目录
内存管理背后的故事
内存管理概述
常见内存分配策略
LwIP的宏配置及内存管理
见招拆招——动态内存堆
数据结构描述
函数实现
以不变应万变——动态内存池
数据结构描述
函数实现
使用C库管理内存策略
无论在哪种系统中,动态内存都是一个非常重要的机制,而在LwIP这种需要处理大量数据的TCP/IP协议栈中,动态内存管理就显得尤为重要了。内存管理策略、内存分配效率是衡量一个系统性能的重要因素之一。LwIP为用户提供了两种最基本的内存管理机制,动态内存池管理和动态内存堆管理。此外,用户还可以根据具体配置情况配置LwIP使用其他的内存管理方式。说到内存分配,我们不得不想起C语言的提供的内存分配函数malloc和free函数,LwIP也支持这种分配内存方式,但是不建议使用。
这里举个形象的例子:内存比作一个大西瓜,内存堆就是吃多少切多少,内存池则是已经切成了若干片相同大小的西瓜,你直接拿其中一块。
内存管理背后的故事
内存管理概述
在平常的编程中,大家都会遇到对动态内存的操作,例如创建一个临时数据区域,在程序的某个阶段结束后释放该区域,这就是动态内存的典型应用了。动态内存管理会涉及到两类重要函数:内存分配函数和内存释放函数,无论使用什么语言工具,都不可避免的为用户提供这两个配套函数,像C语言提到的malloc和free函数就是一个典型代表。那么操作系统内部是如何实现对内存的合理管理与分配的呢?
在使用标准C库时,经常见到malloc和free这两个内存管理函数,内存分配的本质就是在事先准备好一大块内存堆(可以理解为一个很大的数组)中分配合适的空间,然后将该空间的起始地址返回给调用者,内核必须采用自己独有的一套数据结构来描述,记录哪些空间范围已经被分配(称之为占用块、哪些未用(称之为空闲块),而根据这里使用的机制的不同,就会延伸出多种类型的内存分配策略。
内存分配最重要的就是分配的时间效率问题,在系统看来,用户在某一个时刻可能请求分配的空间大小各有差异,内存分配策略会负责如何在可用的所有空间中找出一块返回给用户。显然,不管在何种动态内存管理系统中,在初始时,整个内存就相当于一块大的空闲块。随着,用户进入系统,先后提出内存分配、内存释放请求,经过一段时间的运行后,内存中会出现空闲空间和占用空间交错的状态,这时候的内存组织状况可以通过下面的图来描述,在这种交错状态下,如何根据新的用户申请找到一个合适的空间给用户,这是最重要的问题,通常各种内存分配策略也会在这里出现差异。
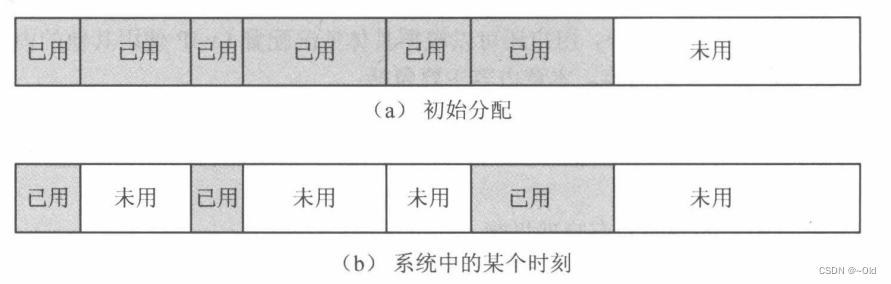
在系统运行于某个时刻,内存的组织如图所示,如果此时用户又提出内存空间申请,那么内存分配函数又将怎样去做呢?通常可以分为两种类型:一种是系统继续从高地址的空闲块中进行分配,而不去理会已经分配给用户的内存区域是否已被释放,当分配无法进行时(即高地址空间不能满足用户请求的大小时),系统才去逐渐地检查以前分配给用户的空间是否已释放,同时系统将所有已释放的空间重新组织成-一个大的可用空闲块,以满足用户的内存分配请求;另一种策略是一旦用户运行结束并释放内存空间,系统便将该空间标记为空闲,每当有用户提出空间分配申请时,系统将依次遍历整个系统中的空闲块,找出一个系统认为可 每当有用户提出空间分配申请时,系统将依次遍历整个系统中的空闲块,找出一个系统认为可行的空闲块给用户。这里最常见的是第二种策略,这种类型的分配方式又可以衍生出好几种内存分配策略。
在内存释放时,内存释放函数最关心的问题是如何能高效地回收这些内存空间,标记对应空间为空闲,以便下次分配时使用。另一方面,内存释放函数应该尽量避免内存碎片的产生,尽量保留那些大的空闲块,这就涉及到空闲块回收时的节点合并问题,即怎样把几个相邻的小空闲块合并为-一个大空闲块,以保障用户的大内存空间申请。
内存分配与内存释放,这两者之间是互相联系的,它们互相配合,完成系统动态内存的高效管理。
常见内存分配策略
这里介绍三种常见的内存分配策略,这三种策略也是在LwIP中被使用的,它们各有所长,根据不同应用场合选择不同的内存分配策略,会使得系统的内存开销,内存操作效率得到很大的提高。
第一种:系统规定用户在申请内存时,申请大小必须指定为某几个固定值(例如4、8、16等)否则内存分配函数不予分配。系统初始化时,会事先在内存中初始化相应的空闲内存块空间,如图所示,系统将所有可用区域以固定大小为单位进行划分,然后用一个简单的链表将所有空闲块链接起来。由于链表中所有节点的大小相同,所以分配时不需要查找,直接取出第一个节点中的空间分配给用户即可,同样,内存释放过程也很简单,直接将释放的内存空间插入到对应链表首部即可。通常,这种分配方式内存所需的时间很短,效率也很高。但这种方式使用时比较拘束,因为用户申请的大小必须为某个固定长度,所以这种方式不可避免的会产生内存浪费的现象,以及在申请大内存时有可能出现申请不成功的情况。在LwIP中实现了这种方式的内存分配策略,称之为动态内存池分配,这种方式可以用来对某种固定的数据结构进行空间的分配(如TCP首部,IP首部等)。
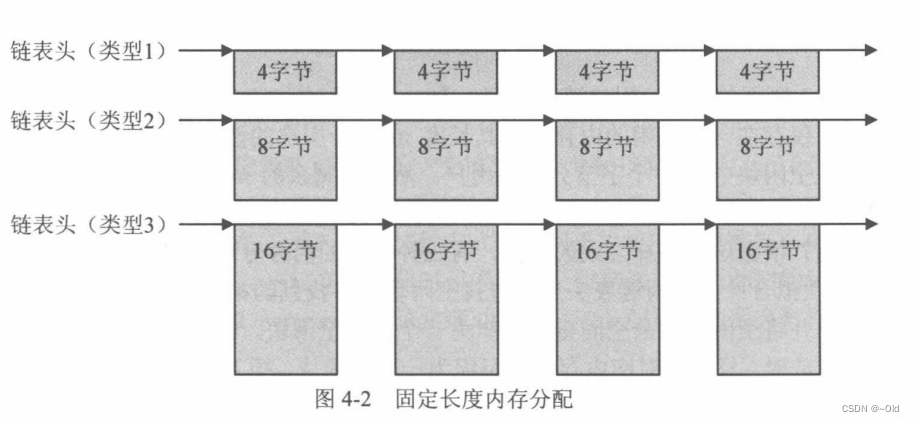
第二种分配策略与第一种分配相似,系统启动时也会在内存中初始化几个如图所示的固定大小的内存块链表,但在第二种方式下,系统把用户程序在运行期间可能会请求的内存空间大小划分为几个范围(向上取整,以满足系统某个固定大小) 。例如,用户需要申请5个字节时,系统会在链表2上为用户分配一个空间,用户需要申请11个字节时,系统会在链表3上为用户分配一个空间,以此类推。这种分配方式会造成一定的空间浪费,但是可以达到很高的分配速度,因为分配时不需要进行链表的遍历。另外,可以采取一些措施达到节省空间的目的,例如,如果用户请求5个字节的空间,但同时链表2上的空闲块已经全部被分配出去了,则此时系统可以在包含更大字节的链表中去查找空闲空间,这里为链表3,分配函数在链表3上取出一个空闲块,并截取其中的8个字节,同时,将该空闲块剩余部分(8个字节)重新组织并插入到链表2中,当然,采用这种优化策略也会带来问题,例如当用户请求空间的大小在所有链表的空闲块上都不能满足时,此时的空间分配会失败。但事实上,系统中可能存在满足用户要求的连续空间,只是系统在运行过程中出现大量小块的内存分配和回收,使得链表3中的大空闲块被多次划分,最终被间隔成几个独立的空间并连接到了链表1和链表2中。此时,若要使系统能继续运行,则必须将上面的链表进行重新组织,这就是常说的存储紧缩操作。在LwIP中,这种内存分配方式是可选的,但其具体实现和这里描述的还有点差异。
第三种:这种方式是在很多系统中被用到的。系统运行时,各个空闲块的大小是随着系统运行而改变的,系统分配给用户的空间大小随着用户请求的大小而改变,系统刚开始时,整个内存空间就是一个大的空闲块,随着分配和回收的进行,内存块的大小、数量也随着系统的运行而改变,某个时刻内存中空闲块的组织示意图如下所示:
