xgboost plot tree debug
- problem1
- solutions
- reference
- problem2
- solution
- reference
- problem3
- solution
- reference
- supplementary explanation
- plot_tree参数介绍
- num_trees=model.get_booster().best_iteration
- 图中信息介绍
- 缺失值
- 叶子的值
- 训练的XGB模型里有多少棵树
problem1
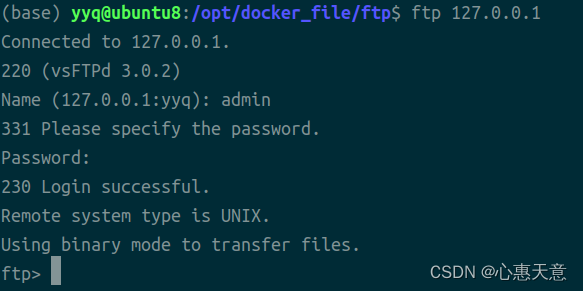
用xgboost的plot_tree(booster)画图,出来只有一个叶子节点,没有整棵树。
solutions
plot_tree(model, num_trees=model.get_booster().best_iteration)
在plot_tree中添加num_trees=model.get_booster().best_iteration。
原因:
XGB是一种基于集成原理的技术,因此XGB创建多棵树,有些树只能以一片叶子结束。
用于绘制export_graphviz / plot_tree 的函数将第一棵树绘制为默认值,而不是最佳交互。为此,需要设置参数num_trees
plot_tree中对于参数的介绍:
num_trees : int, default 0
Specify the ordinal number of target tree 指定目标树的序号
所以必须找到目标树的序数。幸运的是,有两个函数为我们设置了:.get_booster().best_iteration。
参考下面的代码来绘制具有最佳交互的树。
from xgboost import plot_tree
plot_tree(model, ax=ax, num_trees=model.get_booster().best_iteration)
reference
https://stackoom.com/question/4K9uw
problem2
画出来的图看不清

solution
from xgboost import plot_tree
import matplotlib.pyplot as plt
plot_tree(model, num_trees=reg_a.get_booster().best_iteration)
fig=plt.gcf()
fig.set_size_inches(150,100)
fig.savefig('../pics/tree.png')
这样存下来是一个1.9MB大小的png文件。
reference
https://blog.csdn.net/anshuai_aw1/article/details/82988494
problem3
到这里,我输出的png已经是以特征名画出来的图了。但是看网上说,有的图画出来不是特征名,而是0123,这里网上给出了以下解决方法。
solution
def ceate_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0}\t{1}\tq\n'.format(i, feat))
i = i + 1
outfile.close()
'''
X_train.columns在第一段代码中也已经设置过了。
特别需要注意:列名字中不能有空格。
'''
ceate_feature_map(X_train.columns)
reference
https://zhuanlan.zhihu.com/p/28324798
supplementary explanation
plot_tree参数介绍
Parameters
----------
booster : Booster, XGBModel
Booster or XGBModel instance
提升器或者XGB模型
fmap: str (optional)
The name of feature map file
特征名称的映射关系的文件,主要是为了画图显示的是特征名,而不是012.
num_trees : int, default 0
Specify the ordinal number of target tree
指定目标树的序数, 画的第几课树
rankdir : str, default "TB"
Passed to graphiz via graph_attr
通过graph_attr传给graphiz,'LR'=from left to right; 'TB'/'UT'=from top to bottom.
ax : matplotlib Axes, default None
Target axes instance. If None, new figure and axes will be created.
kwargs :
Other keywords passed to to_graphviz
Returns
-------
ax : matplotlib Axes
num_trees=model.get_booster().best_iteration
get_booster
获取此模型的底层xgboost Booster。
best_iteration
通过提前停止获得的最佳迭代。该属性是基于0的,
例如,如果最佳迭代是第一轮,则best_iteration为0。
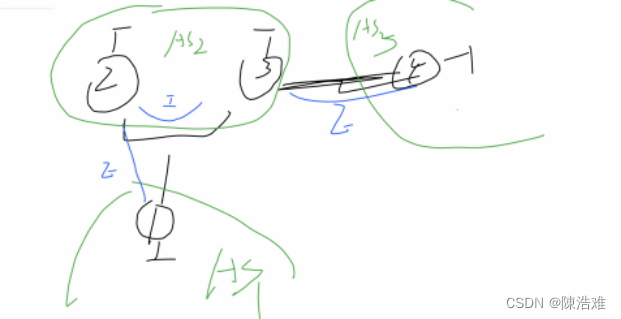
图中信息介绍
缺失值
在画出来的树模型图中可以看到有一条蓝色的线,上面写着“yes,missing”,这表示只要是缺失值就跟着蓝色线走。这是XGBoost对缺失值的处理方法。
那这个蓝色的线又是如何生成的呢?
这个算法实际上做的是一件非常简单的事情。对于第k个特征,我们首先将样本中第k个特征的特征值为缺失值的样本全部剔除。然后我们正常进行样本划分。最后,我们做两个假设,一个是缺失值全部摆左子结点,一个是摆右子节点。哪一个得到的增益大,就代表这个特征最好的划分。总结一下,就是缺失值都摆一起,选最好的情况
注意:对于加权分位法中对于特征值的排序,缺失值不参与。也就是说缺失值不会作为分裂点。gblinear将缺失值视为0。
reference:
原文链接:https://blog.csdn.net/zzoo2200/article/details/126786630
叶子的值
leaf_value实际上是这个节点的交叉熵值: 1 / (1 + np.exp(-x))

以上面的树为例, 第二层的叶子节点
左节点预测概率1 / (1 + np.exp(0.2198)) = 0.445,
右节点的预测概率1 / (1 + np.exp(-0.217)) = 0.554
0.445 + 0.554 = 1
reference:
链接:https://www.jianshu.com/p/3b4575795146
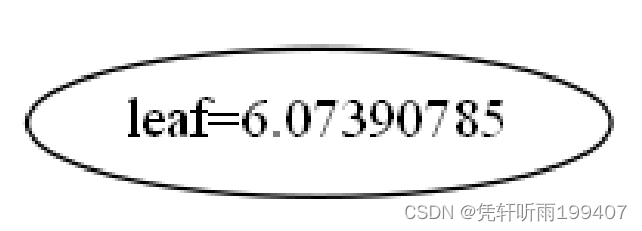
训练的XGB模型里有多少棵树
使用dump model,xgboost会生成一个列表,其中每个元素都是单个树的字符串表示。然后计数list中有多少元素即可获得模型中树的数量。
# model is a XGBoost model fitted using the sklearn API
dump_list = model.get_booster().get_dump()
print(dump_list )
# ['0:leaf=6.07390785\n', '0:leaf=4.2559433\n', '0:leaf=2.98210931\n', '0:leaf=2.08954239\n', '0:leaf=1.46412754\n']
num_trees = len(dump_list)
print(num_trees )
# 5
reference:
https://stackoverflow.com/questions/50426248/how-to-know-the-number-of-tree-created-in-xgboost