Elasticsearch 是一个强大且可扩展的搜索和分析引擎,可用于索引和搜索大量数据。 Elasticsearch 通常用于集群环境中,以提高性能、提供高可用性并实现数据冗余。 在本文中,我们将讨论如何在 Ubuntu 20.04 上安装和配置具有多节点集群的 Elasticsearch 版本 8。

得益于 Elasticsearch 版本 8 的功能,现在部署 Elasticsearch 集群变得更加容易。 你可以在此处查看有关安装的官方文档。 在本文中,我们将使用 ubuntu deb 安装。 在我之前的文章 “Elasticsearch: 使用 Debian 安装包来安装 Elasticsearch 8.x” 我详述了如何使用 Debian 安装包来安装具有一个节点的集群。在今天的文章中,我来详细介绍如何在 Ubuntu 系统上安装具有三个节点的 Elasticsearch 集群。我的系统配置如下:
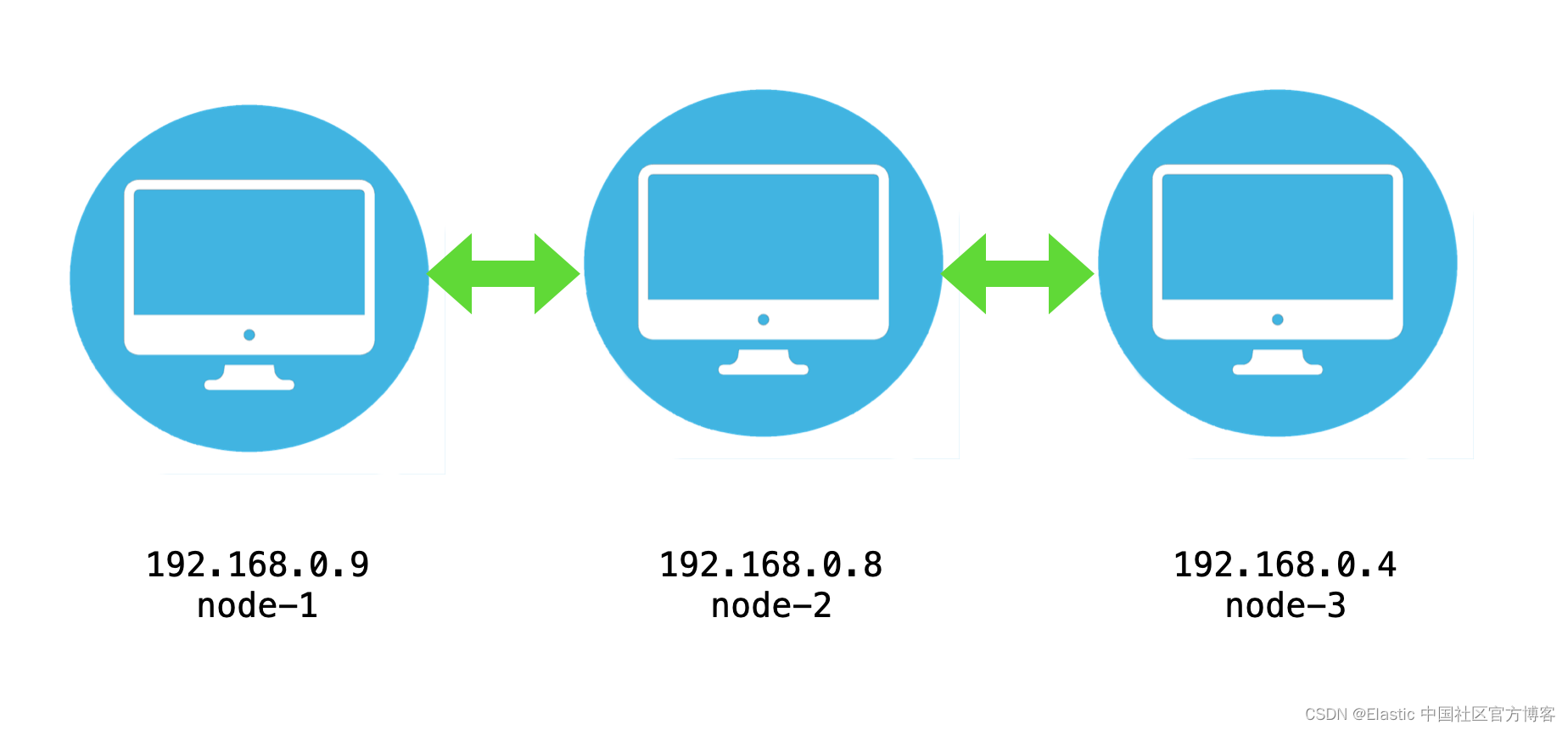
如上所示,我们在 Ubuntu 系统上的 IP 地址如上所示。我们可以使用如下的命令来获得当前的系统的 IP 地址:
ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}'$ ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}'
192.168.0.9如果你曾经在自己的电脑上安装过 Elasticsearch,你可以使用如下的命令把之前的安装全部删除:
remove.sh
sudo apt remove elasticsearch
sudo apt purge elasticsearch
sudo rm -rf /var/lib/elasticsearchchmod a+x remove.sh
sudo ./remove.sh一旦之前的 Elasticsearch 都被成功地删除了,那么我们就可开始下面的安装工作了。安装 Elasticsearch 集群的简单步骤如下:
- 在 node-1 上安装 elasticsearch
- 更新 node-1 的 elasticsearch.yml
- 启动 elasticsearch 节点1
- 检查节点健康状况
- 在 node-2 上安装 elasticsearch
- 使用节点 1 中的令牌在节点 2 上运行 “elasticsearch-reconfigure-node --enrollment-token <token-here>” 命令
- 更新 node-2 的 elasticsearch.yml
- 启动 elasticsearch 节点2
- 检查节点数 GET _cat/nodes
- 在相同或不同节点上安装 Kibana
- 为 Kibana 创建注册令牌 elasticsearch-create-enrollment-token -s kibana
- 启动Kibana
安装
安装 node-1
参照官方文档,我们创建如下的安装脚本,以便在各个节点上运行:
install.sh
#!/bin/bash
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
apt-get install apt-transport-https
echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.list
sudo apt-get update && sudo apt-get install elasticsearch我们使用如下的命令来进行安装:
chmod a+x install.sh
sudo ./install.sh 
在当前的 terminal 下,我们可以看到如下的输出:

安装完成后,你需要创建一个数据目录并将其所有者更改为 Elasticsearch 用户。 接下来,使用以下设置更新 Elasticsearch 配置文件:
/etc/elasticsearch/elasticsearch.yml
cluster.name: elk-logs
node.name: node-1
network.host: 192.168.0.9
discovery.seed_hosts: ["192.168.0.9"]
cluster.initial_master_nodes: ["192.168.0.9"]
重新加载 systemctl 守护进程,启用 Elasticsearch 服务,并通过运行以下命令启动 Elasticsearch 服务:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearchsystemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
Created symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /lib/systemd/system/elasticsearch.service.你可以使用以下命令检查 Elasticsearch 服务的状态:
systemctl status elasticsearch
你也可以使用如下的命令来进行查看:
service elasticsearch status如果需要的话,我们可以使用如下的命令来重置内置 elastic 用户的密码,请运行以下命令:
/usr/share/elasticsearch/bin/elasticsearch-reset-password -i -u elastic比你可以使用以下命令检查 Elasticsearch 集群健康状况和节点信息:
curl -k -u elastic:<password> "https://localhost:9200/_cluster/health?pretty"
curl -k -u elastic:<password> "https://localhost:9200/_cat/nodes?v"root@ubuntu2204:~# curl -k -u elastic:password "https://localhost:9200/_cluster/health?pretty"
{
"cluster_name" : "elk-logs",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1,
"active_shards" : 1,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
root@ubuntu2204:~# curl -k -u elastic:password "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
127.0.0.1 10 98 7 0.41 0.34 0.26 cdfhilmrstw * ubuntu2204从上面的输出中,我们可以看到有一个节点的集群已经运行起来了。
你需要创建一个注册令牌,以便稍后在其他节点中使用以加入现有的 Elasticsearch 集群。 运行以下命令在 Node-1 上创建注册令牌:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node我们可以通过如下的命令来查看 Elasticsearch 的输出日志:
journalctl -u elasticsearch
如果你觉得历史日志太长不便于查看,你可以使用如下的命令来清除之前的日志:
sudo journalctl --rotate
sudo journalctl --vacuum-time=1s安装 node-2
要在 node-2 上安装 Elasticsearch,我们仿照上面的步骤创建 install.sh,并在它们的机器上运行。
sudo ./install.sh不要启动 Elasticsearch。 首先,你需要运行以下命令。 以下命令将修改证书、密钥库和 elasticsearch.yml。

安装后,你可以通过运行以下命令将 Elasticsearch 服务配置为使用你在 node-1 中创建的注册令牌。我们在 node-1 的 terminal 中打入如下的命令:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s noderoot@ubuntu2204:~# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node
eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6IjQ5ODRmZDM0ZGJjMTkyNGZjMGI4YmZlZjM4ZTg3NjdjNmUxMzFmNWIxYjAxZGE0MDc4MzI2N2NlODFiMjI5NzQiLCJrZXkiOiI3eGRwLVlrQkhGcVEtMlRPMU1lYTp6dk9rbjEtSFQ1dVEzR3R6MGd4bW5nIn0=我们在 node-2 的 terminal 中打入如下的命令:
/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>root@ubuntu2004:~# /usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6IjQ5ODRmZDM0ZGJjMTkyNGZjMGI4YmZlZjM4ZTg3NjdjNmUxMzFmNWIxYjAxZGE0MDc4MzI2N2NlODFiMjI5NzQiLCJrZXkiOiI3eGRwLVlrQkhGcVEtMlRPMU1lYTp6dk9rbjEtSFQ1dVEzR3R6MGd4bW5nIn0=
This node will be reconfigured to join an existing cluster, using the enrollment token that you provided.
