两阶段提交 2PC
在MySQL InnoDB中,为了保证Bin Log和Redo Log的一致性,便采用了两阶段提交;ZooKeeper、ETCD集群为了保证数据一致性,也采用了两阶段提交,RocketMQ的事务消息也采用了两阶段提交,可见两阶段提交是分布式事务中比较常用的解决方案。
MySQL InnoDB中的两阶段提交
我们看下在MySQL InnoDB是如何采用两阶段提交是保证Bin Log和Redo Log的一致性的:

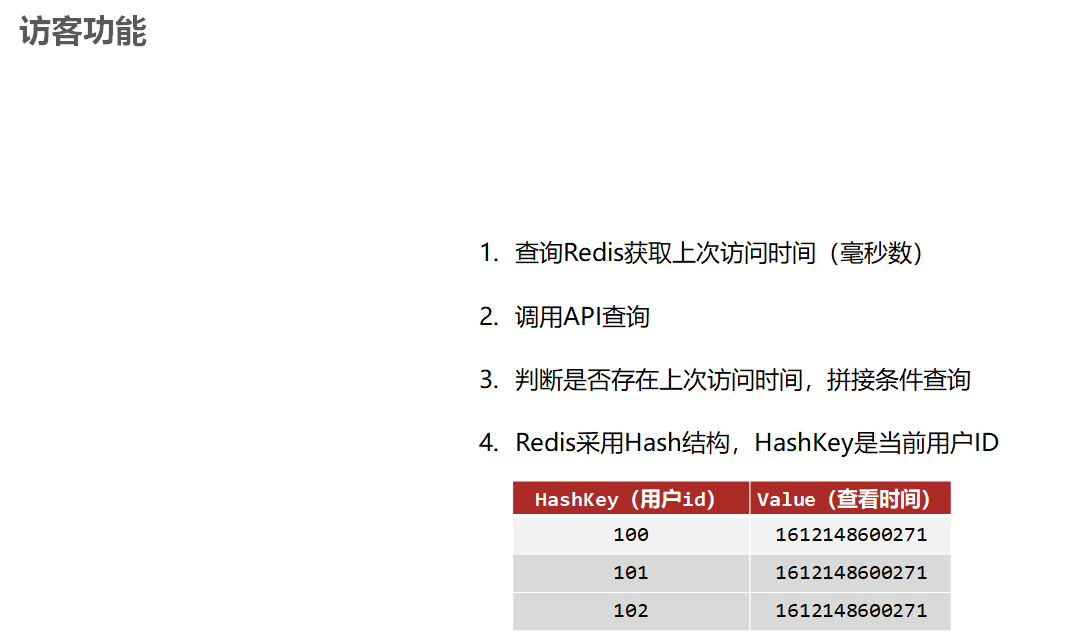
- 收到客户端的数据操作请求后,MySQL InnoDB会在内存中完成数据更新;
- 写Redo Log,此时Redo Log的状态为Prepare;
- 写Bin Log,此时Redo Log的状态不变,还是为Prepare;
- 提交事务,此时Redo Log的状态为Commit;
由于本篇博客,重点不在于MySQL,所以就不介绍为什么需要Bin Log和Redo Log两种日志了,只需要知道只有这样才可以保证数据的一致性,而且可以看出Redo Log有两种状态:Prepare、Commit,这两种状态便是两阶段提交的核心。有了这个基础,我们就可以来看看两阶段提交的概念了。
两阶段提交 2PC

两阶段提交把一个操作分为了Prepare、Commit/Rollback两个阶段:
- 事务协调器向多个本地资源管理器发起Prepare请求;
- 本地资源管理器收到事务协调器的Prepare请求,会执行自身的操作,但是不会真正生效,随后会响应事务协调器;
- 如果事务协调器在一定时间内,收到所有本地资源管理器的Prepare响应,会向本地资源管理器发起Commit请求,如果事务协调器在一定时间内,没有收到所有本地资源管理器的Prepare响应,会向本地资源管理器发起Rollback请求;
- 如果本地资源管理器收到的是事务协调器的Commit请求,会提交自身的操作,使其真正生效;如果本地资源管理器收到的是事务协调器的Rollback请求,会回滚自身的操作;
- 不管本地资源管理器执行的是Commit操作,还是Rollback操作,都会响应事务协调器。
事务协调器也被称之为“TC”,本地资源管理器也被称之为“RM”。
关于两阶段提交,网上有很多说法都不太一样,因为这仅仅是一个思想,是一个理论,不同的人有不同的理解,真正做起来,也会有不同的实现,比如【本地资源管理器收到事务协调器的Prepare请求,会执行自身的操作】,【本地资源管理器收到事务协调器的Commit请求后,会提交自身的操作】这两个操作:
