目录
1、简介
2、实现原理
3、实现步骤
4、公式分析
5、实例分析
6、⭐协方差矩阵补充说明
7、LaTex文本
⭐创作不易,您的一键三连,就是支持我写作的最大动力!🥹
关于代码如何实现,请看这篇文章:[机器学习]特征工程:主成分分析_逐梦苍穹的博客-CSDN博客
https://blog.csdn.net/qq_60735796/article/details/132324240
1、简介

主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维和特征提取技术,用于将高维数据转化为低维表示,同时保留数据的主要特征。
它通过线性变换将原始特征投影到新的坐标轴上,使得投影后的特征具有最大的方差,从而达到降低数据维度的目的。
PCA 的主要思想是寻找数据中的主要方向,即数据的主成分,这些主成分是数据变化最大的方向。通过保留最重要的主成分,可以将数据的维度减少,从而减少存储和计算的成本,同时可以降低数据中的噪声和冗余信息,提高模型的泛化能力。
2、实现原理
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。
PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。
其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。
依次类推,可以得到n个这样的坐标轴。
通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。
于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。
事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
3、实现步骤
PCA 的工作步骤如下:
- 标准化数据
- 计算数据的协方差矩阵。
- 对协方差矩阵进行特征值分解,得到特征值和特征向量。
- 将特征值按从大到小的顺序排列,选择前几个特征值对应的特征向量作为主成分。
- 将原始数据投影到选定的主成分上,得到降维后的数据。
4、公式分析
①特征样本均值:
②特征样本方差:
③特征方差:
④协方差:
⑤协方差矩阵:
⑥样本去中心化协方差:
⑦特征向量:
⑧特征值:令 |C-λE| =0
⑨特征向量标准化(先求特征向量的长度):
5、实例分析
给出平面直角坐标系上的五个点:(-1,-2),(-1, 0),( 0, 0),( 2, 1),( 0, 1),
所以矩阵为:
描点画图:
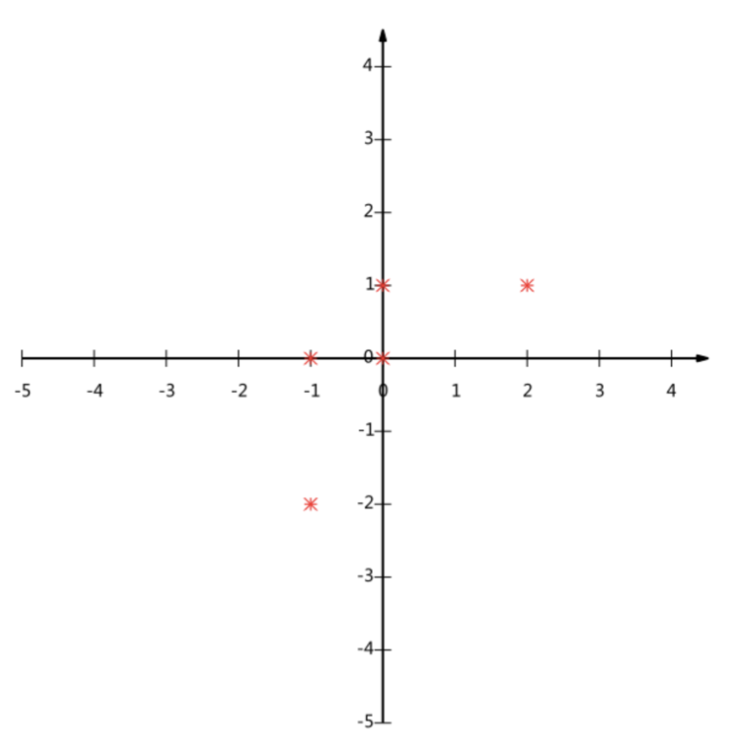
下面使用主成分分析方法进行降维,结果如下:

下面是主成分分析的实现过程:
①去中心化。由于这组数据的两个指标的平均值都为0,所以该样本就是去中心化样本。
所以该样本为:
②计算标准差。这里的特征标准差都一致,所以这一步可以不用。
③计算协方差,这里因为数据去中心化了,所以使用的公式为:
(后面细讲这个公式)
协方差计算过程为:
④特征值和特征向量:Cv=λv。
计算过程:
整理一下,得出:
进行化简,得到:
行列式求解:
因式分解得:
解得:λ1=2,λ2=2/5
特征值依次带入行列式的矩阵,乘以对应的特征向量,得:
把λ1=2,λ2=2/5依次带入,得到:
最终特征向量v1为:
同理可得最终特征向量v2为:
其中对应的特征向量分别是一个通解,C1和C2可以取任意实数。那么标准化后的特征向量为:
v1:
v2:
所以特征矩阵为:
⑤选取主成分:
取p1和p2:
最后结果公式为:Y=PX,带入p1,得Y=p1X:
带入p2同理,但是最终主成分分析的结果,应取带入p1为佳,投影到一维坐标之后,矩阵元素点到新坐标原点的距离之和,, 带入p1大于p2。
6、⭐协方差矩阵补充说明
样本去中心化协方差:
我们来推导一下协方差矩阵公式的原理:
假设我们有一个数据矩阵 X,其中每一行表示一个观测样本,每一列表示一个特征。假设数据已经被中心化,即每个特征的均值为零。
协方差矩阵的元素 Cov(Xi,Xj) 表示随机变量 Xi 和 Xj 之间的协方差。协方差的计算公式为:
其中,xki 表示第 k 个样本的第 i 个特征值,xˉi 表示第 i 个特征的均值,n 表示观测样本数。
我们可以把数据矩阵 X 写成如下形式:
其中,每一行对应一个观测样本,每一列对应一个特征。
我们现在考虑协方差矩阵的一个元素Cov(Xi,Xj):
