进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. 创建库
2. 查看数据库
3. 删除库
4. 创建表
5. 查看表
6. 查看表的定义
8. 删除表
9. 修改表
9.1 添加列
9.2 删除列
9.3 清空列
9.4 给列修改注释
9.5 修改列类型
10. 给表重命名
10.1 给表重命名语法
10.2 示例
DDL:Data Definition Language,数据库定义语言。在ClickHouse中,DDL语言中修改表结构仅支持Merge表引擎、Distributed表引擎及MergeTree家族的表引擎,SQL 中的库、表、字段严格区分大小写。
1. 创建库
- 创建库基础语法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]2. 查看数据库
- 查看数据库语法
SHOW DATABASES;3. 删除库
- 删除库基础语法:
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster]- 示例:
#创建库 test_db
node1 :) create database if not exists test_db;
CREATE DATABASE IF NOT EXISTS test_db
Ok.
0 rows in set. Elapsed: 0.007 sec.
#删除库
node1 :) drop database test_db;
DROP DATABASE test_db
Ok.
0 rows in set. Elapsed: 0.003 sec.注意:在创建数据库时,在/var/lib/clickhouse/metadata/目录下会有对应的库目录和库.sql文件,库目录中会存入在当前库下建表的信息,xx.sql文件中存入的是建库的信息。如图:
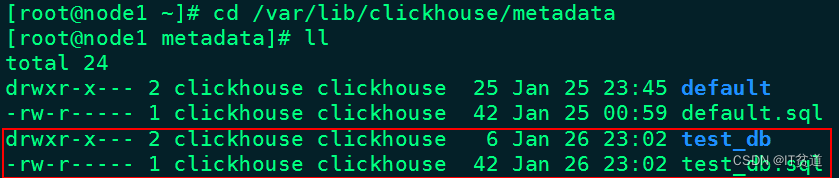
当删除数据库时,/var/lib/clickhouse/metadata/目录下对应的库目录和xx.sql文件也会被清空。
4. 创建表
创建表的基本语法:
#第一种
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
#第二种
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
#第三种
CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ...注意:以上普通第一种建表语句是直接创建表。第二种创建表方式可以创建一个与db2中name2一样结构的表,也可以指定表引擎,也可以不指定,不指定默认与db2中的name2表引擎一样,不会将表name2中的数据填充到对应的新表中。第三种方式可以指定引擎创建一个与Select 子句的结果相同结构的表,并将Select子句的结果填充它。
- 示例:
#第一种方式创建表
node1 :) create table if not exists newdb.t1(
:-] id UInt8 default 0 comment '编号',
:-] name String default '无姓名' comment '姓名',
:-] age UInt8 default 18 comment '年龄'
:-] )engine = TinyLog;
CREATE TABLE IF NOT EXISTS newdb.t1
(
`id` UInt8 DEFAULT 0 COMMENT '编号',
`name` String DEFAULT '无姓名' COMMENT '姓名',
`age` UInt8 DEFAULT 18 COMMENT '年龄'
)
ENGINE = TinyLog
Ok.
0 rows in set. Elapsed: 0.004 sec.
# 第二种方式创建表
node1 :) create table if not exists t2 engine = Memory as newdb.t_tinylog;
CREATE TABLE IF NOT EXISTS t2 AS newdb.t_tinylog
ENGINE = Memory
Ok.
0 rows in set. Elapsed: 0.006 sec.
# 第三种方式创建表
node1 :) create table if not exists t3 engine = Memory as select * from newdb.t_tinylog where id >2;
CREATE TABLE IF NOT EXISTS t3
ENGINE = Memory AS
SELECT *
FROM newdb.t_tinylog
WHERE id > 2
Ok.
0 rows in set. Elapsed: 0.010 sec.
#查询表t3数据
node1 :) select * from t3;
SELECT *
FROM t3
┌─id─┬─name─┬─age─┐
│ 3 │ 王五 │ 20 │
└────┴──────┴─────┘
1 rows in set. Elapsed: 0.004 sec.5. 查看表
- 查看表语法:
SHOW TABLES;
SHOW TABLES IN default;6. 查看表的定义
- 查看表定义语法:
SHOW CREATE TABLE XXX;- 示例:
#查看表定义
node1 :) show create table t3;
SHOW CREATE TABLE t3
┌─statement─────────────────────────────────┐
│ CREATE TABLE newdb.t3
(
`id` UInt8,
`Name` String
)
ENGINE = TinyLog │
└───────────────────────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.7. 查看表的字段
- 查看表定义语法:
DESC XXXX;- 示例:
#查看表t3的字段
node1 :) desc t3;
DESCRIBE TABLE t3
┌─name─┬─type───┬─default_type─┬─...
│ id │ UInt8 │ │ ...
│ Name │ String │ │ ...
└──────┴────────┴──────────────┴──...