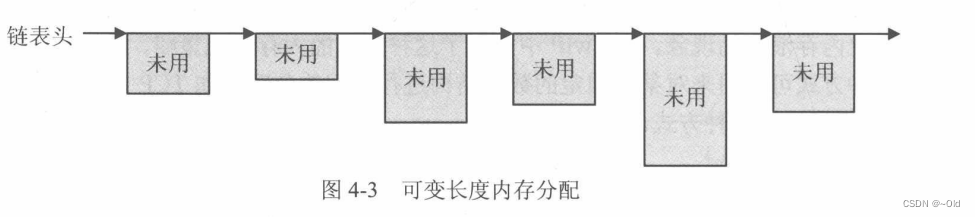
在上图中,用户请求分配一个大小为n的空间,系统应该怎么做呢?若整个空闲链表中,仅存在一个空闲的内存块,其长度m大于用户的请求n,则此时的分配比较简单,直接将该空闲块中的n个字节分配给用户,然后将剩余的m-n重新组织为一个空闲块,并链接在链表中。若链表中存在多个空闲块,它们的长度都大于n,则此时系统应该选择哪个空闲块来分配呢?根据这种选择方式的不同,有三种常见的内存分配策略。
(1)首次拟合(First Fit)
从空闲链表头开始查找空闲块,将找到的第一个长度不小于n的空闲块分配给用户,并将空闲块剩余空间重新组织为一个小的空闲块,插入到链表中。这种策略下, 在内存空间释放时,只需将对应内存空间组织为-一个空闲块,插入到空闲链表表头即可。首次拟合是目前使用最多的内存分配策略,在LwIP中也提供了这种内存分配策略的实现,称之为内存堆分配。
(2)最佳拟合
系统从空闲链表中查找长度和n最接近的空闲块分配给用户,这种方式下系统需要遍历整个链表,以找到最合适的。通常在这种方式下,为避免在每次分配时都进行链表的全部遍历,系统会将各空闲块按照空间由小到大的顺序组织起来,这样在内存分配时,分配函数只需找到第一个长度大于n的空闲块就可以了。使用这种内存分配策略时,内存的回收过程较慢,它需要将空闲内存块按照其大小插入到链表中的某个特定位置上。
(3)最差拟合
从系统最大的空闲块中划分出n个字节分配给用户,使用这种方式也需要遍历链表,所以通常这种情况下,空闲块链表会按照其空间由大到小的顺序进行组织。这样,每次分配时无须查找,只要从链表中取出第一个空闲块,分配其中一部分给用户,并将剩余空间重新组织,插入到空闲链表中的具体位置。使用这种内存分配策略时,在内存释放过程中也一样会遍历空闲链表,将空闲内存块插入到合适的位置。
上述这三种方式各有优点,一般来说,最佳拟合适用于用户请求大小范围较广的系统,因为按照最佳拟合的原则进行分配时,系统总是找到最接近请求大小的空闲块,大的空闲块得到保护不会被多次划分,以备后续大内存申请时使用,但另一方面,系统中可能产生一些很小甚至无法再被使用的内存片;最差拟合每次选择最大的空闲块进行分配,这会使空闲链表中的各空闲块大小趋于均匀,所以这种方式更适合于用户内存请求大小范围较窄的系统;首次拟合法的分配是随机的,因此它介于这两者之间,通常用于系统不知道运行期间用户请求大小的情况。从时间上来看,首次拟合在分配时会查询空闲链表,在回收时只用将空闲块插到表头;最差拟合法相反,分配时不需要查找,而在回收时需要查找空闲链表,以将空闲块插入到合适的位置;最佳拟合法无论是分配还是回收均需要查找链表,最浪费时间。
在实际使用的系统中,回收空闲块时还需要考虑节点合并的问题,这是因为系统在不断进行分配和回收的过程中,大的空闲块逐渐被分割成小的占用块,在这些小的占用块被释放时,即使是地址相邻的两个空闲块也是作为两个独立空闲块被插入到空闲链表中,这使得后来的大容量内存申请无法正确进行。为了更加有效地利用内存空间,系统应该在回收时尽量将地址相邻的空闲块合并成更大的空闲节点。
LwIP的宏配置及内存管理
在LwIP中内存的选择需要以下几个宏定义的值来决定,用户可以根据宏值来判断LwIP使用哪种内存管理策略。如下表所示:
| 宏定义 | 描述 |
| MEM_LIBC_MALLOC | 选择 C 标准库分配策略(默认为 0) |
| MEMP_MEM_MALLOC | 是否使用 lwIP 内存堆分配策略实现内存池分配(默认为 0) |
| MEM_USE_POOLS | 是否使用 lwIP 内存池分配策略实现内存堆的分配(默认为 0) |
注:lwIP 内存堆管理策略和 C 标准库管理策略只能选其一,若 MEM_LIBC_MALLOC 为 0,则 lwIP 内核选择内存堆管理策略。
这里内存堆管理的内存由来:mem.c注释写的很详细
第一种:通过开辟一个内存堆,使用模拟C运行时库的内存分配策略实现(大数组)
第二种:通过动态内存池的方式实现
* To let mem_malloc() use pools (prevents fragmentation and is much faster than
* a heap but might waste some memory), define MEM_USE_POOLS to 1, define
* MEMP_USE_CUSTOM_POOLS to 1 and create a file "lwippools.h" that includes a list
* of pools like this (more pools can be added between _START and _END):
*
* Define three pools with sizes 256, 512, and 1512 bytes
* LWIP_MALLOC_MEMPOOL_START
* LWIP_MALLOC_MEMPOOL(20, 256)
* LWIP_MALLOC_MEMPOOL(10, 512)
* LWIP_MALLOC_MEMPOOL(5, 1512)
* LWIP_MALLOC_MEMPOOL_END
*/LwIP默认使用第一种分配方式。
见招拆招——动态内存堆
动态内存堆分配策略的本质就是对一个事先定义好的内存块进行合理有效的组织和管理,其内存分配的策略采用首次拟合(First Fit)方式,只要找到一个比用户请求空间大的空闲块,就从中切割出合适的块,并把剩余的部分返回到动态内存堆中(如果大小满足要求)。
动态内存堆也叫可变长分配方式,这种可变长的内存块分配在很多系统中被用到,系统本 身就是一个很大的内存堆,随着系统的运行,不断的申请和释放内存造成了系统的内存块的大 小和数量随之改变,严重一点可能造成内存碎片。lwIP 动态内存堆策略采用 First Fit(首次拟 合)内存管理算法。该算法倾向于优先利用内存中低址部分的空闲分区,从而保留了高址部分 的大空闲区,这为以后到达的大作业分配大的内存空间创造了条件,但是缺点也是明显的,因 为首次拟合(First Fit)算法是从低地址不断被划分的,所以系统会留下许多难以利用的且很 小的空闲分区,我们称为内存碎片。每次申请内存时系统每次查找都是从低地址部分开始的, 这无疑又会增加查找可用空闲分区时的时间。
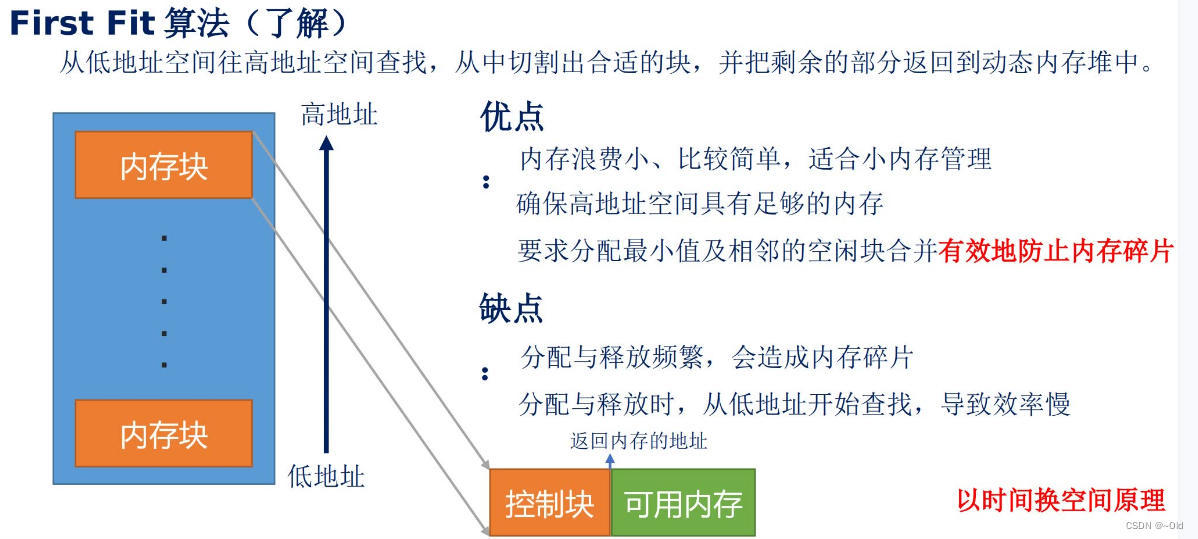 这里,需要说明的是,一个内存块包含两部分,一部分是控制块,一部分是可用内存,一般返回的地址都是针对可用内存的起始地址,控制块是描述可用内存的信息。
这里,需要说明的是,一个内存块包含两部分,一部分是控制块,一部分是可用内存,一般返回的地址都是针对可用内存的起始地址,控制块是描述可用内存的信息。
数据结构描述
(1)内存堆的结构体
管理内存块的结构体,如下源码所示:
struct mem {