This operation will overwrite the existing configuration. Specifically:
- Security auto configuration will be removed from elasticsearch.yml
- The [certs] config directory will be removed
- Security auto configuration related secure settings will be removed from the elasticsearch.keystore
Do you want to continue with the reconfiguration process [y/N]y将你在 node-1 上生成的注册令牌粘贴到 上面的命令中, 并运行命令。 该命令将修改 node-2 中的证书和 elasticsearch.yml
我们同时对 elasticsearch.yml 文件进行修改:
cluster.name: elk-logs
node.name: node-2
network.host: 192.168.0.8重新加载 systemctl 守护进程,启用 Elasticsearch 服务,并通过运行以下命令启动 Elasticsearch 服务:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch我们通过如下的命令来查看 elasticsearch 服务的状态:
service elasticsearch status
同样地,我们使用如下的命令来查看集群的节点:
curl -k -u elastic:<password> "https://localhost:9200/_cat/nodes?v"curl -k -u elastic:-K2s_i2nsG62iphpNOvY "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 20 98 9 0.09 0.16 0.17 cdfhilmrstw - node-2
192.168.0.9 12 98 5 0.10 0.17 0.18 cdfhilmrstw * node-1请注意在上面,我们使用的密码和之前的 node-1 中的不同,这是因为我使用了如下的命令修改了 elastic 超级用户的密码:
oot@ubuntu2004:/etc/elasticsearch# /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic
This tool will reset the password of the [elastic] user to an autogenerated value.
The password will be printed in the console.
Please confirm that you would like to continue [y/N]y
Password for the [elastic] user successfully reset.
New value: -K2s_i2nsG62iphpNOvY从上面的 node 显示结果中,我们可以看出来,已经有两个节点组成了集群。
我们按照上面的步骤,在 node-3 上进行安装。安装完毕后,我们使用同样的命令来进行查看:
root@liuxgu:/etc/elasticsearch# curl -k -u elastic:-K2s_i2nsG62iphpNOvY "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 17 98 7 0.19 0.21 0.18 cdfhilmrstw - node-2
192.168.0.4 4 99 3 0.50 0.53 0.32 cdfhilmrstw - node-3
192.168.0.9 15 98 5 0.11 0.19 0.18 cdfhilmrstw * node-1从上面的显示中,我们可以看到有三个节点的 Elasticsearch 已经安装完毕。
重新配置各个节点
添加所有节点后,删除 node-1 的 Elasticsearch 配置文件中的 “cluster.initial_master_nodes” 设置。 然后,使用主节点的 IP 或主机名将 “discovery.seed_hosts”设置添加到 node-1 的 Elasticsearch 配置文件中。
比如:
删除节点 1 上的 elasticsearch.yml 文件中的以下设置:
cluster.initial_master_nodes: ["..."]然后,将以下设置添加到 node-1 上的 elasticsearch.yml 文件中:
discovery.seed_hosts: ["192.168.0.9:9300", "192.168.0.8:9300", "192.168.0.4:9300"]请注意,seed_hosts 列表中的 IP 地址和端口号应与集群中符合主节点资格的节点的 IP 地址和端口号相匹配。
首次成功形成集群后,从每个节点的配置中删除 cluster.initial_master_nodes 设置。 重新启动集群或向现有集群添加新节点时不应使用此设置。
接下来,更新所有节点上的 elasticsearch.yml 文件中的 discovery.seed_hosts 设置,以包含集群中所有节点(包括该文件所在节点)的 IP 地址和端口号。
最后,创建一个示例 elasticsearch.yml 文件,其中包含集群所需的配置。 此文件应包含 cluster.name、path.data 和 path.logs 设置,以及任何其他必要的设置,例如安全和传输设置。
cluster.name: elk-logs
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
discovery.seed_hosts: ["192.168.0.9:9300", "192.168.0.8:9300", "192.168.0.4:9300"]