2 rows in set. Elapsed: 0.004 sec.8. 删除表
- 删除表的基本语法:
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]- 示例:
#删除表
node1 :) drop table t3;
DROP TABLE t3
Ok.
0 rows in set. Elapsed: 0.003 sec.9. 修改表
- 修改表语法
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ...9.1 添加列
- 示例:
#使用default 库,创建表 test1,使用MergeTree引擎
node1 :) use default;
node1 :) create table test1(id UInt8,name String)engine = MergeTree() order by id partition by name;
CREATE TABLE test1
(
`id` UInt8,
`name` String,
`loc` String
)
ENGINE = MergeTree()
PARTITION BY loc
ORDER BY id
Ok.
0 rows in set. Elapsed: 0.005 sec.Ok.
#查看表test1表结构
node1 :) desc test1;
DESCRIBE TABLE test1
┌─name─┬─type───┬...
│ id │ UInt8 │...
│ name │ String │...
│ loc │ String │...
└──────┴────────┴...
3 rows in set. Elapsed: 0.004 sec.
#添加表字段
node1 :) alter table test1 add column age UInt8;
#查看表结构,添加字段成功
node1 :) desc test1;
DESCRIBE TABLE test1
┌─name─┬─type───┬...
│ id │ UInt8 │...
│ name │ String │...
│ loc │ String │...
│ age │ UInt8 │...
└─────┴─────┴...
4 rows in set. Elapsed: 0.003 sec.9.2 删除列
- 示例:
#删除表test1中的name age字段
node1 :) alter table test1 drop column age;
#查看表 test1表结构
node1 :) desc test1;
DESCRIBE TABLE test1
┌─name─┬─type───┬...
│ id │ UInt8 │...
│ name │ String │...
│ loc │ String │...
└──────┴────────┴...
2 rows in set. Elapsed: 0.004 sec.9.3 清空列
注意,不能清空排序、主键、分区字段。
- 示例:
#向表 test1中插入以下几条数据
node1 :) insert into table test1 values (1,'张三','北京'),(2,'李四','上海'),(3,'王五','北京');
#查看表中的数据
┌─id─┬─name─┬─loc──┐
│ 1 │ 张三 │ 北京 │
│ 3 │ 王五 │ 北京 │
└────┴──────┴──────┘
┌─id─┬─name─┬─loc──┐
│ 2 │ 李四 │ 上海 │
└────┴──────┴──────┘
#清空 test1 name列在’北京’分区的值
node1 :) alter table test1 clear column name in partition '北京';
#查看表中的数据
node1 :) select * from test1;
┌─id─┬─name─┬─loc──┐
│ 1 │ │ 北京 │
│ 3 │ │ 北京 │
└────┴──────┴──────┘
┌─id─┬─name─┬─loc──┐
│ 2 │ 李四 │ 上海 │
└────┴──────┴──────┘
#清空 test1 name 列下的值
node1 :) alter table test1 clear column name;
#查看表中的数据
node1 :) select * from test1;
┌─id─┬─name─┬─loc──┐
│ 1 │ │ 北京 │
│ 3 │ │ 北京 │
└───┴────┴─────┘
┌─id─┬─name─┬─loc──┐
│ 2 │ │ 上海 │
└───┴─────┴────┘9.4 给列修改注释
- 示例:
#修改表 test1 name 列的注释
node1 :) alter table test1 comment column name '姓名';
#查看表 test1描述
┌─name─┬─type───┬─default_type─┬─default_expression─┬─comment─┬...
│ id │ UInt8 │ │ │ │...
│ name │ String │ │ │ 姓名 │...
│ loc │ String │ │ │ │...
└──────┴────────┴──────────────┴────────────────────┴─────────┴...-
9.5 修改列类型
- 示例:
#修改表 test1 name列类型为UInt8
node1 :) alter table test1 modify column name UInt8
#node1 :) desc test1;
┌─name─┬─type───┬─default_type─┬─default_expression─┬─comment─┬
│ id │ UInt8 │ │ │ │
│ name │ UInt8 │ │ │ 姓名 │
│ loc │ String │ │ │ │
└──────┴────────┴──────────────┴────────────────────┴─────────┴10. 给表重命名
给表重新命名可以作用在任意的表引擎上。
10.1 给表重命名语法
RENAME TABLE [db11.]name11 TO [db12.]name12, [db21.]name21 TO [db22.]name22, ... [ON CLUSTER cluster]10.2 示例
#创建库 testdb1
node1 :) create database testdb1;
#创建库 testdb2
node1 :) create database testdb2;
#使用库testdb1,并创建表 t1
node1 :) use testdb1;
node1 :) create table t1 (id UInt8 ,name String) engine = MergeTree() order by id ;
#将表 t1 重命名为test1
node1 :) rename table t1 to test1;
#将表test1 移动到testdb2库下,并重新命名为t2, testdb1 下没有表了
node1 :) rename table testdb1.test1 to testdb2.t2;👨💻如需博文中的资料请私信博主。