- 本地资源管理器收到事务协调器的Prepare请求,可以是开启一个本地事务,执行自身的业务逻辑,但是不提交事务,当本地资源管理器收到事务协调器的Commit请求后,才会提交事务;当本地资源管理器收到事务协调器的Rollback请求后,会回滚事务。这种是传统的两阶段提交实现方式,事务可能比较长,也会长时间占用数据库资源,性能比较低下,但是可靠性比较高。
- 本地资源管理器收到事务协调器的Prepare请求,可以将业务逻辑的反操作记录下来(相当于Undo Log),随后释放数据库资源,当资源管理器收到事务协调器的Commit请求后,这条反操作记录就无效了(因为操作成功了,不会利用这反操作记录进行数据的恢复了);当本地资源管理器收到事务协调器的Rollback请求,可以利用反操作记录来进行数据的回滚。如果是这种实现,不会长时间占用数据库资源,性能可能会有所提高,可靠性会相对差一些(这就是Seata AT模式的实现)。
虽说两阶段提交有不同的实现,但是整体上一定分为Prepare、Commit/Rollback这两个阶段。
传统的两阶段提交存在下以下几个问题:
- 性能低下:传统的两阶段提交会长时间占用数据库资源,直到Commit/Rollback才释放;
- 事务协调器故障:如果事务协调器挂了,怎么办?特别是在第二阶段,本地资源管理器在等待事务协调器的Commit/Rollback请求,此时事务协调器挂了,那本地资源管理器就会处于“悬而未决”的“懵逼”状态;
- 某个本地资源管理器Commit/Rollback失败,怎么办?
- 使用场景限制:一般来说,传统的两阶段提交是基于事务的,所以需要数据库支持事务,如果业务逻辑中有对Redis、Mongo、ES的操作,传统的两阶段提交就不太适用了。
讲道理,在介绍完两阶段提交后,应该要介绍三阶段提交了,但是两阶段提交存在的问题,在三阶段提交中,并没有改善多少(也有可能是我没有领悟出来),所以就不介绍三阶段提交了。
TCC
TCC是支付宝提出的,是两阶段提交的变种,TCC是三个单词的缩写:Try、Confirm、Cancel。Confirm对应两阶段提交中的Commit,Cancel对应两阶段提交中的Rollback。


如图所示:
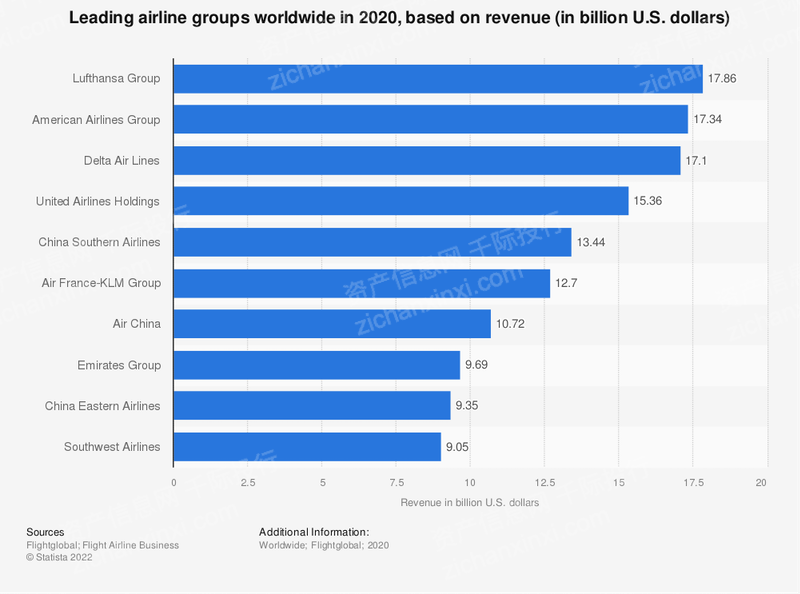
- 调用方会向所有服务提供方发起Try请求,服务提供方根据业务要求,做一系列操作:比如检查数据、锁定资源等,然后会响应调用方;