/** 保存下一个内存块的索引,注意这里是数组索引,而不是地址 */
mem_size_t next;
/** 保存前一个内存块的索引 */
mem_size_t prev;
/** 此内存块是否被使用,1:使用 0:未使用 */
u8_t used;
#if MEM_OVERFLOW_CHECK
/** this keeps track of the user allocation size for guard checks,未使用 */
mem_size_t user_size;
#endif
};
可以看出,这个结构体只定义了三个成员变量,其中 next、prev 变量用来保存下一个和前 一个内存块的索引(注意是数组的索引,而不是地址),而 used 变量用来声明被管理的内存块是否可用。
(2)内存堆的对齐及最小配置值
#ifndef MIN_SIZE
#define MIN_SIZE 12
#endif /* MIN_SIZE */
/* 最小大小做对齐处理,后面均用对齐后的该宏值 * */
#define MIN_SIZE_ALIGNED LWIP_MEM_ALIGN_SIZE(MIN_SIZE)
/*内存块头大小做对齐处理,后面均用对齐后的该宏值 */
#define SIZEOF_STRUCT_MEM LWIP_MEM_ALIGN_SIZE(sizeof(struct mem))
/*用户定义的堆大小做对齐处理,后面均用对齐后的该宏值*/
#define MEM_SIZE_ALIGNED LWIP_MEM_ALIGN_SIZE(MEM_SIZE)lwIP 内核为了有效防止内存碎片,它定义了最小分配大小 MIN_SIZE(12),若用户申请的内存 小于最小分配内存,则系统分配 MIN_SIZE 大小的内存资源。往下的宏定义是对内存大小进 行 4 字节对齐。注:内存对齐的作用:1,平台原因:不是全部的硬件平台都能访问随意地址 上的随意类型数据的;某些硬件平台仅仅能在某些地址处取某些特定类型的数据,否则抛出硬 件异常。2,性能原因:经过内存对齐后,CPU 的内存访问速度大大提升。
(3)定义内存堆空间
ifndef LWIP_RAM_HEAP_POINTER
/*定义堆内存空间*/
LWIP_DECLARE_MEMORY_ALIGNED(ram_heap, MEM_SIZE_ALIGNED +
(2U*SIZEOF_STRUCT_MEM));
#define LWIP_RAM_HEAP_POINTER ram_heap
#endif无论是内存堆还是内存池,它们都是对一个大数组进行操作,上述的宏定义就是指向一个 名为 ram_heap 数组,该数组的大小为 MEM_SIZE_ALIGNED + (2U*SIZEOF_STRUCT_MEM), lwIP 内存堆申请的内存就是从这个数组分配得来的。
(4)操作内存堆的变量
/* 指向对齐后的内存堆的地址*/
static u8_t *ram;
/* 指向对齐后的内存堆的最后一个内存块 */
static struct mem *ram_end;
/* 指向已被释放的索引号最小的内存块(内存堆最前面的已被释放的)*/
static struct mem * LWIP_MEM_LFREE_VOLATILE lfree;ram_heap 数组就是 lwIP 定义的内存堆总空间,如何从这个总空间申请合适大小的内存, 就是利用上述源码的三个指针,ram 指针指向对齐后的内存堆总空间首地址,ram_end 指针指向内存堆总空间尾地址(接近总空间的尾地址),而 lfree 指针指向最低内存地址的空闲内存块。 注:lwIP 内核就是根据 lfree 指针指向空闲内存块来分配内存,而 ram_end 指针用来检测该总 内存堆空间是否有空闲的内存。
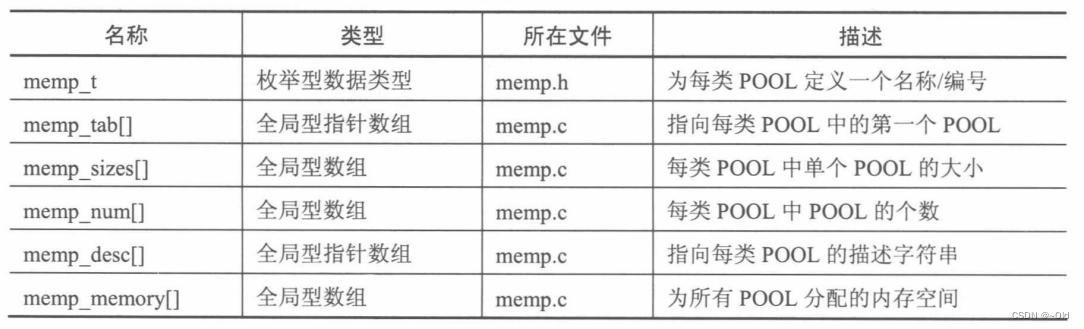
| 名称 | 类型 | 所在文件 | 描述 |
| ram_heap[] | 全局型数组 | mem.c | 系统内存堆空间 |
| ram | 全局型指针 | mem.c | 指向内存堆对齐后的起始地址 |
| mem | 结构体 | mem.c | 内核附加在各个内存开前面的控制结构体 |
| ram_end | mem型指针 | mem.c | 指向系统的最后一个内存块 |
| lfree | mem型指针 | mem.c | 指向当前系统具有最低地址的空闲内存块 |
| mem_mutex | 互斥量 | mem.c | 用于保护内存堆的互斥信号量,暂时没用到 |
内存堆的组织结构如下图所示:

函数实现
1、内存堆的初始化:mem_init函数
void
mem_init(void)
{
struct mem *mem;
LWIP_ASSERT("Sanity check alignment",
(SIZEOF_STRUCT_MEM & (MEM_ALIGNMENT - 1)) == 0);
/* 对内存堆的地址(全局变量名)进行对齐指向ram_heap */
ram = (u8_t *)LWIP_MEM_ALIGN(LWIP_RAM_HEAP_POINTER);
/* 建立第一个内存块,内存块由内存块头+空间组成 */
mem = (struct mem *)(void *)ram;
/* 下一个内存块不存在,因此指向内存堆的结束 */
mem->next = MEM_SIZE_ALIGNED;
/*前一个内存块就是它自己,因为这是第一个内存块*/
mem->prev = 0;
/*第一个内存块没有被使用*/
mem->used = 0;
/*初始化堆的末端(指向MEM_SIZE_ALIGNED底部位置)*/
ram_end = ptr_to_mem(MEM_SIZE_ALIGNED);
/*最后一个内存块被使用,因为其后面没有可用的空间,必须标记为已被使用*/
ram_end->used = 1;
/*下一个不存在,因此指向内存堆的结束*/
ram_end->next = MEM_SIZE_ALIGNED;
/*前一个不存在,因此指向内存堆的结束*/
ram_end->prev = MEM_SIZE_ALIGNED;
MEM_SANITY();
/*已释放的索引最小的内存块就是上面建立的第一个内存块*/
lfree = (struct mem *)(void *)ram;
MEM_STATS_AVAIL(avail, MEM_SIZE_ALIGNED);
/*这里建立一个互斥信号量,主要是用来进行内存的申请、释放的保护*/
if (sys_mutex_new(&mem_mutex) != ERR_OK) {
LWIP_ASSERT("failed to create mem_mutex", 0);
}