我们可以把这个元素的计算写成矩阵形式,将每一列表示一个特征向量,得到如下形式:
其中,Xi 是第 i 个特征的列向量,xˉi 是第 i 个特征的均值列向量。
现在我们可以考虑协方差矩阵的计算,可以表示为矩阵乘积的形式:
其中,X 是数据矩阵,xˉ 是均值矩阵,每一列表示对应特征的均值。
将 X 展开成列向量形式,我们可以得到:
这就得到了协方差矩阵的计算公式。需要注意的是,这个公式是在数据已经中心化的基础上进行推导的。
在实际应用中,如果数据没有被中心化,还需要额外的操作来考虑均值的影响。
7、LaTex文本
文中所有公式对应的LaTex表达式都放这里了:
4、公式分析
①特征样本均值:\overline{x}= \frac{1}{n}\sum_{i=1}^{n}{x_i}
②特征样本方差:{S}^2= \frac{1}{n-1}\sum_{i=1}^{n}{(x_i-\overline{x})^2}
③特征方差:{S}^2= \frac{1}{n}\sum_{i=1}^{n}{(x_i-\overline{x})^2}
④协方差:\text{Cov}(X, Y) = \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})
⑤协方差矩阵:\text{Cov}(X_1,X_2,...X_p) = \begin{bmatrix}
\text{Cov}(X_1, X_1) & \text{Cov}(X_1, X_2) & \dots & \text{Cov}(X_1, X_p) \\
\text{Cov}(X_2, X_1) & \text{Cov}(X_2, X_2) & \dots & \text{Cov}(X_2, X_p) \\
\vdots & \vdots & \ddots & \vdots \\
\text{Cov}(X_p, X_1) & \text{Cov}(X_p, X_2) & \dots & \text{Cov}(X_p, X_p)
\end{bmatrix}
⑥样本去中心化协方差:\boldsymbol{\Sigma} = \frac{1}{n} \mathbf{X}^T \mathbf{X}
⑦特征向量:Av=\lambda v
⑧特征值:令 |C-λE| =0
⑨特征向量标准化(先求特征向量的长度):\mathbf{v}_{\text{std}} = \frac{\mathbf{v}}{||\mathbf{v}||}
给出平面直角坐标系上的五个点:(-1,-2),(-1, 0),( 0, 0),( 2, 1),( 0, 1),
所以矩阵为:x=
\begin{pmatrix}
-1 & -1 & 0 & 2 & 0 \\
-2 & 0 & 0 & 1 & 1
\end{pmatrix}
下面是主成分分析的实现过程:
①去中心化。由于这组数据的两个指标的平均值都为0,所以该样本就是去中心化样本。
所以该样本为:
X=x=
\begin{pmatrix}
-1 & -1 & 0 & 2 & 0 \\
-2 & 0 & 0 & 1 & 1
\end{pmatrix}
②计算标准差。这里的特征标准差都一致,所以这一步可以不用。
③计算协方差,这里因为数据去中心化了,所以使用的公式为:\boldsymbol{C} = \frac{1}{n} \mathbf{X}^T \mathbf{X} (后面细讲这个公式)
协方差计算过程为:
\boldsymbol{C} = \frac{1}{n} \mathbf{X} \mathbf{X}^T=\frac{1}{5}\begin{pmatrix}
-1 & -1 & 0 & 2 & 0 \\
-2 & 0 & 0 & 1 & 1 \end{pmatrix} \begin{pmatrix}
-1 & -2 \\
-1 & 0 \\
0 & 0 \\
2 & 1 \\
0 & 1 \\ \end{pmatrix} =\begin{pmatrix} \frac{6}{5} & \frac{4}{5} \\ \frac{4}{5} & \frac{6}{5} \\ \end{pmatrix}
④特征值和特征向量:Cv=λv。
计算过程:
\begin{pmatrix}
\frac{6}{5} & \frac{4}{5} \\
\frac{4}{5} & \frac{6}{5} \\
\end{pmatrix}\begin{pmatrix}
v_1\\
