文章目录
- 1. JZ37 序列化二叉树
- 2. JZ54 二叉搜索树的第k个节点
- 3. JZ41 数据流中的中位数
- 数组
- 堆
- 4. JZ59 滑动窗口的最大值
- 5. JZ12 矩阵中的路径
- 6. JZ13 机器人的运动范围
- 7. JZ14 剪绳子
- 乘方
- dp
- 8. JZ82 二叉树中和为某一值的路径(一)
- 9. JZ9 用两个栈实现队列
- 10. JZ22 链表中倒数最后k个结点
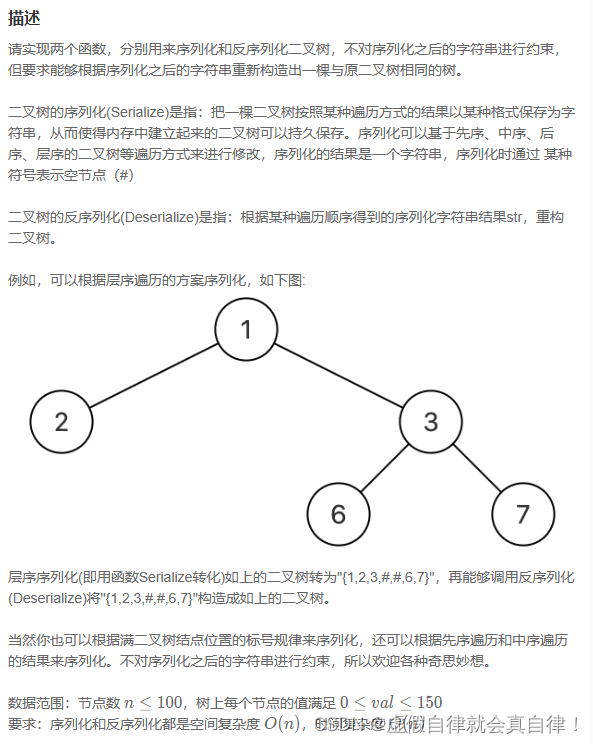
1. JZ37 序列化二叉树
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
#include <string>
class Solution {
private:
string toSerialize(TreeNode *root)
{
if(root == nullptr)
return "#!";
string str;
str += to_string(root->val) +"!";//加一个 ! 隔开每一个节点
str += toSerialize(root->left);
str += toSerialize(root->right);
return str;
}
TreeNode* toTreenode(char*& str)
{
//说明是空指针
if(*str == '#')
{
str++;
return nullptr;
}
//把当前字符转成数字 有可能是个多位数
int num = 0;
while(*str != '!')
{
num = num*10 + *str-'0';
str++;
}
TreeNode* node = new TreeNode(num);
node->left = toTreenode(++str);
node->right = toTreenode(++str);
return node;
}
public:
char* Serialize(TreeNode *root) {
string str = toSerialize(root);
char* result = new char[str.size()];//result是一个指针,存放在栈区,指向堆区的一块 str.size() 字节的区域的首地址
for(int i=0; i<str.size(); i++)
{
result[i] = str[i];
//cout << "str = " << str[i] << " res = " << result[i] << endl;
}
return result;
}
TreeNode* Deserialize(char *str) {
return toTreenode(str);
}
};
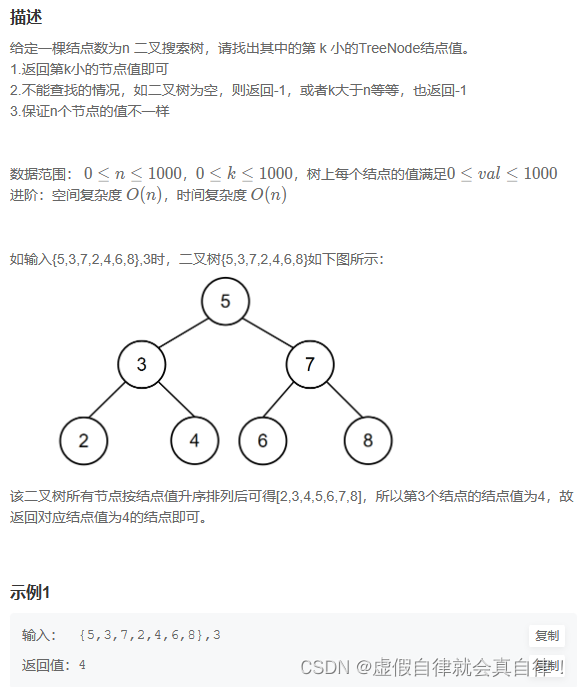
2. JZ54 二叉搜索树的第k个节点
- 中序遍历+迭代+栈,两种写法,一个是if用法,一共是while用法。
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
int KthNode(TreeNode* proot, int k) {
//中序遍历
if(proot == nullptr) return -1;
stack<TreeNode*> st;
TreeNode* cur = proot;