}上述源码就是对堆空间初始化,一开始lfree指针指向第一个内存块,该内存块有两个部分组成,一个是控制块(struct mem大小,标志管理的内存是否可用),另一个是可用内存。ram_end指针指向尾内存块,它用来标志这个堆空间是否有可用内存,若lfree指针指向ram_end指针,则该堆空间没有可用内存分配,由此可以看出,lfree指针从堆空间低地址不断查找和划分内存,最终在ram_end指针指向的地址结束分配。内存堆初始化示意图如下所示:
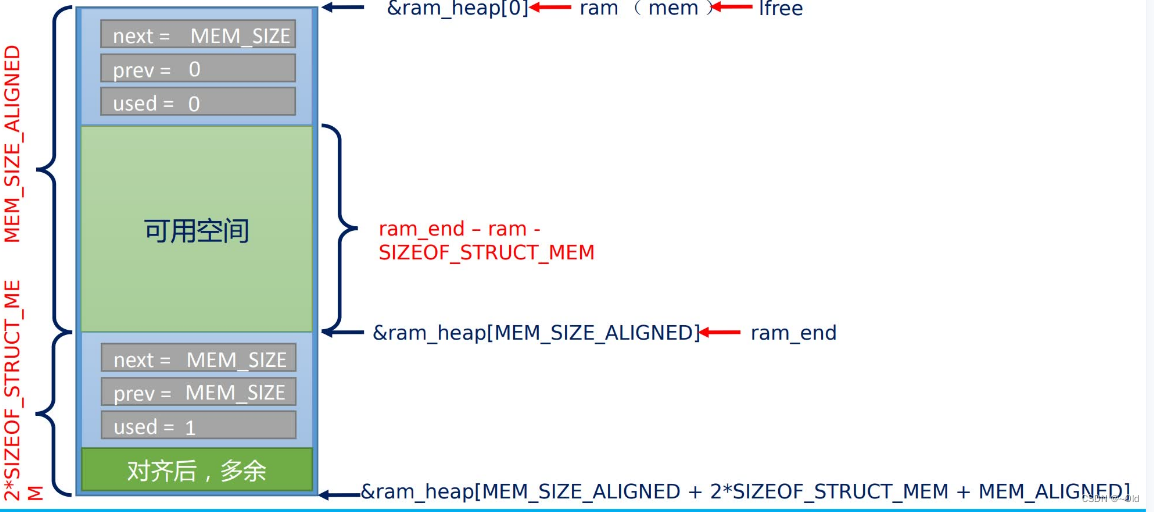
注意:struct mem结构体的next和prev变量并不是指针类型,它们保存的是内存块的索引,例如定义一个a[10]数组,next和prev保存的是0~9的索引号,LwIP内核根据索引号获取a数组索引的地址(&a[0~9])。
2、mem_malloc函数
void *
mem_malloc(mem_size_t size_in)
{
mem_size_t ptr, ptr2, size;
struct mem *mem, *mem2;
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
u8_t local_mem_free_count = 0;
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
LWIP_MEM_ALLOC_DECL_PROTECT();
if (size_in == 0) {
return NULL;
}
/* 获取你要分配的内存的大小 */
size = (mem_size_t)LWIP_MEM_ALIGN_SIZE(size_in);
if (size < MIN_SIZE_ALIGNED) {
/*内存堆有一个最小分配单元为12 */
size = MIN_SIZE_ALIGNED;
}
#if MEM_OVERFLOW_CHECK
size += MEM_SANITY_REGION_BEFORE_ALIGNED + MEM_SANITY_REGION_AFTER_ALIGNED;
#endif
if ((size > MEM_SIZE_ALIGNED) || (size < size_in)) {
return NULL;
}
/* 内存堆的保护 */
sys_mutex_lock(&mem_mutex);
LWIP_MEM_ALLOC_PROTECT();
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
/* run as long as a mem_free disturbed mem_malloc or mem_trim */
do {
local_mem_free_count = 0;
#endif /* 上面的代码主要两个功能:1检测用户申请的内存块是否满足LwIP规则
2从内存堆中划分用户的内存块 */
/* 寻找足够大的空闲块,从最低的空闲块开始*/
for (ptr = mem_to_ptr(lfree); ptr < MEM_SIZE_ALIGNED - size;
ptr = ptr_to_mem(ptr)->next) {
mem = ptr_to_mem(ptr); /*根据索引,取它的地址*/
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_free_count = 0;
LWIP_MEM_ALLOC_UNPROTECT();
/* allow mem_free or mem_trim to run */
LWIP_MEM_ALLOC_PROTECT();
if (mem_free_count != 0) {
/* If mem_free or mem_trim have run, we have to restart since they
could have altered our current struct mem. */
local_mem_free_count = 1;
break;
}
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
if ((!mem->used) &&
(mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size) {
/* 这个地方需要判断,剩余的内存块是否可以申请size的内存块 */
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >= (size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED)) {
/*上面注释一大堆是说:剩余内存可能连一个内存块头部都放不下了,这个时候
就没法新建内存块,其索引也就不能移动*/
/*指向申请后的位置,即:建立下一个未使用的内存块的头部,即:插入一个新的空内存块*/
ptr2 = (mem_size_t)(ptr + SIZEOF_STRUCT_MEM + size);
LWIP_ASSERT("invalid next ptr",ptr2 != MEM_SIZE_ALIGNED);
/* 从Ptr2地址开始新建mem2结构体 */
mem2 = ptr_to_mem(ptr2); /*调用struct mem将索引转为地址*/
mem2->used = 0;
/*这个根据下面的if(mem->next != MEM_SIZE_ALIGNED)判定*/
mem2->next = mem->next;
mem2->prev = ptr;
/* 前一个内存块指向上面建立的空闲内存块 */
mem->next = ptr2;
mem->used = 1; /*将当前分配的内存块标记为已使用*/
/* 如果 mem2 内存块的下一个内存块不是链表中最后一个内存块 (结束地址),
那就将它下一个的内存块的 prve 指向 mem2 */
if (mem2->next != MEM_SIZE_ALIGNED) {
ptr_to_mem(mem2->next)->prev = ptr2;
}
MEM_STATS_INC_USED(used, (size + SIZEOF_STRUCT_MEM));
} else {
/* 内存块太小了会产生的碎片 */
mem->used = 1;
MEM_STATS_INC_USED(used, mem->next - mem_to_ptr(mem));
}
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_malloc_adjust_lfree:
#endif /* 这里处理:当分配出去的内存正好是 lfree 时,
因为该内存块已经被分配出去了,
必须修改 lfree 的指向下一个最其前面的已释放的内存块*
if (mem == lfree) {
