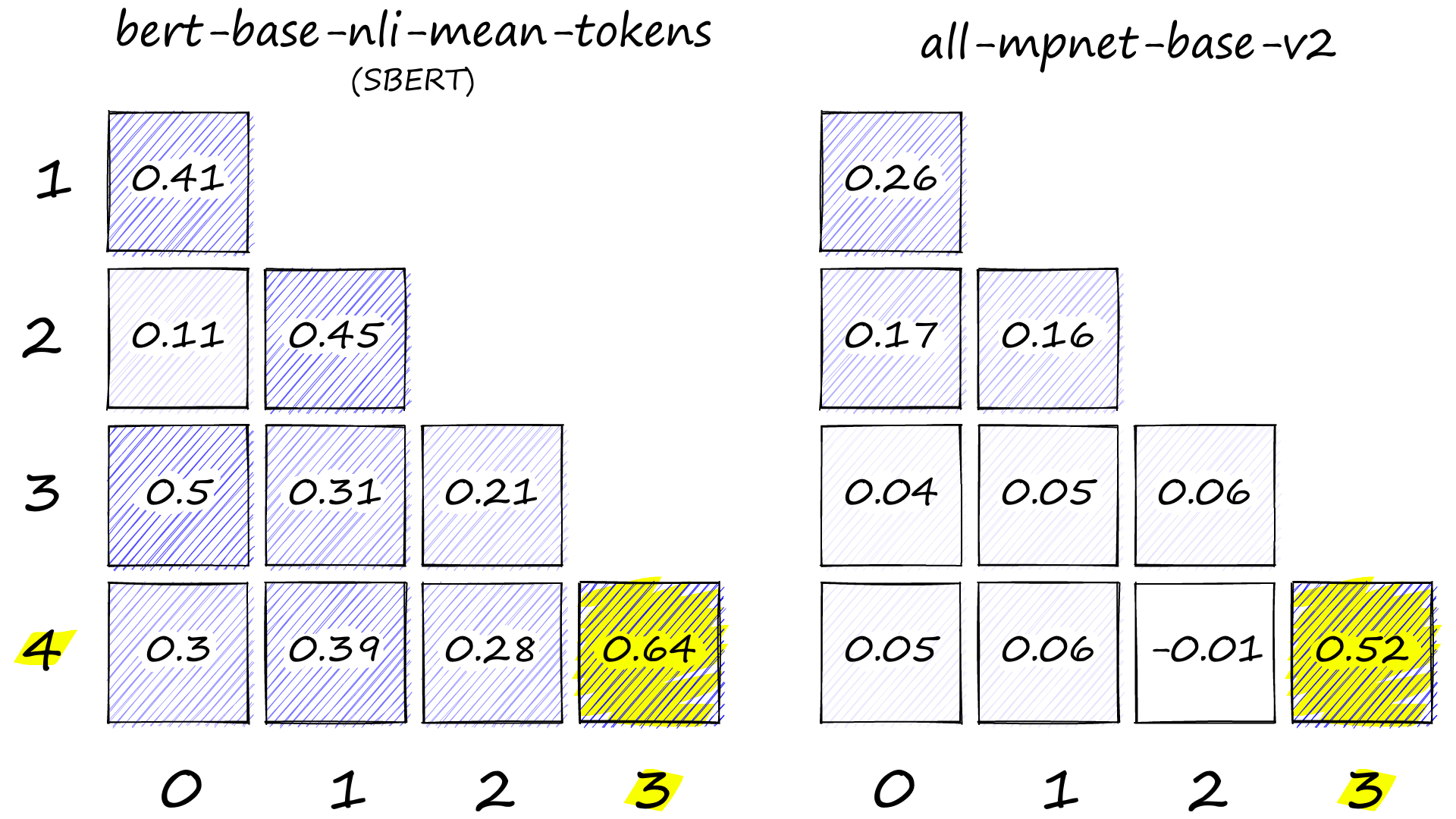
SBERT 和 MPNet 句子转换器的热图。
后来模型的语义表示是显而易见的。尽管 SBERT 正确地将 4 和 3 识别为最相似的对,但它也为其他句子对分配了相当高的相似性。
另一方面,MPNet模型非常清楚地区分了相似和不同的对,大多数对的得分低于0.1,4-3对的得分为0.52。
通过增加不同和相似对之间的距离,我们可以:
这就是本文介绍句子嵌入和当前用于构建这些非常有用的嵌入的 SOTA 句子转换器模型。
句子嵌入虽然最近才普及,但却是由一系列奇妙的创新产生的。我们描述了用于创建第一句变压器SBERT的一些机制。
我们还证明,尽管 SBERT 最近在 2019 年推出,但其他句子转换器的性能已经优于该模型。对我们来说幸运的是,使用句子转换器库很容易将 SBERT 切换为这些较新的模型之一。
在以后的文章中,我们将更深入地研究其中一些较新的模型以及如何训练我们自己的句子转换器。
订阅更多语义搜索材料!提交
引用
[1] A. Vashwani等人,《注意力是你需要的》(2017),NeurIPS
[2] D. Bahdanau等人,通过共同学习对齐和翻译的神经机器翻译(2015),ICLR
[3] N. Reimers,I. Gurevych,Sentence-BERT:使用Siamese BERT-Networks的句子嵌入(2019),ACL
[4] MPNet 模型, 抱面 文档
-
-
-
-