- 如果在一定时间内,调用方收到了所有服务提供方的Try响应,会向所有服务提供方发起Confirm请求,服务提供方收到Confirm请求后,执行自身的业务逻辑。
但是“天佑不测风云,人有祸福旦夕”,不可能总是一帆风顺,如果在一定时间内,调用方没有收到服务提供方的Try响应或者收到了服务提供方的“Try-No”响应,调用方会向所有服务提供方发起Cancel请求:

以前我一直不太明白,如果在一定时间内,调用方没有收到服务提供方的Try响应或者收到了服务提供方的“Try-No”响应,为什么调用方还要向所有服务提供方发起Cancel请求,直接不管不就可以了,反正服务提供方还没有真正执行业务逻辑?因为在Try阶段,服务提供方可能做了锁定资源的操作,所以需要通知服务提供方,让其释放资源。
TCC在一定程度上解决2PC的缺陷:
- 如果某个服务提供方Confirm、Cancel失败了,通过TCC框架可以不停的重试,直到成功;
- TCC并非是基于数据库事务的,所以没有使用场景的限制;
- TCC并非是基于数据库事务的,不会长时间占用数据库资源。
那TCC是不是完美的解决方案呢?也不是,TCC在一定程度上解决2PC的缺陷的同时,又新增了缺陷:
- 服务提供方需要提供Try、Confirm、Cancel三个接口,代码侵入性比较强,比较繁琐;
- 由于没有数据库事务的概念,所以难以保证数据的一致性。
不管是采用2PC,还是TCC,几乎都会引入框架,一旦引入框架,复杂度、学习成本、维护成本就成倍上升了,那有没有不需要框架,就可以解决分布式事务问题的方案呢?
基于事件状态表的检查+事后补偿

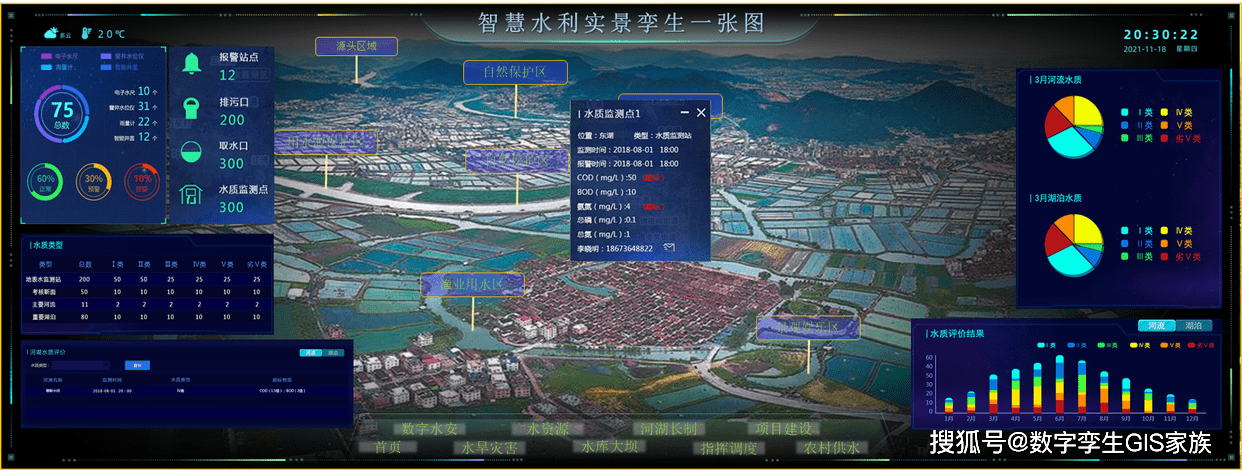
调用方依赖多个服务,如何做到一致性呢?可以新建一张事件状态表,核心字段如下:
- state:事务状态(执行中、执行成功、执行失败)
- content:事务内容
- 调用方先往事件状态表插入一条数据,state为“执行中”;
- 调用方调用各个接口;
- 如果调用一切正常,万事大吉,修改state为“执行成功”;
- 如果其中一个接口出现异常,修改state为“执行失败”;
- 通过定时任务的方式,扫描事件状态表,拿到需要重试(state为“执行中”/“执行失败”)的事务,调用接口,进行重试,重试成功,修改state为“执行成功”,重试失败,state不变。
你可能会问,如果调用接口正常,修改state失败,怎么办?大不了定时任务重试一次,但是需要事先和服务提供方沟通好,保证幂等性。