struct mem *cur = lfree;
/* 只要内存块已使用且没到结尾,则继续往后找 */
while (cur->used && cur != ram_end) {
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_free_count = 0;
LWIP_MEM_ALLOC_UNPROTECT();
/* prevent high interrupt latency... */
LWIP_MEM_ALLOC_PROTECT();
if (mem_free_count != 0) {
/* If mem_free or mem_trim have run, we have to restart since they
could have altered our current struct mem or lfree. */
goto mem_malloc_adjust_lfree;
}
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
cur = ptr_to_mem(cur->next); /*下一个内存块*/
}
/* 指向找到的 第一个已释放的内存块。如果上面没有找到,则 lfree = lfree 不变 */
lfree = cur;
LWIP_ASSERT("mem_malloc: !lfree->used", ((lfree == ram_end) || (!lfree->used)));
}
LWIP_MEM_ALLOC_UNPROTECT();
sys_mutex_unlock(&mem_mutex);
LWIP_ASSERT("mem_malloc: allocated memory not above ram_end.",
(mem_ptr_t)mem + SIZEOF_STRUCT_MEM + size <= (mem_ptr_t)ram_end);
LWIP_ASSERT("mem_malloc: allocated memory properly aligned.",
((mem_ptr_t)mem + SIZEOF_STRUCT_MEM) % MEM_ALIGNMENT == 0);
LWIP_ASSERT("mem_malloc: sanity check alignment",
(((mem_ptr_t)mem) & (MEM_ALIGNMENT - 1)) == 0);
#if MEM_OVERFLOW_CHECK
mem_overflow_init_element(mem, size_in);
#endif
MEM_SANITY();
/* 这里返回内存块的空间的地址,排除内存块的头 */
return (u8_t *)mem + SIZEOF_STRUCT_MEM + MEM_SANITY_OFFSET;
}
}
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
/* if we got interrupted by a mem_free, try again */
} while (local_mem_free_count != 0);
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
MEM_STATS_INC(err);
LWIP_MEM_ALLOC_UNPROTECT();
sys_mutex_unlock(&mem_mutex);
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SERIOUS, ("mem_malloc: could not allocate %"S16_F" bytes\n", (s16_t)size));
return NULL;
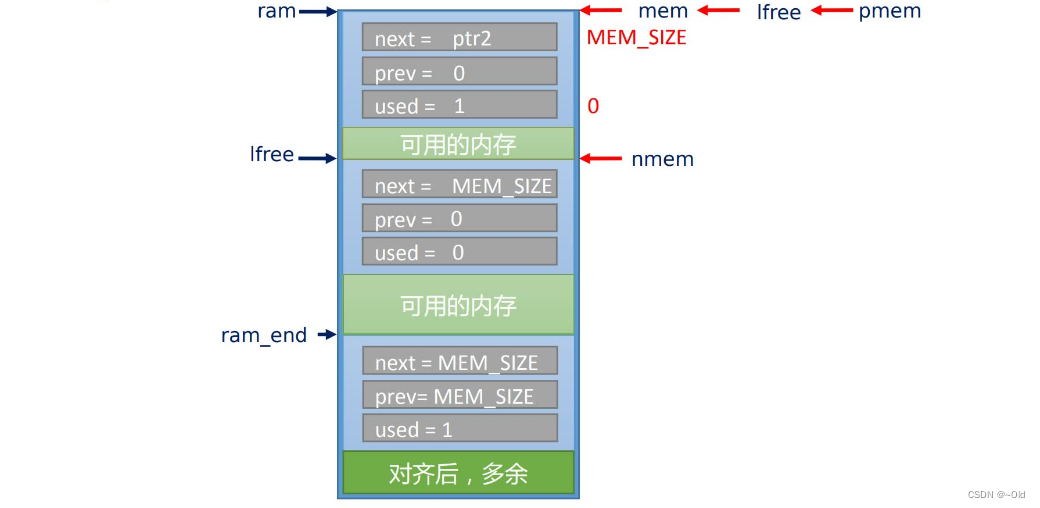
}从上述源码可以看出,lwIP 内存堆申请的内存是从低地址往高地址方向查找合适的内存 块,每一个内存块由两个部分组成,一个是(struct mem)大小的内存块,它用来描述和管理 可用的内存块,另一个是可用内存块,用户可直接操作它。根据上图 4.2.1 图解可以看出, lfree 指针指向的是未被使用的控制块,若用户申请 size 大小的内存,则 lwIP 内核会把 lfree 指 针指向的控制块标志为已用内存,并且往高地址偏移(struct mem)结构体+对齐后的 size 大 小,偏移完成之后 lfree 指针指向的地址附加一个 struct mem 结构体(下一个控制块)。注:下 一个控制块被标志为未使用即 used=0,至此我们可以得到以下示意图。

3、mem_free函数
void
mem_free(void *rmem)
{
struct mem *mem;
LWIP_MEM_FREE_DECL_PROTECT();
/*第一步:检查内存块的参数*/
/*判断释放的内存块释放为空*/
if (rmem == NULL) {
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_TRACE | LWIP_DBG_LEVEL_SERIOUS, ("mem_free(p == NULL) was called.\n"));
return; /*为空则返回*/
}
if ((((mem_ptr_t)rmem) & (MEM_ALIGNMENT - 1)) != 0) {
LWIP_MEM_ILLEGAL_FREE("mem_free: sanity check alignment");
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SEVERE, ("mem_free: sanity check alignment\n"));
/* protect mem stats from concurrent access */
MEM_STATS_INC_LOCKED(illegal);
return;
}
/* Get the corresponding struct mem: */
/* 除去指针就剩下内存块了,通过mem_malloc的到的地址是否不含struct mem的 */
mem = (struct mem *)(void *)((u8_t *)rmem - (SIZEOF_STRUCT_MEM + MEM_SANITY_OFFSET));
if ((u8_t *)mem < ram || (u8_t *)rmem + MIN_SIZE_ALIGNED > (u8_t *)ram_end) {
LWIP_MEM_ILLEGAL_FREE("mem_free: illegal memory");
