写在前面
本文一起看下Redis cluster 集群模式下,发生了主从切换时可能存在的问题以及应对方案。
1:主从数据不一致
主从数据不一致,是由于主从同步延迟造成的,可能的解决方案如下:
1:尽量将主从同机房部署,减少网络延迟的影响,当因为数据高可用等原因无法同机房部署时,尽量给从节点更好的宽带资源
2:不要在从节点执行诸如SDIFFSTORE等集合操作,从而造成从节点计算压力大,造成主从同步慢
3:在从节点读取数据前,判断复制偏移量是否已经同步要读取的数据更新
看下3,读取数据前,在Redis master执行info replication,获取此时master的复制进度值master_repl_offset,然后在要读取数据的slave执行info replication,获取其复制进度slave_repl_offse,当master_repl_offset >= slave_repl_offse时,则说明要读取数据的修改肯定已经同步完成了,但是这种方案有个缺点就是需要多两次数据读取,势必会影响性能,但是凡事有舍有得,实际场景中还是要根据具体的情况来做出最优的选择。
2:读取到过期数据
读取到过期的原因有如下几种:
1:惰性删除和定期删除
2:过期命令在从节点的执行延迟
Redis对于过期数据的处理并非是到期就删除,而是数据读取时才删除,这种方式就会造成大量的过期数据留在内存中,占用内存资源,为了解决这个问题,Redis引入了定期删除策略,但是这种策略也只是随机的选择一批数据,然后删除其中的过期数据,并非删除所有数据。如果是没有被定时删除删除的过期数据,从节点会读到吗?这其实和Redis的版本有关系,在3.2之前的版本,Redis会正常返回数据,因此会读取到数据,对于>=redis3.2的版本,Redis会返回空,此时读不到过期数据。因此生产环境建议使用>=3.2版本的Redis。假定我们现在使用了>=3.2,就读不到过期数据了吗?还是会的,为什么呢?这和我们设置过期时间 的方式有关系,设置过期时间的相关命令如下:
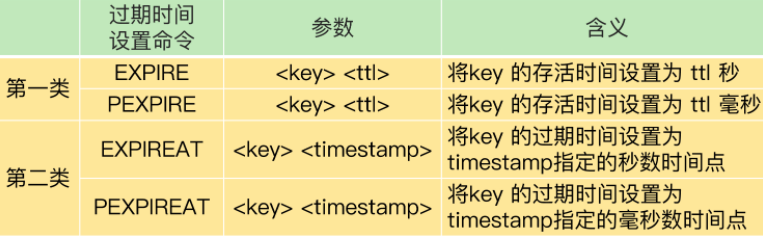
当我们使用了expire,pexpire等相对时间的命令时,可能因为命令同步延迟,导致从库实际的过期时间等于命令延迟时间+实际过期时间,比如执行命令expire myK 60就是设置60秒后过期,比如2022-12-14 11:14:36过期,但是主从延迟20秒,则从库执行后实际的过期时间就是2022-12-14 11:14:46,当在2022-12-14 11:14:40读取数据时实际数据应该是过期的,但是从库的过期时间还没到,就读取到过期数据了。此时我们就需要使用设置绝对过期时间的命令expireat,pexpireat,此时这种方式就需要保证每个服务器上的时间是一致的,可以考虑使用NTPnetwork time protocol服务器,总结解决方案如下:
1:使用>=3.2版本的Redis,避免数据过期还返回
2:使用expireAt,pexireAt命令,设置UNIX时间戳的绝对时间,避免主从延迟导致最终的过期时间不一致
3:使用NTP服务器,保证服务器具有相同的时间,避免设置绝对过期时间时数据有效期不一致
3:不合理配置在主从切换时导致集群挂掉
3.1:protected-mode
该配置项用来设置哨兵节点是否允许非一个局域网内的其他服务器访问,如果是设置为yes,允许访问,但是安全性较低,如果是设置为no,则不允许访问,当出现主节点故障时,因为此设置no可能导致部署在不同局域网中哨兵无法通信,导致无法对故障的主节点进行主从切换,进而导致服务不可用,解决方案是将protected-mode设置为yes保证安全性,并设置允许访问的IP白名单,如下:

3.2:cluster-node-timeout
该参数用于设置集群节点间进行PING/PONG 存活检测时的超时时间,如果超时则被检测节点会被标记为pfailpossible fail,然后经过询问其他节点对该节点状态的判断结果,最终会被标记为fail,即不可用,当超过半数的节点都fail时,集群将不可用。主从切换时如果是切换的时长超过了这个时间就可能发生这种情况,解决的方法是给cluster-node-timeout设置一个比较大的时间,如20秒,主从切换保留足够的时长保证其完成切换。
写在后面
参考文章列表:
Redis集群–Cluster–故障转移的过程(原理) 。