v_2\\
\end{pmatrix}=\lambda\begin{pmatrix}
v_1\\
v_2\\
\end{pmatrix}
整理一下,得出:
\begin{array}{l}
\left\{\begin{matrix}
\frac{6v_1}{5}+\frac{4v_2}{5}=\lambda v_1 \\
\frac{4v_1}{5}+\frac{6v_2}{5}=\lambda v_2
\end{matrix}\right.
\end{array}
进行化简,得到:
\begin{array}{l}
\left\{\begin{matrix}
(\frac{6}{5}-\lambda )v_1+\frac{4v_2}{5}=0 \\
\frac{4v_1}{5}+(\frac{6}{5}-\lambda)v_2=0
\end{matrix}\right.
\end{array}
行列式求解:
\begin{vmatrix}
\frac{6}{5}-\lambda & \frac{4}{5}\\
\frac{4}{5}& \frac{6}{5}-\lambda \\
\end{vmatrix} =0
因式分解得:
\left(\lambda-\frac{2}{5}\right)\left(\lambda-2\right) =0
解得:λ1=2,λ2=2/5
特征值依次带入行列式的矩阵,乘以对应的特征向量,得:
\begin{pmatrix}
\frac{6}{5}-\lambda & \frac{4}{5} \\
\frac{4}{5} & \frac{6}{5}-\lambda \\
\end{pmatrix}\begin{pmatrix}
v_{i1}\\
v_{i2}\\
\end{pmatrix}=\begin{pmatrix}
0\\
0\\
\end{pmatrix}
把λ1=2,λ2=2/5依次带入,得到:
\begin{pmatrix}
\frac{6}{5}-2 & \frac{4}{5} \\
\frac{4}{5} & \frac{6}{5}-2 \\
\end{pmatrix}\begin{pmatrix}
v_{11}\\
v_{12}\\
\end{pmatrix}=
\begin{pmatrix}
-\frac{4}{5} & \frac{4}{5} \\
\frac{4}{5} & -\frac{4}{5} \\
\end{pmatrix}\begin{pmatrix}
v_{11}\\
v_{12}\\
\end{pmatrix}=
\begin{pmatrix}
0\\
0\\
\end{pmatrix}
最终特征向量v1为:C_1\begin{pmatrix}
1 \\
1 \\
\end{pmatrix}
同理可得最终特征向量v2为:C_2\begin{pmatrix}
-1 \\
1 \\
\end{pmatrix}
其中对应的特征向量分别是一个通解,C1和C2可以取任意实数。那么标准化后的特征向量为:
v1:
\mathbf{v}_{\text{1}} = \frac{\mathbf{v_1}}{||\mathbf{v}||}=
\frac{
\begin{pmatrix}
1 \\
1
\end{pmatrix}
}{
\sqrt{1^2+1^2}
}=\frac{
\begin{pmatrix}
1 \\
1
\end{pmatrix}
}{
\sqrt{2}
}=\begin{pmatrix}
\frac{1}{\sqrt{2} } \\
\frac{1}{\sqrt{2} }
\end{pmatrix}
v2:
\mathbf{v}_{\text{2}} = \frac{\mathbf{v_1}}{||\mathbf{v}||}=
\frac{
\begin{pmatrix}
-1 \\
1
\end{pmatrix}
}{
\sqrt{(-1)^2+1^2}
}=\frac{
\begin{pmatrix}
-1 \\
1
\end{pmatrix}
}{
\sqrt{2}
}=\begin{pmatrix}
-\frac{1}{\sqrt{2} } \\
\frac{1}{\sqrt{2} }
\end{pmatrix}
所以特征矩阵为:
P=\begin{pmatrix}
\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\