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SEVERE, ("mem_free: illegal memory\n"));
/* protect mem stats from concurrent access */
MEM_STATS_INC_LOCKED(illegal);
return;
}
#if MEM_OVERFLOW_CHECK
mem_overflow_check_element(mem);
#endif
/* protect the heap from concurrent access */
LWIP_MEM_FREE_PROTECT();
/* mem has to be in a used state */
if (!mem->used) {
LWIP_MEM_ILLEGAL_FREE("mem_free: illegal memory: double free");
LWIP_MEM_FREE_UNPROTECT();
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SEVERE, ("mem_free: illegal memory: double free?\n"));
/* protect mem stats from concurrent access */
MEM_STATS_INC_LOCKED(illegal);
return;
}
if (!mem_link_valid(mem)) {
LWIP_MEM_ILLEGAL_FREE("mem_free: illegal memory: non-linked: double free");
LWIP_MEM_FREE_UNPROTECT();
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SEVERE, ("mem_free: illegal memory: non-linked: double free?\n"));
/* protect mem stats from concurrent access */
MEM_STATS_INC_LOCKED(illegal);
return;
}
/* 第二步:查找指定的内存块,标记为未使用 */
mem->used = 0;
/*第三步:需要移动全局的释放指针,因为lfree始终指向内存堆中最小索引的那个已经释放的内存块*/
if (mem < lfree) {
/* 新释放的结构现在是最低的 */
lfree = mem;
}
MEM_STATS_DEC_USED(used, mem->next - (mem_size_t)(((u8_t *)mem - ram)));
/* finally, see if prev or next are free also */
plug_holes(mem);
MEM_SANITY();
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_free_count = 1;
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
LWIP_MEM_FREE_UNPROTECT();
}
lwIP 内存堆释放内存是非常简单的,它一共分为三个步骤,第一、检测传入的地址是否 正确,第二、对这个地址进行偏移,偏移大小为 struct mem,这样可以得到释放内存的控制块 首地址,并且设置该控制块为未使用标志,第三、判断该控制块的地址是否小于 lfree 指针指 向的地址,若小于,则证明 mem 的内存块在 lfree 指向的内存块之前即更接近堆空间首地址, 系统会把 lfree 指针指向这个释放的内存块(控制块 + 可用内存),以后申请内存时会在 lfree 指针的内存块开始查找合适的内存。注:申请内存时 lwIP 内核会从 lfree 指针指向的内存块开 始查找,若该内存块不满足申请要求,则 lwIP 内核根据这个内存块的 next 变量保存的数值作 为下一跳查询的地址。
 以不变应万变——动态内存池
以不变应万变——动态内存池
动态内存池分配策略可以说是一个比较笨的分配策略了,但其分配策略实现简单,内存的分配、释放效率高,可以有效防止内存碎片的产生。这种方式下,用户只能申请固定大小的空间,在LwIP中,这种方式主要用于内核中固定数据结构的分配,例如UDP控制块,TCP控制块等,内核在初始化时已经为每个数据结构类型都初始化好了一定数量的POOL。源文件memp.c和memp.h文件包含了实现动态内存池分配策略的所有数据结构和函数。
数据结构描述
为什么叫POOL?这点很有趣,内核初始化的POOL有很多种,每种类型的数据结构都会针对应一种POOL,这点依赖于用户,系统配置LwIP内核的方式(在lwipopts.h和opt.h文件中)。例如,在头文件opt.h中定义了宏LWIP_UDP为1,在编译时与UDP控制块数据结构相关的内存池POOL(MEMP_UDP_PCB就会被建立) ,定义了LWIP_TCP为1,同理。

实现LwIP内存池的文件
memp_priv.h:定义memp和memp_desc结构体
/*管理内存块*/
struct memp {
struct memp *next;
#if MEMP_OVERFLOW_CHECK
const char *file;
int line;
#endif /* MEMP_OVERFLOW_CHECK */
};/*管理和描述各类型得内存池*/
struct memp_desc {
#if defined(LWIP_DEBUG) || MEMP_OVERFLOW_CHECK || LWIP_STATS_DISPLAY
/** Textual description */
const char *desc;
#endif /* LWIP_DEBUG || MEMP_OVERFLOW_CHECK || LWIP_STATS_DISPLAY */
#if MEMP_STATS
/** Statistics */
struct stats_mem *stats;
#endif
/** 每个内存块大小*/
u16_t size;
#if !MEMP_MEM_MALLOC
/** 内存块得数量 */
u16_t num;
/** 指向内存得基地址*/
u8_t *base;
/** 每个池得第一个空闲元素,元素形成一个链表. */
struct memp **tab;
#endif /* MEMP_MEM_MALLOC */
};这个文件主要定义了两个结构体,它们分别为memp和memp_desc结构体,其中memp结构体是把同一类型得内存池以链表得形式链接起来,而memp_desc结构体是用来管理和描述各类型得内存池,如数量、大小、内存池得起始地址和指向空闲内存池的指针。memp和memp_desc结构体的关系如下图。