后台对账
- 异步消息对账,这个方案在可落地的分布式事务解决方案这篇博客中,已经介绍过了;
- 全量对账:定时任务对比多个库的全量数据;
- 增量对账:基于更新时间,对比多个库的增量数据。
还有一种比较“隐性”的场景,比如订单从“支付完成”到“商家确认”,一般不超过24小时,那就意味着,如果超过了24小时,可能就触发了异常场景,定时任务可以针对这种数据进行处理。
前台对账
举个例子,一般来说电商网站,热门商品的库存数据在数据库中有一份,在Redis也有一份,为了性能,商品详情中展示的库存,可能是Redis中的,到了扣减库存环节,既要扣除数据库中的库存,又要扣除Redis中的库存,数据库中的库存才是最可靠的,所以在执行扣减库存的操作的时候,会对比Redis中的库存和数据库中的库存,如果不一致,就用数据库中的库存覆盖Redis中的库存(当然也可以不管三十二十一,直接用数据库中的库存福覆盖Redis中的库存)。这种方案比较适合轻量级的业务操作,比如查库存、修改库存,都是很快、很轻的操作。
妥协方案:基于业务特性的弱一致性+基于事件状态表的检查+事后补偿
- TCC是一个同步的方案,有两个阶段,性能比较差;
- 基于事件状态表的检查+事后补偿,写事件状态表是一个同步的操作,而且需要两次操作事件状态表,性能比较差,事后补偿是一个事后的操作,及时性比较差;
- 后台对账是一个事后的操作,及时性比较差。
如果既要让系统之间最大限度的保证一致性,性能又不能太受影响,应该怎么办?
举个创建订单的例子,创建订单分为两步:创建订单、扣减库存。
一般来说,电商是不允许超卖发生的,因为超卖导致发不了货,会影响平台信誉,用户体验,平台可能还需要进行赔偿,所以宁愿多扣减库存,也不能少扣减库存,我们就可以利用这个特性,来设计我们的弱一致性方案:先扣减库存,再创建订单:
- 扣减库存成功,创建订单成功,没有任何问题;
- 扣减库存成功,创建订单失败,多扣减了库存;
- 扣减库存失败,不再创建订单。
但是库存多扣减了,怎么进行补偿呢?
一般来说,库存扣减会生成库存扣减记录,库存扣减记录有状态、时间两个字段,扣减库存后,库存扣减记录的状态为“占用中”,支付完成后,库存扣减记录的状态为“释放”。定时任务可以扫描长时间处于“占用中”的库存扣减记录,进行库存的回收,同时还可以取消订单。
妥协方案:重试+报警+人工补偿
调用方调用接口失败,重试一定的次数,如果最终还是失败的,就发送一条通知,人工干预。虽然这种方案很“丑陋”,但是非常实用,毕竟调用接口失败,是非常少见的。