-\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}}
\end{pmatrix}
⑤选取主成分:
取p1和p2:
p_1=\begin{pmatrix}
\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}}
\end{pmatrix}
p_2=\begin{pmatrix}
-\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}}
\end{pmatrix}
最后结果公式为:Y=PX,带入p1,得Y=p1X:
Y=p_1X=\begin{pmatrix}
\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}}
\end{pmatrix} \begin{pmatrix}
-1 & -1 & 0 & 2 & 0 \\
-2 & 0 & 0 & 1 & 1
\end{pmatrix} =\begin{pmatrix}
-\frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}} & 0 & \frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}}
\end{pmatrix}
带入p2同理,但是最终主成分分析的结果,应取带入p1为佳,投影到一维坐标之后,矩阵元素点到新坐标原点的距离之和,, 带入p1大于p2。
6、⭐协方差矩阵补充说明
样本去中心化协方差:\boldsymbol{C} = \frac{1}{n} \mathbf{X} \mathbf{X}^T
我们来推导一下协方差矩阵公式\boldsymbol{C} = \frac{1}{n} \mathbf{X} \mathbf{X}^T的原理:
假设我们有一个数据矩阵 X,其中每一行表示一个观测样本,每一列表示一个特征。假设数据已经被中心化,即每个特征的均值为零。
协方差矩阵的元素 Cov(Xi,Xj) 表示随机变量 Xi 和 Xj 之间的协方差。协方差的计算公式为:
\text{Cov}(X, Y) = \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})
其中,xki 表示第 k 个样本的第 i 个特征值,xˉi 表示第 i 个特征的均值,n 表示观测样本数。
我们可以把数据矩阵 X 写成如下形式:
X=\begin{pmatrix}
a_{11} & a_{12} &\cdots & a_{1p} \\
a_{21} & a_{22} & \cdots & a_{2p} \\
\vdots & \ddots & \vdots & \vdots\\
a_{n1} & a_{n2}&\cdots & a_{np}
\end{pmatrix}
其中,每一行对应一个观测样本,每一列对应一个特征。
我们现在考虑协方差矩阵的一个元素Cov(Xi,Xj):
\text{Cov}(X_i, Y_i) = \frac{1}{n} \sum_{k=1}^{n} (x_{ki} - \bar{x_i})(x_{ki} - \bar{x_j})
我们可以把这个元素的计算写成矩阵形式,将每一列表示一个特征向量,得到如下形式:
\text{Cov}(X_i, Y_i) = \frac{1}{n} (X_{i} - \bar{x_i})^T(X_{j} - \bar{x_j})
其中,Xi 是第 i 个特征的列向量,xˉi 是第 i 个特征的均值列向量。
现在我们可以考虑协方差矩阵的计算,可以表示为矩阵乘积的形式:
\boldsymbol{\Sigma}= \frac{1}{n} (X_{} - \bar{x})^T(X_{} - \bar{x})
其中,X 是数据矩阵,xˉ 是均值矩阵,每一列表示对应特征的均值。
将 X 展开成列向量形式,我们可以得到:
\boldsymbol{\Sigma}= \frac{1}{n} X^TX
这就得到了协方差矩阵的计算公式。需要注意的是,这个公式是在数据已经中心化的基础上进行推导的。
在实际应用中,如果数据没有被中心化,还需要额外的操作来考虑均值的影响。




![[LeetCode]矩阵对角线元素的和](https://img-blog.csdnimg.cn/3eab16098fcb49e6826fa3cbbdcc7960.png)