从上图可以看出,每个描述符都是用来管理同一类型的内存池,而这些内存池即内存块是以链表的形式链接起来。
memp_std.h:申请所需的内存池,该文件定义了LwIP内核所需得内存池,由于LwIP内核得固定数据结构多种多样,所以使用宏定义声明是否使用该类型得内存池,如TCP、UDP、ICMP等协议。这些宏定义一般在lwipopts.h文件中声明启用,该文件得源码如下所示:
#if LWIP_RAW
LWIP_MEMPOOL(RAW_PCB, MEMP_NUM_RAW_PCB, sizeof(struct raw_pcb), "RAW_PCB")
#endif /* LWIP_RAW */
从上述得源码中可以看出两点重要内容:1、不同类型得内存池是由相应得宏定义声明启用 2、LWIP_MEMPOOL宏定义用来初始化各类型的内存池
memp.h:声明宏定义以及函数提供外部文件使用
typedef enum {
#define LWIP_MEMPOOL(name,num,size,desc) MEMP_##name,
#include "lwip/priv/memp_std.h"
MEMP_MAX
} memp_t;
这个枚举类型就是为了获取MEMP_MAX的数值 ,同时为系统将用的各个类型的POOL取一个好看、好记得名字(或者为每个类型POOL编一个号)。这里需要说明的是这里##在C语言中是连接符,这里LwIP作者代码编写能力非常高超。
#define LWIP_MEMPOOL_DECLARE(name,num,size,desc) \
LWIP_DECLARE_MEMORY_ALIGNED(memp_memory_ ## name ## _base, ((num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))); \
\
LWIP_MEMPOOL_DECLARE_STATS_INSTANCE(memp_stats_ ## name) \
\
static struct memp *memp_tab_ ## name; \
\
const struct memp_desc memp_ ## name = { \
DECLARE_LWIP_MEMPOOL_DESC(desc) \
LWIP_MEMPOOL_DECLARE_STATS_REFERENCE(memp_stats_ ## name) \
LWIP_MEM_ALIGN_SIZE(size), \
(num), \
memp_memory_ ## name ## _base, \
&memp_tab_ ## name \
};
此宏定义非常重要,各类型的内存池都使用这个宏定义声明,例如内存池的内存由来,各 类型内存池的数量、大小、内存由来的地址以及指向空闲的指针。这个宏定义展开后如下源码 所示:
#define LWIP_MEMPOOL_DECLARE(name,num,size,desc) \
u8_t memp_memory_ ## name ## _base[((((((num) * (MEMP_SIZE + (((size) +
MEM_ALIGNMENT - 1U) & ~(MEM_ALIGNMENT-1U))))) + MEM_ALIGNMENT -
1U)))];\
static struct memp *memp_tab_ ## name;\
const struct memp_desc memp_ ## name = { \
LWIP_MEM_ALIGN_SIZE(size), \
(num), \
memp_memory_ ## name ## _base, \
&memp_tab_ ## name \
};展开之后可以看出,各类型的内存池的内存由来和 lwIP 内存堆一样,都是由数组分配的。 这个宏定义的使用会在 memp.c 文件中讲解
memp.c:编写相关分配内存池以及回收资源函数
函数实现
memp_init函数
void
memp_init(void)
{
u16_t i;
/*遍历需要多少个内存池: */
for (i = 0; i < LWIP_ARRAYSIZE(memp_pools); i++) {
memp_init_pool(memp_pools[i]);
#if LWIP_STATS && MEMP_STATS
lwip_stats.memp[i] = memp_pools[i]->stats;
#endif
}
#if MEMP_OVERFLOW_CHECK >= 2
/* check everything a first time to see if it worked */
memp_overflow_check_all();
#endif /* MEMP_OVERFLOW_CHECK >= 2 */
}memp_init_pool函数
void
memp_init_pool(const struct memp_desc *desc)
{
#if MEMP_MEM_MALLOC
LWIP_UNUSED_ARG(desc);
#else
int i;
struct memp *memp;
*内存对齐;
memp = (struct memp *)LWIP_MEM_ALIGN(desc->base);
#if MEMP_MEM_INIT
/* force memset on pool memory */
memset(memp, 0, (size_t)desc->num * (MEMP_SIZE + desc->size
#if MEMP_OVERFLOW_CHECK
+ MEM_SANITY_REGION_AFTER_ALIGNED
#endif
));
#endif
/* 将内存块链接成链表形式 */
for (i = 0; i < desc->num; ++i) {
memp->next = *desc->tab;
*desc->tab = memp;
#if MEMP_OVERFLOW_CHECK
memp_overflow_init_element(memp, desc);
#endif /* MEMP_OVERFLOW_CHECK */
/* 地址偏移 */
memp = (struct memp *)(void *)((u8_t *)memp + MEMP_SIZE + desc->size
#if MEMP_OVERFLOW_CHECK
+ MEM_SANITY_REGION_AFTER_ALIGNED
#endif
);
}
#if MEMP_STATS
desc->stats->avail = desc->num;
#endif /* MEMP_STATS */
#endif /* !MEMP_MEM_MALLOC */