while(!st.empty() || cur != nullptr)
{
//写法1
/*
if(cur != nullptr)
{
st.push(cur);
cur = cur->left;
}
else {
cur = st.top();
st.pop();
k--;
if(k==0) return cur->val;
cur = cur->right;
}
*/
//写法2
while(cur != nullptr)
{
st.push(cur);
cur = cur->left;
}
cur = st.top();
st.pop();
k--;
if(k == 0) return cur->val;
cur = cur->right;
}
return -1;
}
};
- 中序+递归
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
int KthNode(TreeNode* proot, int k) {
if(proot == nullptr) return -1;
//中序遍历 递归
inOrder(proot, k);
if(res != nullptr) return res->val;
return -1;
}
void inOrder(TreeNode* root, int target)
{
if(root == nullptr || target <= 0) return;
inOrder(root->left, target);
count++;
if(count == target) res = root;//记下目标节点
inOrder(root->right, target);
}
TreeNode* res = nullptr;
int count = 0;
};
3. JZ41 数据流中的中位数

数组
存在数组里边,然后直接输出中位数
class Solution {
public:
void Insert(int num) {
result.push_back(num);
}
double GetMedian() {
sort(result.begin(), result.end());
int len = result.size();
if(len % 2 == 0) return (result[len/2] + result[len/2 -1]) / 2.0;
else return result[len/2];
}
vector<int> result;
};
堆
- 根据中位数可以把数组分为如下三段:
[0 ... median - 1], [median], [median ... arr.size() - 1],即[中位数的左边,中位数,中位数的右边]。 - 如果我有个数据结构保留
[0...median-1]的数据,并且可以O(1)时间取出最大值,即arr[0...median-1]中的最大值,也就是大顶堆;
如果我有个数据结构可以保留[median + 1 ... arr.size() - 1]的数据, 并且可以O(1)时间取出最小值,即arr[median + 1 ... arr.size() - 1]中的最小值,也就是小顶堆。
然后,我们把[median],即中位数,随便放到哪个都可以。 - 假设
[0 ... median - 1]的长度为l_len,[median + 1 ... arr.sise() - 1]的长度为 r_len.