http.host: 0.0.0.0
transport.host: 0.0.0.0不要尝试将 elasticsearch.yml 复制并粘贴到此处,因为它不起作用。 证书和密钥库需要在节点之间匹配:)。
检查 Elasticsearch 安装的操作系统级别设置也很重要。 Elasticsearch 文档提供了有关此主题的指导。
如果需要指定 node.role,可以更新 elasticsearch.yml 文件并重新启动 Elasticsearch。 node.roles 设置可用于指定节点的角色,例如数据节点或主节点。 Elasticsearch 文档提供了有关此主题的更多信息。
一旦 Elasticsearch 集群启动并运行,就可以安装并配置 Kibana 以连接到集群。 这涉及使用 elasticsearch-create-enrollment-token 命令在其中一个节点上为 Kibana 创建注册令牌,然后使用注册令牌在 Kibana 服务器上运行 kibana-setup 命令。 最后就可以启动Kibana服务了。
如果安装过程中出现任何问题,可能需要完全删除 Elasticsearch 并从头开始。 Elasticsearch 文档提供了在各种操作系统(包括基于 Debian 的系统)上删除 Elasticsearch 的说明。
安装 Kibana
我们将在 node-1 机器上安装 Kibana。我们运行如下的命令:
sudo apt remove --purge kibana接下来,我们可以运行以下命令来安装 Kibana:
sudo apt install kibana安装后,我们需要在其中一个节点上为 Kibana 创建注册令牌。 为此,请运行以下命令:
sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibanaparallels@ubuntu2204:~$ sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
[sudo] password for parallels:
eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6Ijg2NWViYmRmMmQyNDBiMzJjMzI3NDI5MjBmZDBmOGVkMmJlZWZiODlkNzliM2QwODAyYWEwZmNlOGVlZjQ4ZjUiLCJrZXkiOiJmX0MxLVlrQlBZcnJLUkJJMWNPQjpYTzAwN081b1FES1AtWmdNWWkxXzhBIn0=
接下来,我们需要在安装的节点上运行以下命令,以使用注册令牌配置 Kibana:
sudo /usr/share/kibana/bin/kibana-setup --enrollment-token <enrollment-token>parallels@ubuntu2204:~$ sudo /usr/share/kibana/bin/kibana-setup --enrollment-token eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6Ijg2NWViYmRmMmQyNDBiMzJjMzI3NDI5MjBmZDBmOGVkMmJlZWZiODlkNzliM2QwODAyYWEwZmNlOGVlZjQ4ZjUiLCJrZXkiOiJmX0MxLVlrQlBZcnJLUkJJMWNPQjpYTzAwN081b1FES1AtWmdNWWkxXzhBIn0=
✔ Kibana configured successfully.
To start Kibana run:
bin/kibana将 <enrollment-token> 替换为上一步中生成的注册令牌。
最后,我们可以使用以下命令在节点上启动 Kibana 服务:
sudo systemctl start kibana这是 kibana.yml 的示例:
server.host: 0.0.0.0
elasticsearch.hosts: ['https://192.168.0.9:9200']
logging.appenders.file.type: file
logging.appenders.file.fileName: /var/log/kibana/kibana.log
logging.appenders.file.layout.type: json
logging.root.appenders: [default, file]
pid.file: /run/kibana/kibana.pid
elasticsearch.serviceAccountToken: long-token
elasticsearch.ssl.certificateAuthorities: [/var/lib/kibana/ca_1692111671076.crt]
xpack.fleet.outputs: [{id: fleet-default-output, name: default, is_default: true, is_default_monitoring: true, type: elasticsearch, hosts: ['https://192.168.0.9:9200'], ca_trusted_fingerprint: 865ebbdf2d240b32c32742920fd0f8ed2beefb89d79b3d0802aa0fce8eef48f5}]我们可以在该集群的浏览器中打开 Kibana:


这样我们的 Kibana 的安装已经完成了。


![linux学习(进程替换)[10]](https://img-blog.csdnimg.cn/d5d05c655ebe461180dd6dd394fc0b98.png)







![[xgb] plot tree](https://img-blog.csdnimg.cn/bf6408d1b0024af4941cb730046823a5.png)