#if MEMP_STATS && (defined(LWIP_DEBUG) || LWIP_STATS_DISPLAY)
desc->stats->name = desc->desc;
#endif /* MEMP_STATS && (defined(LWIP_DEBUG) || LWIP_STATS_DISPLAY) */
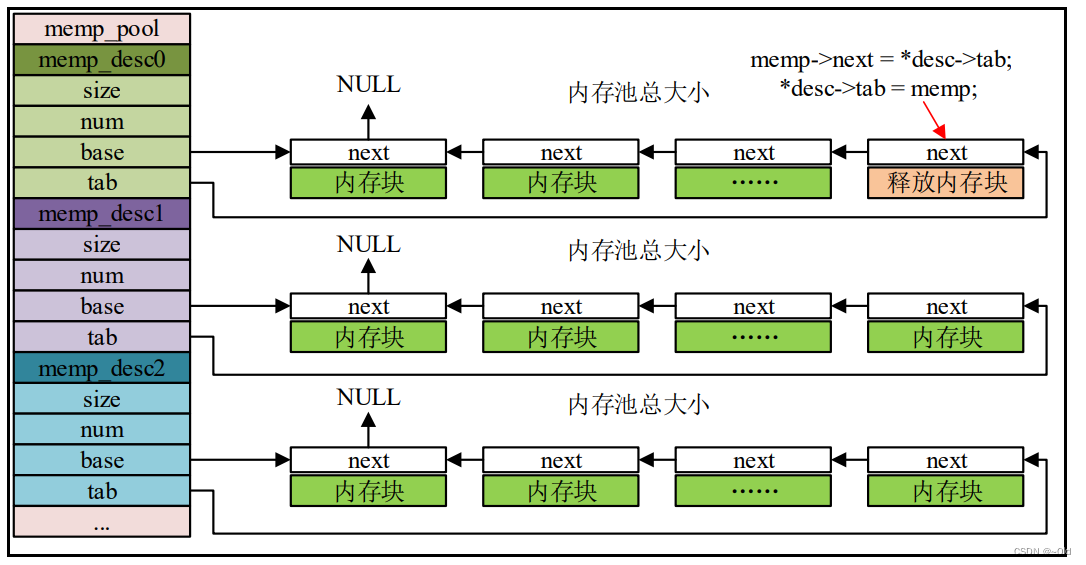
}从上述源码可以看出,每一个类型的描述符都是用来管理和描述该类型的内存池,这些同 一类型的内存池里面包含了指向下一个节点的指针,根据第二个 for 循环语句让这些同一类型 的内存池以链表的形式链接起来,最后不断的循环,我们可以得到以下示意图:

从上图可知,memp_pool 数组包含了多个类型的内存池描述符,这些描述符管理同一类型 的内存池,这些内存池以链表的形式链接起来,最后形成一个单向链表。注:同一类型的内存 池都是在同一个数组分配得来,而 base 指针指向该数组的首地址,tab 指针指向第一个空闲的 内存池,若用户向申请一个内存池,则从 tab 指针指向的内存池分配,分配完成之后 tab 指针 偏移至下一个空闲内存池的地址。
memp_malloc函数和memp_malloc_pool 函数
void *
#if !MEMP_OVERFLOW_CHECK
memp_malloc(memp_t type)
#else
memp_malloc_fn(memp_t type, const char *file, const int line)
#endif
{
void *memp;
LWIP_ERROR("memp_malloc: type < MEMP_MAX", (type < MEMP_MAX), return NULL;);
#if MEMP_OVERFLOW_CHECK >= 2
memp_overflow_check_all();
#endif /* MEMP_OVERFLOW_CHECK >= 2 */
#if !MEMP_OVERFLOW_CHECK
memp = do_memp_malloc_pool(memp_pools[type]);
#else
memp = do_memp_malloc_pool_fn(memp_pools[type], file, line);
#endif
return memp;
}
memp_malloc 函数需要传入申请内存池的类型,如 UDP_PCB…,接着根据传入的类型来 查找对应的内存池描述符,查找完成之后根据该内存池描述符的 tab 指针指向内存池分配给用 户,并且把 tab 指针偏移至下一个空闲内存池。分配流程如下图所示:

memp_free 函数与 memp_free_pool 函数
内存池释放函数非常简单,它需要传入两个形参,第一个是释放内存池的类型,第二个是 释放内存池的地址。lwIP 内核根据这两个形参就可以知道该类型的内存池描述符位置和该类 型内存池描述符的哪个内存池需要释放。内存池释放函数如下所示:
void
memp_free_pool(const struct memp_desc *desc, void *mem)
{
LWIP_ASSERT("invalid pool desc", desc != NULL);
if ((desc == NULL) || (mem == NULL)) {
return;
}
do_memp_free_pool(desc, mem);
}
/**
* Put an element back into its pool.
*
* @param type the pool where to put mem
* @param mem the memp element to free
*/
void
memp_free(memp_t type, void *mem)
{
#ifdef LWIP_HOOK_MEMP_AVAILABLE
struct memp *old_first;
#endif
LWIP_ERROR("memp_free: type < MEMP_MAX", (type < MEMP_MAX), return;);
if (mem == NULL) {
return;
}
#if MEMP_OVERFLOW_CHECK >= 2
memp_overflow_check_all();
#endif /* MEMP_OVERFLOW_CHECK >= 2 */
#ifdef LWIP_HOOK_MEMP_AVAILABLE
old_first = *memp_pools[type]->tab;
#endif
do_memp_free_pool(memp_pools[type], mem);
#ifdef LWIP_HOOK_MEMP_AVAILABLE
if (old_first == NULL) {
LWIP_HOOK_MEMP_AVAILABLE(type);
}
#endif
}
使用C库管理内存策略
LwIP内核是可以支持C标准库管理策略,它与LwIP内存堆管理策略二者只能选择其一,打开mem.c文件找到MEM_LIBC_MALLOC配置项如下源码所示:
#if MEM_LIBC_MALLOC
/* lwIP heap implemented using C library malloc() */
/* in case C library malloc() needs extra protection,
* allow these defines to be overridden.
*/
#ifndef mem_clib_free
#define mem_clib_free free
#endif
#ifndef mem_clib_malloc
#define mem_clib_malloc malloc
#endif
#ifndef mem_clib_calloc
#define mem_clib_calloc calloc
#endif
#if LWIP_STATS && MEM_STATS
#define MEM_LIBC_STATSHELPER_SIZE LWIP_MEM_ALIGN_SIZE(sizeof(mem_size_t))
#else
#define MEM_LIBC_STATSHELPER_SIZE 0
#endif上述的free、malloc以及calloc就是C库中的内存管理函数,注意:C标准库内存管理不能与相邻的空闲内存块合并,且容易造成内存碎片。











![SpringSecurity[5]-基于表达式的访问控制/基于注解的访问控制/Remember Me功能实现](https://img-blog.csdnimg.cn/a886154fde4e41619062cccc238fd14d.png)