- 如果
l_len == r_len + 1, 说明,中位数是左边数据结构的最大值 - 如果
l_len + 1 == r_len, 说明,中位数是右边数据结构的最小值 - 如果
l_len == r_len, 说明,中位数是左边数据结构的最大值与右边数据结构的最小值的平均值。
- GetMedian()操作算法过程为:
初始化一个大根堆bigheap_min,存中位数左边的数据,一个小根堆smallheap_max,存中位数右边的数据。动态维护两个数据结构的大小,即最多只相差一个,保证小顶堆中最小的数也大于大顶堆中的数据。小根堆可以O(1)返回最小值的,可以大根堆O(1)返回最大值的,并且每次插入到堆中的时间复杂度为O(logn)。
-
数据是偶数,将 大顶堆的堆顶 放在小顶堆smallheap_max中:先把当前数据num 放在大顶堆中,然后把大顶堆的堆顶 放入小顶堆中,就可以保证左边 < 右边
-
数据是奇数,将小顶堆的堆顶 放在大顶堆bigheap_min中:先把当前数据num 放在小顶堆,然后把小顶堆的堆顶 放入大顶堆中,就可以保证左边 < 右边
-
最后,如果是偶数,中位数是大小顶堆的堆顶的平均数;如果是奇数,中位数就是大顶堆的堆顶。一个整数与0x1做按位与运算得到的结果是0或者1,就可以判断出这个整数是偶数还是奇数。
/*
//堆
#include <queue>
class Solution {
public:
void Insert(int num) {
count++;
if(count % 2 == 0)//元素个数是偶数 数据放在 大顶堆,然后将 大顶堆 堆顶 放在小顶堆
{
bigheap_min.push(num);
smallheap_max.push(bigheap_min.top());
bigheap_min.pop();
}
else {
smallheap_max.push(num);
bigheap_min.push(smallheap_max.top());
smallheap_max.pop();
}
}
double GetMedian() {
//0x 16进制表示,0x1最后是1,偶数的二进制表示中最后一位是0,
//如果count是奇数,其二进制的最后一位是1,与0x1做按位与运算得到的结果是1,说明是奇数,返回左边大顶堆得最小值即可
if(count & 0x1) return bigheap_min.top();
else return (bigheap_min.top() + smallheap_max.top()) / 2.0;
}
int count = 0;
priority_queue<int, vector<int>, less<int>> bigheap_min;//左边大顶堆 元素数值较小
priority_queue<int, vector<int>, greater<int>> smallheap_max;//右边小顶堆 元素数值都比大顶堆大
};
4. JZ59 滑动窗口的最大值

牛客思路

双端队列deque构造单调队列,写法1
#include <deque>
class Solution {
public:
vector<int> maxInWindows(vector<int>& num, int size) {
//单调队列
vector<int> result;
deque<int> dq;//单调递减队列 存放的是下标
if(num.size() == 0 || size == 0 || num.size() < size) return result;
for(int i=0; i<num.size(); i++)
{
//cout << "i = " << i << " num[i] = " << num[i] << " dq.back() = " << dq.back() << " num[dq.back()] = " << num[dq.back()]<< endl;
//如果当前元素比队列末尾的元素大 就把队列末尾的元素先弹出 注意队列不为空
while(!dq.empty() && num[i] > num[dq.back()])
{
cout << "i = " << i << " dq.back() = " << dq.back() << endl;
dq.pop_back();
}
dq.push_back(i);//再把较大的元素入队
//判断队列的头部元素是否属于窗口
if(dq.front() <= i - size)
dq.pop_front();
//如果遍历的个数 正好是窗口数 保存最大值 遍历的个数用i+1表示
if(i + 1 >= size) result.push_back(num[dq.front()]);
}
return result;
}
};
双端队列deque构造单调队列,写法2
#include <deque>
#include <vector>
class Solution {
private:
class Myqueue {
public:
deque<int> que;// 使用deque来实现单调队列
//如果队头元素=当前元素 队头元素弹出
//队头元素在下一个窗口失效
void pop(int value)
{
if(!que.empty() && que.front() == value)
que.pop_front();
}
//如果当前元素比队尾元素大 先把队尾的元素弹出,再把当前元素存入队尾 保证单调递减
void push(int value)
{
while(!que.empty() && value > que.back())
que.pop_back();
que.push_back(value);
}
// 单调队列 直接返回队列头部元素即可
int front()
{
return que.front();
}
};
public:
vector<int> maxInWindows(vector<int>& num, int size) {
vector<int> result;
if(num.size() == 0 || size == 0 || num.size() < size) return result;
//单调队列 写法2
Myqueue myque;
//1.先放入前size个元素
for(int i=0; i<size; i++)
{
myque.push(num[i]);
}
//2.当前窗口的最大值
result.push_back(myque.front());
//3.更新窗口最大值 并保存
for(int i=size; i<num.size(); i++)
{
myque.pop(num[i-size]);//更新窗口前 移除队头元素 该元素在下一个窗口失效 前面存了size-1个元素 下标就是i-size
myque.push(num[i]);//更新窗口前 加入最后面的元素
result.push_back(myque.front());
}
return result;
}
};
5. JZ12 矩阵中的路径

一个和原二维数组board等大小的visited数组,是bool型的,用来记录当前位置 是否被访问过。
如果二维数组的当前字符和目标字符串str对应的字符相等,则对其上下左右四个邻字 符串分别调用dfs的递归函数,只要有一个返回true,那么就表示找到对应的字符串。
class Solution {
public:
bool hasPath(vector<vector<char> >& matrix, string word) {
vector<vector<bool>> visited(matrix.size(), vector<bool>(matrix[0].size()));
if(word.size() == 0) return false;
for(int i=0; i<matrix.size(); i++)
{
for(int j=0; j<matrix[0].size(); j++)
{
if(dfs(matrix, word, 0, i, j, visited) == true)
return true;
}
}
return false;
}
bool dfs(vector<vector<char> >& matrix, string word, int index, int i, int j, vector<vector<bool>>& visited)
{
if(index == word.size()) return true;//搜寻超过路径长度,符合条件,返回true
if(i<0 || j<0 || i>=matrix.size() || j>=matrix[0].size()) return false;//访问越界,终止,返回false
if(visited[i][j]) return false;
if(matrix[i][j] != word[index]) return false;
visited[i][j] = true;
if( dfs(matrix, word, index+1, i, j-1, visited) || //上
dfs(matrix, word, index+1, i, j+1, visited) || //下
dfs(matrix, word, index+1, i-1, j, visited) || //左
dfs(matrix, word, index+1, i+1, j, visited)) //右
return true;
visited[i][j] = false;
return false;
}
};
6. JZ13 机器人的运动范围

dfs 递归 和bfs 迭代两种方式
class Solution {
public:
int movingCount(int threshold, int rows, int cols) {
vector<vector<bool>> visited(rows, vector<bool>(cols, false));
//当前横向位置 纵向位置 横向边界 纵向边界
//return dfs(threshold, visited, 0, 0, rows, cols);
//bfs
return bfs(threshold, rows, cols, visited);
}
//能够搜索
bool canInter(int threshold, int i, int j)
{
int sum = 0;
//获取i每一位的值累加
while(i > 0)
{
sum += i % 10;//先是个位
i /= 10;
}
while(j > 0)
{
sum += j %10;
j /= 10;
}
//小于阈值可以搜索
return (sum <= threshold) ? true : false;
}
int dfs(int threshold, vector<vector<bool>>& visited, int i, int j, int rows, int cols)
{
//如果超出边界 当前位置访问过 当前位置不能搜索 都停止本层递归
if(i<0 || i>=rows || j<0 || j>=cols || visited[i][j]==true || canInter(threshold, i, j)==false)
return 0;
//标记当前位置
visited[i][j] = true;
//所有可访问的位置数量累加 当前位置的四个方向 不需要回溯
return dfs(threshold, visited, i-1, j, rows, cols) //上
+ dfs(threshold, visited, i+1, j, rows, cols) //下
+ dfs(threshold, visited, i, j-1, rows, cols) //左
+ dfs(threshold, visited, i, j+1, rows, cols) //右
+ 1; //表示的是当前位置
}
int bfs(int threshold, int rows, int cols, vector<vector<bool>>& visited)
{
queue<pair<int, int>> que;//记录可以搜索的位置
if(canInter(threshold, 0, 0))//保存第一个位置
{
que.push(make_pair(0, 0));
visited[0][0] = true;
}
int count = 0;
int i, j;//队列中取出一个位置
while(!que.empty())
{
count++;
tie(i, j) = que.front();
que.pop();
//i+1 j位置 不能越界 没有访问过 可以搜索
if(i+1 < rows && visited[i+1][j]==false && canInter(threshold, i+1, j))
{
visited[i+1][j] = true;
que.push(make_pair(i+1, j));
}
//i j+1位置
if(j+1 < cols && visited[i][j+1]==false && canInter(threshold, i, j+1))
{
visited[i][j+1] = true;
que.push(make_pair(i, j+1));
}
}
return count;
}
};
7. JZ14 剪绳子
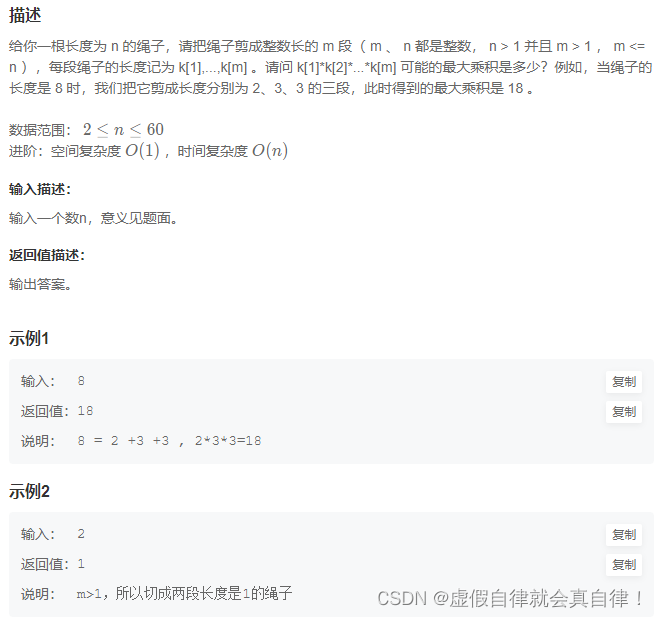
分析:

- 首先判断,0到m可能有哪些数字,实际上只可能是2或者3,也有可能是4,但是4=22,就不考虑了。
其次,15<23,16<33,比6更大的数字就更不用考虑了,肯定要继续分。
然后,再看2和3的数量,2的数量肯定小于3个,为什么呢?因为222<33,那么题目就简单了。
总结起来,就是直接用n除以3,根据得到的余数判断是一个2、还是两个2、还是没有2就行了。 - 由于题目规定m>1,所以2只能是11,3只能是21,这两个特殊情况直接返回。
- 乘方运算的复杂度为:O(log n),用动态规划来做会耗时比较多。
这个思路太巧妙了。
乘方
#include <climits>
class Solution {
public:
int cutRope(int n) {
if(n < 2) return 0;
if(n == 2 || n==3) return n-1;
//乘方
int result = 1;
//result每乘一个3,n就要减掉一个3,直到n=4结束
while (n > 4)
{
result *= 3;
n -= 3;
}
//此时n=4=2*2,结果就是result * n
result *= n;
return result;
}
};
dp
定义绳子长度为i时,dp[i]是分割之后的最大乘积。
- 写法1
#include <climits>
class Solution {
public:
int cutRope(int n) {
if(n < 2) return 0;
if(n == 2 || n==3) return n-1;
//dp
vector<int> dp(n+1, 0);
dp[0] = 1;
dp[1] = 1;
for(int i=2; i<=n; i++)
{
//先分成两段2~i-1,i-1~i
dp[i] = i-1;
for(int j=2; j<i; j++)
{
//然后继续分,分成 2~j(长度表示j)和 j~i-1(长度表示i-j),那么就看dp[i] 和 dp[i-j] * j (新的dp[i])
//如果不能分,分成 j(长度表示j)和 i-j(长度表示i-j),那么就看dp[i] 和 当前长度的乘积 (i-j) * j
dp[i] = max(dp[i], dp[i-j] * j);//继续分
dp[i] = max(dp[i], (i-j) * j);//不能分了
}
}
return dp[n];
}
};
- 写法2
要注意的是,j<=i/2,因为 f(5) = f(1) × f(4) = f(2) × f(3) = f(3) × f(2) = f(4) × f(1) ,可以看成是从1开始,走到后面,又回来了。所以走一半即可,但一定要走到一半才行,不能小于i/2,必须是小于等于。
8. JZ82 二叉树中和为某一值的路径(一)
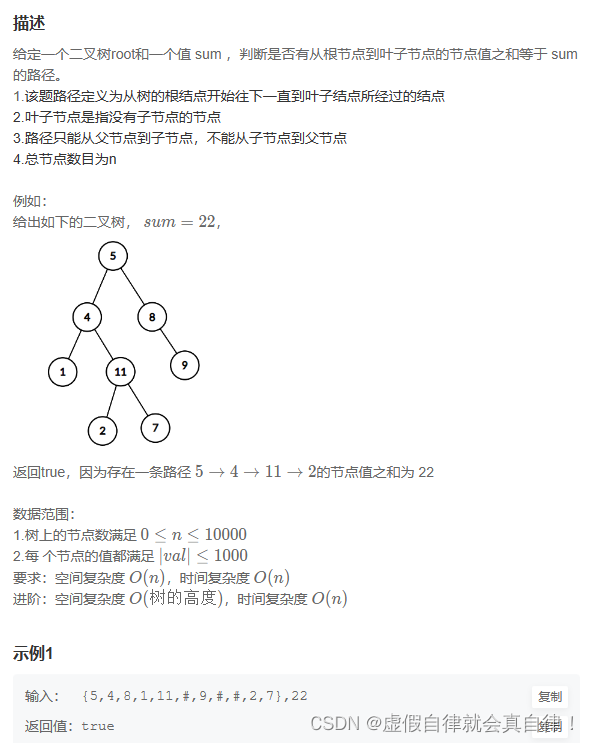
- 写法1
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
if(root == nullptr) return false;
int res = 0;
return dfs(root, sum, res);
}
bool dfs(TreeNode* root, int sum, int res)
{
if(root == nullptr) return false;
res += root->val;
if(!root->left && !root->right && res == sum) return true;
return dfs(root->left, sum, res) || dfs(root->right, sum, res);
}
};
- 写法2
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
if(root == nullptr) return false;
if(!root->left && !root->right && root->val == sum) return true;
return hasPathSum(root->left, sum - root->val) || hasPathSum(root->right, sum - root->val);
}
};
JZ22 链表中倒数最后k个结点
JZ18 删除链表的节点
JZ84 二叉树中和为某一值的路径(三)
JZ86 68 11 44 85 69 71 63 47 48 46 56 21 14 81 83
9. JZ9 用两个栈实现队列

class Solution
{
public:
void push(int node) {
stack1.push(node);
}
int pop() {
while(!stack1.empty())
{
stack2.push(stack1.top());
stack1.pop();
}
int res = stack2.top();
stack2.pop();
while (!stack2.empty()) {
stack1.push(stack2.top());
stack2.pop();
}
return res;
}
private:
stack<int> stack1;
stack<int> stack2;
};
10. JZ22 链表中倒数最后k个结点
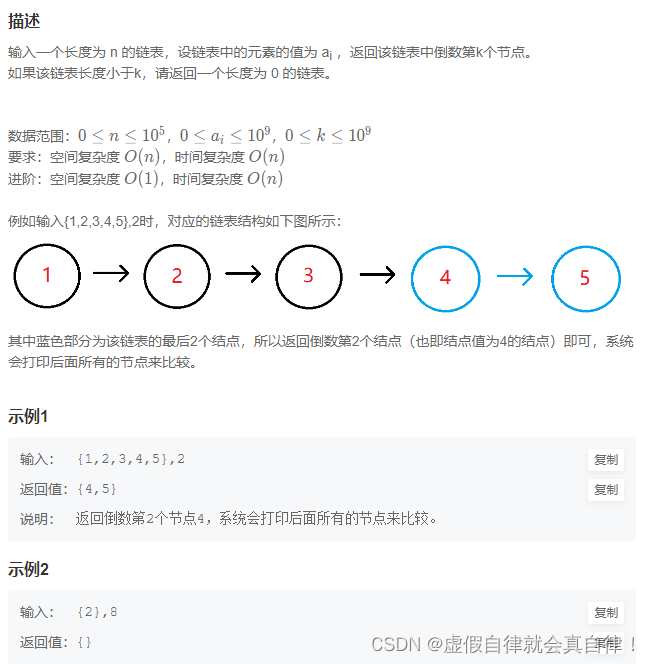
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) : val(x), next(nullptr) {}
* };
*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pHead, int k) {
ListNode* fast = pHead;
if(k <= 0 || pHead==nullptr) return nullptr;
while(k--)
{
if(fast->next && k>0) return nullptr;//链表没有那么长
if(!fast->next) return pHead;//倒数最后一个 返回第一个
fast = fast->next;
}
cout << fast->val << endl;
while(fast!=nullptr)
{
pHead = pHead->next;
fast = fast->next;
}
return pHead;
}
};